假設我有以下名稱串列:
names = [['Matt', 'Matt', 'Paul'], ['Matt']]
我只想回傳串列中的“Matts”,但我也想維護串列結構的串列。所以我想回傳:
[['Matt', 'Matt'], ['Matt']]
我有這樣的事情,但這會將所有內容附加到一個大串列中:
matts = [name for namelist in names for name in namelist if name=="Matt"]
我知道這樣的事情是可能的,但我想避免遍歷串列和追加。這可能嗎?
names = [['Matt', 'Matt', 'Paul'], ['Matt']]
matts = []
for namelist in names:
matts_namelist = []
for name in namelist:
if name=="Matt":
matts_namelist.append(name)
else:
pass
matts.append(matts_namelist)
uj5u.com熱心網友回復:
使用嵌套串列理解,如下所示:
names = [['Matt', 'Matt', 'Paul'], ['Matt']]
res = [[name for name in lst if name == "Matt"] for lst in names]
print(res)
輸出
[['Matt', 'Matt'], ['Matt']]
上面的嵌套串列推導等價于下面的 for 回圈:
res = []
for lst in names:
res.append([name for name in lst if name == "Matt"])
print(res)
使用filterand 的第三種替代功能替代方法partial是:
from operator import eq
from functools import partial
names = [['Matt', 'Matt', 'Paul'], ['Matt']]
eq_matt = partial(eq, "Matt")
res = [[*filter(eq_matt, lst)] for lst in names]
print(res)
微基準
%timeit [[*filter(eq_matt, lst)] for lst in names]
56.3 μs ± 519 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
%timeit [[name for name in lst if "Matt" == name] for lst in names]
26.9 μs ± 355 ns per loop (mean ± std. dev. of 7 runs, 10000 loops each)
設定 (微基準)
import random
population = ["Matt", "James", "William", "Charles", "Paul", "John"]
names = [random.choices(population, k=10) for _ in range(50)]
完整基準
候選人
def nested_list_comprehension(names, needle="Matt"):
return [[name for name in lst if needle == name] for lst in names]
def functional_approach(names, needle="Matt"):
eq_matt = partial(eq, needle)
return [[*filter(eq_matt, lst)] for lst in names]
def count_approach(names, needle="Matt"):
return [[needle] * name.count(needle) for name in names]
陰謀
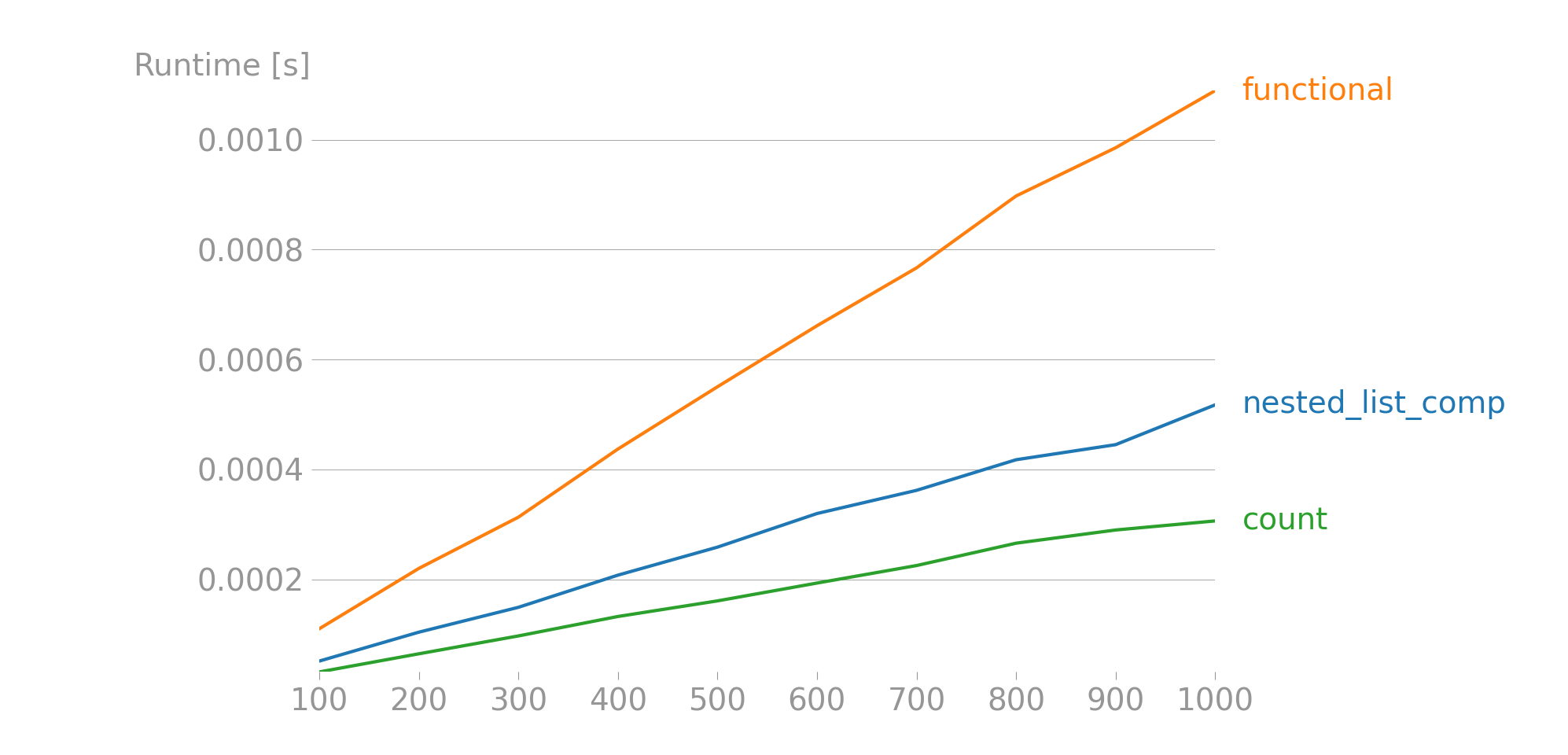
上述結果是針對包含 100 到 1000 個元素的串列獲得的,其中每個元素是從 14 個字串(名稱)中隨機選擇的 10 個字串的串列。可以在此處找到重現結果的代碼。因為它可以從圖中可以看出,最高效的解決方案是一個由@ rv.kvetch。
uj5u.com熱心網友回復:
另一種使用方法list.count:
>>> names = [['Matt', 'Matt', 'Paul'], [], ['Matt']]
>>> [name.count('Matt') * ['Matt'] for name in names]
[['Matt', 'Matt'], [], ['Matt']]
你也可以嘗試itertools.repeat:
>>> import itertools
>>> [[*itertools.repeat('Matt', name.count('Matt'))] for name in names]
[['Matt', 'Matt'], [], ['Matt']]
最后,正如@DaniMensejo 所建議的,您還可以range在嵌套list理解中使用迭代器:
>>> [['Matt' for _ in range(name.count('Matt'))] for name in names]
[['Matt', 'Matt'], [], ['Matt']]
uj5u.com熱心網友回復:
IIUC,您可以使用如下嵌套串列執行此操作:
>>> names = [['Matt', 'Matt', 'Paul'], ['Matt']]
>>> [[name for name in lst_name if name=='Matt'] for lst_name in names]
[['Matt', 'Matt'], ['Matt']]
uj5u.com熱心網友回復:
使用filter功能——
matts = [list(filter(lambda x: x=='Matt', namelist)) for namelist in names]
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/345341.html