一萬粉的時候,我爬光了我所有的粉絲,只為驗證一個事情
前言
CSDN 博客網站的粉絲增長和訪問增長是一件很離奇的事情,
如果你不發博客,粉絲幾乎零增長,你發了一篇文字數量充分多的博客之后的一兩天,會有一個粉絲量和訪問量的突變,然后一下又零增長了,你以為這些突變是你發的這單篇博文帶來的,但是我觀察到,這篇文章幾乎無訪問量,難道這篇文章會帶來別的文章訪問量增加呢?離奇!
曾經每增加 N 個粉絲,都有 k 個人跟你互動,但是通過 C 站推薦,獲得的 100N 個粉絲,卻不足 k 個人跟你互動,不符合大數定律,粉絲很離奇!
原來每日的閱讀量為 S,突然某一天,閱讀量突然變成了 S/2 不到,這個突變,不符合互聯網大背景下的自然市場規律,非常離奇!
……
基于以上的種種的離奇事件,我斗膽做出以下預測:
-
C 站官方“造”了很多機器僵尸粉或者直接利用了主人很久沒上號的半僵尸粉,用于刺激博主們進行主動發文章,發長文章,發高質量文章,實際關注量并沒有資料上那么高,官方放大了數值,在所謂的“熱榜”、“粉絲”等虛榮心的刺激下,大家卷起來了,當然,大部分熱門博主都是靠愛發電,并不是十分在乎這些,也是也有很多人,樂此不疲地去追求,這恰好也是 C 站官方所想看到的,幾乎免費的勞動力,正中下懷,
-
官方給出的每日閱讀量等資料,是 C 站官方人為可控的,可以是主觀的,而不是客觀的訪問,即,他想讓你的訪問量驟降,只是后臺修改一個引數的事情,當然,修改也是基于客觀資料的權重修改,而不是亂來,對于博文的各個資料,他們對于每個博主都有一個 threshhold 引數,來控制 “水” 的流出,各個資料之間似乎也沒有相關關系,
-
熱榜演算法,立足于自身利益,一直在修改,比如說,對于新人發好文的扶持,對于卷王的培養,
以上想法,純屬猜測,如有冒犯,請勿刪文,一個好的企業總是經得起批評的,這樣才會朝著更好的方向發展,狹隘的企業,才會時時提防別人說不好的話,
基于以上想法,值此粉絲破萬之際,我們來爬取一下粉絲,一波分析看看他們是不是“機器僵尸粉”,
爬取 C 站粉絲和他們的訪問量和粉絲數
代碼比較簡單,我就不解釋了,直接貼出來,其中,參考了幾行擦姐的代碼,
爬所有粉絲
# -*- coding: utf-8 -*-
import requests
import random
import json
import pandas as pd
from lxml import etree
import math
n = 10000;#需要修改為想要爬取的粉絲數,數值要小于自己的粉絲數
page_num = math.ceil(n/20);
uas = [
"Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)"
]
ua = random.choice(uas)
headers = {
"user-agent": ua,
