一、InnoDB體系結構
InnoDB 存盤引擎有多個記憶體塊,這些記憶體塊組成了一個大的記憶體池,負責的作業如下:
- 維護所有行程/執行緒需要訪問的多個內部資料結構,
- 快取磁盤上的資料,方便快速地讀取,同時在對磁盤檔案的資料修改之前在這里快取,
- 重做日志緩沖(redo log),
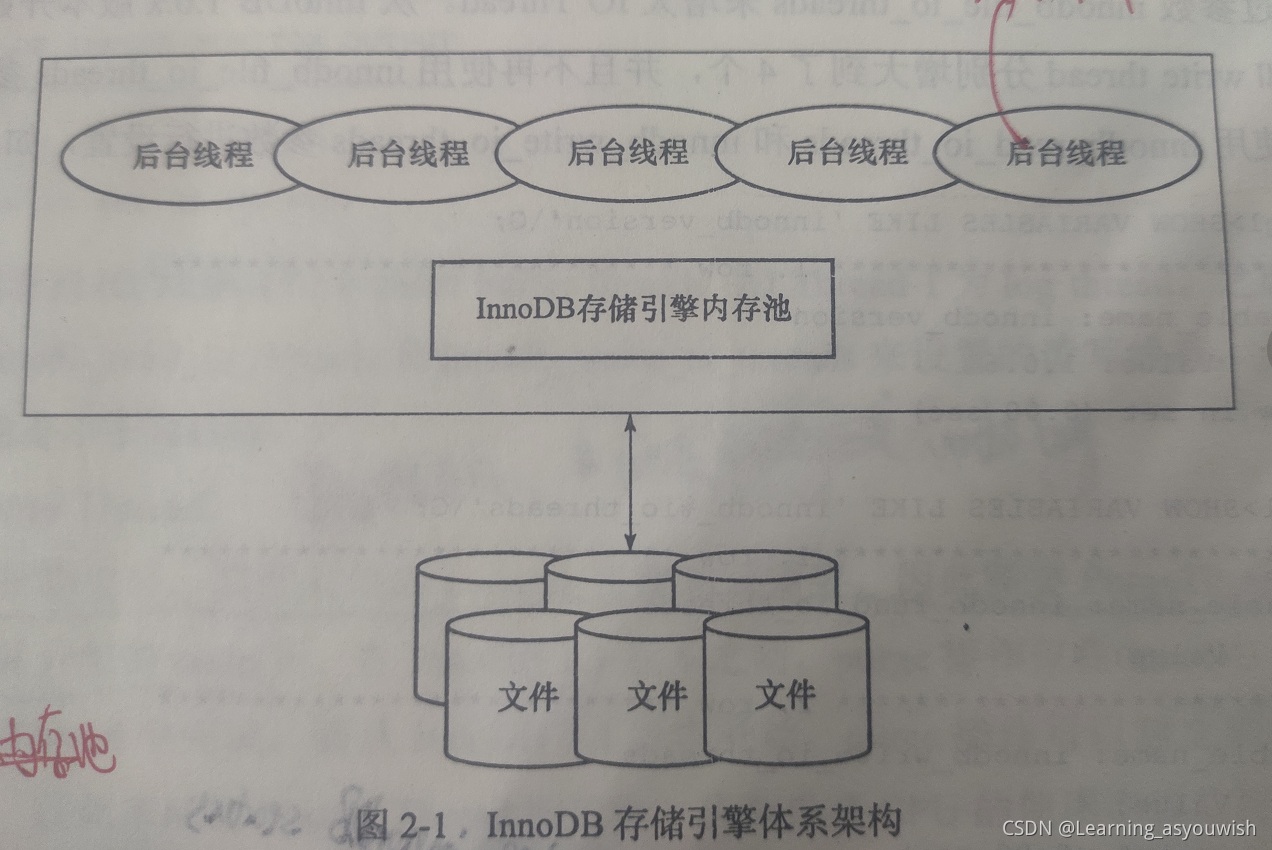
后臺執行緒的作用:負責重繪記憶體池中的資料,保證緩沖池中的記憶體快取的是最近的資料,將已修改的資料檔案重繪到磁盤檔案,同時保證在資料庫發生例外的情況下 InnoDB 能恢復到正常運行狀態,
二、后臺執行緒
InnoDB存盤引擎是多執行緒模型,因此后臺有多個不同的后臺執行緒,負責處理不同的任務,
1、Master Thread
- Master Thread 是一個非常核心的后臺執行緒,主要負責將緩沖池中的資料異步重繪到磁盤,保證資料的一致性,包括臟頁的重繪、合并插入緩沖、undo 頁的回收等,
2、IO Thread
- 在InnoDB中大量使用了 AIO(Async IO)來處理IO請求,這樣可以極大提高資料庫的性能,IO Thread 的主要作業是負責這些IO請求的回呼處理,
- InnoDB 1.0 版本之前共有四個IO Thread,分別是write、read、insert buffer 、log IO Thread,
- InnoDB 1.0.x 版本開始,read thread 和 write thread 分別增大到4個,分別使用 innodb_read_io_threads 和 innodb_wirte_io_threads 引數進行設定,
- 查看引數:SHOW VARIABLE LIKE ‘innodb_%io_threads’\G;
3、Purge Thread
- 事務被提交后,所使用的 undolog 日志可能不再需要,因此需要 Purge Thread 執行緒來回收已經使用且分配的undo頁,InnoDB 1.1 版本開始,purge 操作可以獨立到單獨的執行緒中進行,可以減輕 master thread 的作業,提高CPU的使用率和提升存盤引擎的性能,
- 啟用purge:innodb_purge_threads=1,
- InnoDB 1.2 版本開始,可以啟用多個 purge thread,這樣做的目的是為了加快 undo 頁的回收,同時由于 purge thread 需要離散的讀取 undo 頁,這樣也能進一步利用磁盤的隨機讀取性能,
三、記憶體
1、緩沖池
- InnoDB 存盤引擎是基于磁盤存盤的,并將其中的記錄按照頁的方式進行管理,在資料庫系統中,由于CPU速度和磁盤速度之間存在較大的差異,所以基于磁盤存盤的資料庫系統常用緩沖池技術來提高資料庫的整體性能,緩沖池就是一塊記憶體區域,
- 在資料庫中進行讀取資料頁的操作,首先將從磁盤讀到的頁放入緩沖池中,也就是將頁 “FIX” 在緩沖池中,下一次要讀取該頁時則先從緩沖池進行讀取,若緩沖池中沒有才讀取磁盤上的資料,
- 對于資料庫中頁的修改操作,則首先是在緩沖池中修改對應的頁,然后再按照一定的頻率重繪到磁盤上,頁從緩沖池重繪到磁盤并不是每次頁發生更改時觸發,而是通過 “checkpoint” 機制重繪回磁盤,通過這種方式可以提高資料庫的整體性能,
