
記憶體作為計算機中一項比較重要的資源,它的主要作用就是解決CPU和磁盤之間速度的鴻溝,但是由于記憶體條是需要插入到主板上的,因此對于一臺計算機來說,由于物理限制,它的記憶體不可能無限大的,我們知道我們寫的代碼最終是要從磁盤被加載到記憶體中的,然后再被CPU執行,不知道你有沒有想過,為什么一些大型游戲大到10幾G,卻可以在只有8G記憶體的電腦上運行?甚至在玩游戲期間,我們還可以聊微信、聽音樂...,這么多行程看著同時在運行,它們在記憶體中是如何被管理的?帶著這些疑問我們來看看計算系統記憶體管理那些事,
記憶體的交換技術
如果我們的記憶體可以無限大,那么我們擔憂的問題就不會存在,但是實際情況是往往我們的機器上會同時運行多個行程,這些行程小到需要幾十兆記憶體,大到可能需要上百兆記憶體,當許許多多這些行程想要同時加載到記憶體的時候是不可能的,但是從我們用戶的角度來看,似乎這些行程確實都在運行呀,這是怎么回事?
這就引入要說的交換技術了,從字面的意思來看,我想你應該猜到了,它會把某個記憶體中的行程交換出去,當我們的行程空閑的時候,其他的行程又需要被運行,然而很不幸,此時沒有足夠的記憶體空間了,這時候怎么辦呢?似乎剛剛那個空閑的行程有種占著茅坑不拉屎的感覺,于是可以把這個空閑的行程從記憶體中交換到磁盤上去,這時候就會空出多余的空間來讓這個新的行程運行,當這個換出去的空閑行程又需要被運行的時候,那么它就會被再次交換進記憶體中,通過這種技術,可以讓有限的記憶體空間運行更多的行程,行程之間不停來回交換,看著好像都可以運行,
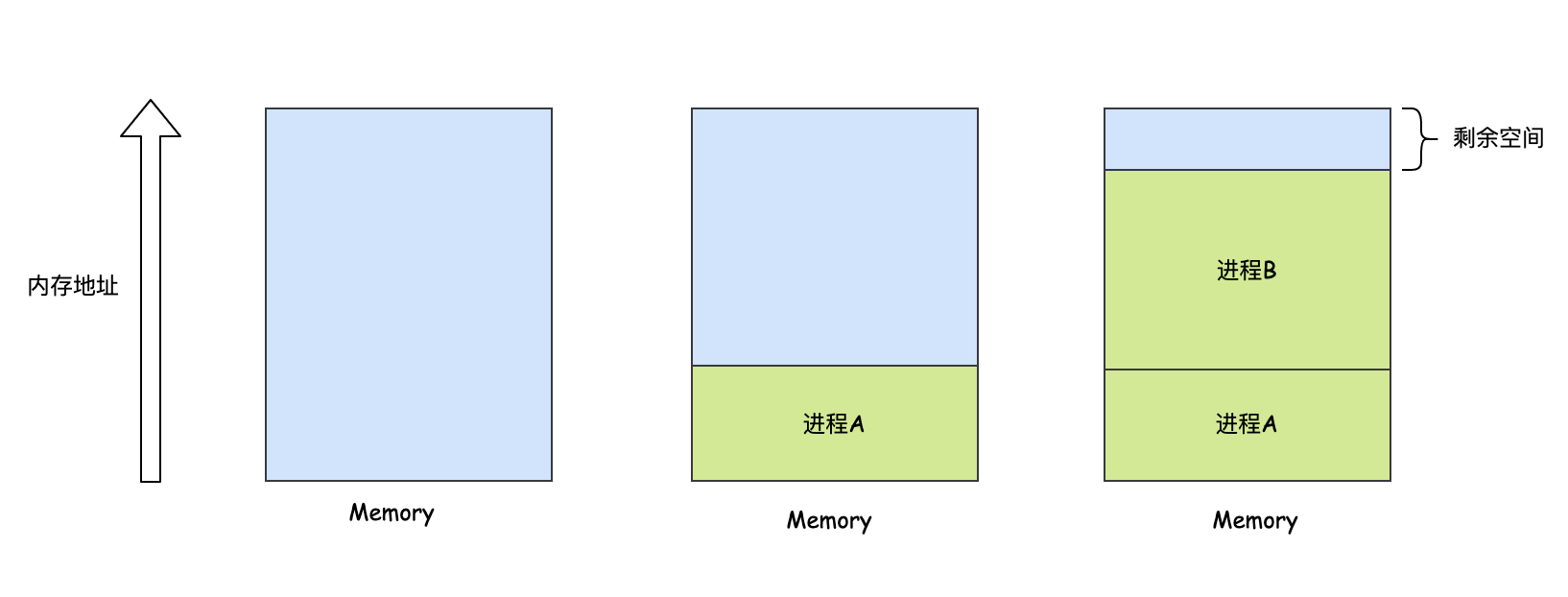
如圖所示,一開始行程A被換入記憶體中,所幸還剩余的記憶體空間比較多,然后行程B也被換入記憶體中,但是剩余的空間比較少了,這時候行程C想要被換入到記憶體中,但是發現空間不夠了,這時候會把已經運行一段時間的行程A換到磁盤中去,然后調入行程C,
記憶體碎片
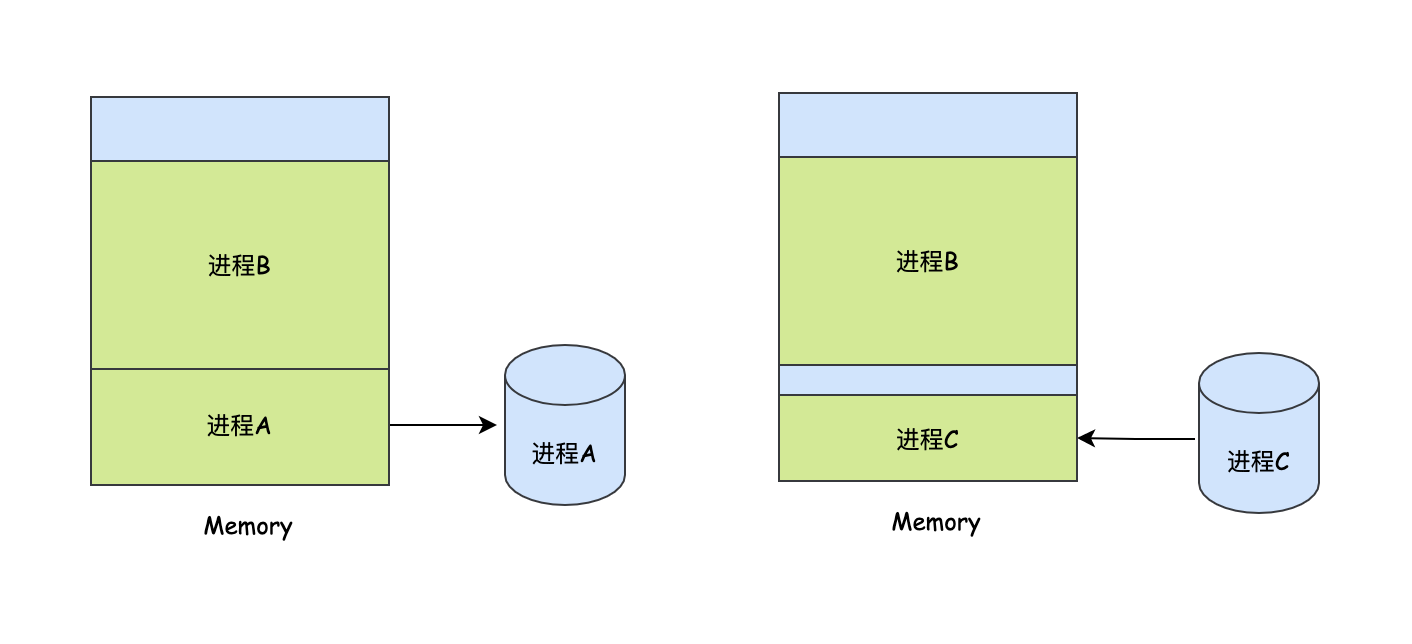
通過這種交換技術,交替的換入和換出行程可以達到小記憶體可以運行更多的行程,但是這似乎也產生了一些問題,不知道你發現了沒有,在行程C換入進來之后,在行程B和行程C之間有段較小的記憶體空間,并且行程B之上也有段較小的記憶體空間,說實話,這些小空間可能永遠沒法裝載對應大小的程式,那么它們就浪費了,在某些情況下,可能會產生更多這種記憶體碎片,
