整理的演算法模板合集: ACM模板
點我看演算法全家桶系列!!!
實際上是一個全新的精煉模板整合計劃
寫在最前面:本文部分內容來自網上各大博客或是各類圖書,由我個人整理,增加些許見解,僅做學習交流使用,無任何商業用途,因個人實力時間等原因,本文并非完全原創,請大家見諒,
目錄
- 《演算法競賽中的初等數論》(四)正文 0x40反演(ACM / OI / MO)(十五萬字符數論書)
- 0x50 篩法
- 0x51 線性篩法
- 0x51.1 線性篩法求歐拉函式
- 0x51.2 線性篩求莫比烏斯函式
- 0x51.3 線性篩求約數個數函式
- 0x51.4 線性篩求約數和函式
- 0x52 杜教篩
- 0x52.1 杜教篩
- 0x52.2 求歐拉函式前綴和
- 0x52.3 求莫比烏斯函式前綴和
- 0x53 Min_25篩
- 0x54 洲閣篩
《演算法競賽中的初等數論》(四)正文 0x40反演(ACM / OI / MO)(十五萬字符數論書)
《演算法競賽中的初等數論》(信奧 / 數競 / ACM)前言、后記、目錄索引(十五萬字符的數論書)
全文目錄索引鏈接: https://fanfansann.blog.csdn.net/article/details/113765056
0x50 篩法
0x51 線性篩法
在上面篩質數的時候,我們講解了如何使用線性篩線性地篩出 1 , ? ? , n 1,\cdots,n 1,?,n 中的所有質數,
每次只用一個數用小于當前這個數最小質因子的質數去篩其他數,即保證每個合數 i × p j i\times p_j i×pj? 只都被自己的最小質因子 p j p_j pj? 篩掉一遍,所以復雜度保證是 O ( n ) O(n) O(n) 的,
我們知道,凡是積性函式,均可由線性篩法來求解,
0x51.1 線性篩法求歐拉函式
我們注意到在線性篩中,每一個合數都是被最小的質因子篩掉,篩法求素數的同時也得到了每個數的最小質因子,這是線性篩求歐拉函式的關鍵,
1. 考慮 n = p j k n=p_j^k n=pjk?, φ ( n ) \varphi(n) φ(n)
顯然有 φ ( p j k ) = p j k ? p j k ? 1 = p j k ? 1 × ( p j ? 1 ) \varphi(p_j^k)=p_j^{k}-p_j^{k-1}=p_j^{k-1}\times(p_j-1) φ(pjk?)=pjk??pjk?1?=pjk?1?×(pj??1)
2. 考慮 n = i × p j n=i\times p_j n=i×pj?, φ ( n ) \varphi(n) φ(n),當 p j ∣ i p_j\mid i pj?∣i
即 i i i 含有因子 p j p_j pj?,由于 i = n p j i=\frac{n}{p_j} i=pj?n? 即 i i i 擁有 n n n 的所有質因子,由唯一分解定理及歐拉函式計算式得:
φ
(
n
)
=
n
×
∏
i
=
1
s
p
i
?
1
p
i
=
p
1
×
n
′
×
∏
i
=
1
s
p
i
?
1
p
i
=
p
1
×
φ
(
n
′
)
\begin{aligned} \varphi(n) & = n \times \prod_{i = 1}^s{\frac{p_i - 1}{p_i}} & \\ &= p_1 \times n' \times \prod_{i = 1}^s{\frac{p_i - 1}{p_i}} & \\ &= p_1 \times \varphi(n') \end{aligned}
φ(n)?=n×i=1∏s?pi?pi??1?=p1?×n′×i=1∏s?pi?pi??1?=p1?×φ(n′)??
3. 考慮
n
=
i
×
p
j
n=i\times p_j
n=i×pj?,
φ
(
n
)
\varphi(n)
φ(n),當
p
j
?
i
p_j\nmid i
pj??i
即 i i i 與 p j p_j pj? 互質,積性函式顯然有性質:
φ ( n ) = φ ( i ) × φ ( p j ) = φ ( i ) × ( p j ? 1 ) \begin{aligned} \varphi(n) & = \varphi(i) \times \varphi(p_j) & \\ & = \varphi(i) \times (p_j - 1) \end{aligned} φ(n)?=φ(i)×φ(pj?)=φ(i)×(pj??1)?
由于我們僅在在線性篩的框架上增加了一些細節,所以時間復雜度依然是 O ( n ) O(n) O(n) 的,
Code
void get_euler(int n)
{
phi[1] = 1;
for(int i = 2; i <= n; ++ i) {
if(!vis[i]) {
primes[ ++ cnt] = i;
phi[i] = i - 1;
}
for(int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[i * primes[j]] = true;
if(i % primes[j] == 0) {//最小的質因子
phi[i * primes[j]] = phi[i] * primes[j];
break;
}
phi[i * primes[j]] = phi[i] * (primes[j] - 1);
}
}
}
0x51.2 線性篩求莫比烏斯函式
同樣考慮三種情況即可,
1. 考慮 n = p j k n=p_j^k n=pjk?, μ ( n ) \mu (n) μ(n)
顯然有
μ ( p j ) = ? 1 \mu(p_j)=-1 μ(pj?)=?1
μ ( p j k ) = 0 , k > 1 \mu(p_j^k)=0,k>1 μ(pjk?)=0,k>1
2. 考慮 n = i × p j n=i\times p_j n=i×pj?, μ ( n ) \mu(n) μ(n),當 p j ∣ i p_j\mid i pj?∣i
μ ( n ) = 0 \mu(n)=0 μ(n)=0
3. 考慮 n = i × p j n=i\times p_j n=i×pj?, μ ( n ) \mu(n) μ(n),當 p j ? i p_j\nmid i pj??i
μ ( n ) = ? m u ( i ) \mu(n)=-mu(i) μ(n)=?mu(i)
Code
void get_mu(int n)
{
cnt = 0, mu[1] = 1;
for(int i = 2; i <= n; ++ i) {
if(vis[i] == 0){
primes[ ++ cnt] = i;
mu[i] = -1;
}
for(int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[primes[j] * i] = 1;
if(i % primes[j] == 0) break;
mu[i * primes[j]] -= mu[i];
//mi[i * primes[j]] = -mu[i];
}
}
for(int i = 1; i <= n; ++ i)
sum[i] += sum[i - 1] + mu[i];
}
0x51.3 線性篩求約數個數函式
約數個數函式: d ( n ) d(n) d(n) :表示 n n n 的正因子數目,
d ( n ) = ∑ i ∣ n 1 d(n)=\sum_{i|n}1 d(n)=i∣n∑?1
定理51.3.1: 若 n = ∏ i = 1 m p i c i n=\prod_{i=1}^mp_i^{c_i} n=∏i=1m?pici??,則 d i = ∏ i = 1 m c i + 1 = ( c 1 + 1 ) × ? × ( c m + 1 ) d_i=\prod_{i=1}^mc_i+1=(c_1+1)\times \cdots \times (c_m+1) di?=∏i=1m?ci?+1=(c1?+1)×?×(cm?+1)
證明:我們知道 p i c i p_i^{c_i} pici?? 的約數一共有 p i 0 , p i 1 , ? ? , p i c i p_i^0,p_i^1,\cdots ,p_i^{c_i} pi0?,pi1?,?,pici?? 個,即對于每個質因子 p i p_i pi? 都可以選擇其出現 0 0 0 次, 1 1 1 次, ? ? , c i \cdots,c_i ?,ci? 次,我們根據乘法原理,可得 n n n 的約數個數為 ∏ i = 1 m c i + 1 \prod_{i=1}^mc_i+1 ∏i=1m?ci?+1
這里我們規定 d i d_i di? 為 i i i 的約數個數, n u m i num_i numi? 表示 i i i 的最小質因子出現次數,
隨機資料下,約數個數的期望是 O ( ln ? n ) O(\ln n) O(lnn)
Code
void get_divisor_num(int n) {
d[1] = 1;
for (int i = 2; i <= n; ++i) {
if (vis[i] == 0) {
vis[i] = 1;
primes[ ++ cnt] = i;
d[i] = 2, num[i] = 1;
}
for (int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[primes[j] * i] = 1;
if (i % primes[j] == 0) {
num[i * primes[j]] = num[i] + 1;//這里的primes[j]一定是i的最小質因子
d[i * primes[j]] = d[i] / num[i * primes[j]] * (num[i * primes[j]] + 1);
//數i*primes[j]的質因子primes[j]的出現次數num增加,即公式中的ci增加,對答案的貢獻增加,所以需要更新
break;
} else num[i * primes[j]] = 1, d[i * primes[j]] = d[i] * 2;
}
}
}
0x51.4 線性篩求約數和函式
約數和函式:
σ
(
n
)
\sigma(n)
σ(n) :表示
n
n
n 的所有正因子之和 ,
σ
(
n
)
=
∑
d
∣
n
d
\sigma(n)=\sum_{d|n}d
σ(n)=d∣n∑?d
定理51.3.2: 若 n = ∏ i = 1 m p i c i n=\prod_{i=1}^mp_i^{c_i} n=∏i=1m?pici??,則 σ i = ∏ i = 1 m ( ∑ j = 0 c i ( p i ) j ) = ( 1 + p 1 + p 1 2 + ? + p 1 c 1 ) × ? × ( 1 + p m + p m 2 + ? + p m c m ) \sigma_i=\prod_{i=1}^{m}(\sum_{j=0}^{c_i}(p_i)^j)=(1+p_1+p_1^2+\cdots +p_1^{c_1})\times\cdots\times(1+p_m+p_m^2+\cdots +p_m^{c_m}) σi?=∏i=1m?(∑j=0ci??(pi?)j)=(1+p1?+p12?+?+p1c1??)×?×(1+pm?+pm2?+?+pmcm??)
