我有一些看起來像這樣的資料:
date signs horoscope newspaper
<chr> <chr> <chr> <chr>
1 06-06-20~ ARIES Your week falls neatly into distinct phases. The completion o~ Indian Expr~
2 06-06-20~ TAURUS You're coming to the end of an emotional period, when you've ~ Indian Expr~
3 06-06-20~ GEMINI Passions are still running high, and the degree of emotional ~ Times of In~
4 06-06-20~ CANCER First things first - don't rush it! There is still a great de~ Indian Expr~
5 06-06-20~ LEO The greatest pressures are coming from all directions at once~ Indian Expr~
我想創建一個語料庫出這個資料,所有的horoscope被組合在一起newspaper,并signs為檔案。
例如,ARIES報紙上的所有內容都Times of India應該是一個檔案,但按時間順序排列(它們的索引應按日期排序)。
由于我不知道如何按newspaper和對文本進行分組signs,因此我嘗試為每份報紙創建兩個不同的語料庫。我試過這樣做:
# Create a dataframe of only Times of India text
h_toi <- horoscopes %>%
filter(newspaper == "Times of India") %>%
select(-c("newspaper"))
# Create a corpus of out this
horo_corp_toi <- corpus(h_toi, text_field = "horoscope")
# Create docids
docids <- paste(h_toi$signs)
# Use this as docnames
docnames(horo_corp_toi) <- docids
head(docnames(horo_corp_toi), 5)
# [1] "ARIES.1" "TAURUS.1" "GEMINI.1" "CANCER.1" "LEO.1"
但是正如你所看到的,docnames語料庫的"ARIES.1", `"TAURUS.1" 等等。這是一個問題,因為當我嘗試使用 quanteda 的
相反,我希望能夠做這樣的事情:
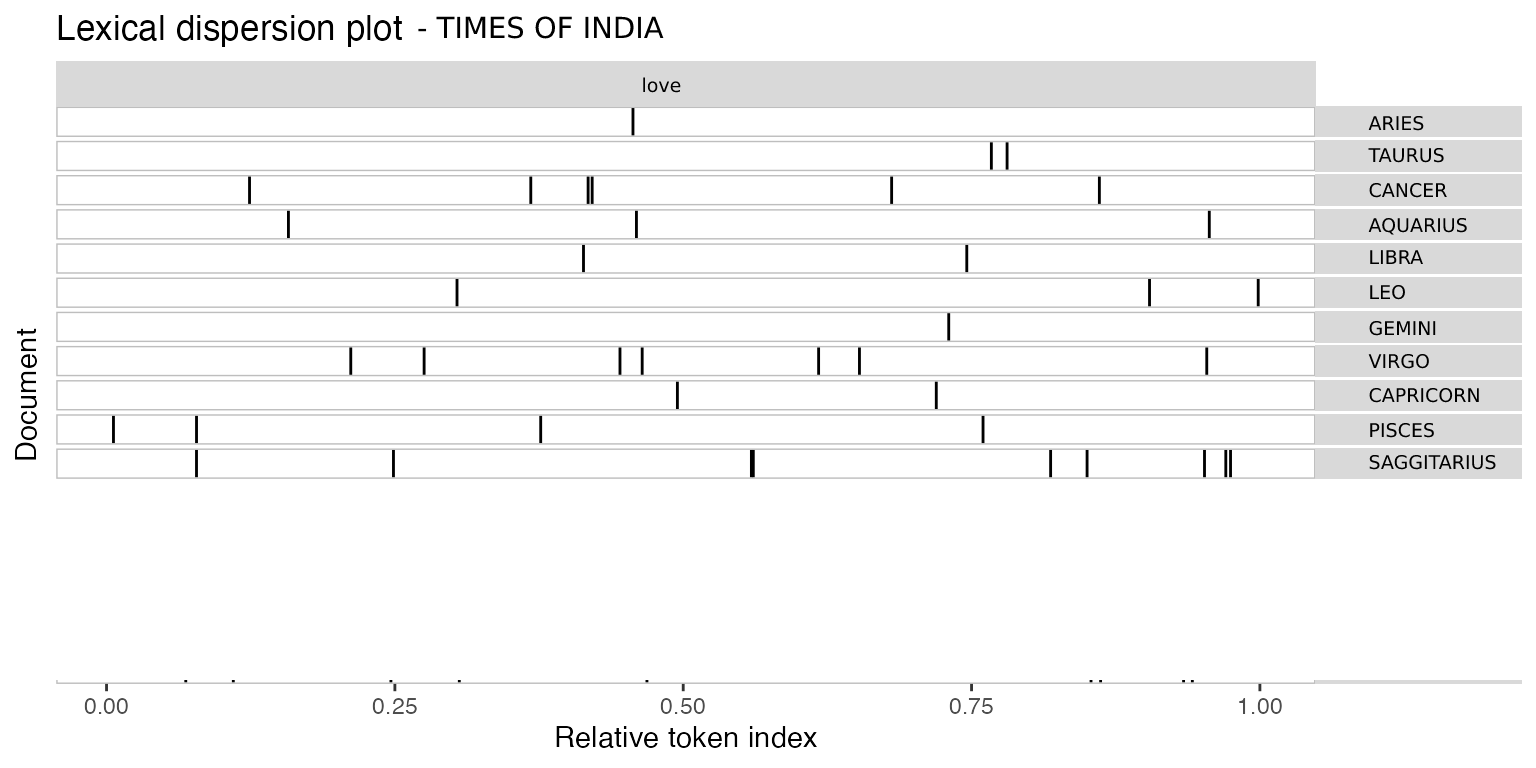
我無法獲得此可視化,因為我最初不知道如何操作和創建語料庫。我該怎么做,我做錯了什么?
