🎉🎉想快速入門資料結構,推薦訂閱作者的初階資料結構專欄!此專欄預計更新:順序表,鏈表,堆疊,佇列,二叉樹,排序演算法等等
🎉🎉初階資料結構我們通過c語言實作,所以此專欄也可以幫助大家鞏固大家的c語言知識
🎉🎉源代碼已上傳至我的碼云
前言
二叉樹算是初階資料結構的一個新坑吧,不僅僅是因為難度比前面的資料結構提升了一個檔次,而且這也是我們學的第一種非線性結構
我們在前面學的資料結構,無論是順序表還是鏈表,不管它們在物理中的存盤方式如何,它們的邏輯一定是串在一起的,
但是樹形結構卻不一樣,它是一種有層次的結構,其元素具有一對多的特性
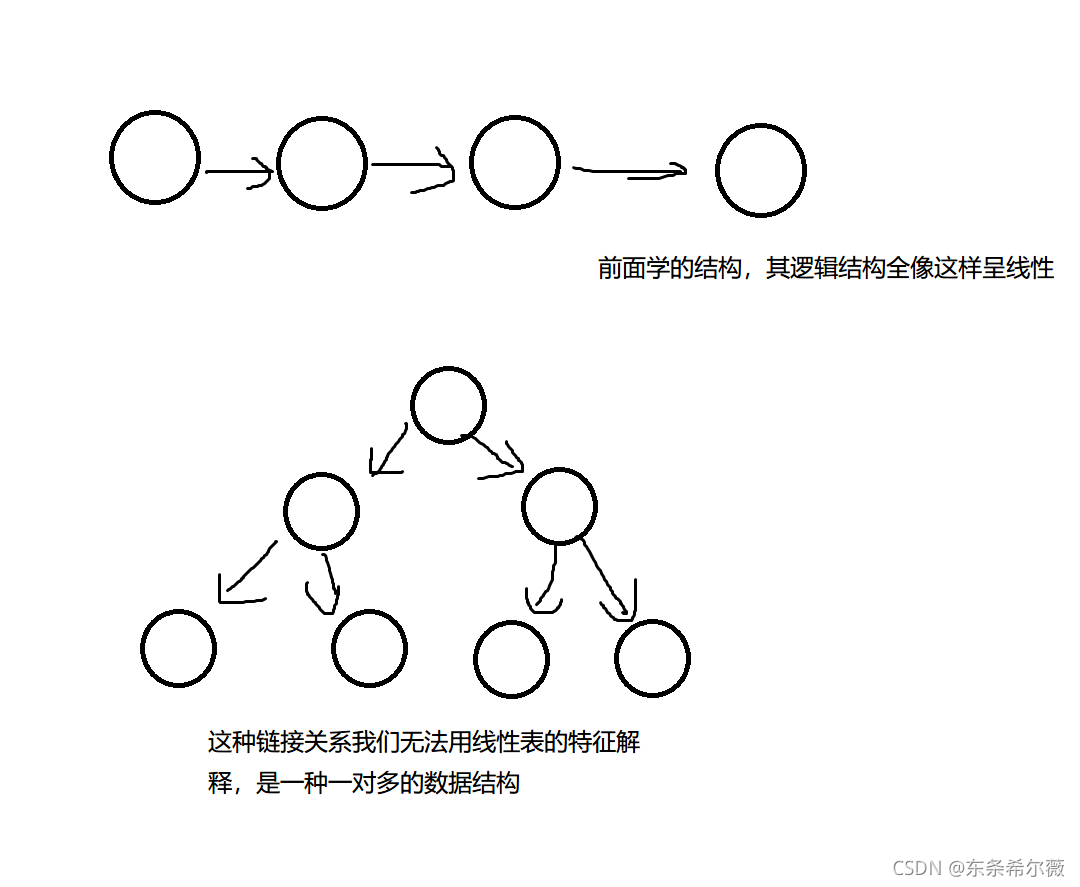