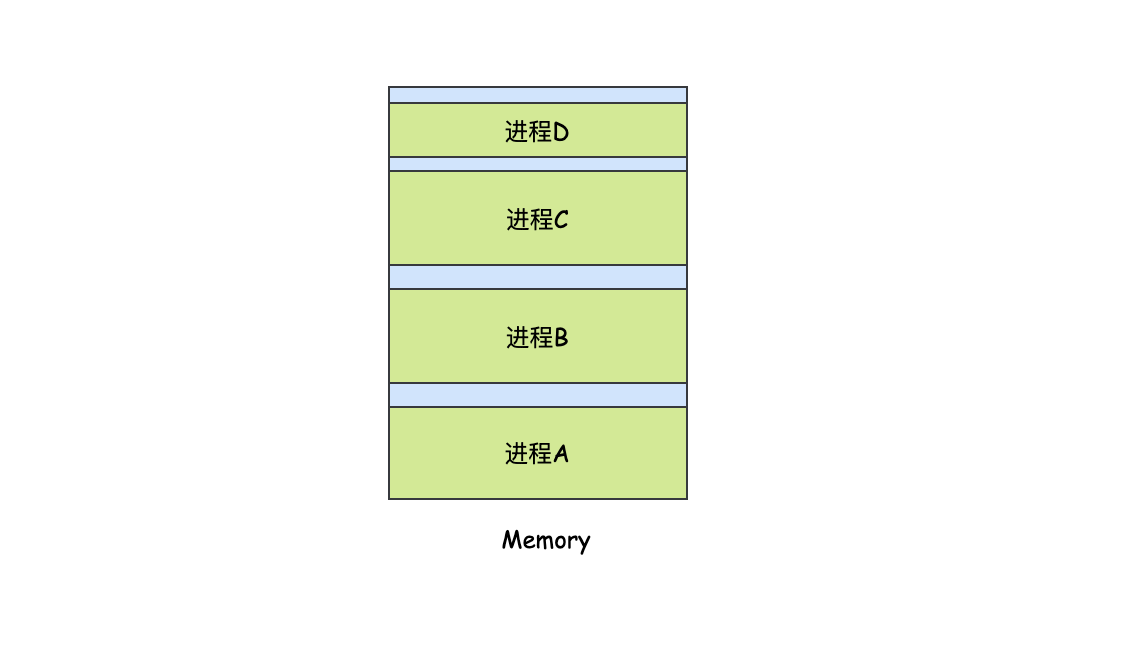
如果想要節約記憶體,那么就得用到記憶體緊湊的技術了,即把所有的行程都向下移動,這樣所有的碎片就會連接在一起變成一段更大的連續記憶體空間了,
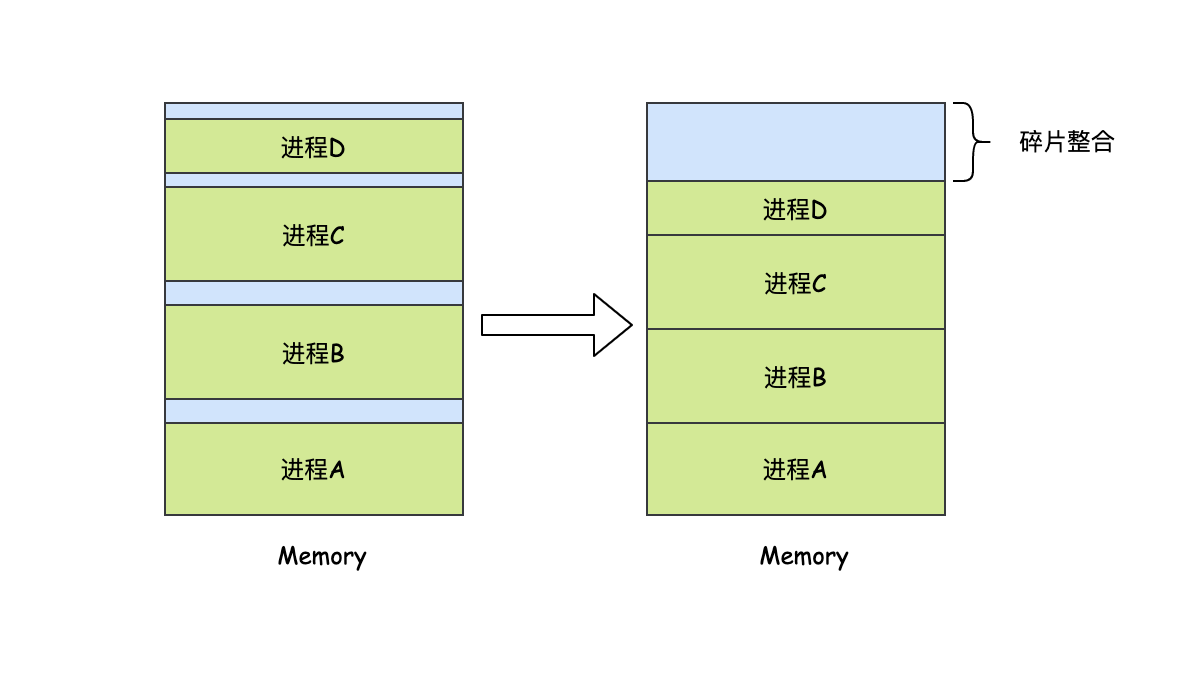
但是這個移動的開銷基本和當前記憶體中的活躍行程成正比,據統計,一臺16G記憶體的計算機可以每8ns復制8個位元組,它緊湊全部的記憶體大概需要16s,所以通常不會進行緊湊這個操作,因為它耗費的CPU時間還是比較大的,
動態增長
其實上面說的行程裝載算是比較理想的了,正常來說,一個行程被創建或者被換入的時候,它占用多大的空間就分配多大的記憶體,但是如果我們的行程需要的空間是動態增長的,那就麻煩了,比如我們的程式在運行期間的for回圈可能會利用到某個臨時變數來存放目標資料(例如以下變數a,隨著程式的運行是會越來越大的):
var a []int64
for i:= 0;i <= 1000000;i++{
if i%2 == 0{
a = append(a,i) //a是不斷增大的
}
}
當需要增長的時候:
- 如果行程的鄰居是空閑區那還好,可以把該空閑區分配給行程
- 如果行程的鄰居是另一個行程,那么解決的辦法只能把增長的行程移動到一個更大的空閑記憶體中,但是萬一沒有更大的記憶體空間,那么就要觸發換出,把一個或者多個行程換出去來提供更多的記憶體空間,很明顯這個開銷不小,
為了解決行程空間動態增長的問題,我們可以提前多給一些空間,比如行程本身需要10M,我們多給2M,這樣如果行程發生增長的時候,可以利用這2M空間,當然前提是這2M空間夠用,如果不夠用還是得觸發同樣的移動、換出邏輯,
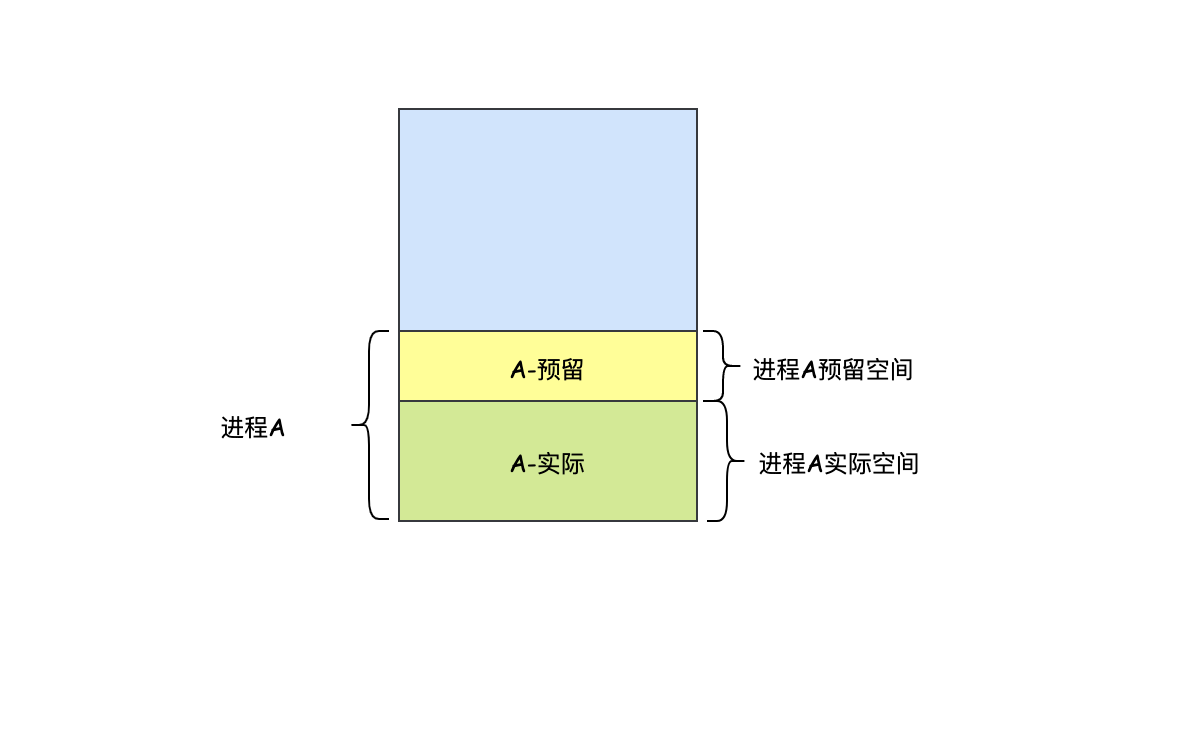
空閑的記憶體如何管理
前面我們說到記憶體的交換技術,交換技術的目的是騰出空閑記憶體來,那么我們是如何知道一塊記憶體是被使用了,還是空閑的?因此需要一套機制來區分出空閑記憶體和已使用記憶體,一般作業系統對記憶體管理的方式有兩種:位圖法和鏈表法,
位圖法
先說位圖法,沒錯,位圖法采用位元位的方式來管理我們的記憶體,每塊記憶體都有位置,我們用一個位元位來表示:
- 如果某塊記憶體被使用了,那么位元位為1
- 如果某塊記憶體是空閑的,那么位元位為0