證明略,思路同約數個數函式 d ( n ) d(n) d(n) 的證明,
這里我們規定 f i f_i fi? 表示 i i i 的約數和, g i g_i gi? 表示 i i i 的最小質因子 p + p 1 + p 2 + ? p k p+p^1+p^2+ \cdots p^k p+p1+p2+?pk,
void get_divisor_sum() {
g[1] = f[1] = 1;
for (int i = 2; i <= n; ++ i) {
if (vis[i] == 0) {
vis[i] = 1;
primes[ ++ cnt] = i;
g[i] = i + 1;
f[i] = i + 1;
}
for (int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
v[i * primes[j]] = 1;
if (i % primes[j] == 0) {
g[i * primes[j]] = g[i] * primes[j] + 1;
f[i * primes[j]] = f[i] / g[i] * g[i * primes[j]];//更新
break;
} else {
f[i * primes[j]] = f[i] * f[primes[j]];
g[i * primes[j]] = primes[j] + 1;
}
}
}
for (int i = 1; i <= n; ++ i)
f[i] = (f[i - 1] + f[i]) % mod;
}
我們可以利用線性篩求解其他的所有積性函式的值,僅需根據具體的性質自行推導兩種情況的處理辦法即可,
n n n 的正約數之積… n ? d ( x ) 2 ? n^{\left \lfloor \frac{d(x)}{2}\right\rfloor} n?2d(x)??
0x52 杜教篩
0x52.1 杜教篩
杜教篩被用來處理數論函式的前綴和問題,對于一個前綴和,杜教篩可以在低于線性時間的復雜度(
O
(
n
2
3
)
O(n^{\frac 2 3})
O(n32?))內求解,

杜教篩其實特別簡單,就是一個構造
+
+
+ 和式轉換,利用
D
i
r
i
c
h
e
l
t
Dirichelt
Dirichelt 卷積構造兩個積性函式卷起來,將要求的前綴和
s
(
n
)
s(n)
s(n)構造成
s
(
?
n
i
?
)
s(\left \lfloor \dfrac{n}{i}\right \rfloor)
s(?in??)的形式,這樣我們就可以用整除分塊來優化復雜度,可以快速解決一類積性函式的前綴和,
n
n
n 可以達到
1
0
9
~
1
0
10
10^9\sim 10^{10}
109~1010 ,積性函式比如莫比烏斯函式
μ
(
x
)
μ(x)
μ(x) ,歐拉函式
?
(
x
)
\phi(x)
?(x) ,約數和函式
σ
k
(
x
)
σ_k(x)
σk?(x) ,約數個數函式
σ
(
x
)
σ(x)
σ(x) 等等,
● 基本性質定理
性質52.1.1: g ( 1 ) S ( n ) = ∑ i = 1 n ( f ? g ) ( i ) ? ∑ d = 2 n g ( d ) S ( ? n d ? ) \displaystyle g(1) S(n)=\sum_{i=1}^{n}(f \ast g)(i)-\sum_{d=2}^{n} g(d) S\left(\left \lfloor\frac{n}{d}\right \rfloor\right) g(1)S(n)=i=1∑n?(f?g)(i)?d=2∑n?g(d)S(?dn??)(其中 S ( n ) = ∑ i = 1 n f ( i ) \displaystyle S(n)=\sum_{i=1}^{n}f(i) S(n)=i=1∑n?f(i))
● 推導結論:
性質52.2.1: S μ ( x ) ( n ) = 1 ? ∑ d = 2 n S ( ? n d ? ) \displaystyle S_{\mu(x)}(n)=1-\sum_{d=2}^{n}S(\left \lfloor\frac{n}{d}\right \rfloor) Sμ(x)?(n)=1?d=2∑n?S(?dn??)(模板)
性質52.2.2: S φ ( x ) ( n ) = ∑ i = 1 n i ? ∑ d = 2 n S ( ? n d ? ) \displaystyle S_{\varphi(x)}(n)=\sum_{i=1}^{n} i-\sum_{d=2}^{n}S(\left \lfloor\frac{n}{d}\right \rfloor) Sφ(x)?(n)=i=1∑n?i?d=2∑n?S(?dn??)(模板)
性質52.2.3: S ( n 2 φ ( n ) ) = ∑ i = 1 n i 3 ? ∑ d = 2 n d 2 S ( ? n d ? ) \displaystyle S_{(n^{2}\varphi(n))}=\sum_{i=1}^{n} i^{3}-\sum_{d=2}^{n} d^{2} S\left(\left\lfloor\frac{n}{d}\right\rfloor\right) S(n2φ(n))?=i=1∑n?i3?d=2∑n?d2S(?dn??)(例題)
0x52.2 求歐拉函式前綴和

0x52.3 求莫比烏斯函式前綴和

Template A. 【模板】杜教篩(Sum)(P4213)
給定一個正整數,求
a
n
s
1
=
∑
i
=
1
n
φ
(
i
)
ans1=\sum^n_{i=1}\varphi(i)
ans1=i=1∑n?φ(i)
a
n
s
2
=
∑
i
=
1
n
μ
(
i
)
ans2=\sum^n_{i=1}\mu(i)
ans2=i=1∑n?μ(i)
Code
//const int N = 5e6 + 10; // n^2/3
const int N = 1665703; // n^2/3
inline int read()
{
register int x=0,f=1;
char c=getchar();
while(c<'0'||c>'9') {if(c=='-') f=-1;c=getchar();}
while(c>='0'&&c<='9') x=x*10+c-48,c=getchar();
return x*f;
}
int cnt;
int primes[N + 7];
ll mu[N + 7];
bool vis[N + 7];
ll phi[N + 7];
unordered_map<ll, ll> sum_mu;//陣列開不了那么大,所以用哈希表
unordered_map<ll, ll> sum_phi;
inline void init(int n)
{
vis[0] = vis[1] = 1;
mu[1] = phi[1] = 1;
for (int i = 2; i <= n; ++ i) {
if (!vis[i]) {
primes[ ++ primes[0]] = i;
mu[i] = -1;
phi[i] = i - 1;
}
for (int j = 1; j <= primes[0] && i * primes[j] <= n; ++ j) {
vis[i * primes[j]] = 1;
if (i % primes[j] == 0) {
mu[i * primes[j]] = 0;
phi[i * primes[j]] = phi[i] * primes[j];
break;
}
else {
mu[i * primes[j]] = - mu[i];
phi[i * primes[j]] = phi[i] * phi[primes[j]];
}
}
}
for (int i = 1; i <= n; ++ i) {
mu[i] += mu[i - 1];
phi[i] += phi[i - 1];
}
}
inline int g_sum(int x) //g的前綴和,這里的g = I(x)//常數函式
{
return x;
}
inline int get_sum_mu(int x) // 記憶化搜索
{
if (x <= N) return mu[x]; //預處理
//if (sum_mu.find(x) != sum_mu.end()) return sum_mu[x]; //記憶化
if(sum_mu[x]) return sum_mu[x];
int ans = 1; // 杜教篩中推出的1
for (ll l = 2, r; l <= x;l = r + 1) { // 整除分塊
r = x / (x / l);
//Σ_i=2 {g(i)*S(?n/i?)} g不一樣, S一樣,然后整除分塊
ans -= (g_sum(r) - g_sum(l - 1)) * get_sum_mu(x / l);
}
return sum_mu[x] = ans / g_sum(1); // 最后除以g(1)
}
inline ll get_sum_phi(int x)
{
if(x <= N) return phi[x];
//if(sum_phi.find(x) != sum_phi.end()) return sum_phi[x];
if(sum_phi[x]) return sum_phi[x];
ll ans = x * ((ll)x + 1) / 2;//杜教篩中的 n(n + 1) / 2
for (ll l = 2, r; l <= x; l = r + 1) {
r = x / (x / l);
ans -= 1ll * (g_sum(r) - g_sum(l - 1)) * get_sum_phi(x / l);
}
return sum_phi[x] = ans / g_sum(1);
}
int main()
{
init(N);
int t;
