
前言:
本章節將對鏈表的概念進行介紹,著重講解單順序表,對常用的介面函式進行一個個講解,并進行決議,單鏈表表講解部分將從零實作常見單鏈表介面函式,我會盡量加快資料結構的更新速度,還希望大家多多三連支持!
🔗 C語言教學專欄:《維生素C語言》
一、鏈表介紹
0x00 鏈表的概念

📚 概念:鏈表是一種物理存盤結構上非連續、非順序的存盤結構,陣列元素的邏輯順序是通過鏈表中的指標鏈接次序實作的,
0x01 順序表和鏈表的優缺點
? 為什么線性表和鏈表各自存在?
💡 因為他們各有優點,他們是互補的,并不是有他沒我,有我沒他的,
? 順序表的優點:

① 支持隨機訪問,有些演算法需要結構隨機訪問,比如二分查找和優化的快排等,
② 資料是按順序存放的,空間利用率高,
③ 通過下標直接訪問,存取速度高效,
? 順序表的缺陷:
① 空間不夠了就需要擴容,擴容是存在消耗的,
② 頭部或者中間位置的插入或洗掉,需要挪動,挪動資料時也是存在消耗的,
③ 避免頻繁擴容,一次一般都是按倍數去擴容(2倍適中),可能存在一定空間的浪費現象,
0x02 順序表的優缺點
? 鏈表的優點:
① 按需申請空間,不用就釋放空間( 鏈表可以更合理地使用空間),
② 頭部或者中間位置的插入和洗掉,不需要挪動資料,
③ 不存在空間浪費,
? 鏈表的缺陷:
① 每一個資料,都要存一個指標去鏈接后面的資料節點,
② 不支持隨機訪問(用下標直接訪問第 i 個),必須得走 O(N) ,
Tips:單鏈表的缺陷還是很多的,單純單鏈表的增刪查找的意義不大,但是很多OJ題考察的都是單鏈表,單鏈表多用于更復雜的資料結構的子結構,如哈希桶,鄰接表等,所以真正存盤資料還是得靠雙向鏈表,
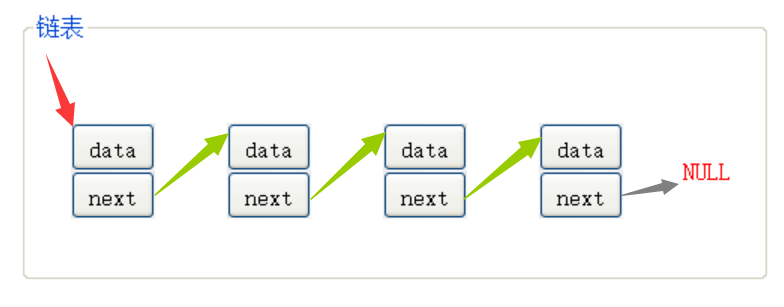
0x03 鏈表的結構
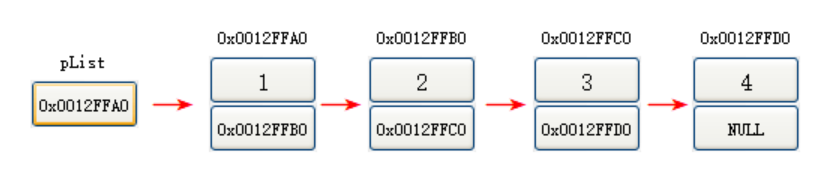
① 邏輯結構:便于更形象方便地理解而想象出來的(比如這個箭頭其實不存在),
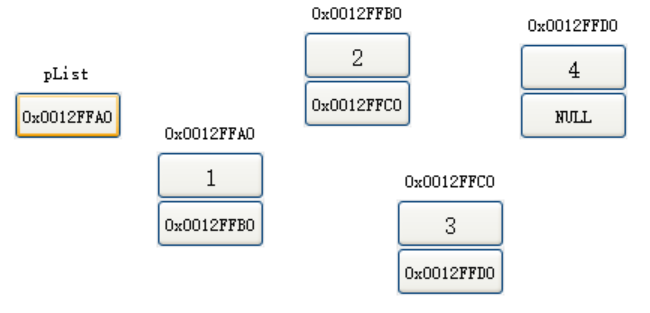
② 物理結構:在記憶體中是實實在在如何存盤,
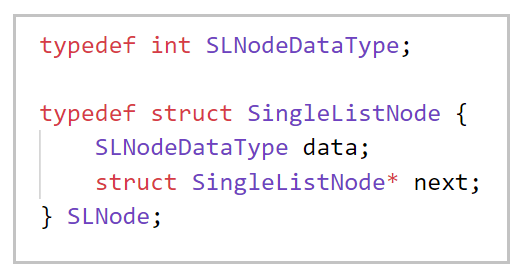
二、單鏈表的定義
0x00 定義單鏈表
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
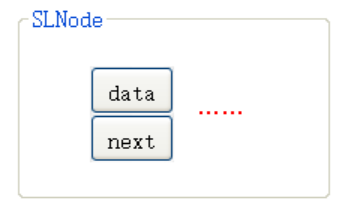
🔑 解讀:在順序表章節講過,為了方便后續使用我們將型別 typedef 一下,首先創建結構體,因為叫單鏈表,所以我們將它取為 SingleListNode,結構體有兩個變數,data 是用來存放節點的資料的變數,而 next 是用來指向后繼節點指標的變數,我們詳細來說說結構體指標 next,它的型別是 struct SingleListNode* 也就是自己本身,從而實作 "套娃" 的效果,這么一來它就擁有了 "鏈接" 的資本(既可以存資料,又可以存下一個節點的地址,簡直是一直用一直爽啊),為了方便后續地使用,我們再把這個結構體重命名成 SLNode(非常合理的簡寫,SingleListNode),
0x01 介面函式
📚 這是需要實作幾個介面函式:
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode** pHead, SLNodeDataType x);
void SListPushFront(SLNode** ppHead, SLNodeDataType x);
void SListPopBack(SLNode** pHead);
void SListPopFront(SLNode** pHead);
SLNode* SListFind(SLNode* pHead, SLNodeDataType x);
void SListInsert(SLNode** ppHead, SLNode* pos, SLNodeDataType x);
//void SListInsert(SLNode* pHead, int pos, SLNodeDataType x);
void SListEarse(SLNode** ppHead, SLNode* pos);
void SListDestroy(SLNode** ppHead);
void SListInsertAfter(SLNode* pos, SLNodeDataType x);三、詳解介面函式的實作
0x00 列印(SListPrint)
💬 SList.h
#pragma once
#include <stdio.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
void SListPrint(SLNode* pHead);🔑 解讀:用結構體指標 *pHead 接收, 這里 *pHead 就表示頭結點,我下面會詳細說一下,
💬 SList.c
#include "SList.h"
/* 列印 */
void SListPrint (
SLNode* pHead //pHead為形參,是pList的一份臨時拷貝(取名為pHead方便區分)
)
{
SLNode* cur = pHead; //工具人
while (cur != NULL) //cursor不為空時進入回圈
{