所以,相對于以前幾期,它是一種全新的資料結構
目錄
- 樹的概念
- 樹的定義
- 樹的相關名詞
- 二叉樹的概念
- 一些特殊的二叉樹
- 二叉樹的順序存盤結構——堆
- 堆的實作
- 插入和向上調整演算法
- 堆的洗掉與向下調整演算法
樹的概念
樹的定義
要了解二叉樹,首先我們要對普通的樹有一定的認知
在前言提到過,樹是一種非線性資料結構,資料的組織具有層次性
它的定義:始終由根結點(沒有前驅結點的結點)和子樹構成
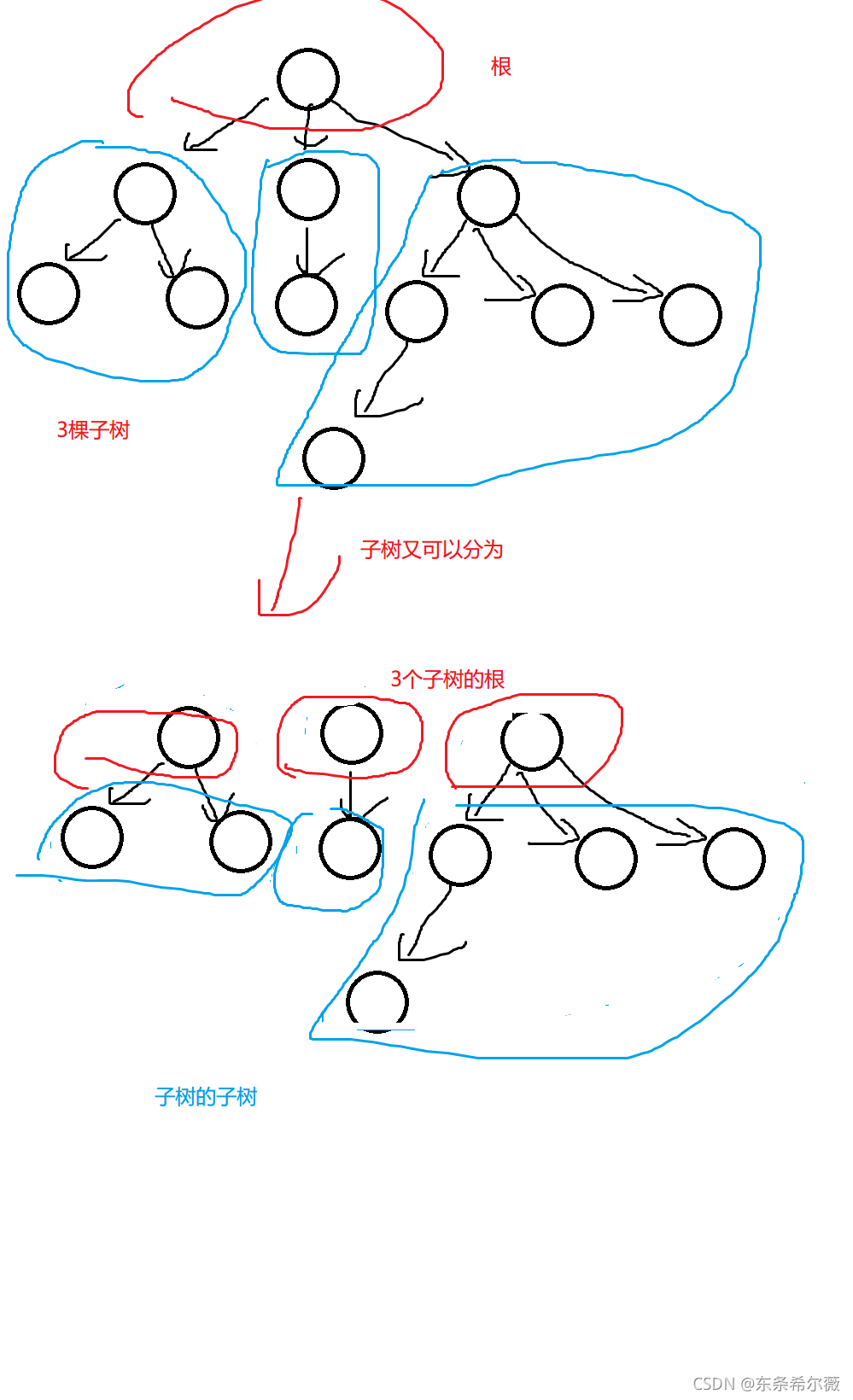
所以我們可以知道:樹是遞回定義的
樹的相關名詞
節點的度:一個節點含有的子樹的個數稱為該節點的度;