scanf("%d", &t);
while(t -- ) {
int n;
scanf("%d", &n);
printf("%lld %d\n", get_sum_phi(n), get_sum_mu(n));
}
return 0;
}
當我們的題目中所給出的積性函式前綴和不太好找到性質使用線性篩 O ( n ) O(n) O(n) 求解,或者資料過大需要更加優秀的時間復雜度時,我們可以用狄利克雷卷上一個積性函式,使卷完后的式子的前綴和變得簡單,卷完后的前綴和算出來基本上題目就完成了,
例如:我們遇見 φ ( x ) \varphi(x) φ(x),就想辦法推式子往 ∑ d ∣ n φ ( d ) \displaystyle \sum_{d|n}\varphi(d) d∣n∑?φ(d) 上湊,
- 做題時想辦法湊出 ∑ i = 1 n ∑ d ∣ i f ( d ) \displaystyle \sum_{i=1}^n\sum_{d|i}f(d) i=1∑n?d∣i∑?f(d) ,且要求這個式子可以直接求出來,
- 我們轉化這個式子 ∑ i = 1 n ∑ j = 1 ? n i ? f ( d ) \displaystyle \sum_{i=1}^n\sum_{j=1}^{\lfloor \frac{n}{i}\rfloor }f(d) i=1∑n?j=1∑?in???f(d),再拆出要求的答案: ∑ i = 1 n ∑ j = 1 ? n i ? f ( d ) = ∑ i = 2 n ∑ j = 1 ? n i ? f ( d ) + ∑ j = 1 n f ( d \displaystyle \sum_{i=1}^n\sum_{j=1}^{\lfloor \frac{n}{i}\rfloor }f(d)=\sum_{i=2}^n\sum_{j=1}^{\lfloor \frac{n}{i}\rfloor }f(d)+\sum_{j=1}^nf(d i=1∑n?j=1∑?in???f(d)=i=2∑n?j=1∑?in???f(d)+j=1∑n?f(d
- ∑ i = 2 n ∑ j = 1 ? n i ? f ( d ) \displaystyle \sum_{i=2}^n\sum_{j=1}^{\lfloor \frac{n}{i}\rfloor }f(d) i=2∑n?j=1∑?in???f(d)這部分往下遞回做即可,
- 當 f ( i ) = φ ( i ) f(i)=\varphi(i) f(i)=φ(i) 或者 μ ( i ) \mu(i) μ(i) 時, ∑ d ∣ n f ( i ) \displaystyle \sum_{d|n}f(i) d∣n∑?f(i) 可以直接求出來,但是當 f ( i ) = i ? u ( i ) f(i)=i*u(i) f(i)=i?u(i) 時就不行了,我們需要卷積一個 g ( i ) = i g(i)=i g(i)=i,此時 ∑ i = 1 n f ? g = ∑ i = 1 n ∑ d ∣ i f ( d ) g ( i d ) = ∑ i = 1 n ∑ d ∣ i u ( d ) = 1 \displaystyle \sum_{i=1}^nf*g=\sum_{i=1}^n\sum_{d|i}f(d)g(\frac{i}{d})=\sum_{i=1}^n\sum_{d|i}u(d)=1 i=1∑n?f?g=i=1∑n?d∣i∑?f(d)g(di?)=i=1∑n?d∣i∑?u(d)=1,
競賽例題選講
Problem A. 簡單數學題 (Luogu P3768)

n ≤ 1 0 10 n \leq 10^{10} n≤1010 , 5 × 1 0 8 ≤ p ≤ 1.1 × 1 0 9 5 \times 10^8 \leq p \leq 1.1 \times 10^9 5×108≤p≤1.1×109 且 p p p 為質數,
Solution

注意一點:這種需要輸入模數mod的題,一定要等輸入模數之后再初始化 init !!不然會RE…膜0可不就RE了嘛…
Time
O ( n 2 3 ) O(n^{\frac{2}{3}}) O(n32?)
Code
#include <bits/stdc++.h>
#define int long long
using namespace std;
typedef long long ll;
const int N = 4641589;// ?(10^10)^(2/3)?
int primes[N + 7], cnt;
ll phi[N + 7];
bool vis[N + 7];
unordered_map<ll, ll> sum_f;
int mod, n;
int inv4, inv6;
int qpow(int a, int b)
{
int res = 1;
while(b) {
if(b & 1) res = 1ll * res * a % mod;
a = 1ll * a * a % mod;
b >>= 1;
}
return res % mod;
}
void init(int n)
{
phi[1] = 1;
for(int i = 2; i <= n; ++ i) {
if(vis[i] == 0) {
primes[ ++ cnt] = i;
phi[i] = i - 1;
}
for(int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[i * primes[j]] = true;
if(i % primes[j] == 0) {
phi[i * primes[j]] = 1ll * phi[i] * primes[j] % mod;
break;
}
phi[i * primes[j]] = 1ll * phi[i] * phi[primes[j]] % mod;
}
}
for(int i = 1; i <= n; ++ i) {
phi[i] = (1ll * phi[i - 1] + (1ll * phi[i] * i % mod * i % mod)) % mod;
}
}
inline int g_sum(int n) //i^2
{
n %= mod;
return 1ll * n * inv6 % mod * (n + 1) % mod * (2 * n + 1) % mod;
}
inline int h_sum(int n) //i^3
{
n %= mod;
return 1ll * n * inv4 % mod * n % mod * (n + 1) % mod * (n + 1) % mod;
}
inline int get_s_sum(int x)
{
if(x <= N - 7) return phi[x];
if(sum_f.find(x) != sum_f.end()) return sum_f[x];
ll ans = h_sum(x);
for(ll l = 2, r; l <= x; l = r + 1) {
r = x / (x / l);
ans = (ans - 1ll * (g_sum(r) - g_sum(l - 1) + mod) % mod * get_s_sum(x / l) % mod) % mod ;
}
return sum_f[x] = ans / g_sum(1);
}
void solve(int n)
{
ll ans = 0;
for(int l = 1, r; l <= n; l = r + 1) {
r = n / (n / l);
ans = (ans + (1ll * h_sum(n / l) * (get_s_sum(r) - get_s_sum(l - 1) + mod) % mod)) % mod;
}
printf("%lld\n", ans);
return ;
}
signed main()
{
scanf("%lld%lld", &mod, &n);
init(N - 7);
inv4 = qpow(4, mod - 2);
inv6 = qpow(6, mod - 2);
solve(n);
//cout << "ok" << endl;
return 0;
}
Problem B. Product(2019 ACM/ICPC 全國邀請賽(西安)B)
給定 n ( n ≤ 1 0 9 ) , m ( m ≤ 2 × 1 0 9 ) , p ( p ≤ 2 × 1 0 9 ) n ( n \le 10^9), m ( m \le 2 \times 10^9), p(p \le 2 \times 10^9) n(n≤109),m(m≤2×109),p(p≤2×109)
計算:
∏ i = 1 n ∏ j = 1 n ∏ k = 1 n m gcd ? ( i , j ) [ k ∣ gcd ? ( i , j ) ] \displaystyle \displaystyle\prod_{i = 1}^n \displaystyle\prod_{j = 1}^n \displaystyle\prod_{k = 1}^n m^{\gcd(i,j)[k|\gcd(i,j)]} i=1∏n?j=1∏n?k=1∏n?mgcd(i,j)[k∣gcd(i,j)]
Solution

Hint
res = (res + (1ll * (l + r) * (r - l + 1) / 2) % mod * ((1ll + x / l) * (x / l) / 2) % mod) % mod;//AC
res = (res + (1ll * (l + r) * (r - l + 1) / 2) % mod * (1ll + x / l) % mod * (x / l) / 2 % mod) % mod;//WA
想想看,^^(答案就是我腦子抽了 )
Time
O ( n + n 2 3 ) O(\sqrt n+n^{\frac 2 3}) O(n ?+n32?)