printf("%d -> ", cur->data); //列印data中的內容
cur = cur->next; //令cursor指向后繼節點
}
printf("NULL\n");
}🔑 解讀:我們想實作單鏈表的列印,我們就需要遍歷整個鏈表,首先創建一個結構體指標 cur 來存放 pHead ,然后通過 cur 來把整個鏈表走一遍,只要 cur 不為 NULL,就說明還沒有走完,就進入回圈,回圈體內列印出當前 cur->data 的內容,就實作了列印節點中的內容,隨后將 cur 賦值成 cur->next ,使得 cur 指向它后面的節點,當 cur 為 NULL 時說明已經走完了,則跳出回圈,最后我們再列印一個 "NULL" 把鏈表的尾部表示出來(便于除錯觀看),
💬 Test.c
這里我們還沒寫什么東西,就不寫測驗用例了, (其實是作者想偷懶 )
0x01 尾插(SListPushBack)
💬 SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode** pHead, SLNodeDataType x);🔑 解讀:創建一個新節點,我們就需要動態開辟記憶體,所以我們要引入 #include <stdlib.h> 這個頭檔案,SListPushBack 函式引數為 SLNode** pHead,這里用 "二級指標" 接收,因為傳入的就是一個結構體指標的地址(&pList),它本身就是一個指標了,所以這里我們就需要用指標的指標(即二級指標)來接收它,因為形參是實參的一份臨時拷貝,至于這里為什么傳入 &pList 呢?因為形參只是實參的一份臨時拷貝,為了能夠改變外部,所以我們要采用址傳遞(即傳入結構體指標 pList 的地址并用二級指標接收),
💬 SList.c
/* 尾插 */
void SListPushBack (
SLNode** ppHead, //頭結點,二級指標
SLNodeDataType x //傳入的資料
)
{
//創建新節點
SLNode* new_node = (SLNode*)malloc(sizeof(SLNode));
// 檢查是否擴容失敗
if (new_code == NULL)
{
printf("malloc failed!\n");
exit(-1);
}
//放置
new_code->data = x; //要傳入的資料
new_code->next = NULL; //next默認置為空
//如果鏈表是空的
if (*ppHead == NULL)
{
//直接插入即可
*ppHead = new_node;
}
else
{
//找到尾結點
SLNode* end = *ppHead;
while (end->next != NULL)
{
end = end->next; //令end指向后繼節點
}
//插入
end->next = new_node;
}
}🔑 解讀:
Step1:首先我們需要創建新的節點,定義一個新的結構體指標變數 new_node 作為新節點,這里我們 malloc 一塊能放得下 SLNode 的空間就夠了,這里我們檢查下擴容是否失敗,現在計算機存盤今非昔比,已經到了幾乎不可能出現擴容失敗的情況了,但我還是喜歡檢查一下,我們在動態記憶體開辟章節就建議大家養成這個習慣了,它畢竟是個好習慣,隨后我們就可以往 new_node 里面放置內容了, new_node->data 中存放我們要傳入的資料,因為創建新節點時我們也不確定下面到底有沒有資料,所以 new_node->next 置為 NULL,創建新節點需要做的事情就這么多,
Step2:當新節點創建完畢后,我們就可以開始寫尾插了,如果鏈表沒有資料的話我們就可以直接插入,豈不美哉?所以我們先判斷鏈表是否為空,這里記得對 *ppHead 解參考,如果鏈表是空的,我們就直接把 new_code 賦給 *ppHead 即可完成插入,如果鏈表是有資料的,我們要實作尾部插入,我們就要找到尾節點,這里我們創建一個尋尾指標 SLNode* end 作為工具人,來替代 *ppHead 去找尾節點,思路也很簡單,如果 end 的下一個節點不為空,就進入回圈,令 end 指向后繼節點,這樣 end 就成功找到了尾節點,最后 end->next 就是尾節點了,我們把 new_code 賦給 end->next 即可完成插入,
💬 Test.c
寫到這里,我們就可以來測驗下我們之前寫的東西了:
#include "SList.h"
void TestSList1()
{
SLNode* pList = NULL;
SListPushBack(&pList, 1);
SListPushBack(&pList, 2);
SListPushBack(&pList, 3);
SListPushBack(&pList, 4);
SListPrint(pList);
}
int main()
{
TestSList1();
return 0;
}
🔑 解讀:
① 列印決議:
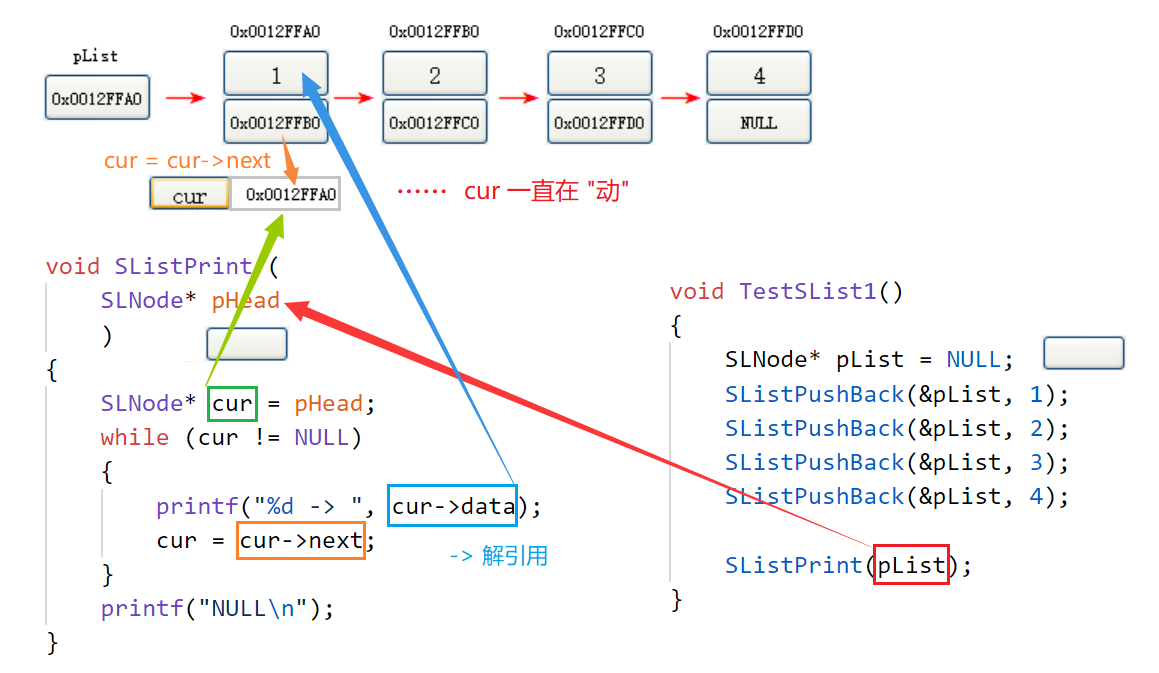
② 尾插決議: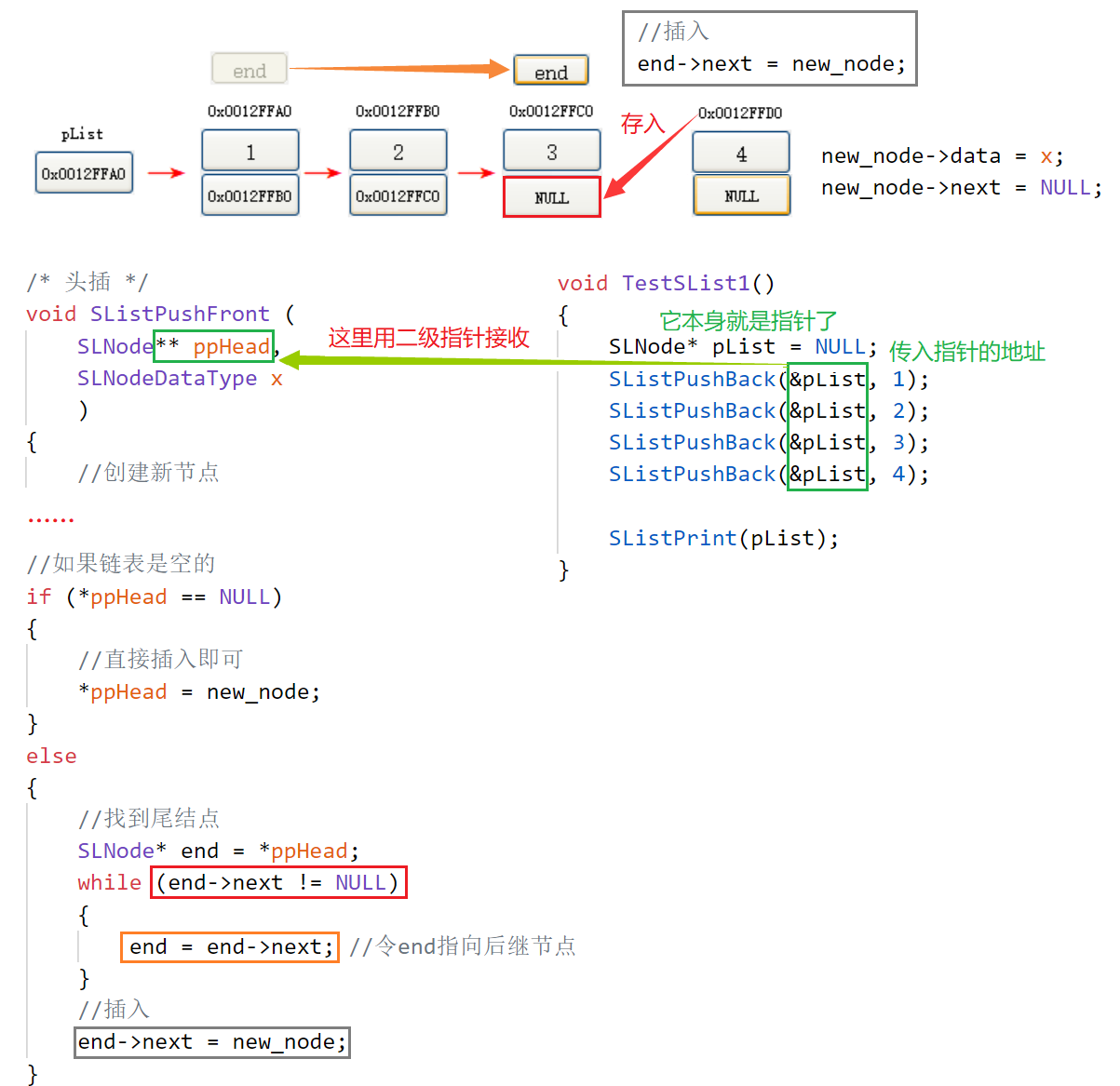
0x02 創建新節點(CreateNewNode)
? 考慮到創建新節點要經常用,為了方便復用,我們把它寫成函式(CreateNewNode):
/* 創建新節點 */
SLNode* CreateNewNode (
