我正在使用 bs4 來抓取 Indeed.com 尋找作業(鏈接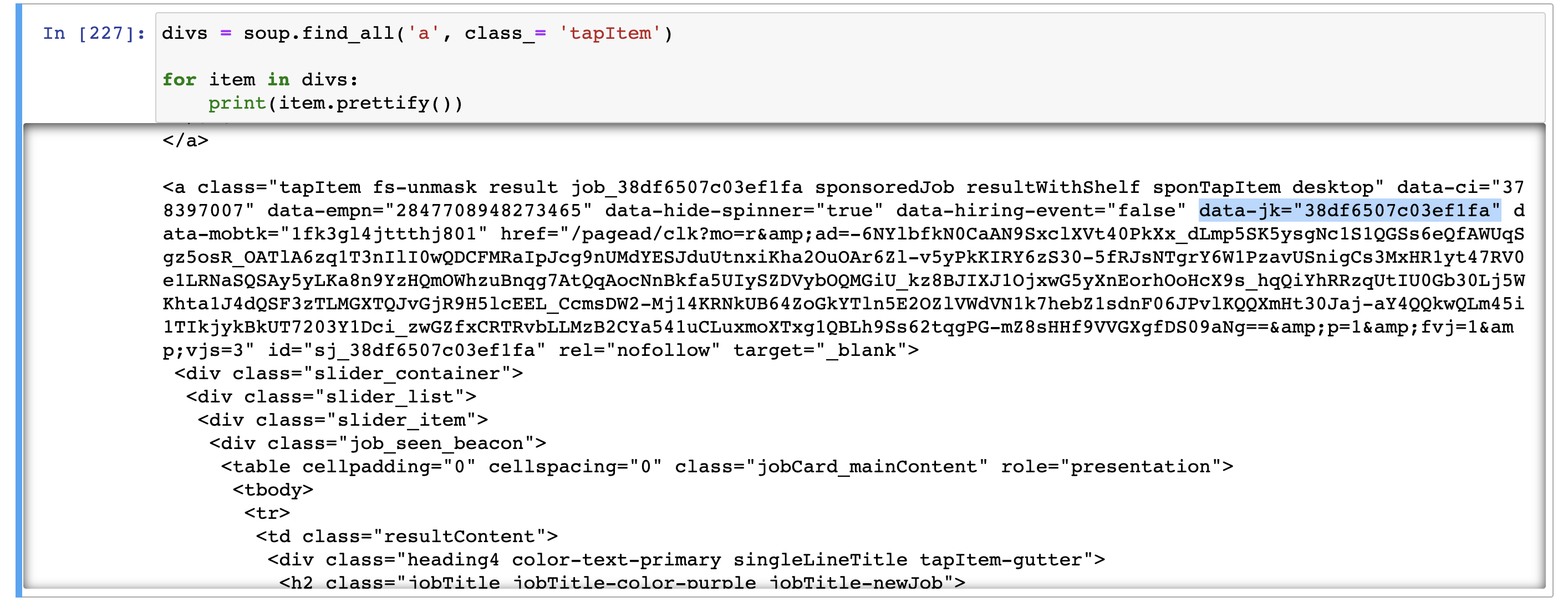
到目前為止,這是我使用 bs4 的功能:
def transform(soup):
divs = soup.find_all('a', class_= 'tapItem')
for item in divs:
title = item.find('h2', {'class':'jobTitle-color-purple'}).text
id = item.find('a')
print(title)
print(id)
transform(soup)
回傳以下結果:
newDevOps Engineer
<a class="turnstileLink companyOverviewLink" data-tn-element="companyName" href="/cmp/Tata-Consultancy-Services-(tcs)" rel="noopener" target="_blank">Tata Consultancy Services (TCS)</a>
newDevOps Engineer - Sydney, Australia
None
DevOps Engineers
<a class="turnstileLink companyOverviewLink" data-tn-element="companyName" href="/cmp/CGI" rel="noopener" target="_blank">CGI</a>
Graduate Software Developer/Programmer (DevOps)
<a class="turnstileLink companyOverviewLink" data-tn-element="companyName" href="/cmp/Tata-Consultancy-Services-(tcs)" rel="noopener" target="_blank">Tata Consultancy Services (TCS)</a>
Cloud Engineer (Entry level, AWS training provided)
As you can see, I am able to extract title successfully but not id, since I do not know how to select the data-jk value from within the <a> tag. I am also confused as to why the <a> tag with class: 'tapItem' does not even appear when I call item.find('a')?
I've scoured stackoverflow but am unable to find a similar question to mine. Hoping someone here can help me figure this out!
uj5u.com熱心網友回復:
title沒有直接href但所有報價都在里面<a>,我什至可以在您的影像上看到 - 在黑色背景的頂部(帶有target="_blank")
你得到job_seen_beaconwhich 也在 this 里面,<a>所以你不能訪問 this <a>。如果你在上面開始幾個標簽,那么你可以獲得<a>和 href`
#divs = soup.find_all('div', class_ = 'job_seen_beacon')
divs = soup.find('div', {'id': 'mosaic-provider-jobcards'}).find_all('a', {'class': 'result'})
for item in divs:
link = item['href']
完整的作業示例
import requests
from bs4 import BeautifulSoup
#extract
def extract(url):
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/14.1.2 Safari/605.1.15'}
r = requests.get(url, headers)
soup = BeautifulSoup(r.content, 'html.parser')
return soup
#transform
def transform(soup):
#divs = soup.find_all('div', class_ = 'job_seen_beacon')
divs = soup.find('div', {'id': 'mosaic-provider-jobcards'}).find_all('a', {'class': 'result'})
joblist = []
for item in divs:
title = item.find('h2', {'class':'jobTitle-color-purple'}).text
company = item.find('span', {'class': 'companyName'}).text
summary = item.find('div', {'class': 'job-snippet'}).text.replace('\n','')
link = item['href']
print(link)
job = {
'title': title,
'company': company,
'summary': summary,
'link': link,
}
joblist.append(job)
#print(job)
print('---')
return joblist
soup = extract('https://uk.indeed.com/jobs?q=devops&start=0')
joblist = transform(soup)
#print(joblist)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/354844.html