'cookie': 'UserName=lusongno1; UserInfo=f332fa86de644360b04f896a8a46f7d4; UserToken=f332fa86de644360b04f896a8a46f7d4;',
"referer": "https://blog.csdn.net/qing_gee?type=sub&subType=fans"
}
url_format = "https://blog.csdn.net/community/home-api/v1/get-fans-list?page={}&size=20&noMore=true&blogUsername=lusongno1"
dfs = pd.DataFrame();
for i in range(1,page_num+1):
print("get page:"+str(i))
url = url_format.format(i);
response = requests.get(url,headers=headers)
content = json.loads(response.text)
tmp=content.get("data")
data=tmp.get("list")
df=pd.DataFrame(data)
dfs = pd.concat([dfs,df],axis=0)
dfs = dfs.reset_index()
dfs.to_csv("fans.csv",encoding='utf_8_sig')#, index_label="index_label")
獲得粉絲的訪問量等基本情況
dfs['訪問'] = None
dfs['粉絲'] = None
dfs['原創'] = None
dfs['周排名'] = None
dfs['總排名'] = None
for i in range(0,len(dfs)):
print("get fan:"+str(i))
link = dfs.iloc[i]['blogUrl']
res = requests.get(link,headers=headers)
html = res.text;
tree=etree.HTML(html)
yuanchuang = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[1]/a/dt/span')
fangwen = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[4]/dt/span')
fensi = tree.xpath('//*[@id="fan"]')
zhoupaiming = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[2]/a/dt/span')