SLNodeDataType x //傳入的資料
)
{
//創建,開辟空間
SLNode* new_node = (SLNode*)malloc(sizeof(SLNode));
//malloc檢查
if (new_node == NULL)
{
printf("malloc failed!\n");
exit(-1);
}
//放置
new_node->data = x; //存傳入的資料
new_node->next = NULL; //next默認置空
return new_node; //遞交新節點
}💬 SList.c:更新一下剛才尾插的寫法
/* 尾插 */
void SListPushBack (
SLNode** ppHead, //頭結點,二級指標
SLNodeDataType x //傳入的資料
)
{
//創建新節點
SLNode* new_node = CreateNewNode(x);
//如果鏈表是空的
if (*ppHead == NULL)
{
//直接插入即可
*ppHead = new_node;
}
else
{
//找到尾結點
SLNode* end = *ppHead;
while (end->next != NULL)
{
end = end->next; //令end指向后繼節點
}
//插入
end->next = new_node;
}
}0x03 頭插(SListPushFront)
💬 SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode** pHead, SLNodeDataType x);
void SListPushFront(SLNode** ppHead, SLNodeDataType x);🔑 解讀:這里仍然要使用二級指標,
💬 SList.c
/* 頭插 */
void SListPushFront (
SLNode** ppHead, //頭結點
SLNodeDataType x //傳入的資料
)
{
//創建新節點
SLNode* new_node = CreateNewNode(x);
//先讓新節點的next指向頭結點
new_node->next = *ppHead;
//更新頭結點
*ppHead = new_node;
}🔑 解讀:
Step1:頭插就很簡單了,思路就是讓新節點的 next 指向頭結點,然后再讓新節點做頭結點即可,首先創建新節點,直接套用我們剛才創建的 CreateNewNode 函式即可,
Step2:創建完畢后,讓新結點 new_node->next 存好頭結點 *ppHead ,這樣在物理上就實作了 "鏈接" ,最后我們再更新下頭結點就可以了,把 new_node 賦給 *ppHead ,現在 new_node 就變成了新的頭結點了,也就實作了頭插的效果,
💬 Test.c:
#include "SList.h"
void TestSList1()
{
SLNode* pList = NULL;
SListPushBack(&pList, 1);
SListPushBack(&pList, 2);
SListPushBack(&pList, 3);
SListPushBack(&pList, 4);
SListPrint(pList);
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
}
int main()
{
TestSList1();
return 0;
}🚩 運行結果如下:
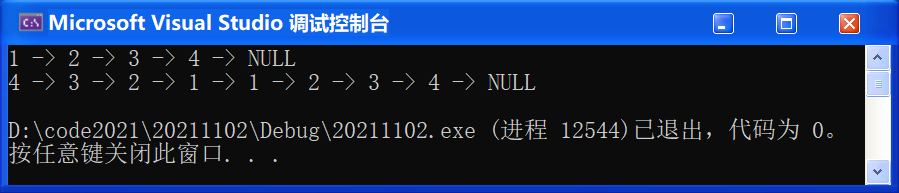
0x04 尾刪(SListPopBack)
💬 SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode** pHead, SLNodeDataType x);
void SListPushFront(SLNode** ppHead, SLNodeDataType x);
void SListPopBack(SLNode** pHead);🔑 解讀:尾刪我們需要注意的是防止沒有東西可洗掉,所以我們需要預防出現為空的情況,這里本人更傾向的是 assert 斷言暴力解決的方法,和在順序表章節中一樣,使用斷言就需要引入頭檔案 #include <assert.h> ,

💬 SList.c
① 方法1:prev 前驅指標
void SListPopBack (
SLNode** ppHead //頭結點
)
{
//防止結點為空
assert(*ppHead != NULL);
//如果只有一個結點
if ((*ppHead)->next == NULL)
{
free(*ppHead);
*ppHead = NULL;
}
else //兩個及兩個以上結點
{
//找到尾部
SLNode* prev = NULL; //前驅指標
SLNode* end = *ppHead;
while (end->next != NULL)
{
prev = end; //保存現有end
end = end->next; //令end指向后繼節點
}
// 洗掉
free(end);
end = NULL;
prev->next = NULL;
}
}🔑 解讀:
Step1:首先 assert 斷言防止鏈表沒有節點,
