大家好,我是老三,很高興又和大家見面,最近降溫,大家注意保暖,
這節分享Java執行緒池,接下來我們一步步把執行緒池扒個底朝天,
引言:老三取錢
有一個程式員,他的名字叫老三,
老三兜里沒有錢,匆匆銀行業務辦,
這天起了一大早,銀行姐姐說早安,
老三一看柜臺空,卡里五毛都取完,
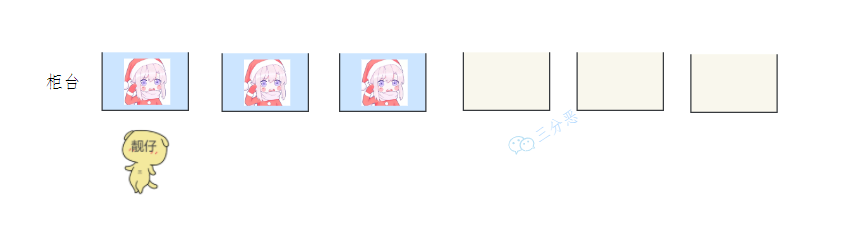
老三這天起的晚,營業視窗都排滿,
只好進入排隊區,摸出手機等空閑,
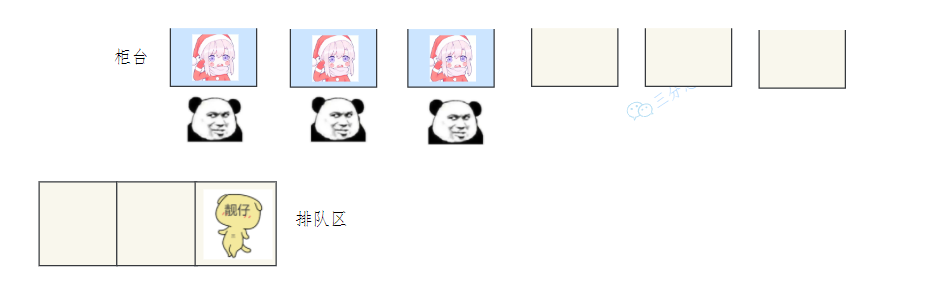
老三睡到上三桿,視窗排隊都爆滿,
經理一看開新口,排隊同志趕緊辦,
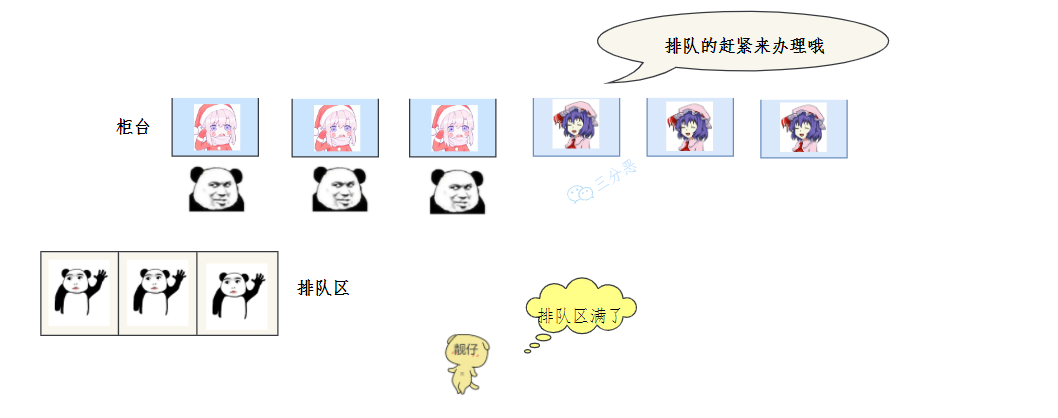
這天業務太火爆,柜臺排隊都用完,
老三一看急上火,經理你說怎么辦,
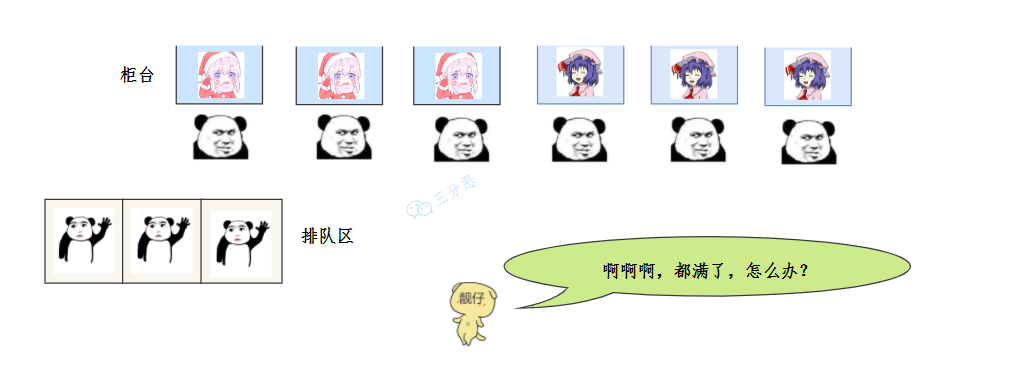
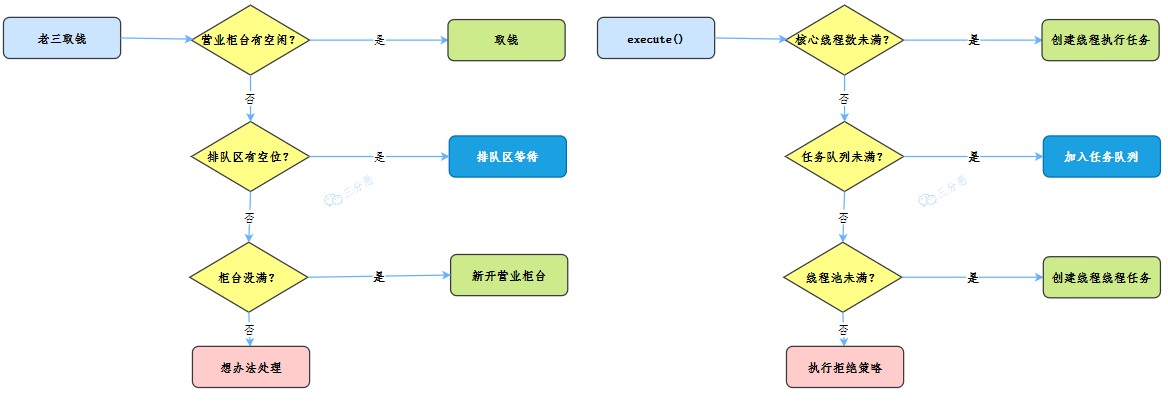
經理揮手一笑間,這種場面已見慣,四種辦法來處理,你猜我會怎么辦,
- 小小銀行不堪負,陳舊系統已癱瘓,
- 我們廟小對不起,誰叫你來找誰辦,
- 看你情況特別急,來去隊里加個塞,
- 今天實在沒辦法,不行你看改一天,
對,沒錯,其實這個流程就和JDK執行緒池ThreadPoolExecutor的作業流程類似,先賣個關子,后面結合執行緒池作業流程,保證你會豁然開朗,
實戰:執行緒池管理資料處理執行緒
光說不練假把式,show you code,我們來一個結合業務場景的執行緒池實戰,——很多同學面試的時候,執行緒池原理背的滾瓜爛熟,一問專案中怎么用的,歇菜,看完這個例子,趕緊琢磨琢磨,專案里有什么地方能套用的,
應用場景
應用場景非常簡單,我們的專案是一個審核類的系統,每年到了核算的時候,需要向第三方的核算系統提供資料,以供核算,
這里存在一個問題,由于歷史原因,核算系統提供的介面只支持單條推送,但是實際的資料量是三十萬條,如果一條條推送,那么起碼得一個星期,
所以就考慮使用多執行緒的方式來推送資料,那么,執行緒通過什么管理呢?執行緒池,
