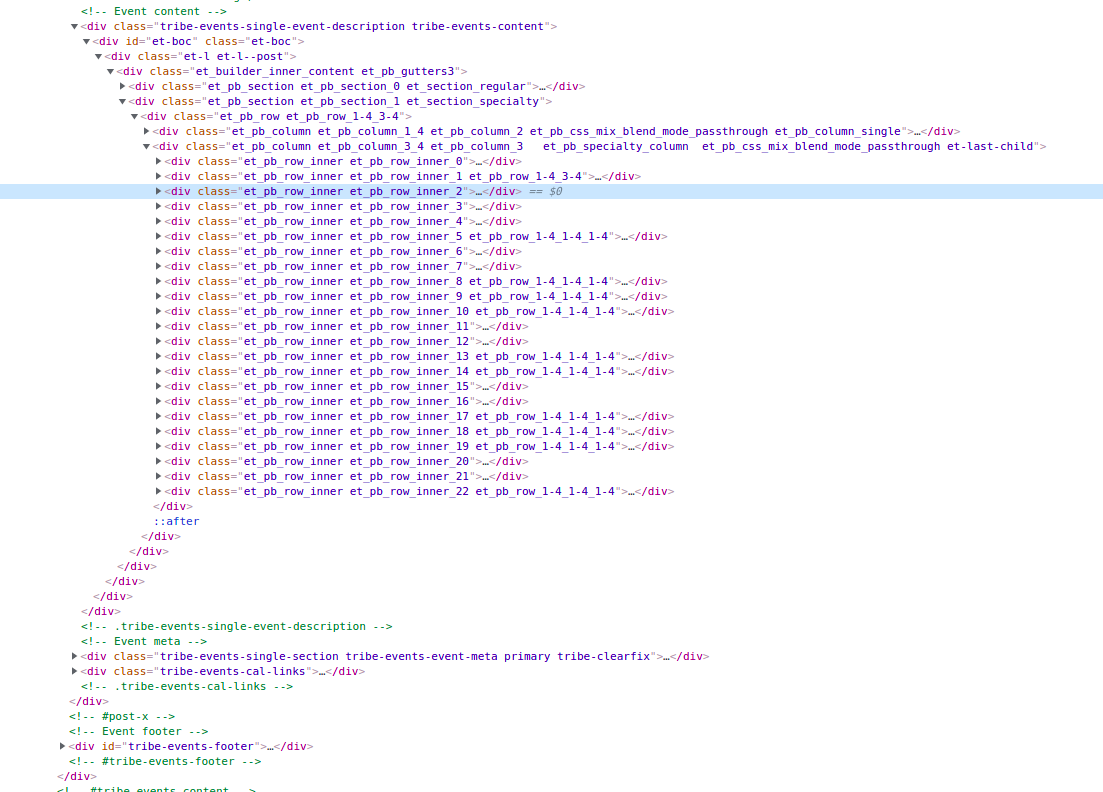
我正在嘗試使用漂亮的湯來清理 html 資料。我想洗掉一組標簽以及該標簽中關聯的資料,這些資料從et_pb_row_inner et_pb_row_inner_2到開始連續et_pb_row_inner et_pb_row_inner_22。
我正在嘗試的代碼是這樣的
代碼
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
for x in range(2,23):
mydiv = soup.find("div", {"class": "et_pb_row_inner et_pb_row_inner_{}".format(x)})
mydiv.extract()
text = soup.getText(separator=u' ')
return text
我通過使用 單獨指定類名來獲得它find(),但是如何以一般方式進行操作。
uj5u.com熱心網友回復:
您可以使用正則運算式來查找所有<div>具有這些屬性并以 2 或更高結尾的標簽。
所以基本上正則運算式r'et_pb_row_inner et_pb_row_inner_([2-9]|[\d]{2,}).*'是說找到所有以et_pb_row_inner et_pb_row_inner_2 到 9 的單個數字結尾或長度為 2 或更多的數字。
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
for mydiv in soup.find_all("div", {"class":re.compile(r'et_pb_row_inner et_pb_row_inner_([2-9]|[\d]{2,}).*')}):
mydiv.extract()
text = soup.getText(separator=u' ')
return text
這樣你就不需要對范圍 2 到 21 進行硬編碼。它只會從 2 到最后一個值。另一種方法是使用切片。
def madisonsymphony(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
for h in soup.find_all('header'):
try:
h.extract()
except:
pass
for f in soup.find_all('footer'):
try:
f.extract()
except:
pass
tophead = soup.find("div",{"id":"top-header"})
tophead.extract()
mydivs = soup.find_all("div", {"class":re.compile(r'et_pb_row_inner et_pb_row_inner_.*')})
for mydiv in mydivs[2:]: # Start at the 2nd element in the list and continue to the end
mydiv.extract()
text = soup.getText(separator=u' ')
return text
問題在于您必須假設存在 a0和1。如果由于某種原因屬性從 開始1,那么您將保留2,這將是第二個元素。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/341149.html