Step2:開始判斷,分為兩種情況,第一種情況是只有一個結點,第二種情況是有兩個及兩個以上的節點,我們首先來看第一種情況,第一種情況時,我們就可以直接洗掉,使用 free 釋放空間完空間后再把它置成空(動態記憶體開辟章節詳細講過為什么要這么做),【維生素C語言】第十三章 - 動態記憶體管理

Step3:第二種情況時,因為是尾刪所以我們理所當然要找到尾部的節點,為了防止最后沒法觸及上一個節點從而沒辦法把它置空,所以這里在創建尋尾指標 end 的同時,還要創建一個前驅指標 prev 以用來實時保存 end 的值,讓 end 去送死,只要 end->next 不是 NULL 時就進入回圈,首先保存 end 的值,然后令 end 指向后繼節點,當 end->next 為 NULL 時,free 釋放空間并置空,此時這個尾部節點就被洗掉了,但是上一個節點還存著這個已經洗掉的節點地址,這時,我們的前驅指標 prev 就能派上用場了,將 prev -> next 置為 NULL 就可以解決問題,這就是前驅指標的作用,
② 方法2:next->next 保守解決
/* 尾刪 */
void SListPopBack (
SLNode** ppHead //頭結點
)
{
//防止結點為空
assert(*ppHead != NULL);
//如果只有一個結點
if ((*ppHead)->next == NULL)
{
free(*ppHead);
*ppHead = NULL;
}
else //兩個及兩個以上結點
{
SLNode* end = *ppHead;
while (end->next->next)
{
end = end->next;
}
free(end->next);
end->next = NULL;
}
}🔑 解讀:
Step1 & Step2 同上,
Step3:我們也可以不使用前驅指標來實作,利用鏈表的性質進行更深一層的解參考也可以解決最后沒法觸及上一個節點從而無法將其置空的問題,首先創建尋尾指標 end,回圈判斷條件讓 end 保留在 "安全位置" 不讓他去送死了,也就是 end->next->next ,從而做到提前發現為空的情況,從而讓 end 能夠保留下來用來置空,當 end->next->next 為空時跳出回圈,free 釋放掉 end->next ,最后將 end->next 置為空,
💬 List.c:
① 把頭插的4個資料逐個洗掉并列印:
#include "SList.h"
void TestSList2()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
//SListPopBack(&pList);
}
int main()
{
//TestSList1();
TestSList2();
return 0;
}🚩 運行結果如下:
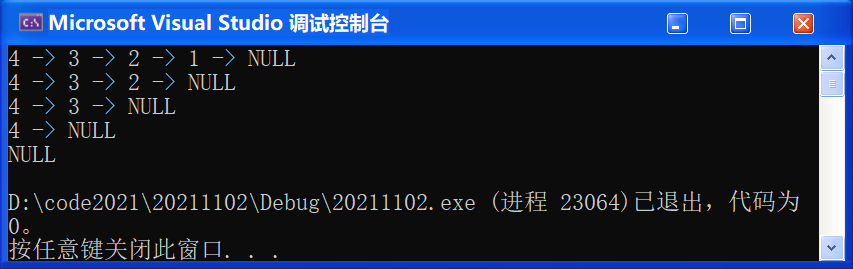
② 測驗斷言效果:
#include "SList.h"
void TestSList2()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
SListPopBack(&pList);
SListPrint(pList);
}
int main()
{
//TestSList1();
TestSList2();
return 0;
}🚩 運行結果如下:
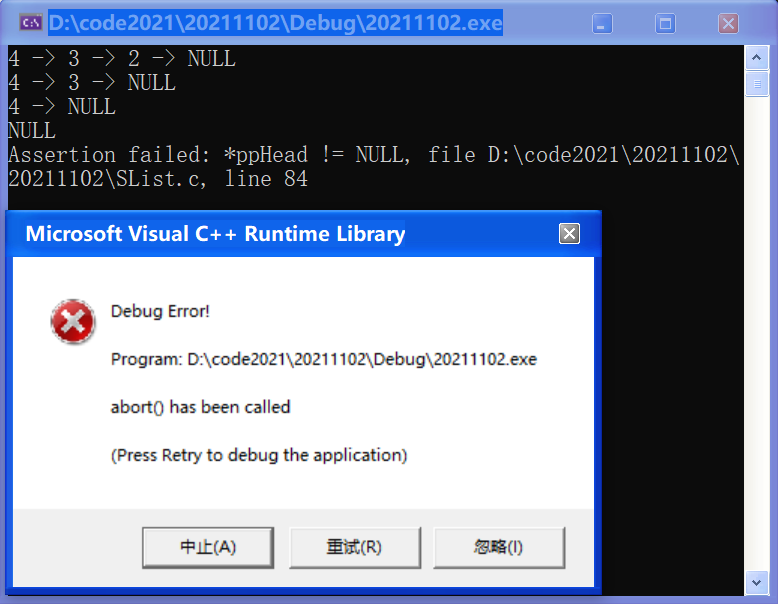
0x05 頭刪(SListPopFront )
💬 SList.h
void SListPopFront(SLNode** pHead);💬 SList.c
/* 頭刪 */
void SListPopFront (
SLNode** ppHead //頭節點
)
{
//防止節點為空
assert(*ppHead != NULL);
//直接free會導致你找不到下一個節點了,所以我們需要處理一下:
SLNode* save_next = (*ppHead)->next; //保存頭節點的下一個節點
//洗掉
free(*ppHead); //釋放頭節點
*ppHead = save_next; //更新頭節點(剛才我們保存的)
}🔑 解讀:
Step1:首先防止節點為空,
Step2:頭刪我們要注意的是不能直接 free 掉,因為直接刪的話就會導致找不到下一個節點了,創建 save_next 指標,用來保存我們要洗掉的頭結點 *phead 指向的下一個結點的地址,保存好了之后我們就可以大膽的洗掉了,直接把頭結點 free 掉即可,
Step3:更新頭結點,將我們剛才保存的 save_next 賦值給 *pphead
💬 List.c
#include "SList.h"
void TestSList3()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
SListPopFront(&pList);
SListPrint(pList);
SListPopFront(&pList);
SListPrint(pList);
SListPopFront(&pList);
SListPrint(pList);
SListPopFront(&pList);
SListPrint(pList);
//SListPopFront(&pList);