這里的某塊記憶體具體是多大得看作業系統是如何管理的,它可能是一個位元組、幾個位元組甚至幾千個位元組,但是這些不是重點,重點是我們要知道記憶體被這樣分割了,
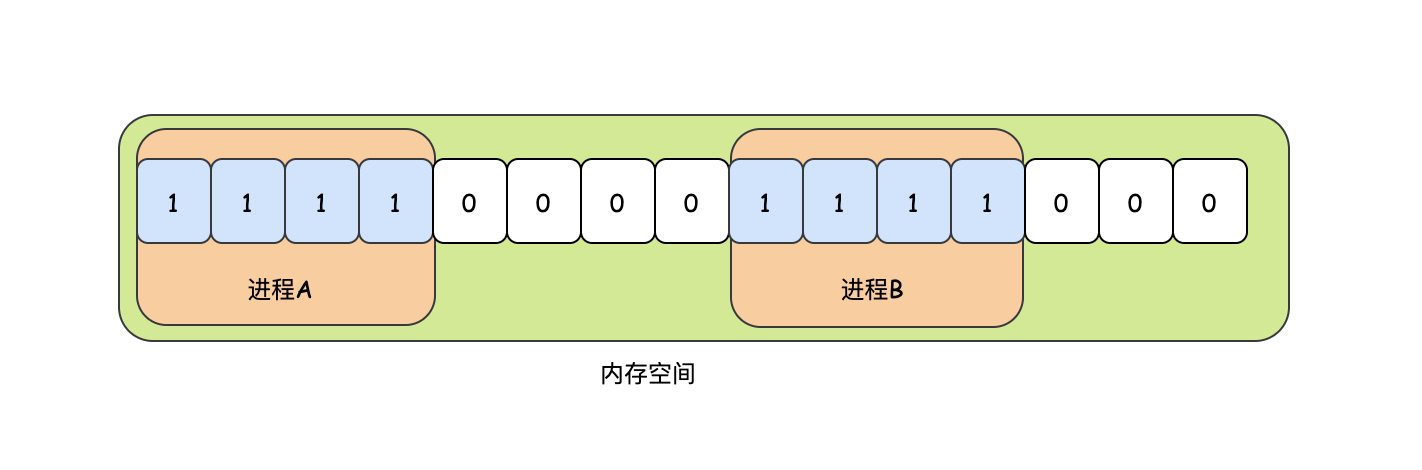
位圖法的優點就是清晰明確,某個記憶體塊的狀態可以通過位圖快速的知道,因為它的時間復雜度是O(1),當然它的缺點也很明顯,就是需要占用太多的空間,尤其是管理的記憶體塊越小的時候,更糟糕的是,行程分配的空間不一定是記憶體塊的整數倍,那么最后一個記憶體塊中一定是有浪費的,
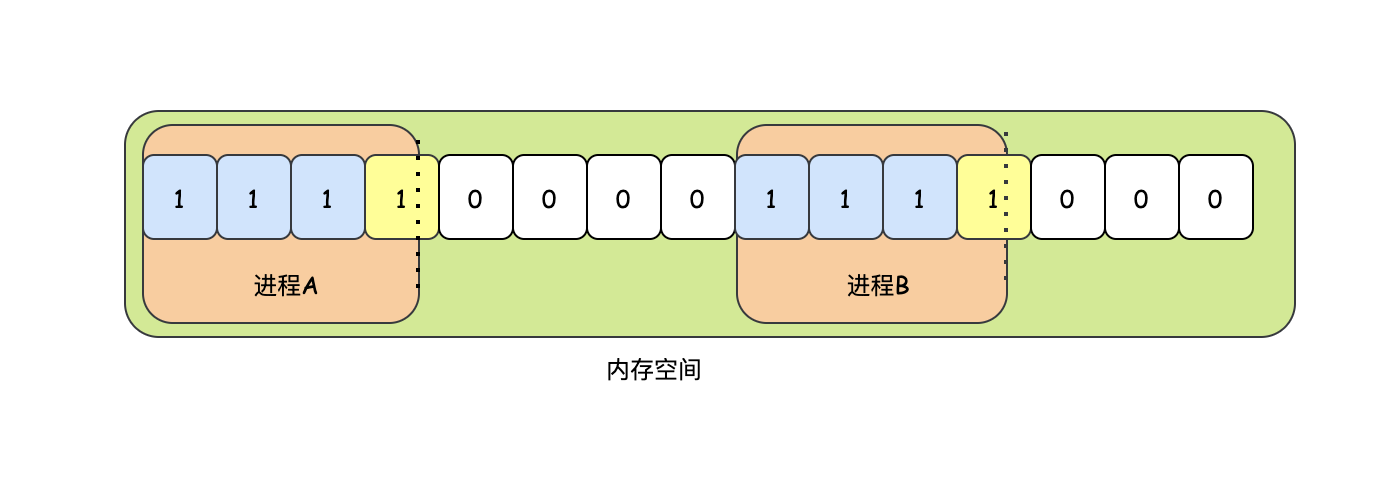
如圖,行程A和行程B都占用的最后一個記憶體塊的一部分,那么對于最后一個記憶體塊,它的另一部分一定是浪費的,
鏈表法
相比位圖法,鏈表法對空間的利用更加合理,我相信你應該已經猜到了,鏈表法簡單理解就是把使用的和空閑的記憶體用鏈表的方式連接起來,那么對于每個鏈表的元素節點來說,他應該具備以下特點:
- 應該知道每個節點是空閑的還是被使用的
- 每個節點都應該知道當前節點的記憶體的開始地址和結束地址
針對這些特點,最終記憶體對應的鏈表節點大概是這樣的:
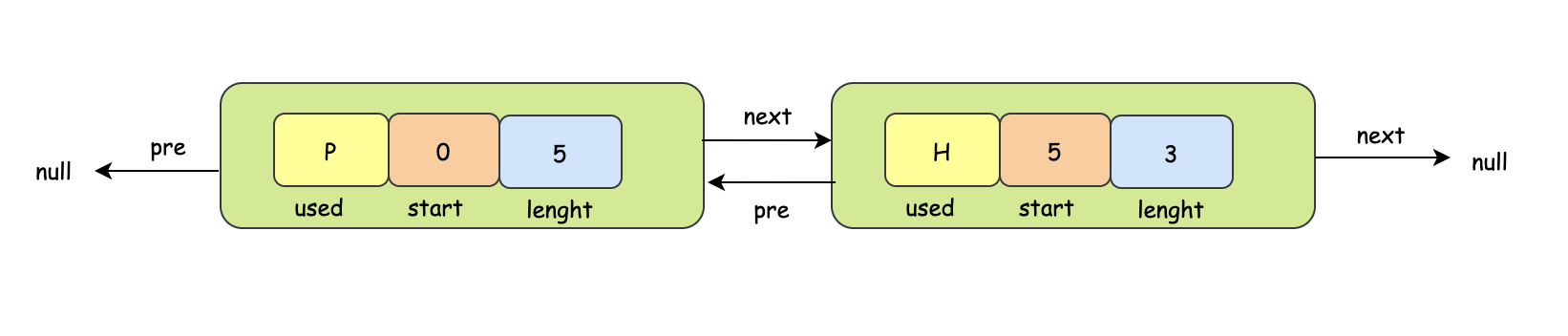
p代表這個節點對應的記憶體空間是被使用的,H代表這個節點對應的記憶體空間是空閑的,start代表這塊記憶體空間的開始地址,length代表的是這塊記憶體的長度,最后還有指向鄰居節點的pre和next指標,
因此對于一個行程來說,它與鄰居的組合有四種:
- 它的前后節點都不是空閑的
- 它的前一個節點是空閑的,它的后一個節點也不是空閑的
- 它的前一個節點不是空閑的,它的后一個節點是空閑的
- 它的前后節點都是空閑的
當一個記憶體節點被換出或者說行程結束后,那么它對應的記憶體就是空閑的,此時如果它的鄰居也是空閑的,就會發生合并,即兩塊空閑的記憶體塊合并成一個大的空閑記憶體塊,
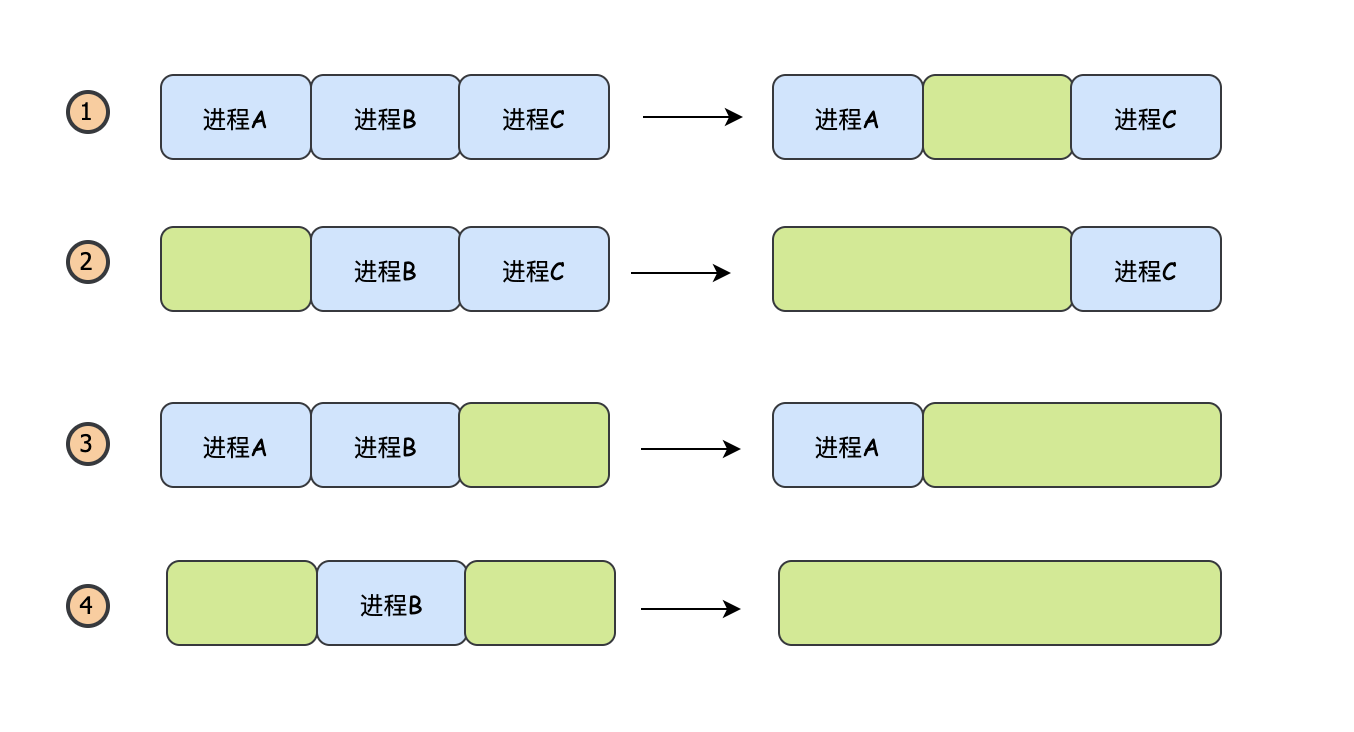
ok,通過鏈表的方式把我們的記憶體給管理起來了,接下來就是當創建一個行程或者從磁盤換入一個行程的時候,如何從鏈表中找到一塊合適的記憶體空間?
首次適應演算法
其實想要找到空閑記憶體空間最簡單的辦法就是順著鏈表找到第一個滿足需要記憶體大小的節點,如果找到的第一個空閑記憶體塊和我們需要的記憶體空間是一樣大小的,那么就直接利用,但是這太理想了,現實情況大部分可能是找到的第一個目標記憶體塊要比我們的需要的記憶體空間要大一些,這時候呢,會把這個空閑記憶體空間分成兩塊,一塊正好使用,一塊繼續充當空閑記憶體塊,