- 緩沖池大小設定:引數 innodb_buffer_pool_size 可以設定緩沖池的大小,
- 緩沖池中快取的資料頁型別:索引頁、資料頁、undo 頁、插入緩沖(insert buffer)、自適應哈希索引、innodb存盤的鎖資訊、資料字典資訊等,其中索引頁和資料頁占緩沖池的很大一部分記憶體,
- 從 InnoDB 1.0.x 版本開始,可以設定多個緩沖池,將每個頁根據哈希值平均分配到不同緩沖池實體中,可以減少資料庫內部的競爭,增加資料庫的并發處理能力,可以通過引數 “innodb_buffer_pool_instances” 來配置(可通過 “show engine innodb status” 查看緩沖池狀態),
2、記憶體區域管理:LRU List、Free List、Flush List
- 資料庫的緩沖池通過 LRU 演算法進行管理的,當緩沖池不能存放新讀取的頁時,首先將 LRU 串列中尾端的頁,再將新頁放在 LRU 串列中前端,在 InnoDB 存盤引擎中,緩沖池中頁的默認大小是 16KB,
- InnoDB 對傳統的 LRU 演算法做了優化,在 LRU串列中加入了 midpoint 位置,新讀取的頁并不是直接放入 LRU 串列的首部,而是放到 LRU 串列的 midpoint 位置,在默認配置下,midpoint 位置在 LRU 串列長度的 5/8 處,midpoint 位置可以由引數 “innodb_old_blocks_pct” 控制,把 midpoint 之前的串列稱為 new 串列(熱點資料),之后的串列稱為 old 串列,
- 為什么要對 LRU 演算法進行改進?
將讀取的頁直接放入 LRU 的首部,常見的這些操作作為索引或資料的掃描操作,這類操作需要訪問表中的許多頁,甚至是全部頁,這些頁通常來說只是在本次查詢中使用,并不是活躍的熱點資料,如果將頁放入 LRU 串列的首部,那么非常可能將所需要的熱點資料頁從串列中移除,在下一次需要讀取這些頁時,需要再次訪問磁盤,從而影響緩沖池的效率, - InnoDB 存盤引擎還引入了另一個引數 “innodb_old_blocks_time” 來進一步管理 LRU 串列,用于表示頁讀取到 mid 位置后需要等待多久才會被加入到 LRU 串列的首部,
- LRU 串列用來管理已經讀取的頁,當資料庫啟動時,串列是空的,這時頁都存放在 Free 串列中,當需要從緩沖池中分頁時,首先從 Free 串列中查詢是否有可用的空閑頁,若有則從 Free 串列中移除,放入到 LRU 串列中;否則,根據 LRU 演算法淘汰 LRU 末尾的頁,將該記憶體分配非新的頁,當頁從 old 部分加入到 new 部分時,此時發生的操作稱作 “page made young” ;因為 “innodb_old_blocks_time” 引數的設定頁沒有從 old 部分加入到 new 部分時,此時發生的操作稱作 “page not made young”,LRU 串列和 Free 串列的使用情況和運行情況如下所示:

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/342059.html
標籤:其他
上一篇:軟體體系結構
下一篇:MYSQL架構詳解