AC Code
#include <bits/stdc++.h>
using namespace std;
const int N = 5e6 + 6;
int mod;
#define int long long
#define mult(x, y) (1ll * x * y >= mod ? 1ll * x * y % mod : 1ll * x * y)
#define minus(x, y) (1ll * x - y < 0 ? 1ll * x - y + mod : 1ll * x - y)
#define plus(x, y) (1ll * x + y >= mod ? 1ll * x + y - mod : 1ll * x + y)
#define ck(x) (x >= mod : x - mod : x)
typedef long long ll;
ll n, m, p;
ll primes[N], cnt, num[N], d[N];
ll phi[N];
//ll sum[N];// x * d(x)
bool vis[N];
unordered_map<ll, ll> M_sum;
unordered_map<ll, ll> M_phi;
void init(ll n)
{
d[1] = 1;
phi[1] = 1;
for(ll i = 2; i <= n; ++ i) {
if(vis[i] == 0) {
primes[ ++ cnt] = i;
phi[i] = i - 1;
d[i] = 2, num[i] = 1;
}
for(ll j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[i * primes[j]] = true;
if(i % primes[j] == 0) {
phi[i * primes[j]] = phi[i] * primes[j];
num[i * primes[j]] = num[i] + 1;
d[i * primes[j]] = (d[i] / num[i * primes[j]] * (num[i * primes[j]] + 1)) % mod;
break;
}
phi[i * primes[j]] = phi[i] * (primes[j] - 1);
num[i * primes[j]] = 1;
d[i * primes[j]] = (d[i] * 2) % mod;
}
}
for(ll i = 1; i <= n; ++ i) {
phi[i] = (phi[i] + phi[i - 1]) % mod;
d[i] = d[i] * i % mod;
d[i] = (d[i] + d[i - 1]) % mod;
}
}
ll qpow(ll a, ll b, ll mod)
{
ll res = 1;
while(b) {
if(b & 1) res = res * a % mod;
a = a * a % mod;
b >>= 1;
}
return res;
}
inline int g_sum(int x)
{
return x;
}
inline ll get_sum_phi(int x)
{
if(x <= N - 7)return phi[x];
if(M_phi[x]) return M_phi[x];
ll ans = mult(x, (1ll * x + 1) / 2);
ll res = 0;
for(ll l = 2, r; l <= x; l = r + 1) {
r = x / (x / l);
res = plus(res, 1ll * (g_sum(r) - g_sum(l - 1)) * get_sum_phi(x / l)) % mod;
}
return M_phi[x] = minus(ans, res) % mod;
}
inline ll get_sum_sum(ll x)
{
if(x <= N - 7) return d[x];
if(M_sum[x]) return M_sum[x];
ll res = 0;
for(ll l = 1, r; l <= x; l = r + 1) {
r = x / (x / l);
//\sum_k=l^r = 平均值乘上長度 (公差為1的等引數列)
res = (res + (1ll * (l + r) * (r - l + 1) / 2) % mod * ((1ll + x / l) * (x / l) / 2) % mod) % mod;//AC
//res = (res + (1ll * (l + r) * (r - l + 1) / 2) % mod * (1ll + x / l) % mod * (x / l) / 2 % mod) % mod;//WA
}
return M_sum[x] = res;
}
signed main()
{
scanf("%lld%lld%lld", &n, &m, &p);
mod = p - 1;
init(N - 7);
ll ans = 0;
for(ll l = 1, r; l <= n; l = r + 1) {
r = n / (n / l);
ans = plus(ans, 1ll * get_sum_phi(n / l) * minus(get_sum_sum(r), get_sum_sum(l - 1)) % mod) % mod;
}
ans = plus(ans, ans) % mod;
ans = minus(ans, get_sum_sum(n));
printf("%lld\n", qpow(m, ans, p) % p);
return 0;
}
Problem C. Grisaia(2018ACM四川省賽G)
計算:
a n s = ∑ i = 1 n ∑ j = 1 i ( n m o d ( i × j ) ) ans =\sum^n_{i=1}\sum^i_{j=1} (n\ mod (i \times j)) ans=i=1∑n?j=1∑i?(n mod(i×j))
其中 T ≤ 5 , n ≤ 1 0 11 T\le 5, n\le 10^{11} T≤5,n≤1011
Solution
使用模的展開式將上述和式展開后,顯然套路列舉 k = i × j k=i\times j k=i×j,由于 n ≤ 1 0 11 n\le10^{11} n≤1011,杜教篩即可,
篩出:
f ( x ) = x × d ( x ) g ( x ) = x × μ ( x ) f(x)=x\times d(x)\\g(x)=x \times \mu(x) f(x)=x×d(x)g(x)=x×μ(x)
然后整除分塊即可,
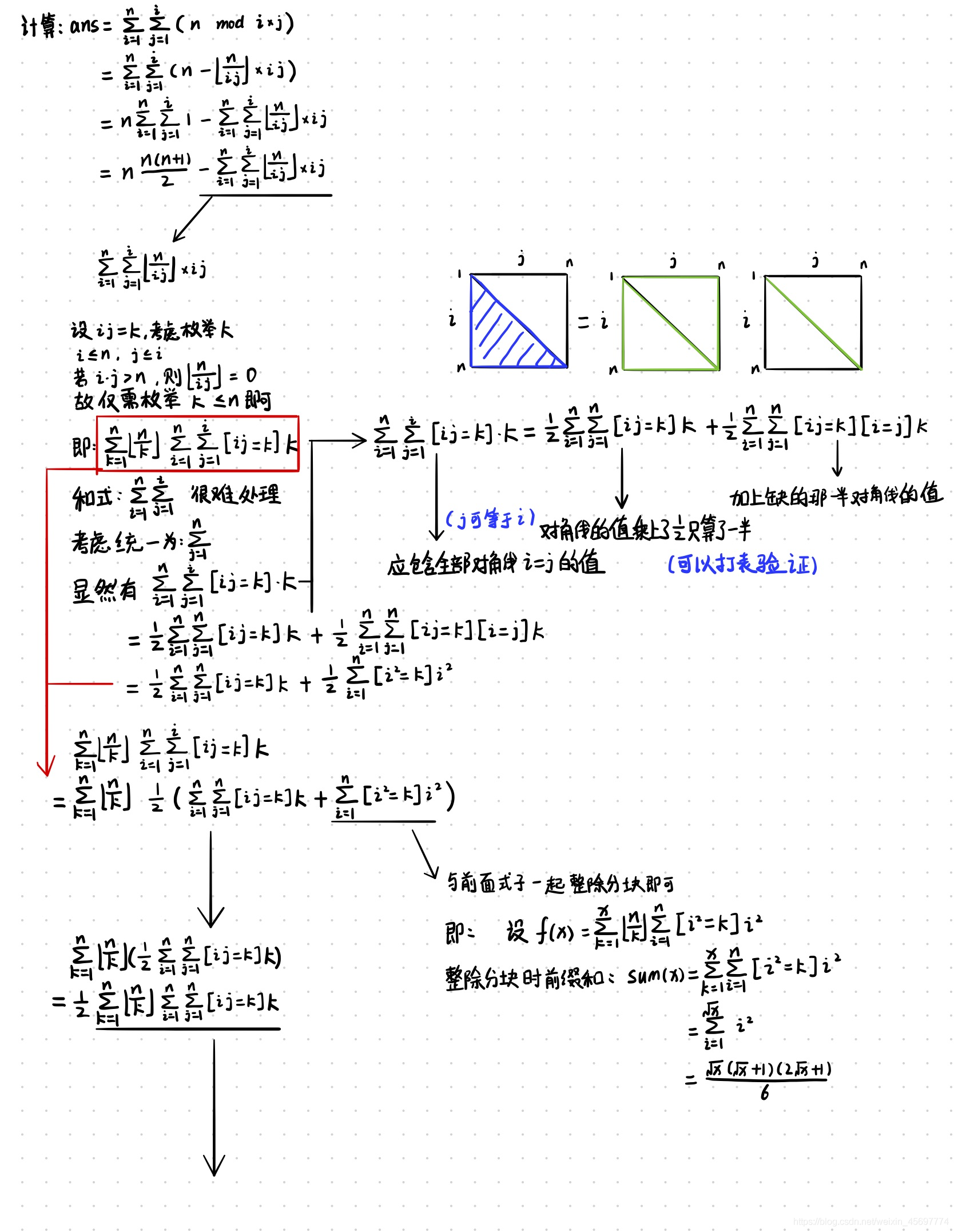

Hint
注意
n
≤
1
0
11
n\le10^{11}
n≤1011,中間多處會爆 long long,強轉成 __int128 即可,
Code
#include <bits/stdc++.h>
using namespace std;
#define int long long
#define ll __int128
const int N = 31644346;
int n, m;
int mu[N];
int primes[N], cnt;
int d[N];
int num[N];
unordered_map<int, ll> sum_mui;
unordered_map<int, ll> sum_dk;
bool vis[N];
int sum[N];
inline ll read()
{
register ll x = 0,f = 1;
char c = getchar();
while(c < '0' || c > '9') {if(c == '-') f = -1;c = getchar();}
while(c >= '0' && c <= '9') x = x * 10 + c-48,c = getchar();
return x * f;
}
inline void print(ll x)
{
if(x < 10)
{
putchar(x + 48);
return;
}
print(x / 10), print(x % 10);
}
void init(int n)
{
vis[0] = vis[1] = 1;
mu[1] = d[1] = 1;
for(int i = 2; i <= n; ++ i) {
if(vis[i] == 0) {
primes[ ++ cnt] = i;
mu[i] = -1;
d[i] = 2 * i;
num[i] = 1;
}
for(int j = 1; j <= cnt && i * primes[j] <= n; ++ j) {
vis[i * primes[j]] = 1;
if(i % primes[j] == 0) {
mu[i * primes[j]] = 0;
num[i * primes[j]] = num[i] + 1;
d[i * primes[j]] = (ll)d[i] / num[i * primes[j]] * (num[i * primes[j]] + 1) * primes[j];
break;
}
mu[i * primes[j]] -= mu[i];
num[i * primes[j]] = 1;
d[i * primes[j]] = d[i] * d[primes[j]];