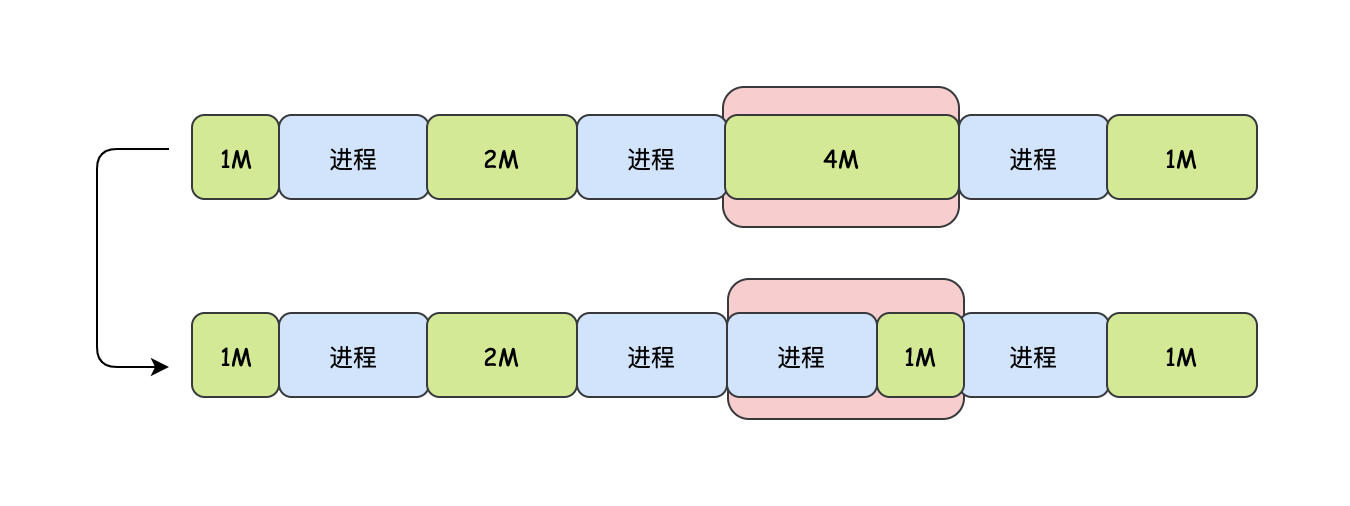
一個需要3M記憶體的行程,會把4M的空間拆分成3M和1M,
下次適配演算法
和首次適應演算法很相似,在找到目標記憶體塊后,會記錄下位置,這樣下次需要再次查找記憶體塊的時候,會從這個位置開始找,而不用從鏈表的頭節點開始尋找,這個演算法存在的問題就是,如果標記的位置之前有合適的記憶體塊,那么就會被跳過,
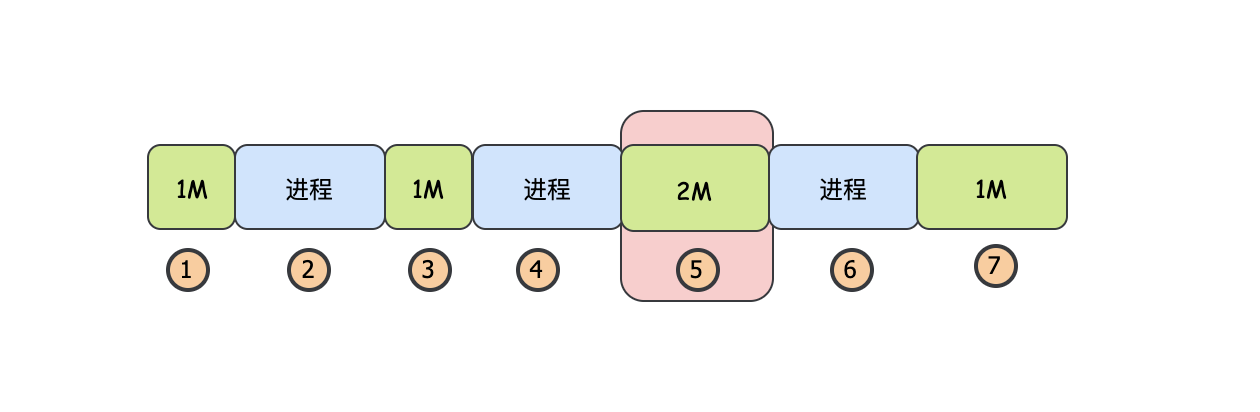
一個需要2M記憶體的行程,在5這個位置找到了合適的空間,下次如果需要這1M的記憶體會從5這個位置開始,然后會在7這個位置找到合適的空間,但是會跳過1這個位置,
最佳適配演算法
相比首次適應演算法,最佳適配演算法的區別就是:不是找到第一個合適的記憶體塊就停止,而是會繼續向后找,并且每次都可能要檢索到鏈表的尾部,因為它要找到最合適那個記憶體塊,什么是最合適的記憶體塊呢?如果剛好大小一致,則一定是最合適的,如果沒有大小一致的,那么能容得下行程的那個最小的記憶體塊就是最合適的,可以看出最佳適配演算法的平均檢索時間相對是要慢的,同時可能會造成很多小的碎片,
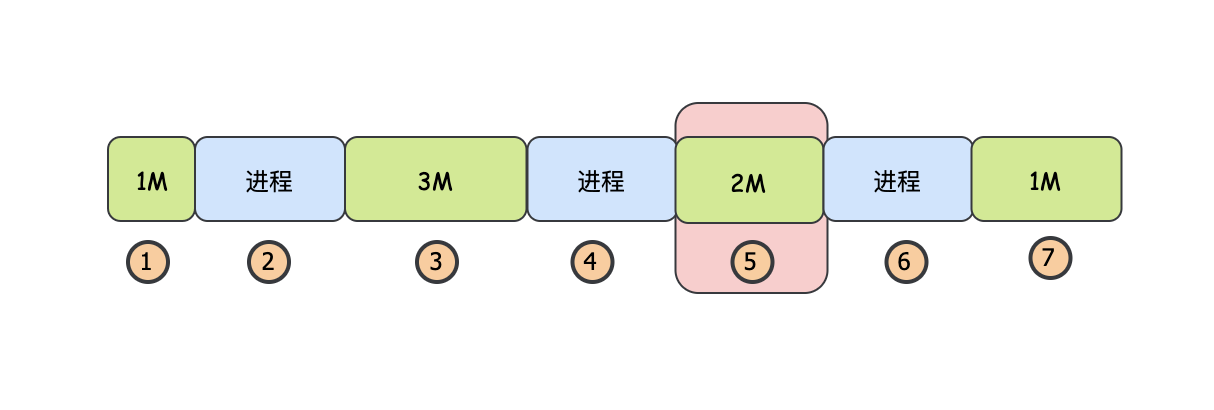
假設現在行程需要2M的記憶體,那么最佳適配演算法會在檢索到3號位置(3M)后,繼續向后檢索,最侄訓選擇5號位置的空閑記憶體塊,
最差適配演算法
我們知道最佳適配演算法中最佳的意思是找到一個最貼近真實大小的空閑記憶體塊,但是這會造成很多細小的碎片,這些細小的碎片一般情況下,如果沒有進行記憶體緊湊,那么大概率是浪費的,為了避免這種情況,就出現了這個最差適配演算法,這個演算法它和最佳適配演算法是反著來的,它每次嘗試分配最大的可用空閑區,因為這樣的話,理論上剩余的空閑區也是比較大的,記憶體碎片不會那么小,還能得到重復利用,
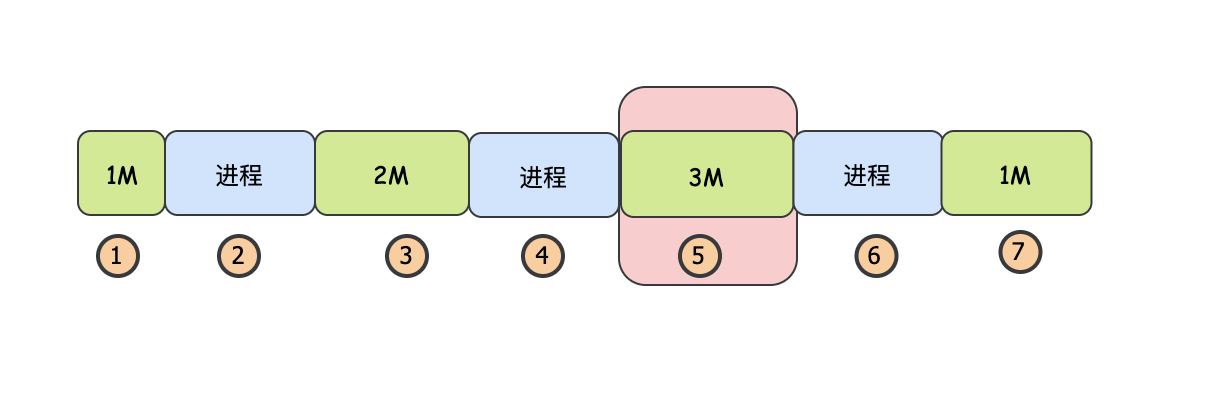
一個需要1.5M的行程,在最差適配演算法情況下,不會選擇3號(2M)記憶體空閑塊,而是會選擇更大的5號(3M)記憶體空閑塊,
快速適配演算法