zongpaiming = tree.xpath('//*[@id="asideProfile"]/div[2]/dl[3]/a/dt/span')
yc = yuanchuang[0].text
fw = fangwen[0].text
fs = fensi[0].text
zpm = zhoupaiming[0].text
zongpm = zongpaiming[0].text
dfs.loc[i:i,('訪問','粉絲','原創','周排名','總排名')]=[fw,fs,yc,zpm,zongpm]
del dfs['userAvatar']
del dfs['briefIntroduction']
del dfs['index']
dfs.to_csv("myFans.csv",encoding='utf_8_sig')
對于粉絲的論述
跑完程式,我就爬下來了兩張表,一張表包括所有粉絲的 ID、昵稱、頭像、博客鏈接、是否互關、是否博客專家、個人簽名,另外一張表包含了粉絲的原創文章數、訪問量、粉絲數、排名情況等,
粉絲基本情況
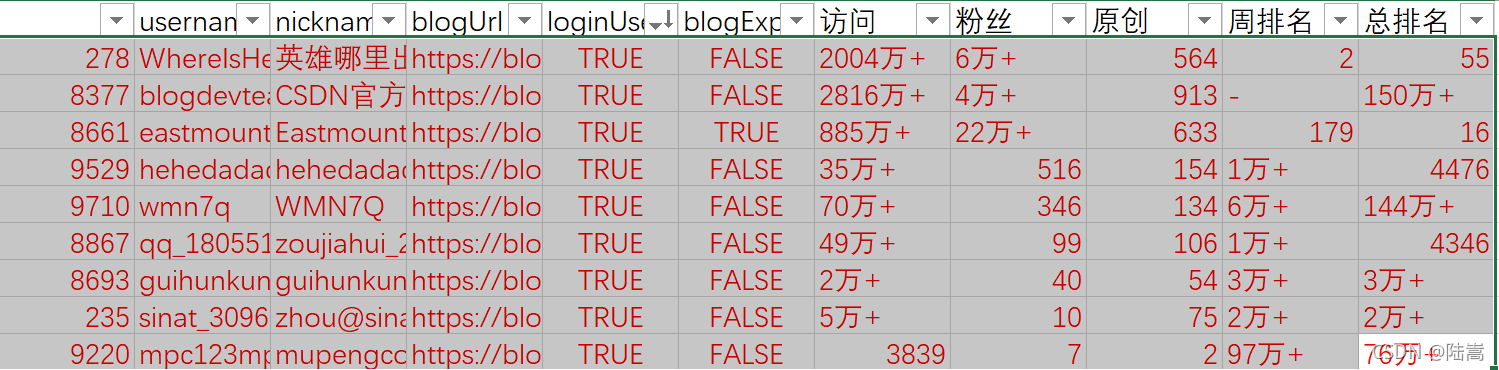
從粉絲上可以看出,和我互關的一共有 9 人,他們是我的幾個研究生同學,還有楊老師、英雄哥等前排的博主,包括 CSDN 官方博客,其中,博客專家有 4+ 人,他們是秀璋老師、天涯哥、大餅和小新,因為 get 回傳的結果有 bug,所以很多博客專家被標成了不是,比如說天涯兄,所以我這里寫了 4+,
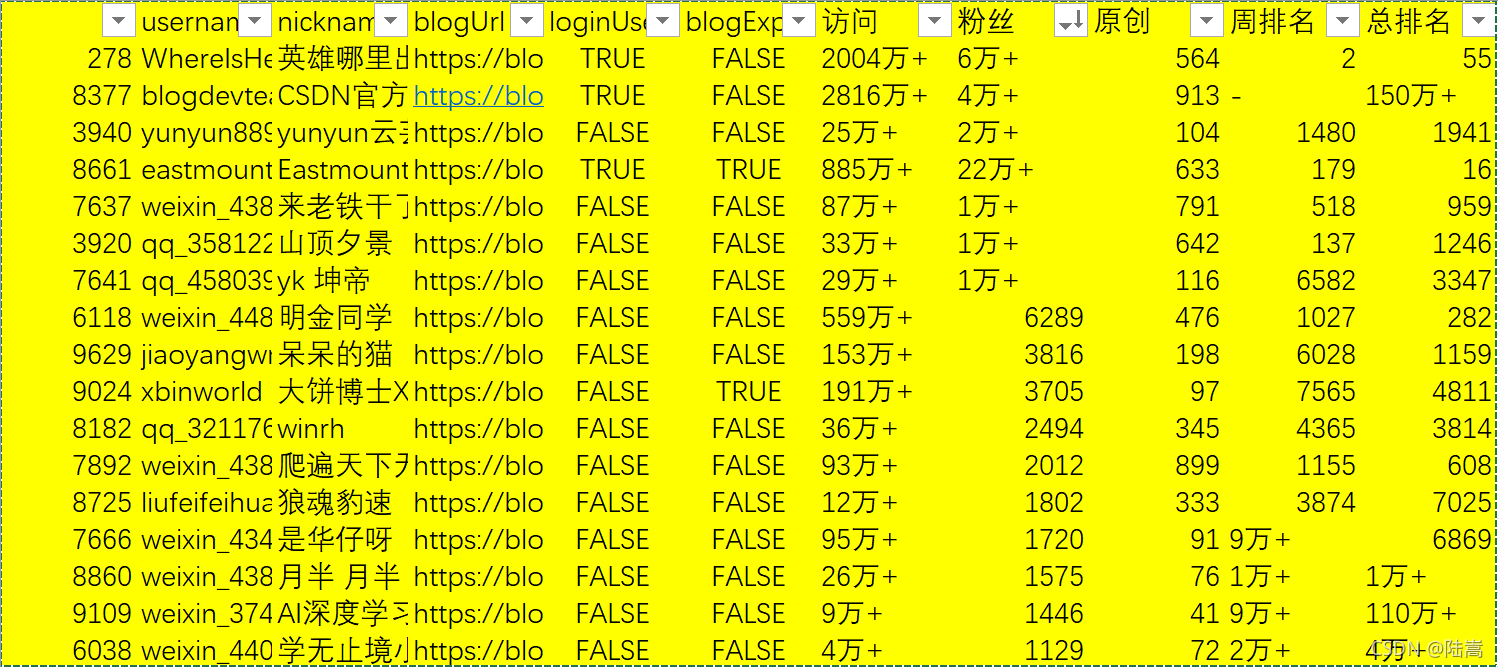
他們當中,粉絲數過 1000 的,一共有 17 人,原創文章數達到 100 的,一共有 68 人,
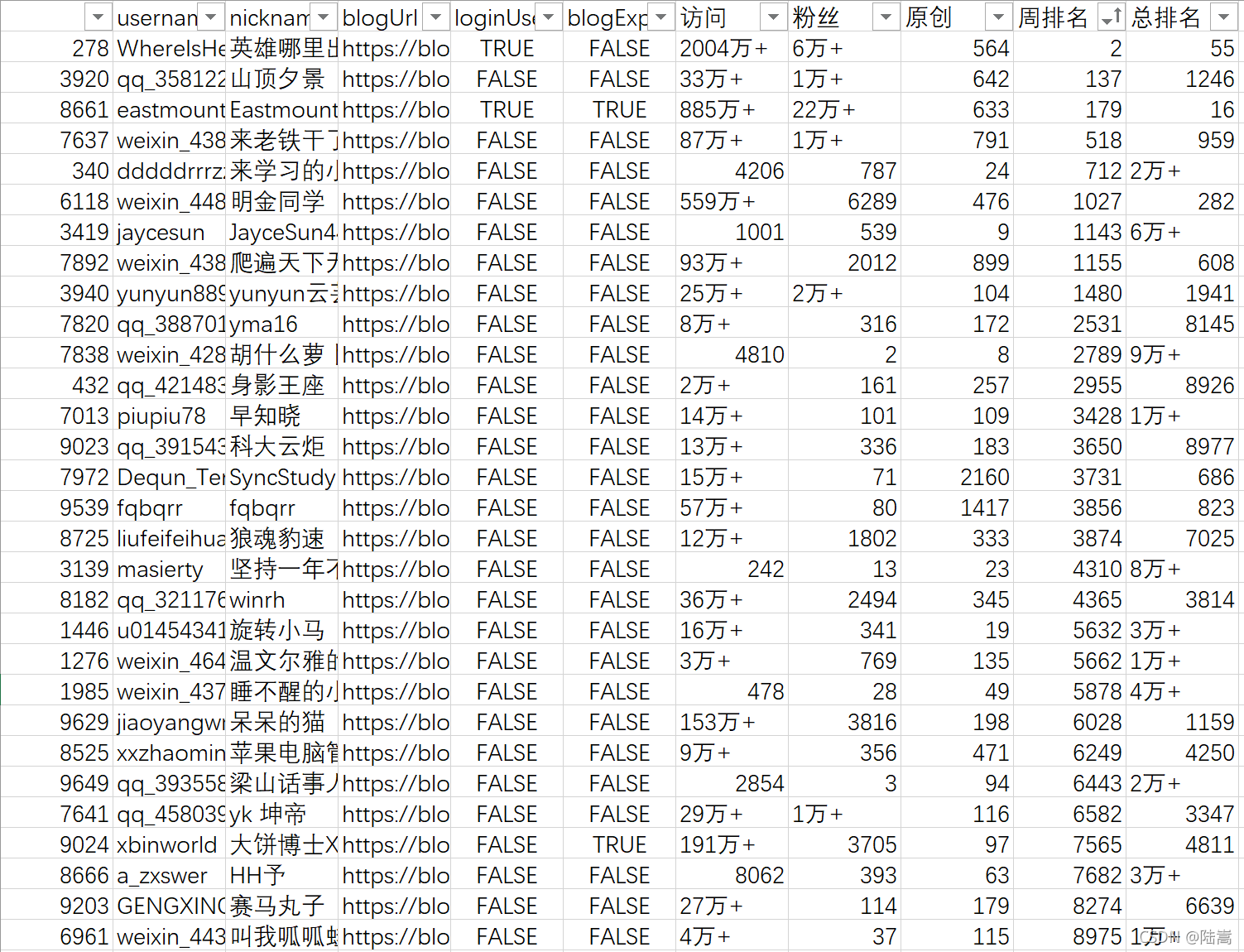
周排名在 1 萬名以內的,一共有 30 人,訪問量過萬的有 371 人,總排名在 1 萬以內的,一共有 42 人,
粉絲是否僵尸粉的判別
現在重點來了,這 1 萬的粉絲里面,到底有沒有是通過官方推薦關注的 “僵尸機器粉” 呢?如何判別?這個有點難,我找到了好多論文,也沒找到有用的方法,
退而求其次,我分析了我的粉絲資料,還是無法推出他們是機器粉的結論,主要是那些零訪問、零粉絲、無文章、無排名的粉絲批量分析之后都太真實了,不管是從頭像,還是 ID,還是昵稱,如果真是隨機的,那我也沒辦法了,
本著疑罪從無的態度,我宣布,C 站沒有用僵尸粉誘導我們寫文章,它還是我們曾經的那個好大哥,
即使如此,博客文章的各個維度的資料,官方必然是有所控制的,而不是自然發展的,他們是一個公司,他們有一幫子人要養,服務器也要錢,不管他們干了什么,哪怕放了很多廣告,我們也要理解,既然享受了權利,就要履行一定的義務,世上沒有只白嫖別人,而不付出的道理,
python3 網頁抓取基本模板
貼一個爬資料的基本模板,引為參考,