}
}
for(int i = 1; i <= n; ++ i) {
sum[i] = sum[i - 1] + mu[i] * i;
d[i] = d[i - 1] + d[i];
}
}
inline ll get_sum_mui(int x)
{
if(x <= N - 7) return sum[x];
if(sum_mui.find(x) != sum_mui.end()) return sum_mui[x];
ll ans = 1;
for(ll l = 2, r; l <= x; l = r + 1) {
r = x / (x / l);
ans -= (ll)(r - l + 1) * (l + r) / 2 * get_sum_mui(x / l);
}
return sum_mui[x] = ans;
}
inline ll get_sum_dk(ll x)
{
if(x <= N - 7) return d[x];
if(sum_dk.find(x) != sum_dk.end()) return sum_dk[x];
ll ans = x * (x + 1) / 2;
for(ll l = 2, r; l <= x; l = r + 1) {
r = x / (x / l);
ans -= (ll)(get_sum_mui(r) - get_sum_mui(l - 1)) * get_sum_dk(x / l);
}
return sum_dk[x] = ans;
}
ll cal(ll x)
{
ll limit = sqrt(x + 0.99);
ll more = limit * (limit + 1) * (2 * limit + 1) / 6;
return (get_sum_dk(x) + more) / 2;
}
void solve()
{
ll ans = (ll)n * n * (n + 1) / 2;
for(ll l = 1, r; l <= n; l = r + 1) {
r = n / (n / l);
//cout << "ok" << cal(r) - cal(l - 1) * (n / l) << endl;
ans -= (ll)(cal(r) - cal(l - 1)) * (n / l);
}
print(ans);
puts("");
}
signed main()
{
int t;
init(N - 7);
t = read();
while(t -- ) {
n = read();
solve();
}
return 0;
}
0x53 Min_25篩
Min_25篩的博客實在是太難寫了,所以就直接摘抄OI-Wiki的講解吧>_<
author: Marcythm, Xeonacid
link: https://oiwiki.org/math/number-theory/min-25/
由于其由 Min_25 發明并最早開始使用,故稱「Min_25 篩」,
從此種篩法的思想方法來說,其又被稱為「Extended Eratosthenes Sieve」,
其可以在 O ( n 3 4 log ? n ) O\left(\frac{n^{\frac{3}{4}}}{\log{n}}\right) O(lognn43??) 或 Θ ( n 1 ? ? ) \Theta\left(n^{1 - \epsilon}\right) Θ(n1??) 的時間復雜度下解決一類 積性函式 的前綴和問題,
要求: f ( p ) f(p) f(p) 是一個關于 p p p 的項數較少的多項式或可以快速求值; f ( p c ) f(p^{c}) f(pc) 可以快速求值,
??
記號
??
- 如無特別說明,本節中所有記為 p p p 的變數的取值集合均為全體質數,
- x / y : = ? x y ? x / y := \left\lfloor\frac{x}{y}\right\rfloor x/y:=?yx??
- isprime ? ( n ) : = [ ∣ { d : d ∣ n } ∣ = 2 ] \operatorname{isprime}(n) := [ |\{d : d \mid n\}| = 2 ] isprime(n):=[∣{d:d∣n}∣=2],即 n n n 為質數時其值為 1 1 1,否則為 0 0 0,
- p k p_{k} pk?:全體質數中第 k k k 小的質數(如: p 1 = 2 , p 2 = 3 p_{1} = 2, p_{2} = 3 p1?=2,p2?=3),特別地,令 p 0 = 1 p_{0} = 1 p0?=1,
- lpf ? ( n ) : = [ 1 < n ] min ? { p : p ∣ n } + [ 1 = n ] \operatorname{lpf}(n) := [1 < n] \min\{p : p \mid n\} + [1 = n] lpf(n):=[1<n]min{p:p∣n}+[1=n],即 n n n 的最小質因數,特別地, n = 1 n=1 n=1 時,其值為 1 1 1,
- F p r i m e ( n ) : = ∑ 2 ≤ p ≤ n f ( p ) F_{\mathrm{prime}}(n) := \sum_{2 \le p \le n} f(p) Fprime?(n):=∑2≤p≤n?f(p)
- F k ( n ) : = ∑ i = 2 n [ p k ≤ lpf ? ( i ) ] f ( i ) F_{k}(n) := \sum_{i = 2}^{n} [p_{k} \le \operatorname{lpf}(i)] f(i) Fk?(n):=∑i=2n?[pk?≤lpf(i)]f(i)
??
具體方法
??觀察 F k ( n ) F_{k}(n) Fk?(n) 的定義,可以發現答案即為 F 1 ( n ) + f ( 1 ) = F 1 ( n ) + 1 F_{1}(n) + f(1) = F_{1}(n) + 1 F1?(n)+f(1)=F1?(n)+1,
考慮如何求出 F k ( n ) F_{k}(n) Fk?(n),通過列舉每個 i i i 的最小質因子及其次數可以得到遞推式:
F k ( n ) = ∑ i = 2 n [ p k ≤ lpf ? ( i ) ] f ( i ) = ∑ k ≤ i ∑ c ≥ 1 p i 2 ≤ n f ( p i c ) ( [ c > 1 ] + F i + 1 ( n / p i c ) ) + ∑ k ≤ i p i ≤ n f ( p i ) = ∑ k ≤ i ∑ c ≥ 1 p i 2 ≤ n f ( p i c ) ( [ c > 1 ] + F i + 1 ( n / p i c ) ) + F prime ( n ) ? F prime ( p k ? 1 ) = ∑ k ≤ i p i 2 ≤ n ∑ c ≥ 1 p i c + 1 ≤ n ( f ( p i c ) F i + 1 ( n / p i c ) + f ( p i c + 1 ) ) + F prime ( n ) ? F prime ( p k ? 1 ) \begin{aligned}F_{k}(n) &=\sum_{i=2}^{n}\left[p_{k} \leq \operatorname{lpf}(i)\right] f(i) \\&=\sum_{k \leq i} \sum_{c \geq 1 \atop p_{i}^{2} \leq n} f\left(p_{i}^{c}\right)\left([c>1]+F_{i+1}\left(n / p_{i}^{c}\right)\right)+\sum_{k \leq i \atop p_{i} \leq n} f\left(p_{i}\right) \\&=\sum_{k \leq i} \sum_{c \geq 1 \atop p_{i}^{2} \leq n} f\left(p_{i}^{c}\right)\left([c>1]+F_{i+1}\left(n / p_{i}^{c}\right)\right)+F_{\text {prime }}(n)-F_{\text {prime }}\left(p_{k-1}\right) \\&=\sum_{k \leq i \atop p_{i}^{2} \leq n} \sum_{c \geq 1 \atop p_{i}^{c+1} \leq n}\left(f\left(p_{i}^{c}\right) F_{i+1}\left(n / p_{i}^{c}\right)+f\left(p_{i}^{c+1}\right)\right)+F_{\text {prime }}(n)-F_{\text {prime }}\left(p_{k-1}\right)\end{aligned} Fk?(n)?=i=2∑n?[pk?≤lpf(i)]f(i)=k≤i∑?pi2?≤nc≥1?∑?f(pic?)([c>1]+Fi+1?(n/pic?))+pi?≤nk≤i?∑?f(pi?)=k≤i∑?pi2?≤nc≥1?∑?f(pic?)([c>1]+Fi+1?(n/pic?))+Fprime ?(n)?Fprime ?(pk?1?)=pi2?≤nk≤i?∑?pic+1?≤nc≥1?∑?(f(pic?)Fi+1?(n/pic?)+f(pic+1?))+Fprime ?(n)?Fprime ?(pk?1?)?