上面的幾種演算法都有一個共同的特點:空閑記憶體塊和已使用記憶體塊是共用的一個鏈表,這會有什么問題呢?正常來說,我要查找一個空閑塊,我并不需要檢索已經被使用的記憶體塊,所以如果能把已使用的和未使用的分開,然后用兩個鏈表分別維護,那么上面的演算法無論哪種,速度都將得到提升,并且節點也不需要P和M來標記狀態了,但是分開也有缺點,如果行程終止或者被換出,那么對應的記憶體塊需要從已使用的鏈表中刪掉然后加入到未使用的鏈表中,這個開銷是要稍微大點的,當然對于未使用的鏈表如果是排序的,那么首次適應演算法和最佳適應演算法是一樣快的,
快速適配演算法就是利用了這個特點,這個演算法會為那些常用大小的空閑塊維護單獨的鏈表,比如有4K的空閑鏈表、8K的空閑鏈表...,如果要分配一個7K的記憶體空間,那么既可以選擇兩個4K的,也可以選擇一個8K的,
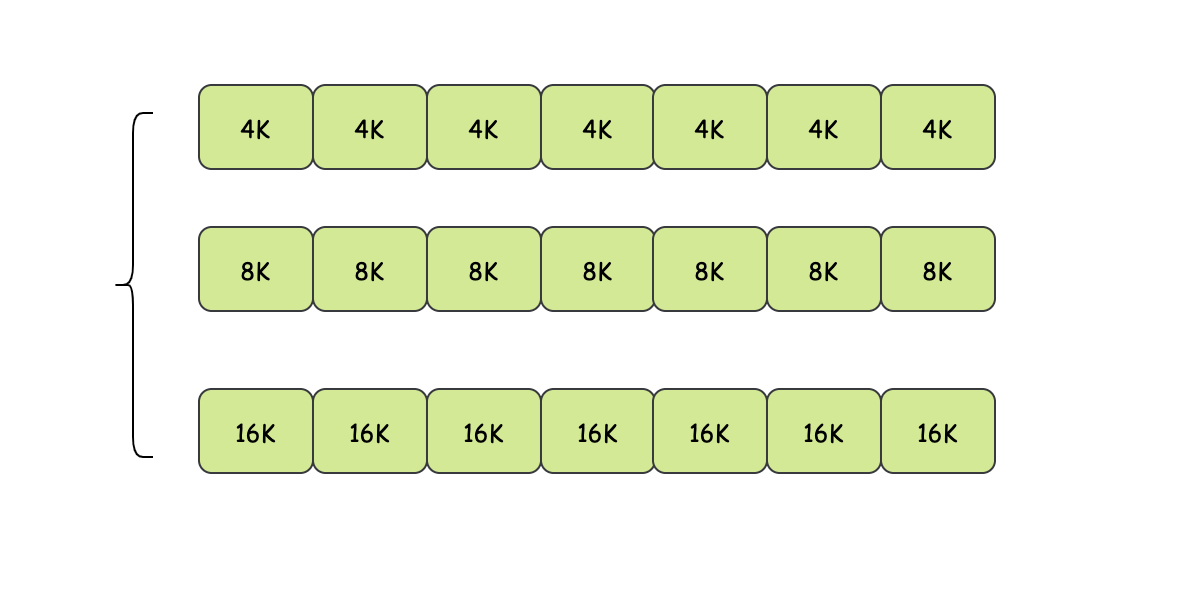
它的優點很明顯,在查找一個指定大小的空閑區會很快速,但是一個行程終止或被換出時,會尋找它的相鄰塊查看是否可以合并,這個程序相對較慢,如果不合并的話,那么同樣也會產生很多的小空閑區,它們可能無法被利用,造成浪費,
虛擬記憶體:小記憶體運行大程式
可能你看到小記憶體運行大程式比較詫異,因為上面不是說到了嗎?只要把空閑的行程換出去,把需要運行的行程再換進來不就行了嗎?記憶體交換技術似乎解決了,這里需要注意的是,首先記憶體交換技術在空間不夠的情況下需要把行程換出到磁盤上,然后從磁盤上換入新行程,看到磁盤你可能明白了,很慢,其次,你發現沒,換入換出的是整個行程,我們知道行程也是由一塊一塊代碼組成的,也就是許許多多的機器指令,對于記憶體交換技術來說,一個行程下的所有指令要么全部進記憶體,要么全部不進記憶體,看到這里你可能覺得這不是正常嗎?好的,別急,我們接著往下看,
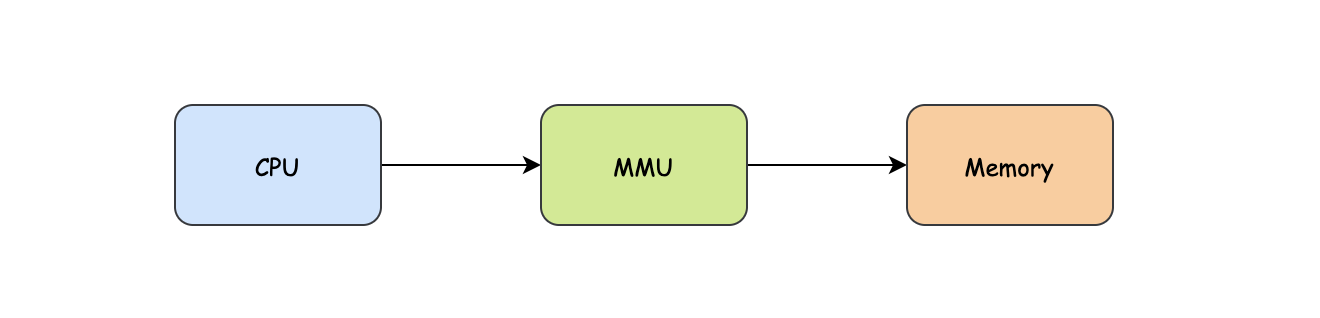
后來出現了更牛逼的技術:虛擬記憶體,它的基本思想就是,每個程式擁有自己的地址空間,尤其注意后面的自己的地址空間,然后這個空間可以被分割成多個塊,每一個塊我們稱之為頁(page)或者叫頁面,對于這些頁來說,它們的地址是連續的,同時它們的地址是虛擬的,并不是真正的物理記憶體地址,那怎么辦?程式運行需要讀到真正的物理記憶體地址,別跟我玩虛的,這就需要一套映射機制,然后MMU出現了,MMU全稱叫做:Memory Managment Unit,即記憶體管理單元,正常來說,CPU讀某個記憶體地址資料的時候,會把對應的地址發到記憶體總線上,但是在虛擬記憶體的情況下,直接發到記憶體總線上肯定是找不到對應的記憶體地址的,這時候CPU會把虛擬地址告訴MMU,讓MMU幫我們找到對應的記憶體地址,沒錯,MMU就是一個地址轉換的中轉站,