urllib、urllib2、requests 庫的區別與聯系
- urllib、urllib2 是 python2 自帶的庫,二者相互補充,
- python3 中只有 urllib,而 urllib2 已經不再存在,在 python3 中,urllib 和 urllib2 進行了合并,現在只有一個 urllib 模塊,urllib 和 urllib2 的中的內容整合進了 urllib.request,urlparse 整合進了urllib.parse,
- requests 是第三方庫,它的 slogen 是“Requests is the only Non-GMO HTTP library for Python, safe for human consumption”,因為 urllib 和 urllib2 太亂了,使用時還需要考慮編碼問題,
- requests 是 對 urllib 更上層的封裝,使用更傻瓜方便,
requests 使用的一個基本框架
GET 方式
import requests
stuID = "xxxxxxxxxxxxxxx"
url = "xxx"+stuID
r = requests.get(url)
# requests提供了 params 關鍵字引數來傳遞引數
parameter = {
"key1":"value1",
"key2":"value2"
}
response = requests.get("http://httpbin.org/get",params = parameter)
print(response.url)
# 輸出 http://httpbin.org/get?key1=value1&key2=value2
POST 方式
import requests
payload = {
"key1":"value1",
"key2":"value2"
}
response = requests.post("http://httpbin.org/post",data = payload)
print(response.text)
import requests
postdata = { 'name':'aaa' }
r = requests.post("http://xxxxx",data=postdata)
print(r.text)
#如果要爬蟲用的話 一般建議帶上session會話和headers表頭資訊,session會話可以自動記錄cookie
s = requests.Session()
headers = { 'Host':'www.xxx.com'}
postdata = { 'name':'aaa' }
url = "http://xxxxx"
s.headers.update(headers)
r = s.post(url,data=postdata)
print(r.text)