為什么要用執行緒池管理執行緒呢?當然是為了執行緒復用,
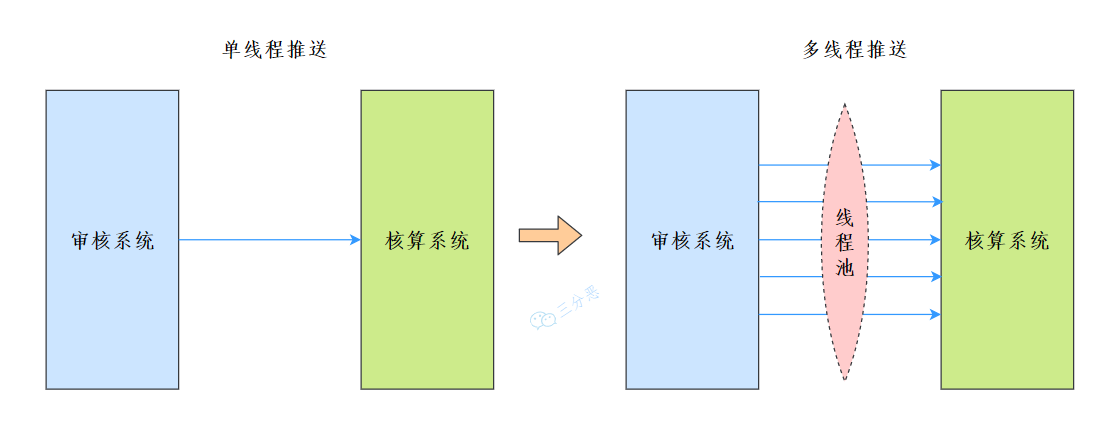
思路也很簡單,開啟若干個執行緒,每個執行緒從資料庫中讀取取(start,count]區間未推送的資料進行推送,
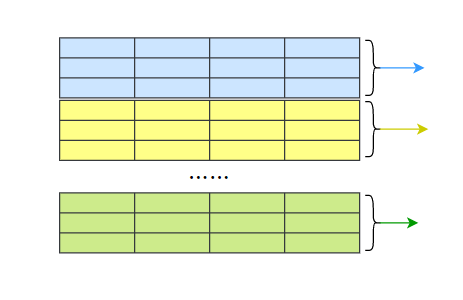
具體代碼實作
我把這個場景提取了出來,主要代碼:
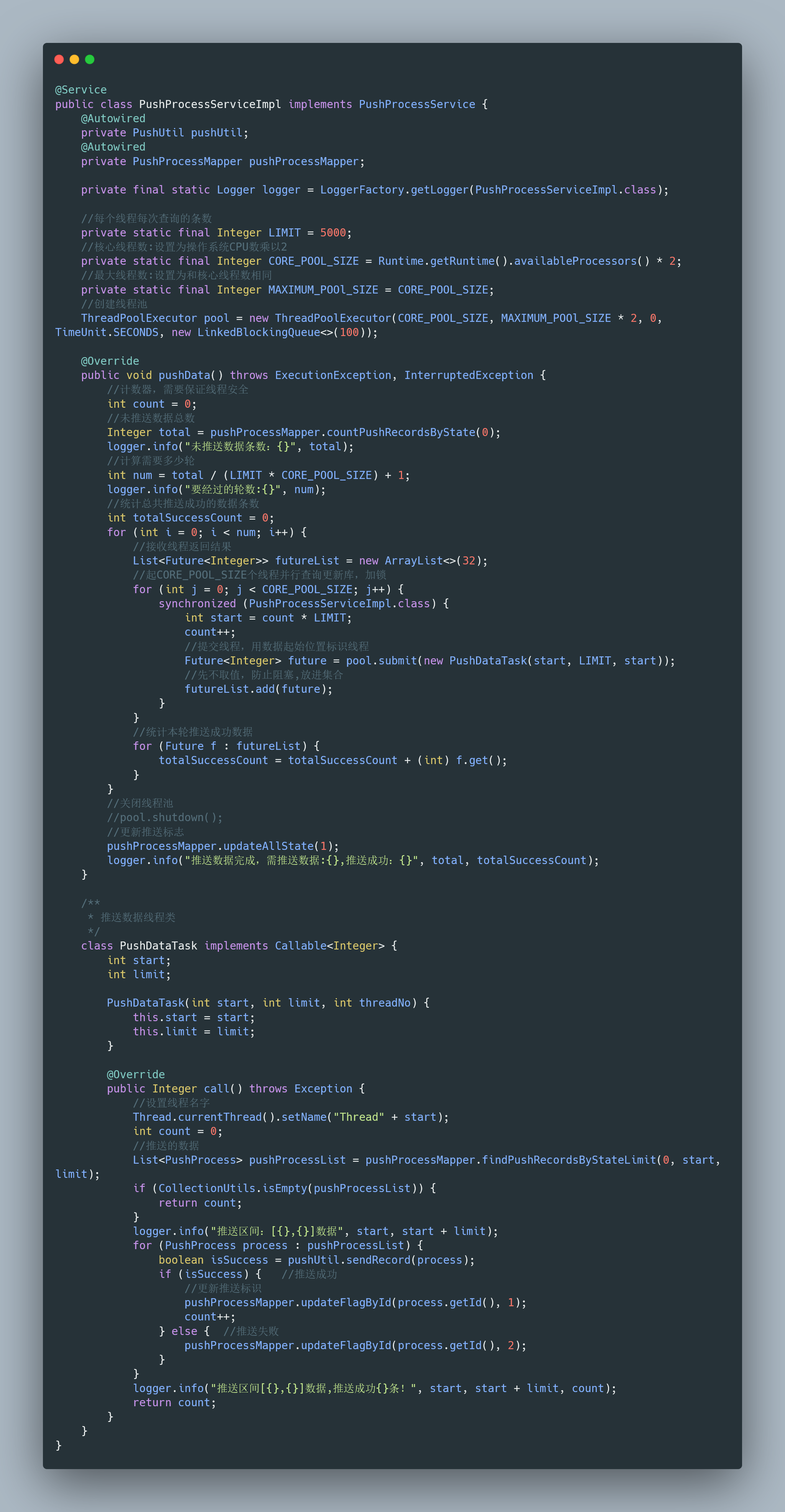
代碼比較長,所以用了carbon美化,代碼看不清,沒關系,可運行的代碼我都上傳到了遠程倉庫,倉庫地址:https://gitee.com/fighter3/thread-demo.git ,這個例子比較簡單,沒有用過執行緒池的同學可以考慮你有沒有什么資料處理、清洗的場景可以套用,不妨借鑒、演繹一下,
本文主題是執行緒池,所以我們重點關注執行緒池的代碼:
執行緒池構造
//核心執行緒數:設定為作業系統CPU數乘以2
private static final Integer CORE_POOL_SIZE = Runtime.getRuntime().availableProcessors() * 2;
//最大執行緒數:設定為和核心執行緒數相同
private static final Integer MAXIMUM_POOl_SIZE = CORE_POOL_SIZE;
//創建執行緒池
ThreadPoolExecutor pool = new ThreadPoolExecutor(CORE_POOL_SIZE, MAXIMUM_POOl_SIZE * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
執行緒池直接采用ThreadPoolExecutor構造:
- 核心執行緒數設定為CPU數×2
- 因為需要分段資料,所以最大執行緒數設定為和核心執行緒數一樣
- 阻塞佇列使用
LinkedBlockingQueue - 拒絕策略使用默認
執行緒池提交任務
//提交執行緒,用資料起始位置標識執行緒