程式地址分頁的好處是:
- 對于程式來說,不需要像記憶體交換那樣把所有的指令都加載到記憶體中才能運行,可以單獨運行某一頁的指令
- 當行程的某一頁不在記憶體中的時候,CPU會在這個頁加載到記憶體的程序中去執行其他的行程,
當然虛擬記憶體會分頁,那么對應的物理記憶體其實也會分頁,只不過物理記憶體對應的單元我們叫頁框,頁面和頁框通常是一樣大的,我們來看個例子,假設此時頁面和頁框的大小都是4K,那么對于64K的虛擬地址空間可以得到64/4=16個虛擬頁面,而對于32K的物理地址空間可以得到32/4=8個頁框,很明顯此時的頁框是不夠的,總有些虛擬頁面找不到對應的頁框,
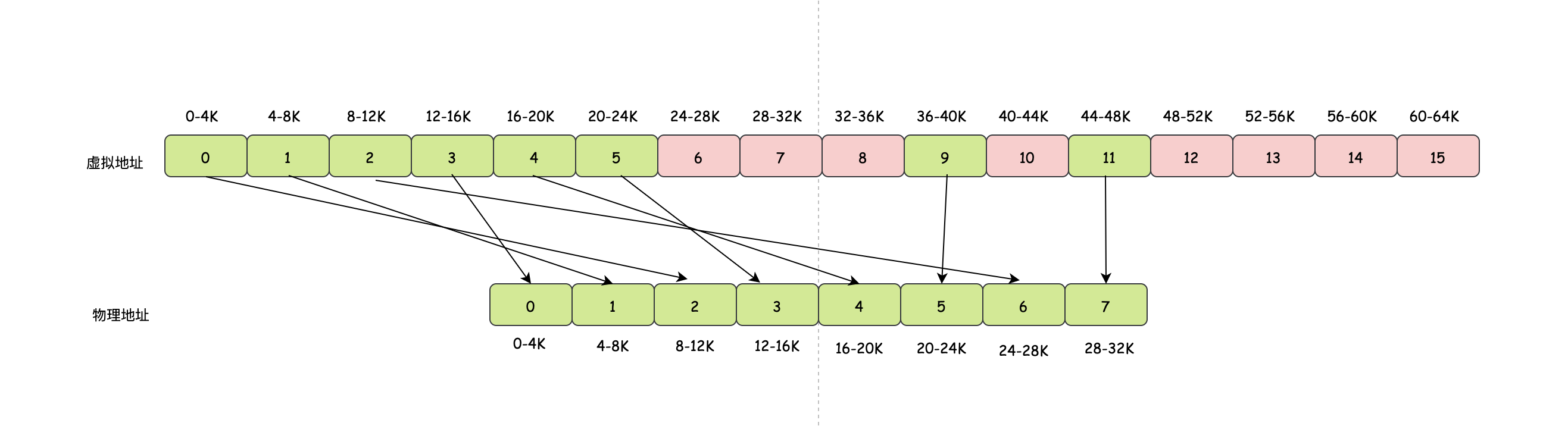
我們先來看看虛擬地址為20500對應物理地址如何被找到的:
- 首先虛擬地址20500對應5號頁面(20480-24575)
- 5號頁面的起始地址20480向后查找20個位元組,就是虛擬地址的位置
- 5號頁面對應3號物理頁框
- 3號物理頁框的起始地址是12288,12288+20=12308,即12308就是我們實際的目標物理地址,
但是對于虛擬地址而言,圖中還有紅色的區域,上面我們也說到了,總有些虛擬地址沒有對應的頁框,也就是這部分虛擬地址是沒有對應的物理地址,當程式訪問到一個未被映射的虛擬地址(紅色區域)的時候,那么就會發生缺頁中斷,然后作業系統會找到一個最近很少使用的頁框把它的內容換到磁盤上去,再把剛剛發生缺頁中斷的頁面從磁盤讀到剛付訓收的頁框中去,最后修改虛擬地址到頁框的映射,然后重啟引起中斷的指令,
最后可以發現分頁機制使我們的程式更加細膩了,運行的粒度是頁而不是整個行程,大大提高了效率,
頁表
上面說到虛擬記憶體到物理記憶體有個映射,這個映射我們知道是MMU做的,但是它是如何實作的?