最后一步推導基于這樣一個事實:對于滿足 p i c ≤ n < p i c + 1 p_{i}^{c} \le n < p_{i}^{c + 1} pic?≤n<pic+1? 的 c c c,有 p i c + 1 > n ?? ? ?? n / p i c < p i < p i + 1 p_{i}^{c + 1} > n \iff n / p_{i}^{c} < p_{i} < p_{i + 1} pic+1?>n?n/pic?<pi?<pi+1?,故 F i + 1 ( n / p i c ) = 0 F_{i + 1}\left(n / p_{i}^{c}\right) = 0 Fi+1?(n/pic?)=0, 其邊界值即為 F k ( n ) = 0 ( p k > n ) F_{k}(n) = 0 (p_{k} > n) Fk?(n)=0(pk?>n),
假設現在已經求出了所有的 F p r i m e ( n ) F_{\mathrm{prime}}(n) Fprime?(n),那么有兩種方式可以求出所有的 F k ( n ) F_{k}(n) Fk?(n):
- 直接按照遞推式計算,
- 從大到小列舉 p p p 轉移,僅當 p 2 < n p^{2} < n p2<n 時轉移增加值不為零,故按照遞推式后綴和優化即可,
現在考慮如何計算 F p r i m e ( n ) F_{\mathrm{prime}}{(n)} Fprime?(n), 觀察求 F k ( n ) F_{k}(n) Fk?(n) 的程序,容易發現 F p r i m e F_{\mathrm{prime}} Fprime? 有且僅有 1 , 2 , … , ? n ? , n / n , … , n / 2 , n 1, 2, \dots, \left\lfloor\sqrt{n}\right\rfloor, n / \sqrt{n}, \dots, n / 2, n 1,2,…,?n ??,n/n ?,…,n/2,n 這 O ( n ) O(\sqrt{n}) O(n ?) 處的點值是有用的, 一般情況下, f ( p ) f(p) f(p) 是一個關于 p p p 的低次多項式,可以表示為 f ( p ) = ∑ a i p c i f(p) = \sum a_{i} p^{c_{i}} f(p)=∑ai?pci?, 那么對于每個 p c i p^{c_{i}} pci?,其對 F p r i m e ( n ) F_{\mathrm{prime}}(n) Fprime?(n) 的貢獻即為 a i ∑ 2 ≤ p ≤ n p c i a_{i} \sum_{2 \le p \le n} p^{c_{i}} ai?∑2≤p≤n?pci?, 分開考慮每個 p c i p^{c_{i}} pci? 的貢獻,問題就轉變為了:給定 n , s , g ( p ) = p s n, s, g(p) = p^{s} n,s,g(p)=ps,對所有的 m = n / i m = n / i m=n/i,求 ∑ p ≤ m g ( p ) \sum_{p \le m} g(p) ∑p≤m?g(p),
Notice: g ( p ) = p s g(p) = p^{s} g(p)=ps 是完全積性函式!
于是設 G k ( n ) : = ∑ i = 1 n [ p k < lpf ? ( i ) ∨ isprime ? ( i ) ] g ( i ) G_{k}(n) := \sum_{i = 1}^{n} \left[p_{k} < \operatorname{lpf}(i) \lor \operatorname{isprime}(i)\right] g(i) Gk?(n):=∑i=1n?[pk?<lpf(i)∨isprime(i)]g(i),即埃篩第 k k k 輪篩完后剩下的數的 g g g 值之和, 對于一個合數 x x x,必定有 lpf ? ( x ) ≤ x \operatorname{lpf}(x) \le \sqrt{x} lpf(x)≤x ?,則 F p r i m e = G ? n ? F_{\mathrm{prime}} = G_{\left\lfloor\sqrt{n}\right\rfloor} Fprime?=G?n ???,故只需篩到 G ? n ? G_{\left\lfloor\sqrt{n}\right\rfloor} G?n ??? 即可, 考慮 G G G 的邊界值,顯然為 G 0 ( n ) = ∑ i = 2 n g ( i ) G_{0}(n) = \sum_{i = 2}^{n} g(i) G0?(n)=∑i=2n?g(i),(還記得嗎?特別約定了 p 0 = 1 p_{0} = 1 p0?=1) 對于轉移,考慮埃篩的程序,分開討論每部分的貢獻,有:
- 對于 n < p k 2 n < p_{k}^{2} n<pk2? 的部分, G G G 值不變,即 G k ( n ) = G k ? 1 ( n ) G_{k}(n) = G_{k - 1}(n) Gk?(n)=Gk?1?(n),
- 對于 p k 2 ≤ n p_{k}^{2} \le n pk2?≤n 的部分,被篩掉的數必有質因子 p k p_{k} pk?,即 ? g ( p k ) G k ? 1 ( n / p k ) -g(p_{k}) G_{k - 1}(n / p_{k}) ?g(pk?)Gk?1?(n/pk?),
- 對于第二部分,由于 p k 2 ≤ n ?? ? ?? p k ≤ n / p k p_{k}^{2} \le n \iff p_{k} \le n / p_{k} pk2?≤n?pk?≤n/pk?,故會有 lpf ? ( i ) < p k \operatorname{lpf}(i) < p_{k} lpf(i)<pk? 的 i i i 被減去,這部分應當加回來,即 g ( p k ) G k ? 1 ( p k ? 1 ) g(p_{k}) G_{k - 1}(p_{k - 1}) g(pk?)Gk?1?(pk?1?),
則有:
G k ( n ) = G k ? 1 ( n ) ? [ p k 2 ≤ n ] g ( p k ) ( G k ? 1 ( n / p k ) ? G k ? 1 ( p k ? 1 ) ) G_{k}(n) = G_{k - 1}(n) - \left[p_{k}^{2} \le n\right] g(p_{k}) (G_{k - 1}(n / p_{k}) - G_{k - 1}(p_{k - 1})) Gk?(n)=Gk?1?(n)?[pk2?≤n]g(pk?)(Gk?1?(n/pk?)?Gk?1?(pk?1?))
??
復雜度分析
??對于 F k ( n ) F_{k}(n) Fk?(n) 的計算,其第一種方法的時間復雜度被證明為 O ( n 1 ? ? ) O\left(n^{1 - \epsilon}\right) O(n1??)(見 zzt 集訓隊論文 2.3); 對于第二種方法,其本質即為洲閣篩的第二部分,在洲閣論文中也有提及(6.5.4),其時間復雜度被證明為
O ( n 3 4 log ? n ) O\left(\frac{n^{\frac{3}{4}}}{\log{n}}\right) O(lognn43??),
對于 F p r i m e ( n ) F_{\mathrm{prime}}(n) Fprime?(n) 的計算,事實上,其實作與洲閣篩第一部分是相同的, 考慮對于每個 m = n / i m = n / i m=n/i,只有在列舉滿足 p k 2 ≤ m p_{k}^{2} \le m pk2?≤m 的 p k p_{k} pk? 轉移時會對時間復雜度產生貢獻,則時間復雜度可估計為:T ( n ) = ∑ i 2 ≤ n O ( π ( i ) ) + ∑ i 2 ≤ n O ( π ( n i ) ) = ∑ i 2 ≤ n O ( i ln ? i ) + ∑ i 2 ≤ n O ( n i ln ? n i ) = O ( ∫ 1 n n x log ? n x d x ) = O ( n 3 4 log ? n ) \begin{aligned} T(n) &= \sum_{i^{2} \le n} O\left(\pi\left(\sqrt{i}\right)\right) + \sum_{i^{2} \le n} O\left(\pi\left(\sqrt{\frac{n}{i}}\right)\right) \\ &= \sum_{i^{2} \le n} O\left(\frac{\sqrt{i}}{\ln{\sqrt{i}}}\right) + \sum_{i^{2} \le n} O\left(\frac{\sqrt{\frac{n}{i}}}{\ln{\sqrt{\frac{n}{i}}}}\right) \\ &= O\left(\int_{1}^{\sqrt{n}} \frac{\sqrt{\frac{n}{x}}}{\log{\sqrt{\frac{n}{x}}}} \mathrm{d} x\right) \\ &= O\left(\frac{n^{\frac{3}{4}}}{\log{n}}\right) \end{aligned} T(n)?=i2≤n∑?O(π(i ?))+i2≤n∑?O(π(in? ?))=i2≤n∑?O(lni ?i ??)+i2≤n∑?O(lnin? ?in? ??)=O(∫1n ??logxn? ?xn? ??dx)=O(lognn43??)?
