本文禁止轉載
EDG奪冠,粉絲炸鍋了!
北京時間11月6日,在英雄聯盟S11總決賽中,中國LPL賽區戰隊EDG電子競技俱樂部以3∶2戰勝韓國LCK賽區戰隊DK,獲得2021年英雄聯盟全球總決賽冠軍,
這個比賽也是備受全網矚目:
- 微博熱搜第一名,顯示有8194萬觀看;
- bilibili平臺,吸引3.5億人氣,滿屏彈幕;
- 騰訊視頻600萬人看過;
- 斗魚和虎牙平臺的熱度也是居高不下;
- 比賽結束后,央視新聞也發微博祝賀EDG戰隊奪冠;

既然比賽熱度這么高,那大家都說了點啥?
我們用Python分析了31000條彈幕資料,滿屏都是粉絲的祝福與感受,

我們不僅可以通過直播和新聞來感受比賽的整個程序,也可以通過Python來分析熱點來感受粉絲的熱情,
文中用到的源代碼、字體檔案、停用詞檔案、背景圖,均可添加好友領取!
手把手教你獲取彈幕資料
1. 簡單說明
沒看過直播的朋友不要緊,有回放呀!整個視頻已經為大家整理好了,從開幕式,到五場比賽,再到奪冠時刻,一共7個視頻,

每個視頻中,都有粉絲發布的彈幕,今天要做的,就是獲取每個視頻里面的彈幕資料,看看粉絲在躁動的心情下,說了點啥?
不得不說,B站網頁的變化速度真快,我記得去年還是很容易找到的,但是今天卻一直沒有找到,
但是沒有關系,我們直接將以前的彈幕資料網址接口拿過來使用就行,
API: https://api.bilibili.com/x/v1/dm/list.so?oid=XXX
這個oid其實就是一串數字,每個視頻都有一個獨特的oid,
2. oid資料找尋
本小節就帶著大家一步步找尋這個oid,要找到oid,首先要找到一個叫做cid的東西,
點擊F12,先打開開發者工具,按照圖中提示,完成1-5處的操作,
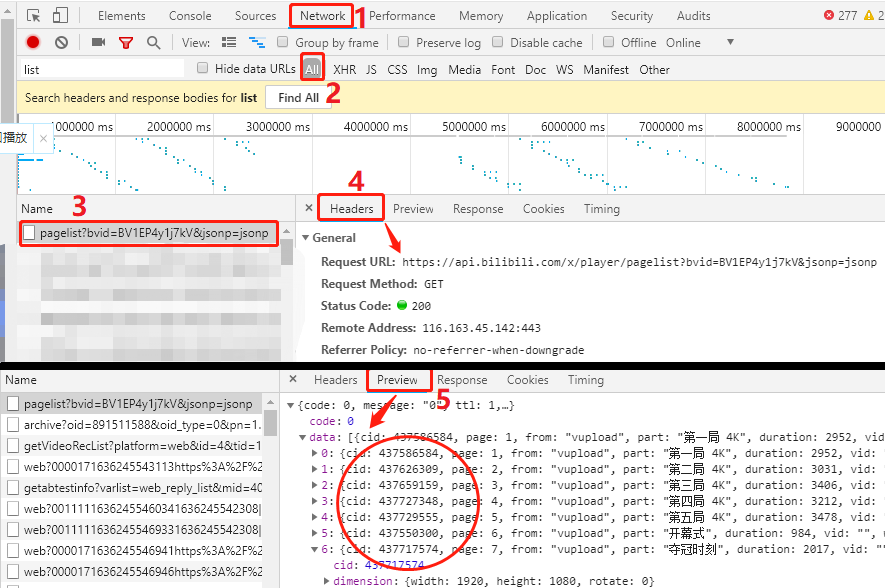
- 第3處:這個頁面有很多個請求,但是你需要找到這個以
pagelist開頭的請求, - 第4處:觀察對應的
Header下方,有一個Request URL,我們要的cid就在這個網址中, - 第5處:觀察對應的
Preview下方,就是請求Request URL,回應給我們的結果,圖中圈起來的就是我們要的cid資料,
2. cid資料獲取
上述我們已經找到了Request URL,下面我們只需要發起請求,獲取里面的cid資料即可,
import requests
import json
url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'
res = requests.get(url).text
json_dict = json.loads(res)
#pprint(json_dict)
for i in json_dict["data"]:
oid = i["cid"]
print(oid)
結果如下:
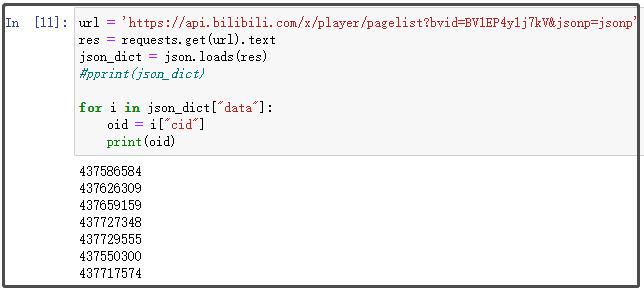
其實,這里cid對應的數字串,就是oid后面的數字串,
3. 拼接url
我們不僅有了彈幕api介面,也有了cid資料,接下來將它們進行拼接,就可以得到最終的url,
url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'
res = requests.get(url).text
json_dict = json.loads(res)
#pprint(json_dict)
for i in json_dict["data"]:
oid = i["cid"]
api = "https://api.bilibili.com/x/v1/dm/list.so?oid="
url = api + str(oid)
print(url)
結果如下:
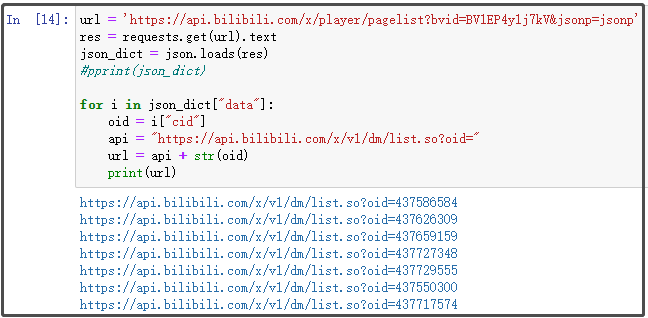
一共有7個網址,分別對應7個視頻里面的彈幕資料,
隨便點開一個查看:

4. 正則提取彈幕資料并保存
有了完整的url后,我們要做的就是提取里面的資料,這里還是直接采用正則運算式,我們以其中一個視頻為例,為大家講解,
final_url = "https://api.bilibili.com/x/v1/dm/list.so?oid=437729555"
final_res = requests.get(final_url)
final_res.encoding = chardet.detect(final_res.content)['encoding']
final_res = final_res.text
pattern = re.compile('<d.*?>(.*?)</d>')
data = pattern.findall(final_res)
with open("彈幕.txt", mode="w", encoding="utf-8") as f:
for i in data:
f.write(i)
f.write("\n")
結果如下:
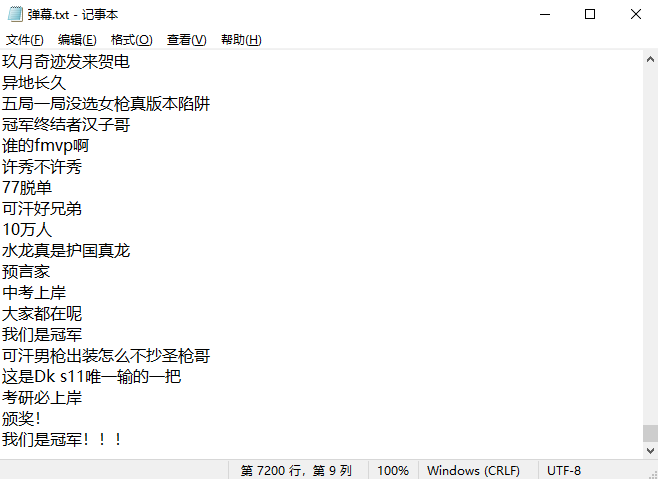
這只是其中一頁的資料,共有7200條資料,
完整代碼
上述我已經分步為大家講解了每一步程序,這里我直接將代碼封裝成函式,
import os
import requests
import json
import re
import chardet
# 獲取cid
def get_cid():
url = 'https://api.bilibili.com/x/player/pagelist?bvid=BV1EP4y1j7kV&jsonp=jsonp'
res = requests.get(url).text
json_dict = json.loads(res)
cid_list = []
for i in json_dict["data"]:
cid_list.append(i["cid"])
return cid_list
# 拼接url
def concat_url(cid):
api = "https://api.bilibili.com/x/v1/dm/list.so?oid="
url = api + str(cid)
return url
# 正則提取資料
def get_data(url):
final_res = requests.get(url)
final_res.encoding = chardet.detect(final_res.content)['encoding']
final_res = final_res.text
pattern = re.compile('<d.*?>(.*?)</d>')
data = pattern.findall(final_res)
return data
# 保存資料
def save_to_file(data):
with open("彈幕資料.txt", mode="a", encoding="utf-8") as f:
for i in data:
f.write(i)
f.write("\n")
cid_list = get_cid()
for cid in cid_list:
url = concat_url(cid)
data = get_data(url)
save_to_file(data)
結果如下:
確實很棒,一共3.1w資料!
保姆級詞云圖制作教程
對于獲取到了 資料,我們 利用EDG背景圖,制作一個好看的詞云圖,
# 1 匯入相關庫
import pandas as pd
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
from imageio import imread
import warnings
warnings.filterwarnings("ignore")
# 注意:動態添加詞語集
for i in ["EDG","永遠的神","yyds","牛逼","發來賀電"]
jieba.add_word(i)
# 2 讀取文本檔案,并使用lcut()方法進行分詞
with open("彈幕資料.txt",encoding="utf-8") as f:
txt = f.read()
txt = txt.split()
txt = [i.upper() for i in txt]
data_cut = [jieba.lcut(x) for x in txt]
# 3 讀取停用詞
with open("stoplist.txt",encoding="utf-8") as f:
stop = f.read()
stop = stop.split()
stop = [" "] + stop
# 4 去掉停用詞之后的最終詞
s_data_cut = pd.Series(data_cut)
all_words_after = s_data_cut.apply(lambda x:[i for i in x if i not in stop])
# 5 詞頻統計
all_words = []
for i in all_words_after:
all_words.extend(i)
word_count = pd.Series(all_words).value_counts()
# 6 詞云圖的繪制
# 1)讀取背景圖片
back_picture = imread("EDG.jpg")
# 2)設定詞云引數
wc = WordCloud(font_path="simhei.ttf",
background_color="white",
max_words=1000,
mask=back_picture,
max_font_size=200,
random_state=42
)
wc2 = wc.fit_words(word_count)
# 3)繪制詞云圖
plt.figure(figsize=(16,8))
plt.imshow(wc2)
plt.axis("off")
plt.show()
wc.to_file("ciyun.png")
結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/353463.html
標籤:其他