#可以直接帶上 header
import requests
#import json
data = {'some': 'data'}
headers = {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
r = requests.post('https://api.github.com/some/endpoint', data=data, headers=headers)
print(r.text)
urllib 使用的一個基本框架
GET 方式
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # 讀取網頁內容
f.write(content)
f.close()
POST 方式
import urllib.request
import urllib.parse
url = 'https://www.runoob.com/try/py3/py3_urllib_test.php' # 提交到表單頁面
data = {'name':'RUNOOB', 'tag' : 'xx教程'} # 提交資料
header = {
'User-Agent':'Mozilla/5.0 (X11; Fedora; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
} #頭部資訊
data = urllib.parse.urlencode(data).encode('utf8') # 對引數進行編碼,解碼使用 urllib.parse.urldecode
request=urllib.request.Request(url, data, header) # 請求處理
reponse=urllib.request.urlopen(request).read() # 讀取結果
fh = open("./urllib_test_post_runoob.html","wb") # 將檔案寫入到當前目錄中
fh.write(reponse)
fh.close()
文章目錄
- 一萬粉的時候,我爬光了我所有的粉絲,只為驗證一個事情
- 前言
- 爬取 C 站粉絲和他們的訪問量和粉絲數
- 爬所有粉絲
- 獲得粉絲的訪問量等基本情況
- 對于粉絲的論述
- 粉絲基本情況
- 粉絲是否僵尸粉的判別
- python3 網頁抓取基本模板
- urllib、urllib2、requests 庫的區別與聯系
- requests 使用的一個基本框架
- GET 方式
- POST 方式
- urllib 使用的一個基本框架
- GET 方式
- POST 方式
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/344317.html
標籤:其他