如何從圍繞 REST 組織的 API 獲取 http 請求,所有 API 回應都回傳 JSON。所有資源都支持通過“串列”API 方法進行批量獲取
這是我的檔案:
# With shell, you can just pass the correct header with each request
curl "https://www.api_url.com/api/dispute?page=1&limit=5"
-H "Authorization: [api_key]"
# Query Parameters:
# page 1 The cursor used in the pagination (optional)
#limit 10 A limit on the number of dispute object to be returned, between 1 and 100 (optional).
我不知道如何在 python 中解釋這個并通過 api_key 從這個物件爭議中提取資料
import requests
import json
response = requests.get("https://api_url.com/")
uj5u.com熱心網友回復:
-Hcurl 中的選項設定請求的標頭。
對于使用 的請求requests,您可以通過傳遞關鍵字引數來設定額外的標頭headers。
import requests
import json
response = requests.get(
"https://www.api_url.com/api/dispute",
headers={"Authorization" : "<api_key_here>"}
)
如果需要,您還可以輕松添加引數
response = requests.get(
"https://www.api_url.com/api/dispute",
headers={"Authorization" : "<api_key_here>"},
params={
"page": 1,
"limit":1
}
)
如果要發出多個請求,可以考慮使用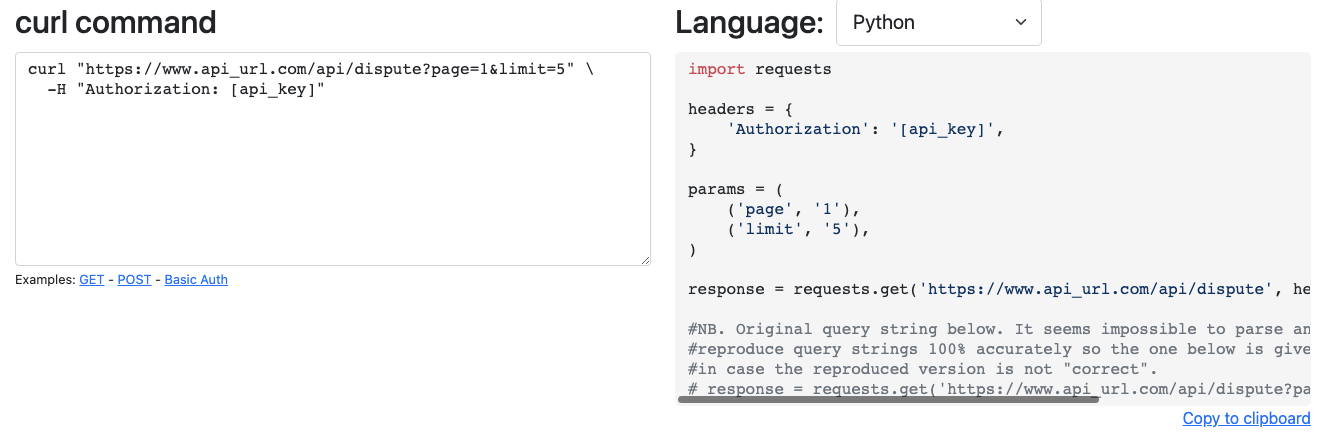
對于提供的curl輸入:
curl "https://www.api_url.com/api/dispute?page=1&limit=5" \
-H "Authorization: [api_key]"
這是 Python 中的結果。請注意,我已更改params為dict物件,因為在 Python 中使用字典更容易。任何查詢引數的值是否為 以外的型別都沒有關系str,因為它們將在發出請求時簡單地連接在 URL 字串中。
import requests
headers = {
'Authorization': '[api_key]',
}
params = {
'page': 1,
'limit': 5
}
response = requests.get('https://www.api_url.com/api/dispute',
headers=headers, params=params)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/341199.html
上一篇:連接具有增量列的檔案的內容只有1