//SListPrint(pList);
}
int main()
{
//TestSList1();
//TestSList2();
TestSList3();
return 0;
}
🚩 運行結果如下:
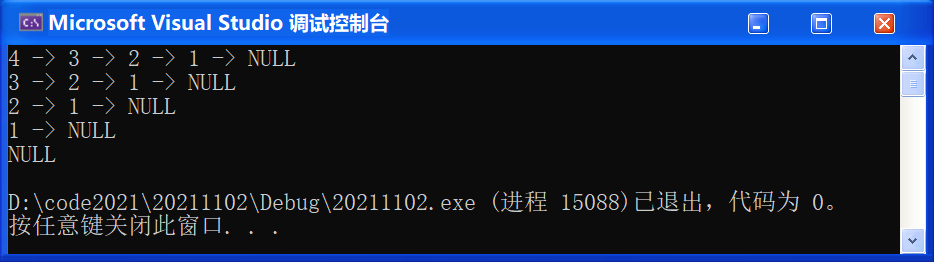
0x06 查找(SListFind)
💬 SList.h
SLNode* SListFind(SLNode* pHead, SLNodeDataType x);🔑 解讀:查找用不上二級指標,因為不需要修改鏈表的內容,函式回傳結果為 SLNode*
💬 SList.c
/* 查找 */
SLNode* SListFind (
SLNode* pHead,
SLNodeDataType x
)
{
//查找就是遍歷整個節點
SLNode* cur = pHead;
while (cur != NULL)
{
if (cur->data == x) // 找到了
return cur;
else // 繼續找
cur = cur->next;
}
// 沒找到
return NULL;
}🔑 解讀:查找和列印函式一樣,很簡單,只需要創建一個 cur 遍歷鏈表就可以了,如果 cur->data 和傳入的 x,即需要查找的值相同就回傳 cur,cur 是帶有值和地址的,如果整個鏈表都走完了還沒有找到相同的值,就回傳 NULL ,
💬 List.c:查找多個節點
#include "SList.h"
void TestSList4()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 2);
SListPushFront(&pList, 4);
SListPushFront(&pList, 2);
SListPushFront(&pList, 2);
SListPushFront(&pList, 4);
SListPrint(pList);
// 找
SLNode* pos = SListFind(pList, 2);
int i = 1;
while (pos)
{
printf("第%d個pos節點:%p->%d\n", i++, pos, pos->data);
pos = SListFind(pos->next, 2);
}
}
int main()
{
//TestSList1();
//TestSList2();
//TestSList3();
TestSList4();
return 0;
}
🚩 運行結果如下:
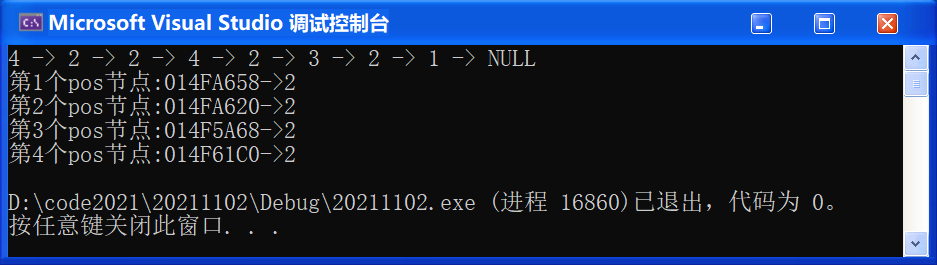
0x07 指定位置之前插入(SListInsert)
一般默認是在pos位置之前去插入一個節點
💬 SList.h
void SListInsert(SLNode** ppHead, SLNode* pos, SLNodeDataType x);🔑 解讀:因為我們要對鏈表動手,所以這里我們又要傳指標的地址,用二級指標接收了,pos 是要插入的位置,帶有值和地址,
💬 SList.c
/* 在pos位置之前去插入一個節點 */
void SListInsert (
SLNode** ppHead,
SLNode* pos,
SLNodeDataType x
)
{
//創建新結點
SLNode* new_node = CreateNewNode(x);
if (*ppHead == pos)
{
//頭插
new_node->next = *ppHead;
*ppHead = new_node;
}
else
{
//找到pos的前一個位置
SLNode* posPrev = *ppHead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
//插入
posPrev->next = new_node;
new_node->next = pos;
}
}🔑 解讀:
Step1:首先創建新節點,分為兩種情況,第一種情況是直接頭插,第二種情況就是要找 pos 的前面一個結點的位置,我們首先看第一種情況,如果 *ppHead == pos 就直接頭插就行了,先讓新節點的 next 指向頭結點,然后再更新頭結點就行,這里你也可以直接呼叫 SListPushFront,但是頭插代碼就2行,所以這里就直接寫了,
Step2:第二種情況,我們定義一個結構體指標 posPrev 用來找 pos 的前一個位置,如果 posPrev-> next 還不是 pos 就進入回圈,讓 posPrev 往下走,直到 posPrev->next 為 pos,也就找到 pos 前一個位置了,
Step3:找到 pos 前一個位置后就可以插入了,直接把 new_node 交給 posPrev->next ,此時 new_node 默認指向 NULL,還要把 pos 交給 new_node->next ,
💬 List.c:
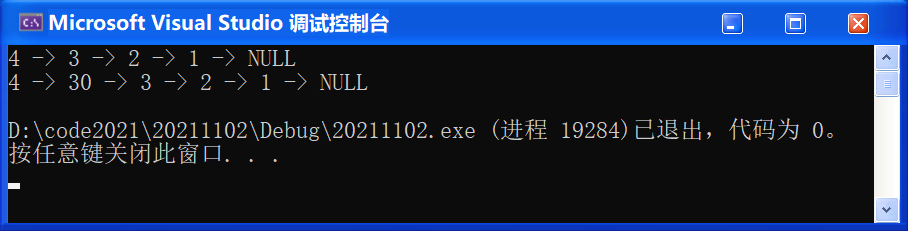
① 第二種情況:
#include "SList.h"
void TestSList5()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
SLNode* pos = SListFind(pList, 3);
if (pos)
{
SListInsert(&pList, pos, 30);