對于空間復雜度,可以發現不論是 F k F_{k} Fk? 還是 F p r i m e F_{\mathrm{prime}} Fprime?,其均只在 n / i n / i n/i 處取有效點值,共 O ( n ) O(\sqrt{n}) O(n ?) 個,僅記錄有效值即可將空間復雜度優化至 O ( n ) O(\sqrt{n}) O(n ?),
首先,通過一次數論分塊可以得到所有的有效值,用一個大小為 O ( n ) O(\sqrt{n}) O(n ?) 的陣列 lis \text{lis} lis 記錄,對于有效值 v v v,記 id ( v ) \text{id}(v) id(v) 為 v v v 在 lis \text{lis} lis 中的下標,易得:對于所有有效值
v v v, id ( v ) ≤ n \text{id}(v) \le \sqrt{n} id(v)≤n ?,然后分開考慮小于等于 n \sqrt{n} n ? 的有效值和大于 n \sqrt{n} n ? 的有效值:對于小于等于 n \sqrt{n} n ? 的有效值 v v v,用一個陣列 le \text{le} le 記錄其 id ( v ) \text{id}(v) id(v),即 le v = id ( v ) \text{le}_v = \text{id}(v) lev?=id(v);對于大于 n \sqrt{n} n ? 的有效值 v v v,用一個陣列 ge \text{ge} ge 記錄
id ( v ) \text{id}(v) id(v),由于 v v v 過大所以借助 v ′ = n / v < n v^\prime = n / v < \sqrt{n} v′=n/v<n ? 記錄
id ( v ) \text{id}(v) id(v),即 ge v ′ = id ( v ) \text{ge}_{v^\prime} = \text{id}(v) gev′?=id(v),這樣,就可以使用兩個大小為 O ( n ) O(\sqrt{n}) O(n ?) 的陣列記錄所有有效值的 id \text{id} id 并 O ( 1 ) O(1) O(1) 查詢,在計算> F k F_{k} Fk? 或 F p r i m e F_{\mathrm{prime}} Fprime? 時,使用有效值的 id \text{id} id 代替有效值作為下標,即可將空間復雜度優化至 O ( n ) O(\sqrt{n}) O(n ?),
??
有關代碼實作
??對于 F k ( n ) F_{k}(n) Fk?(n) 的計算,我們實作時一般選擇實作難度較低的第一種方法,其在資料規模較小時往往比第二種方法的表現要好;
對于 F p r i m e ( n ) F_{\mathrm{prime}}(n) Fprime?(n) 的計算,直接按遞推式實作即可,
對于 p k 2 ≤ n p_{k}^{2} \le n pk2?≤n,可以用線性篩預處理出 s k : = F p r i m e ( p k ) s_{k} := F_{\mathrm{prime}}(p_{k}) sk?:=Fprime?(pk?) 來替代 F k F_{k} Fk? 遞推式中的 F p r i m e ( p k ? 1 ) F_{\mathrm{prime}}(p_{k - 1}) Fprime?(pk?1?), 相應地, G G G 遞推式中的 G k ? 1 ( p k ? 1 ) = ∑ i = 1 k ? 1 g ( p i ) G_{k - 1}(p_{k - 1}) = \sum_{i = 1}^{k - 1} g(p_{i}) Gk?1?(pk?1?)=∑i=1k?1?g(pi?) 也可以用此方法預處理,
用 Extended Eratosthenes Sieve 求 積性函式 f f f 的前綴和時,應當明確以下幾點:
- 如何快速(一般是線性時間復雜度)篩出前 n \sqrt{n} n ? 個 f f f 值;
- f ( p ) f(p) f(p) 的多項式表示;
- 如何快速求出 f ( p c ) f(p^{c}) f(pc),
明確上述幾點之后按順序實作以下幾部分即可:
- 篩出 [ 1 , n ] [1, \sqrt{n}] [1,n ?] 內的質數與前 n \sqrt{n} n ? 個 f f f 值;
- 對 f ( p ) f(p) f(p) 多項式表示中的每一項篩出對應的 G G G,合并得到 F p r i m e F_{\mathrm{prime}} Fprime? 的所有 O ( n ) O(\sqrt{n}) O(n ?) 個有用點值;
- 按照 F k F_{k} Fk? 的遞推式實作遞回,求出 F 1 ( n ) F_{1}(n) F1?(n),
??
例題
??
??
求莫比烏斯函式的前綴和
??求 ∑ i = 1 n μ ( i ) \displaystyle \sum_{i = 1}^{n} \mu(i) i=1∑n?μ(i),
易知 f ( p ) = ? 1 f(p) = -1 f(p)=?1,則 g ( p ) = ? 1 , G 0 ( n ) = ∑ i = 2 n g ( i ) = ? n + 1 g(p) = -1, G_{0}(n) = \sum_{i = 2}^{n} g(i) = -n + 1 g(p)=?1,G0?(n)=∑i=2n?g(i)=?n+1, 直接篩即可得到 F p r i m e F_{\mathrm{prime}} Fprime? 的所有 O ( n ) O(\sqrt{n}) O(n ?) 個所需點值,
??
求歐拉函式的前綴和
??求 ∑ i = 1 n φ ( i ) \displaystyle \sum_{i = 1}^{n} \varphi(i) i=1∑n?φ(i),
首先易知 f ( p ) = p ? 1 f(p) = p - 1 f(p)=p?1, 對于 f ( p ) f(p) f(p) 的一次項 ( p ) (p) (p),有 g ( p ) = p , G 0 ( n ) = ∑ i = 2 n g ( i ) = ( n + 2 ) ( n ? 1 ) 2 g(p) = p, G_{0}(n) = \sum_{i = 2}^{n} g(i) = \frac{(n + 2) (n - 1)}{2} g(p)=p,G0?(n)=∑i=2n?g(i)=2(n+2)(n?1)?; 對于 f ( p ) f(p) f(p) 的常數項
( ? 1 ) (-1) (?1),有 g ( p ) = ? 1 , G 0 ( n ) = ∑ i = 2 n g ( i ) = ? n + 1 g(p) = -1, G_{0}(n) = \sum_{i = 2}^{n} g(i) = -n + 1 g(p)=?1,G0?(n)=∑i=2n?g(i)=?n+1,
篩兩次加起來即可得到 F p r i m e F_{\mathrm{prime}} Fprime? 的所有 O ( n ) O(\sqrt{n}) O(n ?) 個所需點值,
??
「LOJ #6053」簡單的函式
??給定 f ( n ) f(n) f(n):
f ( n ) = { 1 n = 1 p xor ? c n = p c f ( a ) f ( b ) n = a b ∧ a ⊥ b f(n) = \begin{cases} 1 & n = 1 \\ p \operatorname{xor} c & n = p^{c} \\ f(a)f(b) & n = ab \land a \perp b \end{cases} f(n)=??????1pxorcf(a)f(b)?n=1n=pcn=ab∧a⊥b?
