我有一個具有以下結構和資料的示例表。
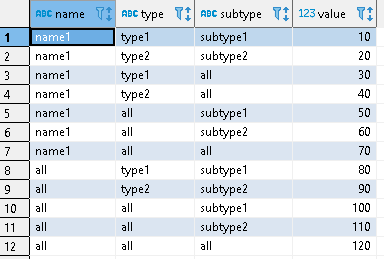
我必須從這個表中選擇關于名稱、型別和子型別的值。如果列值中的任何一個與條件不匹配,則應選擇帶有 'all' 的值。下面是創建的查詢。宣告名稱 varchar 默認 'name1' 宣告型別 varchar 默認 'type1' 宣告子型別 varchar 默認 'subtype1'
SELECT * FROM sampledata sd
where
case when (exists(select 1 from sampledata where name = :name))
then sd.name = :name and
case when exists (select 1 from sampledata where name = :name and type = :type)
then sd.type = :type and
case when exists (select 1 from sampledata where name = :name and type = :type and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
else sd.type = 'all' and
case when exists (select 1 from sampledata where name = :name and type = 'all' and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
end
else sd.name = 'all' and
case when exists (select 1 from sampledata where name = 'all' and type = :type)
then sd.type = :type and
case when exists (select 1 from sampledata where name = 'all' and type = :type and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
else sd.type = 'all' and
case when exists (select 1 from sampledata where name = 'all' and type = 'all' and subtype = :subtype)
then sd.subtype = :subtype
else sd.subtype = 'all'
end
end
end
這是“name1”、“type1”和“subtype1”的結果。

這是“name3”、“type3”和“subtype1”引數的結果。

CREATE TABLE sampledata (
"name" varchar NULL,
"type" varchar NULL,
subtype varchar NULL,
value float4 NULL
);
INSERT INTO sampledata
("name", "type", subtype, value)
VALUES ('name1', 'type1', 'subtype1', 10),
('name1', 'type2', 'subtype2', 20),
('name1', 'type1', 'all', 30),
('name1', 'type2', 'all', 40),
('name1', 'all', 'subtype1', 50),
('name1', 'all', 'subtype2', 60),
('name1', 'all', 'all', 70),
('all', 'type1', 'subtype1', 80),
('all', 'type2', 'subtype2', 90),
('all', 'all', 'subtype1', 100),
('all', 'all', 'subtype2', 110),
('all', 'all', 'all', 120);
查詢作業正常,我想知道是否有優化的邏輯而不使用嵌套案例來實作相同的結果。
提前致謝。
uj5u.com熱心網友回復:
列舉和排序:
\i tmp.sql
-- The table definition
-- ---------------------------------
CREATE TABLE sampledata
( id serial primary key
, name text
, type text
, subtype text
, val integer
);
-- I had to type in the data myself
-- ---------------------------------
INSERT INTO sampledata ( name , type , subtype ,val)
VALUES ('name1' , 'type1' , 'subtype1', 10)
, ('name1' , 'type2' , 'subtype2', 20)
, ('name1' , 'type1' , 'all', 30)
, ('name1' , 'type2' , 'all', 40)
, ('name1' , 'all' , 'subtype1', 50)
, ('name1' , 'all' , 'subtype2', 60)
, ('name1' , 'all' , 'all', 70)
, ('all' , 'type1' , 'subtype1', 80)
, ('all' , 'type2' , 'subtype2', 90)
, ('all' , 'all' , 'subtype1', 100)
, ('all' , 'all' , 'subtype2', 110)
, ('all' , 'all' , 'all', 120)
;
SELECT * FROM sampledata ;
-- Prepared query to allow parameters
-- ------------------------------------
PREPARE omg(text,text,text) AS
SELECT *
, 0::int
40*(name = $1)::int
20*(type = $2)::int
10*(subtype = $3)::int
4*(name = 'all' )::int
2*(type = 'all' )::int
1*(subtype = 'all' )::int
AS flag
FROM sampledata sd
WHERE name in($1, 'all' )
AND type in($2, 'all' )
AND subtype in($3, 'all' )
ORDER BY flag DESC
LIMIT 1
;
-- Example#1
-- -----------
EXECUTE omg('name1' , 'type1' , 'subtype1' );
-- Example#2
-- -----------
EXECUTE omg('name3' , 'type3' , 'subtype1' );
結果:
DROP SCHEMA
CREATE SCHEMA
SET
CREATE TABLE
INSERT 0 12
id | name | type | subtype | val
---- ------- ------- ---------- -----
1 | name1 | type1 | subtype1 | 10
2 | name1 | type2 | subtype2 | 20
3 | name1 | type1 | all | 30
4 | name1 | type2 | all | 40
5 | name1 | all | subtype1 | 50
6 | name1 | all | subtype2 | 60
7 | name1 | all | all | 70
8 | all | type1 | subtype1 | 80
9 | all | type2 | subtype2 | 90
10 | all | all | subtype1 | 100
11 | all | all | subtype2 | 110
12 | all | all | all | 120
(12 rows)
PREPARE
id | name | type | subtype | val | flag
---- ------- ------- ---------- ----- ------
1 | name1 | type1 | subtype1 | 10 | 70
(1 row)
id | name | type | subtype | val | flag
---- ------ ------ ---------- ----- ------
10 | all | all | subtype1 | 100 | 16
(1 row)
uj5u.com熱心網友回復:
我建議采用以下方法:
WITH list AS
( SELECT name, type, subtype
, case when name = 'all' then 2 else 1 end AS name_weight
, case when type= 'all' then 2 else 1 end AS type_weight
, case when subtype= 'all' then 2 else 1 end AS subtype_weight
FROM sampledata sd
WHERE (name = 'name3' OR name = 'all')
AND (type = 'type3' OR type = 'all')
AND (subtype = 'subtype1' OR subtype = 'all')
)
SELECT name, type, subtype
FROM list
ORDER BY (name_weight*type_weight*subtype_weight) ASC
LIMIT 1
如果表中存在兩行,則此查詢將回傳隨機結果:
(all, type3,subtype1) 和 (name3,all,subtype1)
因為它們會得到相同的權重 = name_weight*type_weight*subtype_weight,所以必須針對這種情況細化 ORDER BY 子句,例如通過為 name、type、subtype 定義不同的權重,以便優先考慮它們的重要性
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/341501.html
標籤:sql PostgreSQL