葉節點或終端節點:度為0的節點稱為葉節點;
非終端節點或分支節點:度不為0的節點;
雙親節點或父節點:若一個節點含有子節點,則這個節點稱為其子節點的父節點;
孩子節點或子節點:一個節點含有的子樹的根節點稱為該節點的子節點;
兄弟節點:具有相同父節點的節點互稱為兄弟節點;
樹的度:一棵樹中,最大的節點的度稱為樹的度;
節點的層次:從根開始定義起,根為第1層,根的子節點為第2層,以此類推;
樹的高度或深度:樹中節點的最大層次;
堂兄弟節點:雙親在同一層的節點互為堂兄弟;
節點的祖先:從根到該節點所經分支上的所有節點;
子孫:以某節點為根的子樹中任一節點都稱為該節點的子孫,
森林:由m(m>0)棵互不相交的樹的集合
二叉樹的概念
定義:二叉樹就是度不會大于2的樹(即分支數不會大于2的樹)
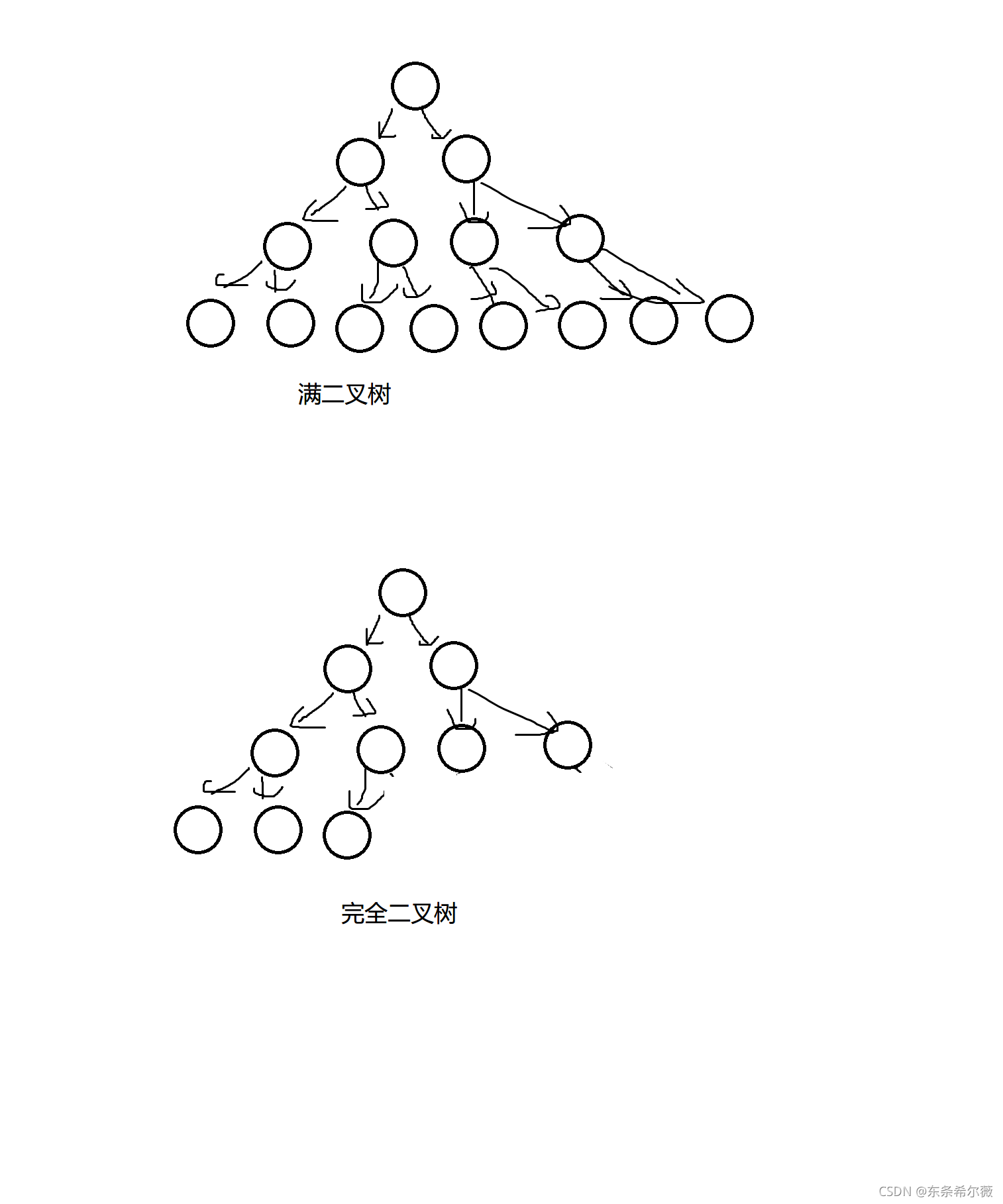
一些特殊的二叉樹
滿二叉樹:每一層的結點達到最大值
完全二叉樹:前n-1層是一顆滿二叉樹,最后一棵樹的結點由左到右連續存放
二叉樹的順序存盤結構——堆
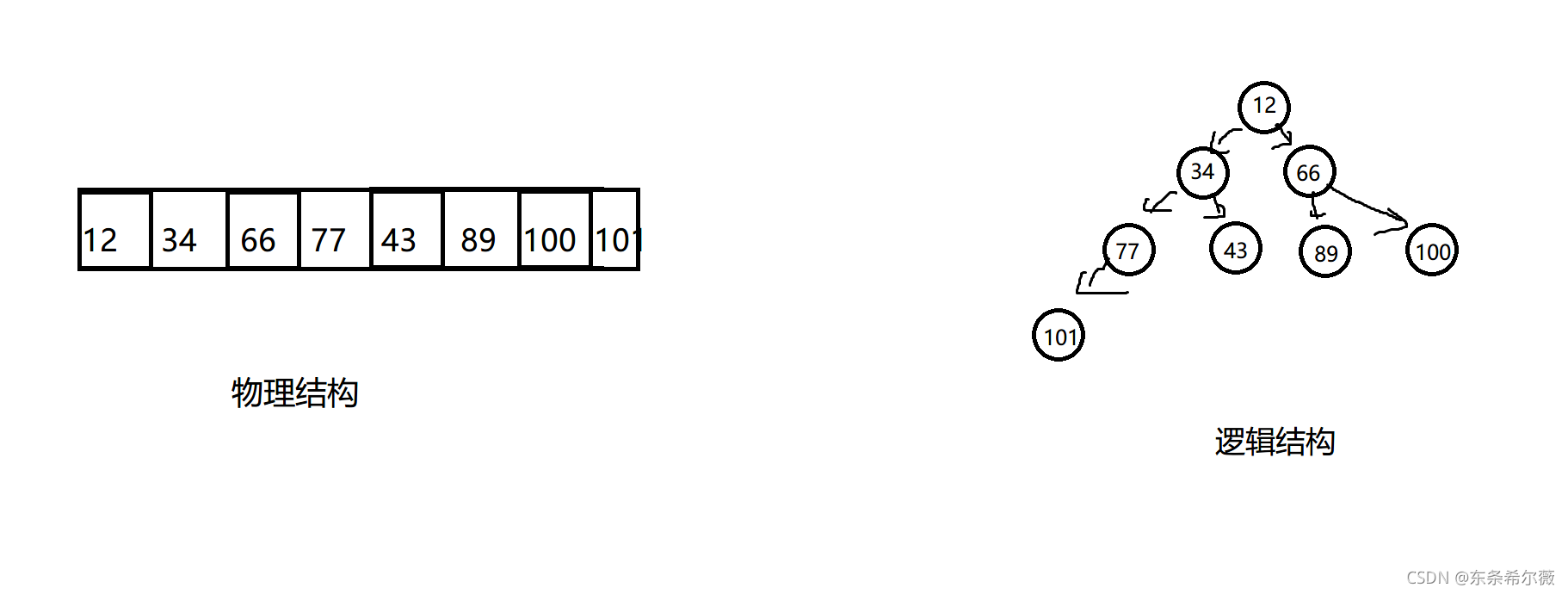
現在來到了本章的重點,堆
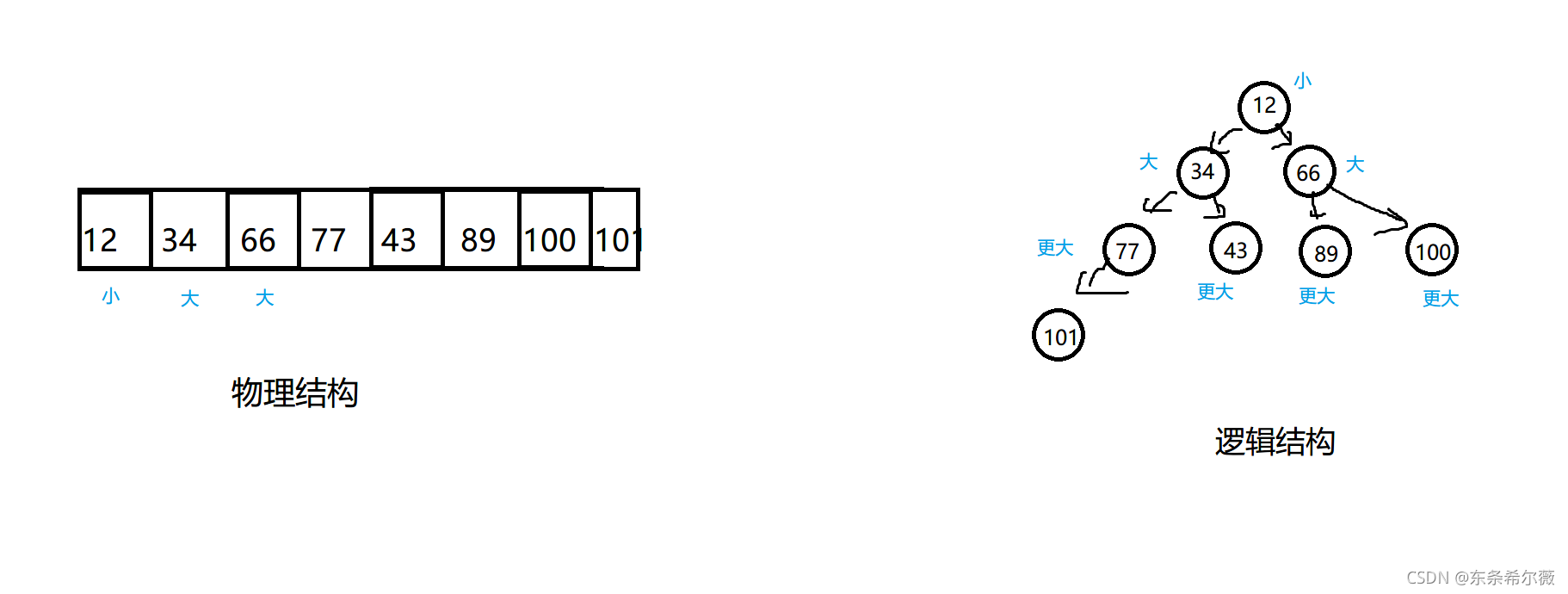
堆是一種在物理上連續存盤,但在邏輯上卻是一顆二叉樹的資料結構
怎么把邏輯結構與物理結構聯系起來呢?