示例 DPUT 在這里
uj5u.com熱心網友回復:
既然問題是問如何按標志和報紙分組,我先回答一下。
library("quanteda")
## Package version: 3.1.0
## Unicode version: 13.0
## ICU version: 69.1
## Parallel computing: 12 of 12 threads used.
## See https://quanteda.io for tutorials and examples.
library("quanteda.textplots")
## horoscopes <- [per linked dput in OP]
corp <- corpus(horoscopes, text_field = "horoscope")
toks <- tokens(corp)
# grouped by sign and newspaper
tokens_group(toks, groups = interaction(signs, newspaper)) %>%
kwic(pattern = "love") %>%
textplot_xray()
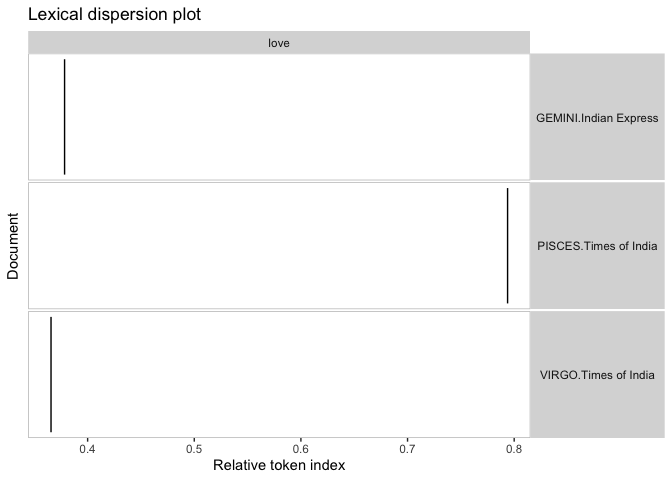
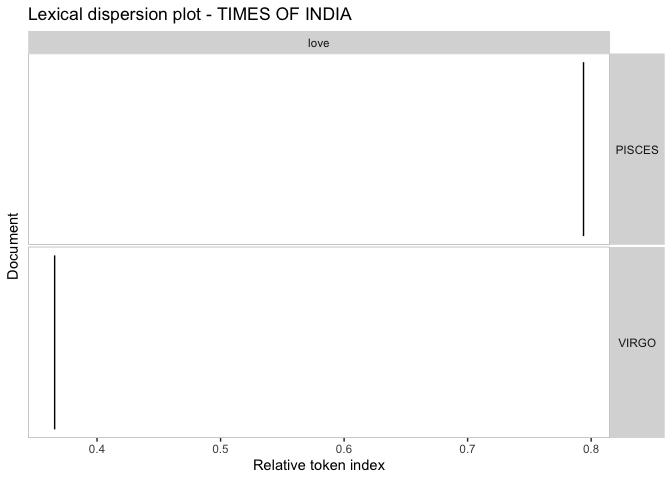
要實作上面的結果輸出(此處僅顯示最后一張影像),您可以遍歷報紙并僅按 分組signs。請注意,此處的星座數量有限,因為在提供的樣本資料中,并非所有生肖范圍都包含在資料中。
# separate kwic for each newspaper
for (i in unique(toks$newspaper)) {
thiskwic <- toks %>%
tokens_subset(newspaper == i) %>%
tokens_group(signs) %>%
kwic(pattern = "love")
textplot_xray(thiskwic)
ggplot2::ggtitle(paste("Lexical dispersion plot -", toupper(i)))
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/343674.html