最簡單的辦法就是需要有一張類似hash表的結構來查看,比如頁面1對應的頁框是10,那么就記錄成hash[1]=10,但是這僅僅是定位到了頁框,具體的位置還沒定位到,也就是類似偏移量的資料沒有,不猜了,我們直接來看看MMU是如何做到的,以一個16位的虛擬地址,并且頁面和頁框都是4K的情況來說,MMU會把前4位當作是索引,也就是定位到頁框的序號,后12位作為偏移量,這里為什么是12位,很巧妙,因為2^12=4K,正好給每個頁框里的資料上了個標號,因此我們只需要根據前4位找到對應的頁框即可,然后偏移量就是后12位,找頁框就是去我們即將要說的頁表里去找,頁表除了有頁面對應的頁框后,還有個標志位來表示對應的頁面是否有映射到對應的頁框,缺頁中斷就是根據這個標志位來的,
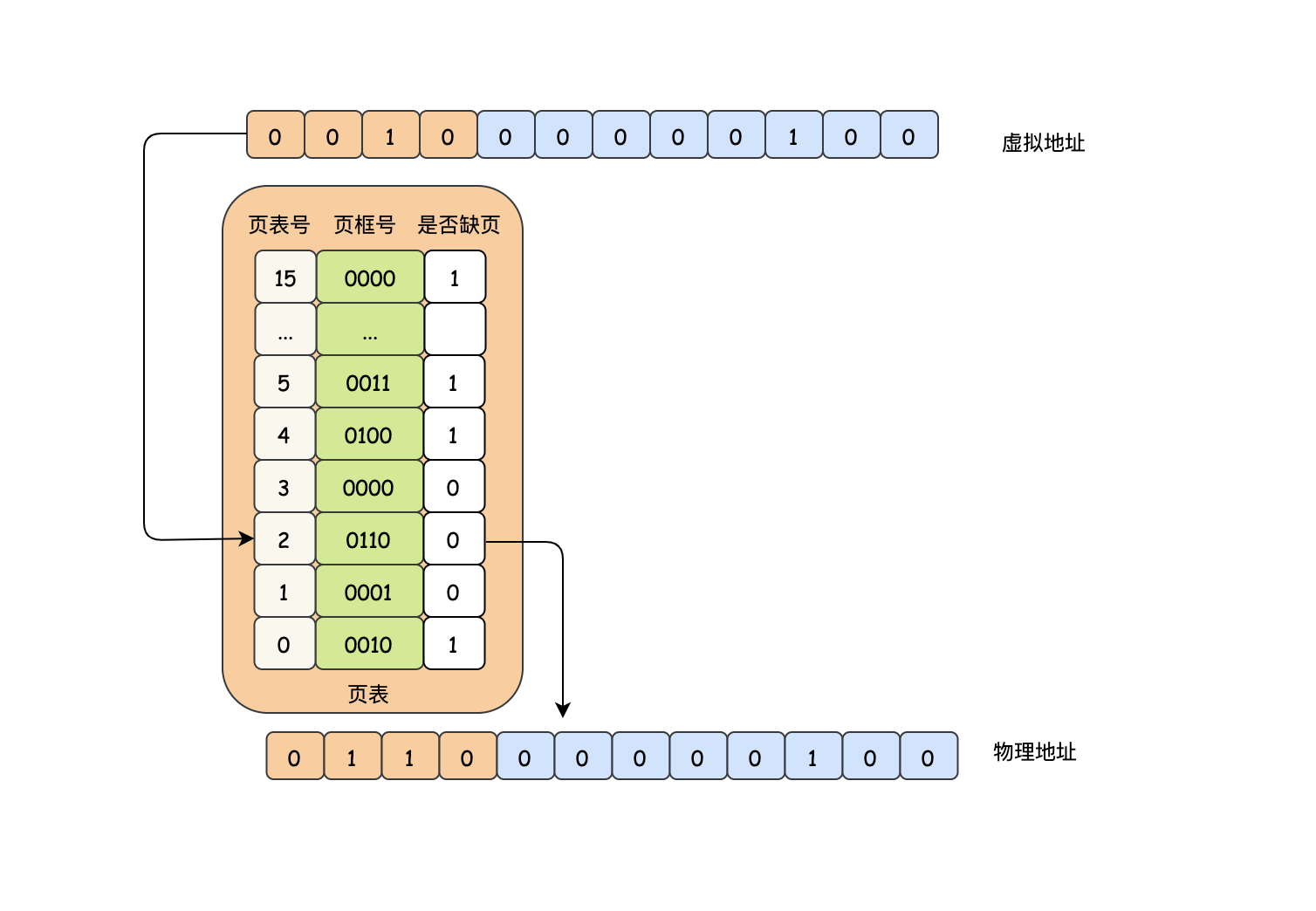
可以看出頁表非常關鍵,不僅僅要知道頁框、以及是否缺頁,其實頁表還有保護位、修改位、訪問位和高速快取禁止位,
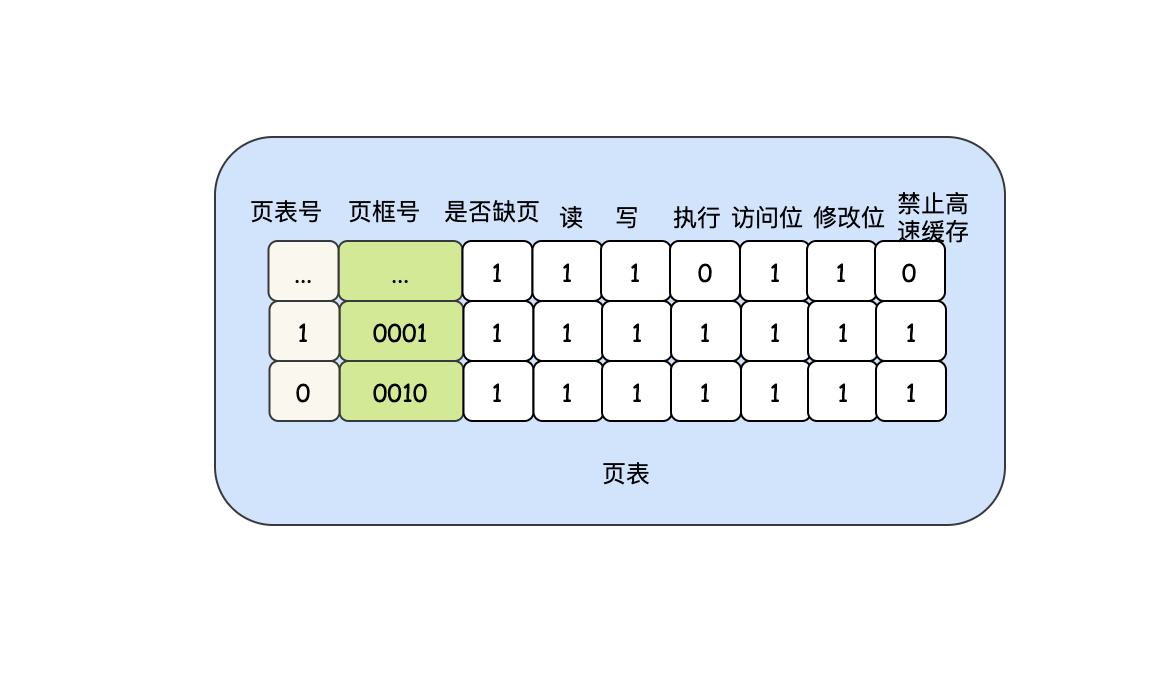
- 保護位:指的是一個頁允許什么型別的訪問,常見的是用三個位元位分別表示讀、寫、執行,
- 修改位:有時候也稱為臟位,由硬體自動設定,當一個頁被修改后,也就是和磁盤的資料不一致了,那么這個位就會被標記為1,下次在頁框置換的時候,需要把臟頁刷回磁盤,如果這個頁的標記為0,說明沒有被修改,那么不需要刷回磁盤,直接把資料丟棄就行了,
- 訪問位:當一個頁面不論是發生讀還是發生寫,該頁面的訪問位都會設定成1,表示正在被訪問,它的作用就是在發生缺頁中斷時,根據這個標志位優先在那些沒有被訪問的頁面中選擇淘汰其中的一個或者多個頁框,
- 高速快取禁止位:對于那些映射到設備暫存器而不是常規記憶體的頁面而言,這個特性很重要,加入作業系統正在緊張的回圈等待某個IO設備對它剛發出的指令做出回應,保證這個設備讀的不是被高速快取的副本非常重要,
TLB快表加速訪問
通過頁表我們可以很好的實作虛擬地址到物理地址的轉換,然而現代計算機至少是32位的虛擬地址,以4K為一頁來說,那么對于32位的虛擬地址,它的頁表項就有2^20=1048576個,無論是頁表本身的大小還是檢索速度,這個數字其實算是有點大了,如果是64位虛擬的地址,按照這種方式的話,頁表項將大到超乎想象,更何況最重要的是每個行程都會有一個這樣的頁表,
我們知道如果每次都要在龐大的頁表里面檢索頁框的話,效率一定不是很高,而且計算機的設計者們觀察到這樣一種現象:大多數程式總是對少量的頁進行多次訪問,如果能為這些經常被訪問的頁單獨建立一個查詢頁表,那么速度就會大大提升,這就是快表,快表只會包含少量的頁表項,通常不會超過256個,當我們要查找一個虛擬地址的時候,首先會在快表中查找,如果能找到那么就可以直接回傳對應的頁框,如果找不到才會去頁表中查找,然后從快表中淘汰一個表項,用新找到的頁替代它,