這里有幾個公式:
通過父親結點找到孩子結點,設陣列開始下標為0:
leftchild=parent2+1
leftchild=parent2+1
這里的child和parent是它們對應的陣列下標
通過孩子結點找到父親結點
parent=(child-1)/2
注意:由于陣列元素是連續存放的,所以為了保證陣列的空間利用率,堆對應的邏輯結構應該是一棵完全二叉樹,(即中間沒有空白結點空間)
但是,不是一個普通的陣列就是堆的,它需要滿足一個特性
根結點的值始終比它的孩子結點的值小(大)
前者叫小堆,后者叫大堆
比如上圖,就是一個典型的小堆
堆的實作
由于初始化和銷毀等其它函式與線性表的定義一樣,因為堆的邏輯結構是個陣列,所以這篇文章中不再闡述
重點講插入和洗掉
插入和洗掉我們要遵循一個原則:那就是堆的性質永遠不會改變
為了遵循以上原則,我們需要引入向上和向下調整演算法
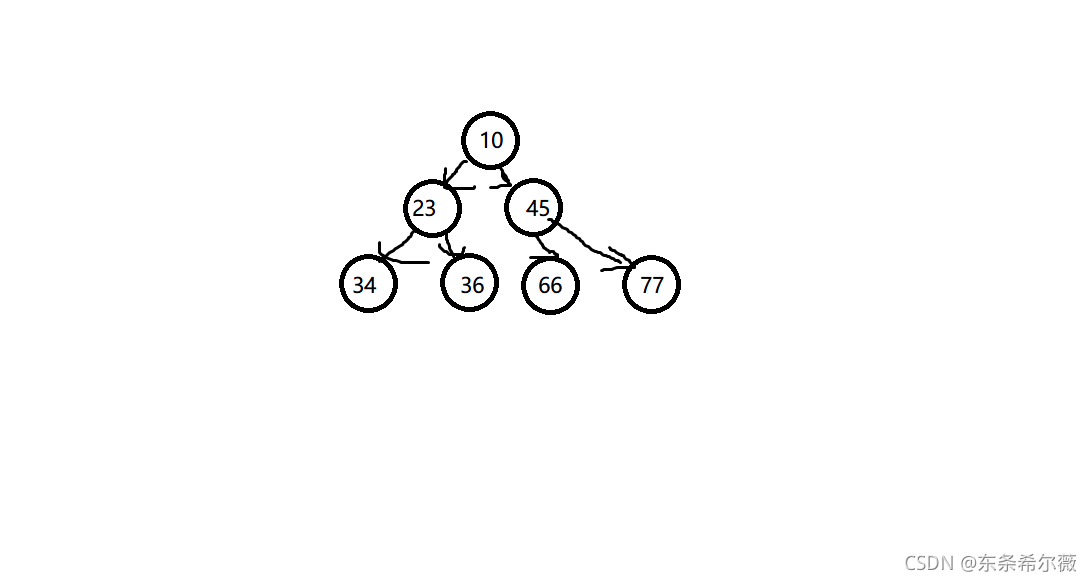
這里我們以小堆為例來創建堆
插入和向上調整演算法
我們以這個小堆來舉例
首先,插入操作前面與順序表差不多,需要檢查容量
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;//這里是防止堆為空
HPDataType* tmp = realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (!tmp)
{
printf("malloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
插入我們可以直接先在陣列的后面插入
hp->a[hp->size] = x;