Future<Integer> future = pool.submit(new PushDataTask(start, LIMIT, start));
- 因為需要回傳值,所以使用
submit()提交任務,如果使用execute()提交任務,沒有回傳值,
代碼不負責,可以done下來跑一跑,
那么,執行緒池具體是怎么作業的呢?我們接著往下看,
原理:執行緒池實作原理
執行緒池作業流程
構造方法
我們在構造執行緒池的時候,使用了ThreadPoolExecutor的構造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
先來看看幾個引數的含義:
-
corePoolSize: 核心執行緒數 -
maximumPoolSize:允許的最大執行緒數(核心執行緒數+非核心執行緒數) -
workQueue:執行緒池任務佇列用來保存等待執行的任務的阻塞佇列,常見阻塞佇列有:
ArrayBlockingQueue:一個基于陣列結構的有界阻塞佇列LinkedBlockingQueue:基于鏈表結構的阻塞佇列SynchronousQueue:不存盤元素的阻塞佇列PriorityBlockingQueue:具有優先級的無限阻塞佇列
-
handler: 執行緒池飽和拒絕策略JDK執行緒池框架提供了四種策略:
AbortPolicy:直接拋出例外,默認策略,CallerRunsPolicy:用呼叫者所在執行緒來運行任務,DiscardOldestPolicy:丟棄任務佇列里最老的任務DiscardPolicy:不處理,丟棄當前任務
也可以根據自己的應用場景,實作
RejectedExecutionHandler介面來自定義策略,
上面四個是和執行緒池作業流程息息相關的引數,我們再來看看剩下三個引數,
keepAliveTime:非核心執行緒閑置下來最多存活的時間unit:執行緒池中非核心執行緒保持存活的時間threadFactory:創建一個新執行緒時使用的工廠,可以用來設定執行緒名等
執行緒池作業流程
知道了幾個引數,那么這幾個引數是怎么應用的呢?