}
SListPrint(pList);
}
int main()
{
//TestSList1();
//TestSList2();
//TestSList3();
//TestSList4();
TestSList5();
return 0;
}🚩 運行結果如下:
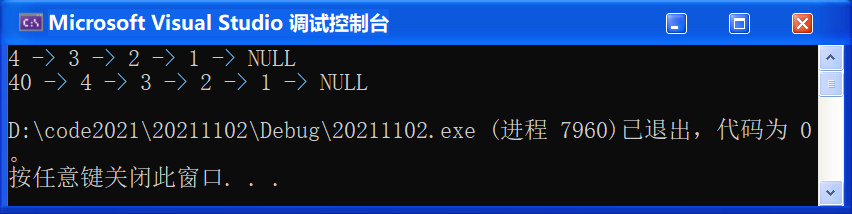
① 第一種情況(需要頭插的情況):
#include "SList.h"
void TestSList5()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
//需要頭插的情況
SLNode* pos = SListFind(pList, 4);
if (pos)
{
SListInsert(&pList, pos, 40);
}
SListPrint(pList);
}
int main()
{
//TestSList1();
//TestSList2();
//TestSList3();
//TestSList4();
TestSList5();
return 0;
}🚩 運行結果如下:
0x08 洗掉指定位置(SListEarse)
💬 SList.h
void SListEarse(SLNode** ppHead, SLNode* pos);💬 SList.c
/* 洗掉pos位置的節點 */
void SListEarse(
SLNode** ppHead,
SLNode* pos
)
{
//防止沒有節點的情況
assert(*ppHead != NULL);
assert(pos);
//只有一個節點的情況
if (*ppHead == pos)
{
//直接頭刪
SListPopFront(ppHead);
}
//二個或兩個以上節點的情況
else
{
SLNode* prev = *ppHead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next; //把前面和后面資料鏈接起來
free(pos);
//pos = NULL;
}
}🔑 解讀:
Step1:防止節點為空,因為我們要洗掉 pos 位置的值,所以還要防止傳入的 pos 為空,
Step2:還是分為兩種情況,一種是有節點的情況,即頭刪的情況,我們直接呼叫 SListPopFront 即可,
Step3:第二種情況,我們定義一個結構體指標 prev 用來找 pos ,在洗掉之前我們要把 pos 前面和后面的資料鏈接起來,prev->next = pos->next ,最后再 free 掉 pos 即可,值得一提的是,因為 pos 被取代了,所以不把它置為空,
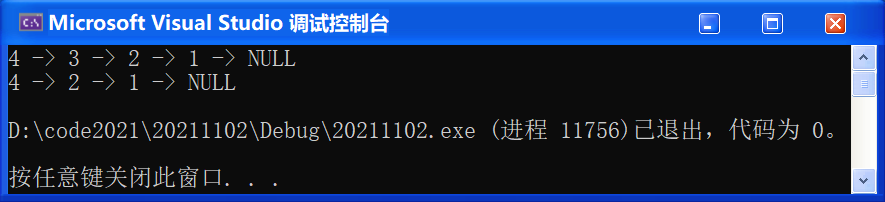
💬 List.c:洗掉 3
#include "SList.h"
void TestSList6()
{
SLNode* pList = NULL;
SListPushFront(&pList, 1);
SListPushFront(&pList, 2);
SListPushFront(&pList, 3);
SListPushFront(&pList, 4);
SListPrint(pList);
SLNode* pos = SListFind(pList, 3);
if (pos)
{
SListEarse(&pList, pos);
}
SListPrint(pList);
}
int main()
{
//TestSList1();
//TestSList2();
//TestSList3();
//TestSList4();
//TestSList5();
TestSList6();
return 0;
}
🚩 運行結果如下:
0x09 銷毀(SListDestroy)
💬 SList.h
void SListDestroy(SLNode** ppHead);💬 SList.c
/* 銷毀 */
void SListDestroy (
SLNode** ppHead
)
{
assert(ppHead);
SLNode* cur = *ppHead;
while (cur != NULL) {
SLNode* next = cur->next;
free(cur);
cur = next;
}
*ppHead = NULL;
}🔑 解讀:銷毀得有東西才能銷毀,所以斷言 ppHead 不為空,通過 cur 逐個走一遍,為了防止刪了一個下一個結點就找不到了,每次進入回圈都先創建一個 next 指標來保存 cur->next,然后再 free 掉,全部結束后再把 *ppHead 置為空,就完成銷毀了,
0x0A 指定位置之后洗掉(SListInsertAfter)
💬 SList.h
void SListInsertAfter(SLNode* pos, SLNodeDataType x);💬 SList.c
/* 在pos位置之后去插入一個節點 */
void SListInsertAfter (
SLNode* pos,
SLNodeDataType x
)
{
assert(pos);
SLNode* new_node = CreateNewNode(x);
new_node->next = pos->next;
pos->next = new_node;