hp->size++;
比如我們要插入一個資料9,然后邏輯結構就變成了這樣
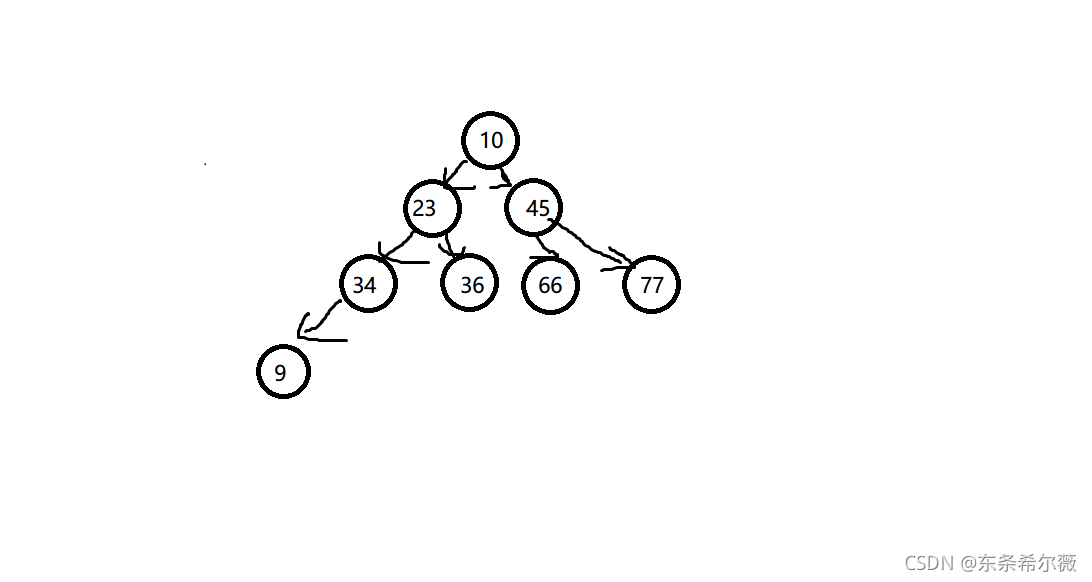
這樣,9比34小了,顯然不滿足小端的特征,所以我們需要向上調整演算法,把它調整到滿足堆的特征的所在位置
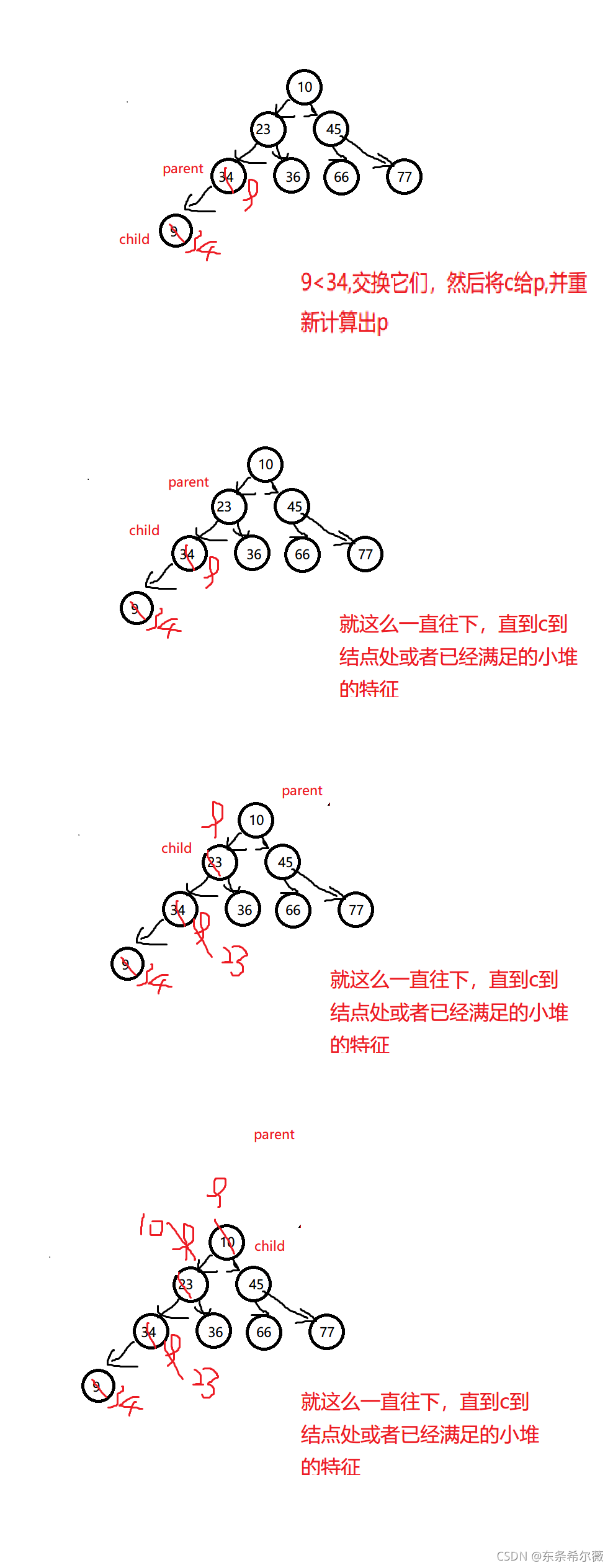
向上調整,只會影響這個結點的祖先結點
思路:與它的父親結點不斷比較,若不滿足要求則交換,滿足要求就停止演算法
圖示:
代碼:
void AdjustUp(HPDataType* a, int size, int child)
{
assert(a);
int parent = (child - 1) / 2;//這里是算出父親結點
while (child > 0)
{
if (a[child] < a[parent])//不滿足小堆的要求
{
Swap(&a[child], &a[parent]);//交換操作
child = parent;
parent = (child - 1) / 2;//這里是遍歷孩子與父親結點
}
else
{
break;
}
}
}
完整的插入代碼
void AdjustUp(HPDataType* a, int size, int child)
{
assert(a);
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void HeapPush(HP* hp, HPDataType x)
{
assert(hp);
if (hp->size == hp->capacity)
{
int newcapacity = hp->capacity == 0 ? 4 : hp->capacity * 2;