以execute()方法提交任務為例,我們來看執行緒池的作業流程:
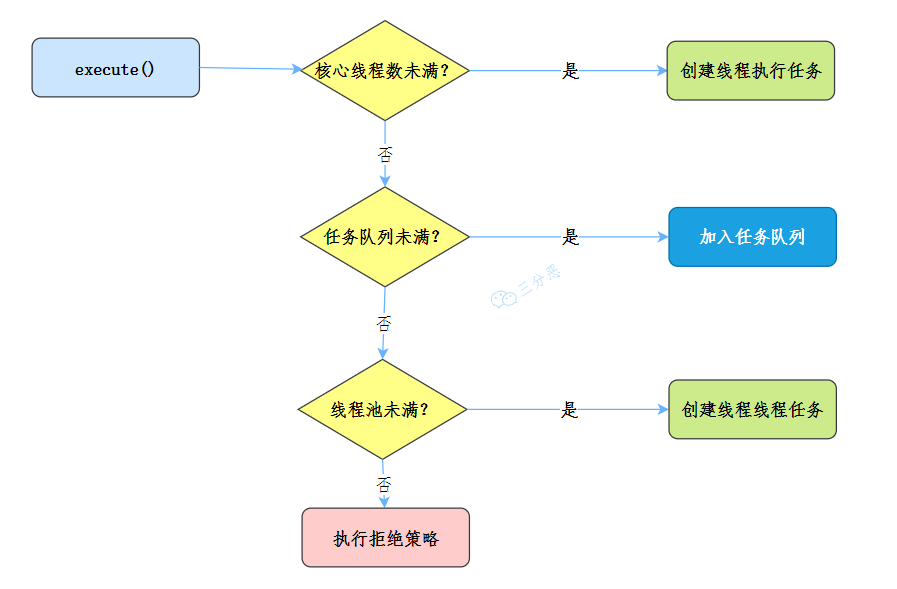
向執行緒池提交任務的時候:
- 如果當前運行的執行緒少于
核心執行緒數corePoolSize,則創建新執行緒來執行任務 - 如果運行的執行緒等于或多于
核心執行緒數corePoolSize,則將任務加入任務佇列workQueue - 如果
任務佇列workQueue已滿,創建新的執行緒來處理任務 - 如果創建新執行緒使當前總執行緒數超過
最大執行緒數maximumPoolSize,任務將被拒絕,執行緒池拒絕策略handler執行
結合一下我們開頭的生活事例,是不是就對上了:
執行緒池作業原始碼分析
上面的流程分析,讓我們直觀地了解了執行緒池的作業原理,我們再來通過原始碼看看細節,
提交執行緒(execute)
執行緒池執行任務的方法如下:
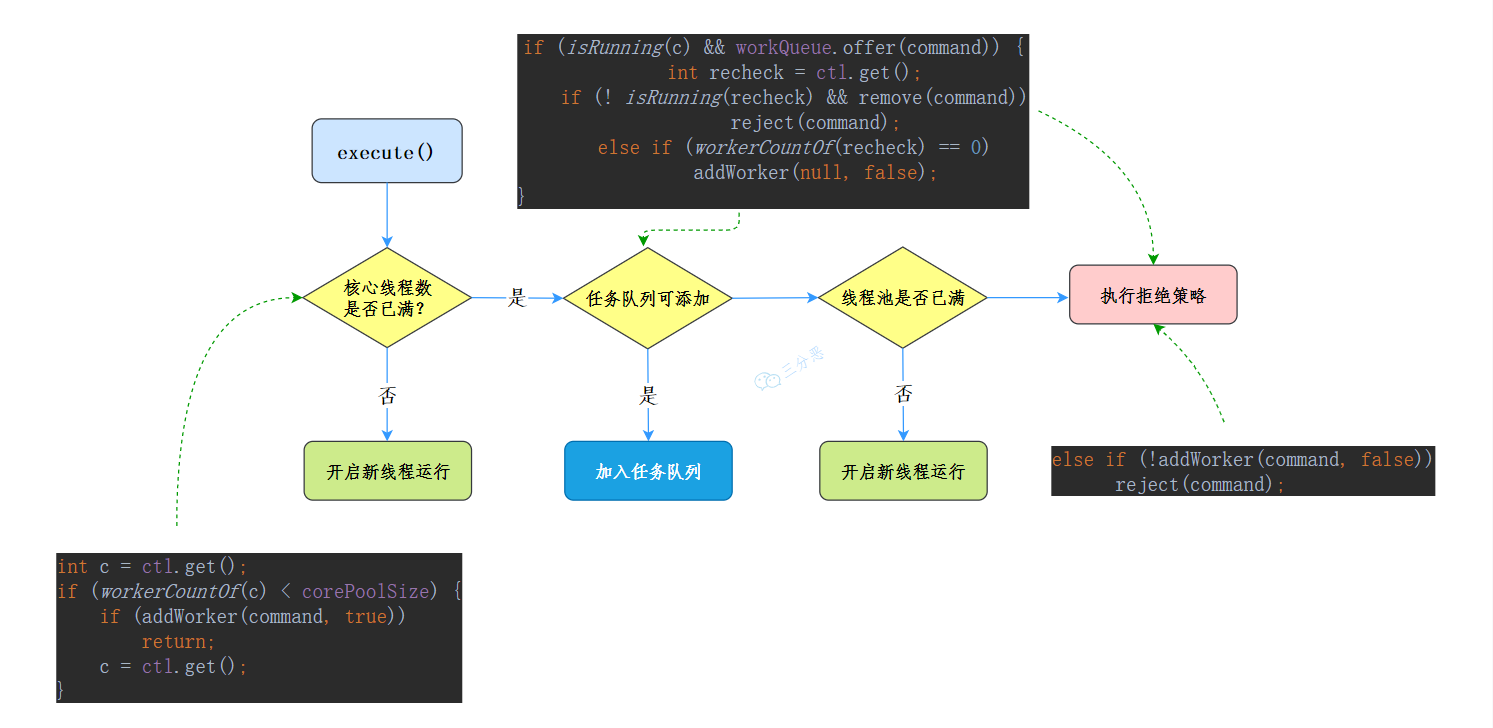
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
//獲取當前執行緒池的狀態+執行緒個數變數的組合值
int c = ctl.get();
//1.如果正在運行執行緒數少于核心執行緒數
if (workerCountOf(c) < corePoolSize) {
//開啟新執行緒運行
if (addWorker(command, true))
return;
c = ctl.get();
}
//2. 判斷執行緒池是否處于運行狀態,是則添加任務到阻塞佇列
if (isRunning(c) && workQueue.offer(command)) {
//二次檢查
int recheck = ctl.get();
//如果當前執行緒池不是運行狀態,則從佇列中移除任務,并執行拒絕策略
if (! isRunning(recheck) && remove(command))
reject(command);
//如若當前執行緒池為空,則添加一個新執行緒
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//最后嘗試添加執行緒,如若添加失敗,執行拒絕策略
else if (!addWorker(command, false))
reject(command);
}
我們來看一下execute()的詳細流程圖:
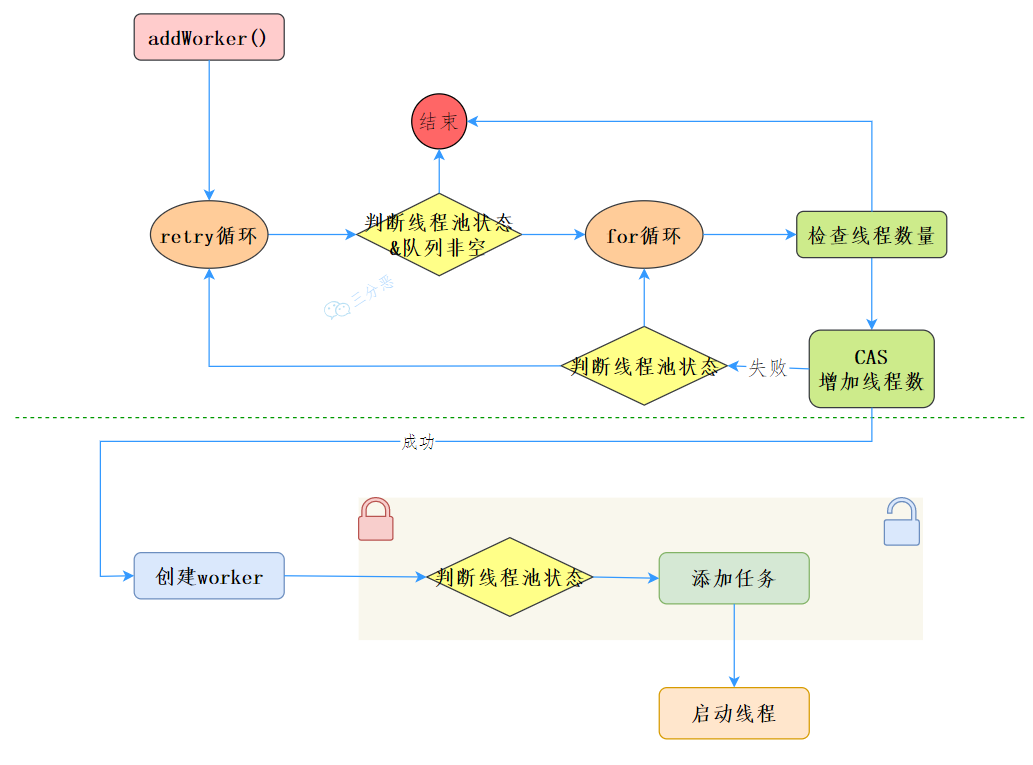
新增執行緒 (addWorker)
在execute方法代碼里,有個關鍵的方法private boolean addWorker(Runnable firstTask, boolean core),這個方法主要完成兩部分作業:增加執行緒數、添加任務,并執行,
- 我們先來看第一部分增加執行緒數:
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 1.檢查佇列是否只在必要時為空(判斷執行緒狀態,且佇列不為空)
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//2.回圈CAS增加執行緒個數
for (;;) {
int wc = workerCountOf(c);
//2.1 如果執行緒個數超限則回傳 false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//2.2 CAS方式增加執行緒個數,同時只有一個執行緒成功,成功跳出回圈
if (compareAndIncrementWorkerCount(c))
break retry;
//2.3 CAS失敗,看執行緒池狀態是否變化,變化則跳到外層,嘗試重新獲取執行緒池狀態,否則內層重新CAS
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
}
}
//3. 到這說明CAS成功了
boolean workerStarted = false;
boolean workerAdded = false;
- 接著來看第二部分添加任務,并執行
Worker w = null;
try {
//4.創建worker
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
//4.1、加獨占鎖 ,為了實作workers同步,因為可能多個執行緒呼叫了執行緒池的excute方法
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
//4.2、重新檢查執行緒池狀態,以避免在獲取鎖前呼叫了shutdown介面
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//4.3添加任務
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
//4.4、添加成功之后啟動任務
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
我們來看一下整體的流程:
執行執行緒(runWorker)
用戶執行緒提交到執行緒池之后,由Worker執行,Worker是執行緒池內部一個繼承AQS、實作Runnable介面的自定義類,它是具體承載任務的物件,
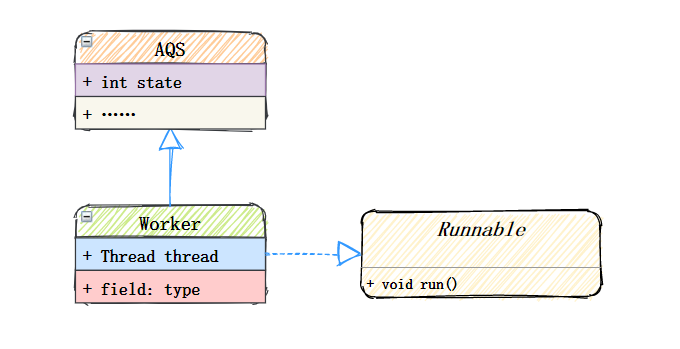
先看一下它的構造方法:
Worker(Runnable firstTask) {
setState(-1); // 在呼叫runWorker之前禁止中斷
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this); //創建一個執行緒
}