}🔑 解讀:在 pos 后面插入就很簡單了,因為不需要找 pos 前面的結點,沒有什么好講的,
0x0B 洗掉指定位置之后的節點(SListInsertAfter)
💬 SList.h
void SListEraseAfter (SLNode* pos);💬 SList.c
/* 洗掉pos之后的一個節點 */
void SListEraseAfter (
SLNode* pos
)
{
assert(pos);
assert(pos->next);
SLNode* save_next = pos->next;
pos->next = save_next->next;
free(save_next);
//next = NULL;
}
四、完整代碼
💬 SList.h
#pragma once
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
typedef int SLNodeDataType; // SLNodeDataType == int
typedef struct SingleListNode {
SLNodeDataType data; // 用來存放節點的資料 int data
struct SingleListNode* next; // 指向后繼節點的指標
} SLNode; // 重命名為SLNode 便于利用該結構體
void SListPrint(SLNode* pHead);
void SListPushBack(SLNode** pHead, SLNodeDataType x);
void SListPushFront(SLNode** ppHead, SLNodeDataType x);
void SListPopBack(SLNode** pHead);
void SListPopFront(SLNode** pHead);
SLNode* SListFind(SLNode* pHead, SLNodeDataType x);
void SListInsert(SLNode** ppHead, SLNode* pos, SLNodeDataType x);
//void SListInsert(SLNode* pHead, int pos, SLNodeDataType x);
void SListEarse(SLNode** ppHead, SLNode* pos);
void SListDestroy(SLNode** ppHead);
void SListInsertAfter(SLNode* pos, SLNodeDataType x);
void SListEraseAfter (SLNode* pos);
💬 SList.c
#include "SList.h"
/* 列印 */
void SListPrint (
SLNode* pHead
)
{
SLNode* cur = pHead;
while (cur != NULL)
{
printf("%d -> ", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
/* 創建新節點 */
SLNode* CreateNewNode (
SLNodeDataType x //傳入的資料
)
{
//創建,開辟空間
SLNode* new_node = (SLNode*)malloc(sizeof(SLNode));
//malloc檢查
if (new_node == NULL)
{
printf("malloc failed!\n");
exit(-1);
}
//放置
new_node->data = x; //存傳入的資料
new_node->next = NULL; //next默認置空
return new_node; //遞交新節點
}
/* 尾插 */
void SListPushBack (
SLNode** ppHead, //頭結點,二級指標
SLNodeDataType x //傳入的資料
)
{
//創建新節點
SLNode* new_node = CreateNewNode(x);
//如果鏈表是空的
if (*ppHead == NULL)
{
//直接插入即可
*ppHead = new_node;
}
else
{
//找到尾結點
SLNode* end = *ppHead;
while (end->next != NULL)
{
end = end->next; //令end指向后繼節點
}
//插入
end->next = new_node;
}
}
/* 頭插 */
void SListPushFront (
SLNode** ppHead, //頭結點
SLNodeDataType x //傳入的資料
)
{
//創建新節點
SLNode* new_node = CreateNewNode(x);
//先讓新節點的next指向頭結點
new_node->next = *ppHead;
//更新頭結點
*ppHead = new_node;
}
/* 尾刪 */
void SListPopBack (
SLNode** ppHead //頭結點
)
{
//防止結點為空
assert(*ppHead != NULL);
//如果只有一個結點
if ((*ppHead)->next == NULL)
{
free(*ppHead);
*ppHead = NULL;