易知 f ( p ) = p ? 1 + 2 [ p = 2 ] f(p) = p - 1 + 2[p = 2] f(p)=p?1+2[p=2],則按照篩 φ \varphi φ 的方法篩,對 2 2 2 討論一下即可,
此處給出一種 C++ 實作:#include <algorithm> #include <cmath> #include <cstdio> const int maxs = 200000; // 2sqrt(n) const int mod = 1000000007; template <typename x_t, typename轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/342265.html
標籤:其他
下一篇:演算法開啟小碼農堆疊血脈
- 標籤雲
-
其他(157675) Python(38076) JavaScript(25376) Java(17977) C(15215) 區塊鏈(8255) C#(7972) AI(7469) 爪哇(7425) MySQL(7132) html(6777) 基礎類(6313) sql(6102) 熊猫(6058) PHP(5869) 数组(5741) R(5409) Linux(5327) 反应(5209) 腳本語言(PerlPython)(5129) 非技術區(4971) Android(4554) 数据框(4311) css(4259) 节点.js(4032) C語言(3288) json(3245) 列表(3129) 扑(3119) C++語言(3117) 安卓(2998) 打字稿(2995) VBA(2789) Java相關(2746) 疑難問題(2699) 细绳(2522) 單片機工控(2479) iOS(2429) ASP.NET(2402) MongoDB(2323) 麻木的(2285) 正则表达式(2254) 字典(2211) 循环(2198) 迅速(2185) 擅长(2169) 镖(2155) 功能(1967) .NET技术(1958) Web開發(1951) python-3.x(1918) HtmlCss(1915) 弹簧靴(1913) C++(1909) xml(1889) PostgreSQL(1872) .NETCore(1853) 谷歌表格(1846) Unity3D(1843) for循环(1842)
- 熱門瀏覽
-
-
面試突擊第一季,第二季,第三季
第一季必考 https://www.bilibili.com/video/BV1FE411y79Y?from=search&seid=15921726601957489746 第二季分布式 https://www.bilibili.com/video/BV13f4y127ee/?spm_id_fro ......
uj5u.com 2020-09-10 05:35:24 more -
北航OO(2020)第四單元博客作業暨課程總結博客
北航OO(2020)第四單元博客作業暨課程總結博客 本單元作業的架構設計 在本單元中,由于UML圖具有比較清晰的樹形結構,因此我對其中需要進行查詢操作的元素進行了包裝,在樹的父節點中存盤所有孩子的參考。考慮到性能問題,我采用了快取機制,一次查詢后盡可能快取已經遍歷過的資訊,以減少遍歷次數。 本單元我 ......
uj5u.com 2020-09-10 05:35:48 more -
BUAA_OO_第四單元
一、UML決議器設計 ? 先看下題目:第四單元實作一個基于JDK 8帶有效性檢查的UML(Unified Modeling Language)類圖,順序圖,狀態圖分析器 MyUmlInteraction,實際上我們要建立一個有向圖模型,UML中的物件(元素)可能與同級元素連接,也可與低級元素相連形成 ......
uj5u.com 2020-09-10 05:35:54 more -
BUAAOO 第四單元 & 課程總結
1. 第四單元:StarUml檔案決議 本單元采用了圖模型決議UML。 UML檔案可以抽象為圖、子圖、邊的邏輯結構。 在實作中,圖的節點包括類、介面、屬性,子圖包括狀態圖、順序圖等。 采用了三次遍歷UML元素的方法建圖,第一遍遍歷建點,第二、三次遍歷設定屬性、連邊,實作圖物件的初始化。這里借鑒了一些 ......
uj5u.com 2020-09-10 05:36:06 more -
談談我對C# 多型的理解
面向物件三要素:封裝、繼承、多型。 封裝和繼承,這兩個比較好理解,但要理解多型的話,可就稍微有點難度了。今天,我們就來講講多型的理解。 我們應該經常會看到面試題目:請談談對多型的理解。 其實呢,多型非常簡單,就一句話:呼叫同一種方法產生了不同的結果。 具體實作方式有三種。 一、多載 多載很簡單。 p ......
uj5u.com 2020-09-10 05:36:09 more -
Python 資料驅動工具:DDT
背景 python 的unittest 沒有自帶資料驅動功能。 所以如果使用unittest,同時又想使用資料驅動,那么就可以使用DDT來完成。 DDT是 “Data-Driven Tests”的縮寫。 資料:http://ddt.readthedocs.io/en/latest/ 使用方法 dd. ......
uj5u.com 2020-09-10 05:36:13 more -
Python里面的xlrd模塊詳解
那我就一下面積個問題對xlrd模塊進行學習一下: 1.什么是xlrd模塊? 2.為什么使用xlrd模塊? 3.怎樣使用xlrd模塊? 1.什么是xlrd模塊? ?python操作excel主要用到xlrd和xlwt這兩個庫,即xlrd是讀excel,xlwt是寫excel的庫。 今天就先來說一下xl ......
uj5u.com 2020-09-10 05:36:28 more -
當我們創建HashMap時,底層到底做了什么?
jdk1.7中的底層實作程序(底層基于陣列+鏈表) 在我們new HashMap()時,底層創建了默認長度為16的一維陣列Entry[ ] table。當我們呼叫map.put(key1,value1)方法向HashMap里添加資料的時候: 首先,呼叫key1所在類的hashCode()計算key1 ......
uj5u.com 2020-09-10 05:36:38 more
-
- 最新发布
-
-
【中介者設計模式詳解】C/Java/JS/Go/Python/TS不同語言實作
* 中介者模式是一種行為型設計模式,它可以用來減少類之間的直接依賴關系,
uj5u.com 2023-04-20 08:20:47 more
* 將物件之間的通信封裝到一個中介者物件中,從而使得各個物件之間的關系更加松散。
* 在中介者模式中,物件之間不再直接相互互動,而是通過中介者來中轉訊息。 ...... -
露天煤礦現場調研和交流案例分享
他們集團的資訊化公司及研究院在一個礦區正在做智能礦山的統一平臺的 試點,專案投資大概1億,包括了礦山的各方面的內容,顯示得我們這次交流有點多余。他們2年前開始做智能礦山的規劃,有很多煤礦行業專家的加持,他們的描述是非常完美,但是去年底應該上線的平臺,現在還沒有看到影子。他們確實有很多場景需求,但是被... ......
uj5u.com 2023-04-20 08:20:25 more -
《社區人員管理》實戰案例設計&個人案例分享
設計是一個讓人夢想成真程序,開始編碼、測驗、除錯之前進行需求分析和架構設計,才能保證關鍵方面都做正確 ......
uj5u.com 2023-04-20 08:20:17 more -
軟體架構生態化-多角色交付的探索實踐
作為一個技術架構師,不僅僅要緊跟行業技術趨勢,還要結合研發團隊現狀及痛點,探索新的交付方案。在日常中,你是否遇到如下問題 “ 業務需求排期長研發是瓶頸;非研發角色感受不到研發技改提效的變化;引入ISV 團隊又擔心質量和安全,培訓周期長“等等,基于此我們探索了一種新的技術體系及交付方案來解決如上問題。 ......
uj5u.com 2023-04-20 08:20:10 more -
【中介者設計模式詳解】C/Java/JS/Go/Python/TS不同語言實作
* 中介者模式是一種行為型設計模式,它可以用來減少類之間的直接依賴關系,
uj5u.com 2023-04-20 08:19:44 more
* 將物件之間的通信封裝到一個中介者物件中,從而使得各個物件之間的關系更加松散。
* 在中介者模式中,物件之間不再直接相互互動,而是通過中介者來中轉訊息。 ...... -
露天煤礦現場調研和交流案例分享
他們集團的資訊化公司及研究院在一個礦區正在做智能礦山的統一平臺的 試點,專案投資大概1億,包括了礦山的各方面的內容,顯示得我們這次交流有點多余。他們2年前開始做智能礦山的規劃,有很多煤礦行業專家的加持,他們的描述是非常完美,但是去年底應該上線的平臺,現在還沒有看到影子。他們確實有很多場景需求,但是被... ......
uj5u.com 2023-04-20 08:19:07 more -
《社區人員管理》實戰案例設計&個人案例分享
設計是一個讓人夢想成真程序,開始編碼、測驗、除錯之前進行需求分析和架構設計,才能保證關鍵方面都做正確 ......
uj5u.com 2023-04-20 08:18:57 more -
軟體架構生態化-多角色交付的探索實踐
作為一個技術架構師,不僅僅要緊跟行業技術趨勢,還要結合研發團隊現狀及痛點,探索新的交付方案。在日常中,你是否遇到如下問題 “ 業務需求排期長研發是瓶頸;非研發角色感受不到研發技改提效的變化;引入ISV 團隊又擔心質量和安全,培訓周期長“等等,基于此我們探索了一種新的技術體系及交付方案來解決如上問題。 ......
uj5u.com 2023-04-20 08:18:49 more -
【架構與設計】常見微服務分層架構的區別和落地實踐
軟體工程的方方面面都遵循一個最基本的道理:沒有銀彈,架構分層模型更是如此,每一種都有各自優缺點,所以請根據不同的業務場景,并遵循簡單、可演進這兩個重要的架構原則選擇合適的架構分層模型即可。 ......
uj5u.com 2023-04-19 08:42:41 more
-
- 友情鏈接