- 在建構式內 首先設定 state=-1,現了簡單不可重入獨占鎖,state=0表示鎖未被獲取狀態,state=1表示鎖已被獲取狀態,設定狀態大小為-1,是為了避免執行緒在運行runWorker()方法之前被中斷
- firstTask記錄該作業執行緒的第一個任務
- thread是具體執行任務的執行緒
它的run方法直接呼叫runWorker,真正地執行執行緒就是在我們的runWorker 方法里:
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // 允許中斷
boolean completedAbruptly = true;
try {
//獲取當前任務,從佇列中獲取任務
while (task != null || (task = getTask()) != null) {
w.lock();
…………
try {
//執行任務前做一些類似統計之類的事情
beforeExecute(wt, task);
Throwable thrown = null;
try {
//執行任務
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 執行任務完畢后干一些些事情
afterExecute(task, thrown);
}
} finally {
task = null;
// 統計當前Worker 完成了多少個任務
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
//執行清理作業
processWorkerExit(w, completedAbruptly);
}
}
代碼看著多,其實砍掉枝蔓,最核心的點就是task.run()讓執行緒跑起來,
獲取任務(getTask)
我們在上面的執行任務runWorker里看到,這么一句while (task != null || (task = getTask()) != null),執行的任務是要么當前傳入的firstTask,或者還可以通過getTask()獲取,這個getTask的核心目的就是從佇列中獲取任務,
private Runnable getTask() {
//poll()方法是否超時
boolean timedOut = false;
//回圈獲取
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// 1.執行緒池未終止,且佇列為空,回傳null
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
//作業執行緒數
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
//2.判斷作業執行緒數是否超過最大執行緒數 && 超時判斷 && 作業執行緒數大于0或佇列為空
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