}
else //兩個及兩個以上結點
{
/*
//找到尾部
SLNode* prev = NULL; //前驅指標
SLNode* end = *ppHead;
while (end->next != NULL)
{
prev = end; //保存現有end
end = end->next; //令end指向后繼節點
}
// 洗掉
free(end);
end = NULL;
prev->next = NULL;
*/
SLNode* end = *ppHead;
while (end->next->next)
{
end = end->next;
}
free(end->next);
end->next = NULL;
}
}
/* 頭刪 */
void SListPopFront (
SLNode** ppHead //頭節點
)
{
//防止節點為空
assert(*ppHead != NULL);
//直接free會導致你找不到下一個節點了,所以我們需要處理一下:
SLNode* save_next = (*ppHead)->next; //保存頭節點的下一個節點
//洗掉
free(*ppHead); //釋放頭節點
*ppHead = save_next; //更新頭節點(剛才我們保存的)
}
/* 查找 */
SLNode* SListFind (
SLNode* pHead,
SLNodeDataType x
)
{
//查找就是遍歷整個節點
SLNode* cur = pHead;
while (cur != NULL)
{
if (cur->data == x) // 找到了
return cur;
else // 繼續找
cur = cur->next;
}
// 沒找到
return NULL;
}
/* 在pos位置之前去插入一個節點 */
void SListInsert (
SLNode** ppHead,
SLNode* pos,
SLNodeDataType x
)
{
//創建新節點
SLNode* new_node = CreateNewNode(x);
if (*ppHead == pos)
{
//頭插
new_node->next = *ppHead;
*ppHead = new_node;
}
else
{
//找到pos的前一個位置
SLNode* posPrev = *ppHead;
while (posPrev->next != pos)
{
posPrev = posPrev->next;
}
//插入
posPrev->next = new_node;
new_node->next = pos;
}
}
/* 洗掉pos位置的節點 */
void SListEarse(
SLNode** ppHead,
SLNode* pos
)
{
//防止沒有節點的情況
assert(*ppHead != NULL);
assert(pos);
//只有一個節點的情況
if (*ppHead == pos)
{
//直接頭刪
SListPopFront(ppHead);
}
//二個或兩個以上節點的情況
else
{
SLNode* prev = *ppHead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next; //把前面和后面資料鏈接起來
free(pos);
//pos = NULL;
}
}
/* 銷毀 */
void SListDestroy (
SLNode** ppHead
)
{
assert(ppHead);
SLNode* cur = *ppHead;
while (cur != NULL) {
SLNode* next = cur->next;
free(cur);
cur = next;
}
*ppHead = NULL;
}
/* 在pos位置之后去插入一個節點 */
void SListInsertAfter (
SLNode* pos,
SLNodeDataType x
)
{
assert(pos);
SLNode* new_node = CreateNewNode(x);
new_node->next = pos->next;
pos->next = new_node;
}
/* 洗掉pos之后的一個節點 */
void SListEraseAfter (
SLNode* pos
)
{
assert(pos);
assert(pos->next);
SLNode* save_next = pos->next;
pos->next = save_next->next;
free(save_next);
//next = NULL;
}
參考資料:
Microsoft. MSDN(Microsoft Developer Network)[EB/OL]. []. .
百度百科[EB/OL]. []. https://baike.baidu.com/.
位元科技. 資料結構v5[EB/OL]. 2021[21]. .
📌 作者:王亦優
📃 更新: 2021.11.3
? 勘誤: 無
📜 宣告: 由于作者水平有限,本文有錯誤和不準確之處在所難免,本人也很想知道這些錯誤,懇望讀者批評指正!
本章完,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/348597.html
標籤:其他