總體來說,TLB類似一個體積更小的頁表快取,它存放的都是最近被訪問的頁,而不是所有的頁,
多級頁表
TLB雖然一定程度上可以解決轉換速度的問題,但是沒有解決頁表本身占用太大空間的問題,其實我們可以想想,大部分程式會使用到所有的頁面嗎?其實不會,一個行程在記憶體中的地址空間一般分為程式段、資料段和堆疊段,堆疊段在記憶體的結構上是從高地址向低地址增長的,其他兩個是從低地址向高地址增長的,
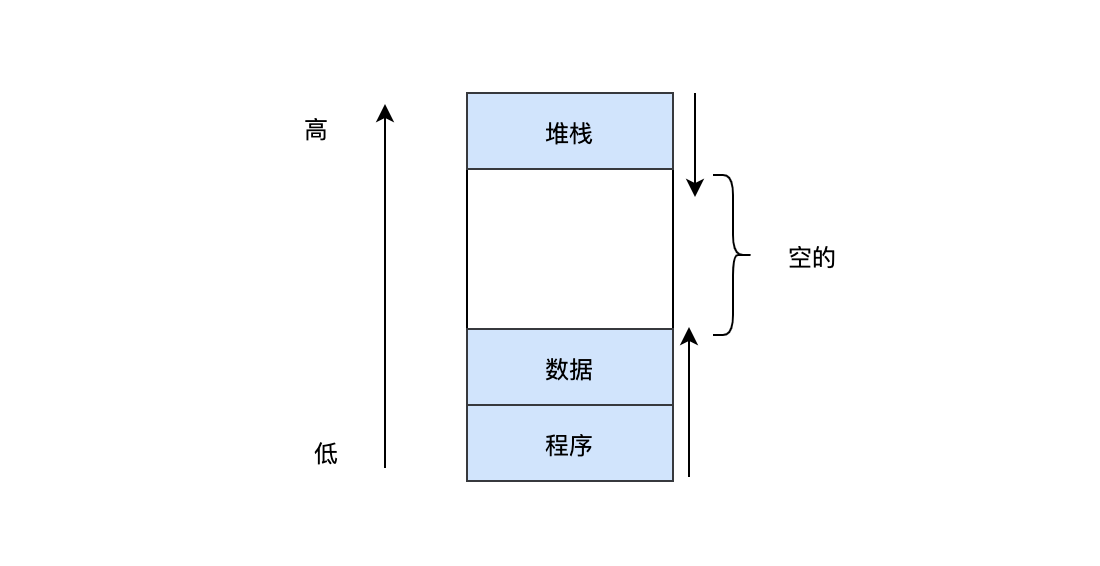
可以發現中間部分是空的,也就是這部分地址是用不到的,那我們完全不需要把中間沒有被使用的記憶體地址也引入頁表呀,這就是多級頁表的思想,以32位地址為例,后12位是偏移量,前20位可以拆成兩個10位,我們暫且叫做頂級頁表和二級頁表,每10位可以表示2^10=1024個表項,因此它的結構大致如下:
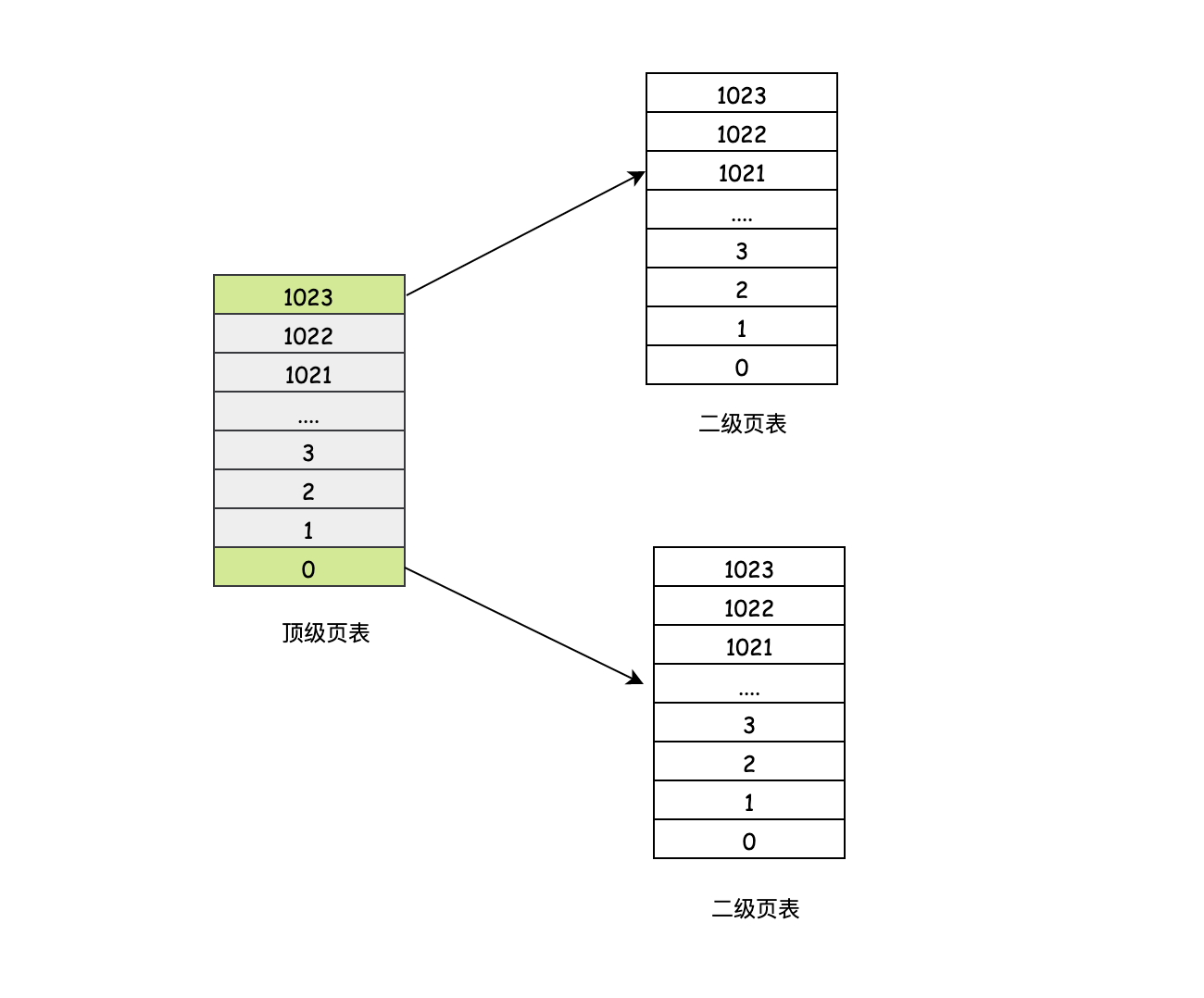
對于頂級頁表來說,中間灰色的部分就是沒有被使用的記憶體空間,頂級頁表就像我們身份證號前面幾個數字,可以定位到我們是哪個城市或者縣的,二級頁表就像身份證中間的數字,可以定位到我們是哪個街道或者哪個村的,最后的偏移量就像我們的門牌號和姓名,通過這樣的分段可以大大減少空間,我們來看個簡單的例子:
如果我們不拆出頂級頁表和二級頁表,那么所需要的頁表項就是2^20個,如果我們拆分,那么就是1個頂級頁表+2^10個二級頁表,兩者的存盤差距明顯可以看出拆分后更加節省空間,這就是多級頁表的好處,
當然我們的二級也可以拆成三級、四級甚至更多級,級數越多靈活性越大,但是級數越多,檢索越慢,這一點是需要注意的,
最后
為了便于大家理解,本文畫了20張圖,肝了將近7000多字,創作不易,各位的三連就是對作者最大的支持,也是作者最大的創作動力,
微信搜一搜【假裝懂編程】,加入我們,與作者共同學習,共同進步,

往期精彩:
- 簡單!代碼原來是這樣被CPU跑起來的
- 20張圖!常見分布式理論與解決方案
- 小心陷入MySQL索引的坑
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/348445.html
標籤:其他
上一篇:資料結構之線性表