try {
//從任務佇列中獲取執行緒
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
//獲取成功
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}
總結一下,Worker執行任務的模型如下[8]:
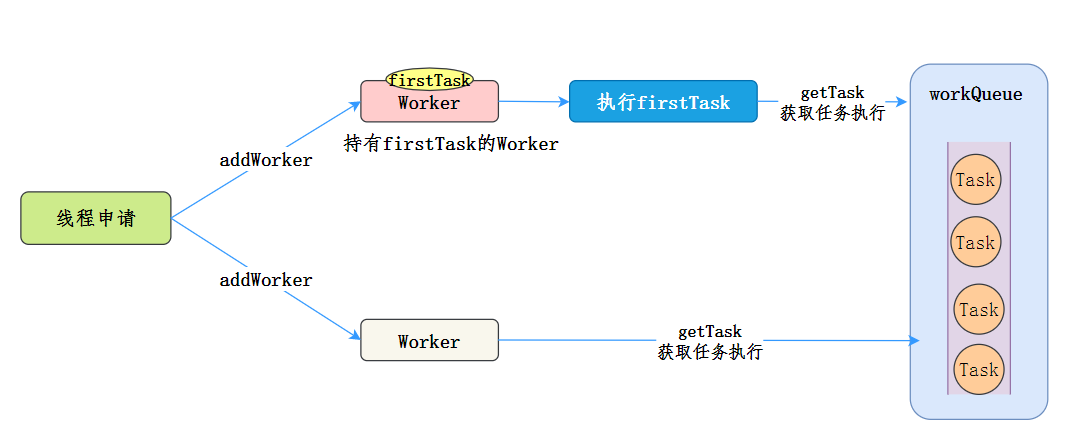
小結
到這,了解了execute和worker的一些流程,可以說其實ThreadPoolExecutor 的實作就是一個生產消費模型,
當用戶添加任務到執行緒池時相當于生產者生產元素,workers 執行緒作業集中的執行緒直接執行任務或者從任務佇列里面獲取任務時則相當于消費者消費元素,
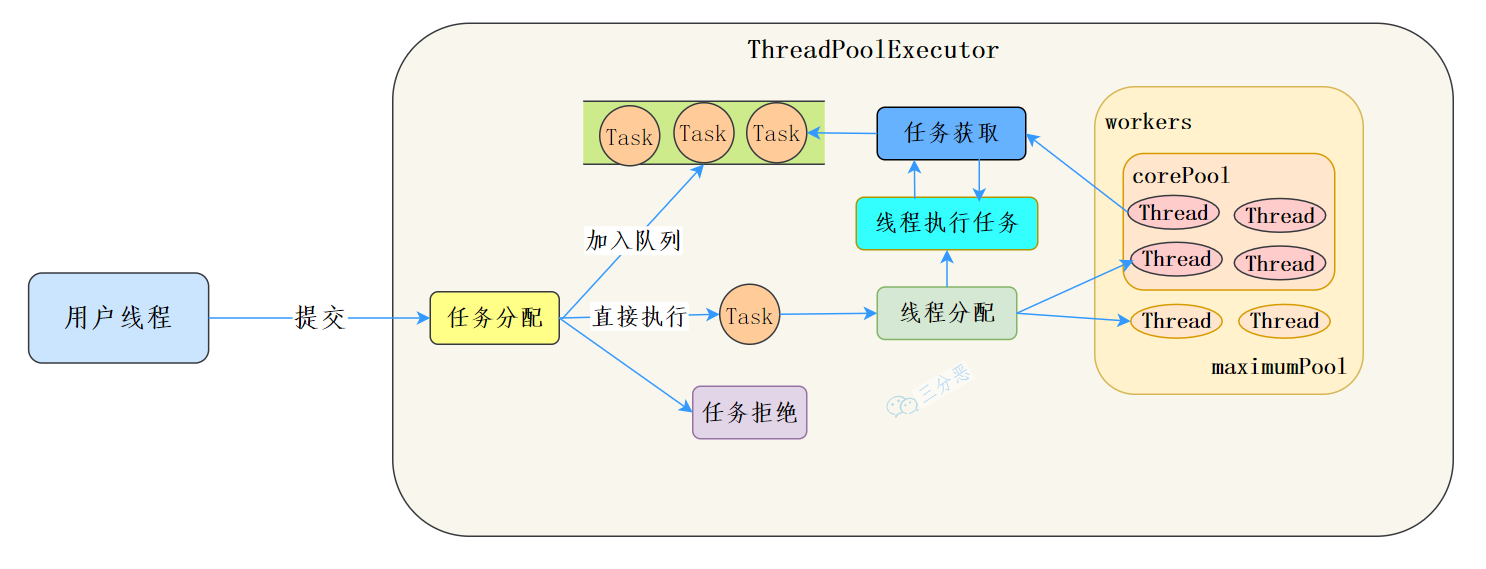
執行緒池生命周期
執行緒池狀態表示
在ThreadPoolExecutor里定義了一些狀態,同時利用高低位的方式,讓ctl這個引數能夠保存狀態,又能保存執行緒數量,非常巧妙![6]
//記錄執行緒池狀態和執行緒數量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
//29
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 執行緒池狀態
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
高3位表示狀態,低29位記錄執行緒數量:
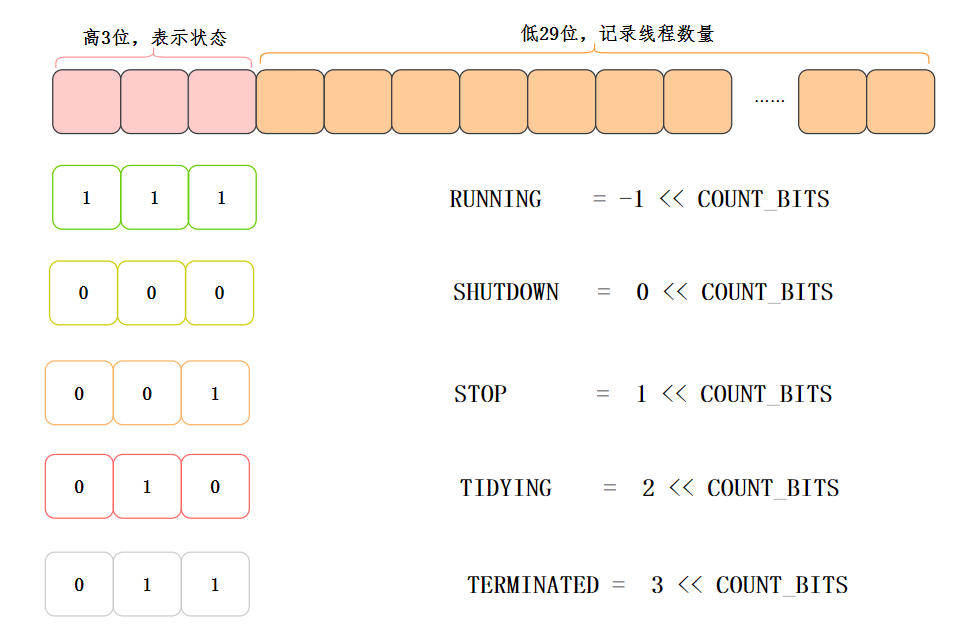
執行緒池狀態流轉
執行緒池一共定義了五種狀態,來看看這些狀態是怎么流轉的[6]:
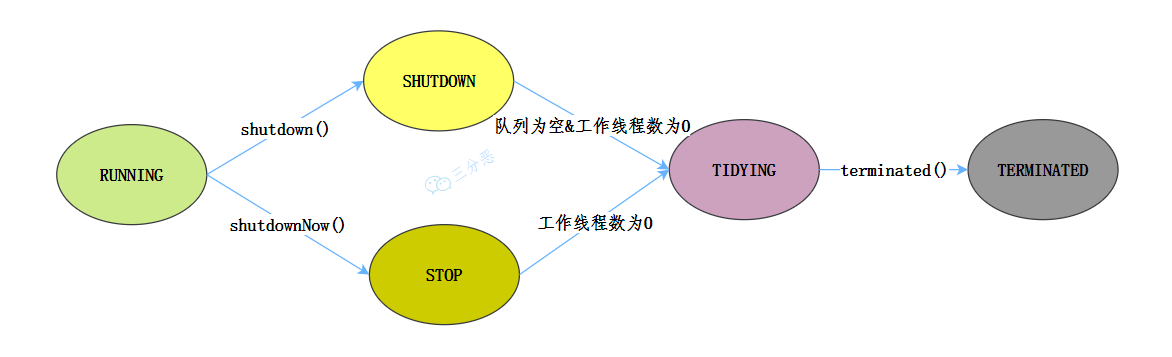
- RUNNING:運行狀態,接受新的任務并且處理佇列中的任務,
- SHUTDOWN:關閉狀態(呼叫了 shutdown 方法),不接受新任務,,但是要處理佇列中的任務,
- STOP:停止狀態(呼叫了 shutdownNow 方法),不接受新任務,也不處理佇列中的任務,并且要中斷正在處理的任務,
- TIDYING:所有的任務都已終止了,workerCount 為 0,執行緒池進入該狀態后會調terminated() 方法進入 TERMINATED 狀態,
- TERMINATED:終止狀態,terminated() 方法呼叫結束后的狀態,
應用:打造健壯的執行緒池
合理地配置執行緒池
關于執行緒池的構造,我們需要注意兩個配置,執行緒池的大小和任務佇列,
執行緒池大小
關于執行緒池的大小,并沒有一個需要嚴格遵守的“金規鐵律”,按照任務性質,大概可以分為CPU密集型任務、IO密集型任務和混合型任務,
- CPU密集型任務:CPU密集型任務應配置盡可能小的執行緒,如配置Ncpu+1個執行緒的執行緒池,