HPDataType* tmp = realloc(hp->a, sizeof(HPDataType) * newcapacity);
if (!tmp)
{
printf("malloc fail\n");
exit(-1);
}
hp->a = tmp;
hp->capacity = newcapacity;
}
hp->a[hp->size] = x;
hp->size++;
AdjustUp(hp->a, hp->size, hp->size - 1);
}
堆的洗掉與向下調整演算法
注意:這里的洗掉是直接洗掉堆頂元素
我們最開始的思路是,能不能像順序表的頭刪一樣,直接挪動資料來洗掉呢?
顯然是不行的,因為這樣會把堆的結構完全打亂,大家可以腦補一下,這里就不圖示了
所以我們需要這么洗掉
先把第一個元素與最后一個元素交換,再進行順序表尾刪,這樣保證了前面堆的結構不會被打亂
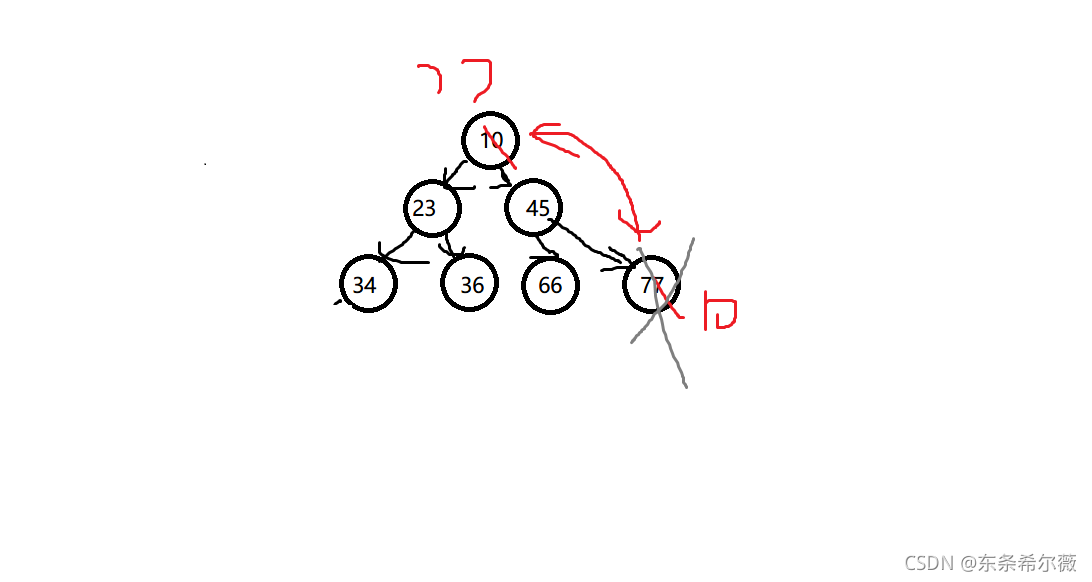
void HeapPop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
Swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
}
但我們的77被換上去了,不滿足堆的特性了,所以為了滿足堆的特性,使用向下調整演算法
思路:
先選出左右孩子中較小的孩子(先默認為左孩子,再與右孩子進行比較,若默認結果不成立,就更新孩子結點)
與向上調整演算法異曲同工
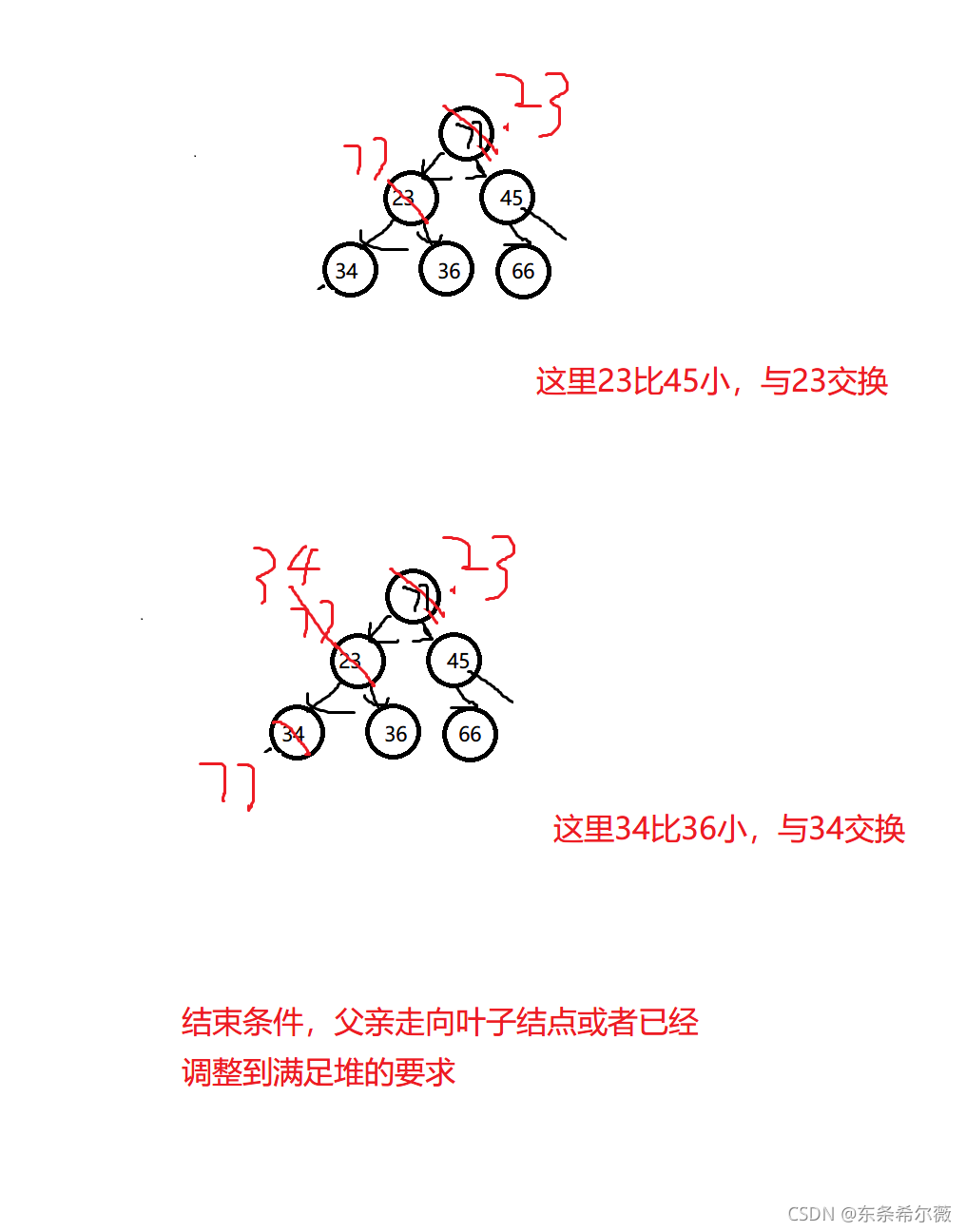
代碼實作
void AdjustDown(HPDataType* a, int size, int parent)
{
assert(a);
int child = parent * 2 + 1;//默認與左孩子交換
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
{
child++;//不滿足默認條件就換為右孩子
}
if (a[child] < a[parent])//交換
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
完成洗掉代碼
void AdjustDown(HPDataType* a, int size, int parent)
{
assert(a);
int child = parent * 2 + 1;
while (child < size)
{
if (child + 1 < size && a[child + 1] < a[child])
{
child++;
}
if (a[child] < a[parent])
{
Swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapPop(HP* hp)
{
assert(hp);
assert(!HeapEmpty(hp));
Swap(&hp->a[0], &hp->a[hp->size - 1]);
hp->size--;
AdjustDown(hp->a, hp->size, 0);
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/349677.html
標籤:其他