- IO密集型任務:IO密集型任務執行緒并不是一直在執行任務,則應配置盡可能多的執行緒,如2*Ncpu,
- 混合型任務:混合型任務可以按需拆分成CPU密集型任務和IO密集型任務,
當然,這個只是建議,實際上具體怎么配置,還要結合事前評估和測驗、事中監控來確定一個大致的執行緒執行緒池大小,執行緒池大小也可以不用寫死,使用動態配置的方式,以便調整,
任務佇列
任務佇列一般建議使用有界佇列,無界佇列可能會出現佇列里任務無限堆積,導致記憶體溢位的例外,
執行緒池監控
[1]如果在系統中大量使用執行緒池,則有必要對執行緒池進行監控,方便在出現問題時,可以根據執行緒池的使用狀況快速定位問題,
可以通過執行緒池提供的引數和方法來監控執行緒池:
- getActiveCount() :執行緒池中正在執行任務的執行緒數量
- getCompletedTaskCount() :執行緒池已完成的任務數量,該值小于等于 taskCount
- getCorePoolSize() :執行緒池的核心執行緒數量
- getLargestPoolSize():執行緒池曾經創建過的最大執行緒數量,通過這個資料可以知道執行緒池是否滿過,也就是達到了 maximumPoolSize
- getMaximumPoolSize():執行緒池的最大執行緒數量
- getPoolSize() :執行緒池當前的執行緒數量
- getTaskCount() :執行緒池已經執行的和未執行的任務總數
還可以通過擴展執行緒池來進行監控:
- 通過繼承執行緒池來自定義執行緒池,重寫執行緒池的beforeExecute、afterExecute和terminated方法,
- 也可以在任務執行前、執行后和執行緒池關閉前執行一些代碼來進行監控,例如,監控任務的平均執行時間、最大執行時間和最小執行時間等,
End
這篇文章從一個生活場景入手,一步步從實戰到原理來深入了解執行緒池,
但是你發現沒有,我們平時常說的所謂四種執行緒池在文章里沒有提及——當然是因為篇幅原因,下篇就安排執行緒池創建工具類Executors,
執行緒池也是面試的重點戰區,面試又會問到哪些問題呢?
這些內容,都已經在路上,點贊、關注不迷路,下篇見!
參考:
[1]. 《Java并發編程的藝術》
[2]. 《Java發編程實戰》
[3]. 講真 這次絕對讓你輕松學習執行緒池
[4]. 面試必備:Java執行緒池決議
[5]. 面試官問:“在專案中用過多執行緒嗎?”你就把這個案例講給他聽!
[6]. 小傅哥 《Java面經手冊》
[7]. 《Java并發編程之美》
[8]. Java執行緒池實作原理及其在美團業務中的實踐
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/347182.html
標籤:其他
上一篇:江西開放資料創新應用大賽VTE賽道單特征0.5+分享
下一篇:docker虛擬化詳細步驟