網路編程補充
- 1.認識
- 2.Socket網路編程
- 3.TCP通訊
- 4.echo模型
- 5.UDP
- 6.UDP廣播
- 7.HTTP
- 8.HTTP回應
- 9.建立回應目錄
- 10.動態請求處理
- 11.urllib3
- 12.twisted模塊認識
- 13.twisted開發TCP程式
- 14.使用twisted開發UDP程式
- 15.Deferred
1.認識
- 網路編程的核心功能就是 IO 操作
- 兩臺主機的通信要保證兩點:
- 線路暢通
- 雙方遵守協議
- 在進行網路程式開發的程序中一般都會考慮兩種不同的開發模式:
- C/S模式(Client/Server—客戶端/服務端架構)
- 需要撰寫兩套不同的程式(客戶端與服務端)
- 專案維護需要進行兩套專案的維護,維護成本比較高
- 但是這種程式一般使用特定的協議(TCP),特定的資料結構,隱藏的埠等,安全性比較高
- B/S模式(Browser/Server–瀏覽器與服務端架構)
- 基于WEB設計的一種架構,基于瀏覽器的形式作為客戶端進行訪問,
- 在程式開發時,成本較低,用戶使用門檻較低
- 但這種開發一般基于HTTP協議完成處理,安全性不高,使用的是80埠,極易遭到攻擊
- C/S模式(Client/Server—客戶端/服務端架構)
- OSI 7層模型 (開放式系統互聯)
- 網路程式開發不僅僅是一個簡單的資料互動程序,還包含一些資料的處理邏輯,而所有的網路設備一定會由不同的硬體廠商生產,所以為了保證資料傳輸的可靠性以及標準性,就定義了 OSI 7層模型
| No | 議成名稱 | 描述 |
|---|---|---|
| 1 | 應用層 | 提供網路服務操作介面 |
| 2 | 表示層 | 對要傳輸的資料進行處理,例如:資料編碼 |
| 3 | 會話層 | 管理不同的通訊節點之間的連接資訊 |
| 4 | 傳輸層 | 建立不同節點之間的網路連接,為資料追加段資訊 |
| 5 | 網路層 | 將網路地址映射為mac地址實作資料包轉發,為資料追加包資訊 |
| 6 | 資料鏈路層 | 將要發送的資料包轉換為資料幀,是其在不可靠的物理鏈路上進行可靠的資料傳輸,為資料追加幀資訊 |
| 7 | 物理層 | 利用物理設備實作資料的傳輸(二進制資料傳輸) |
- 有了這7層不同的網路資料的處理分類,所以任何的硬體廠商生產的設備(不管加入多少輔助技術),其核心是不變的
- Python屬于高級語言,所以對于所有的網路程式開發不可能讓開發者自行處理具體的OSI模型,應該采用統一的模式進行定義,這才有了Socket編程
2.Socket網路編程
Socket(套接字),是一種對TCP/UDP 網路協議進行的一種包裝(或者稱為協議的一種抽象應用),本身的特點提供了不同行程之間的資料通訊操作
- TCP(傳輸控制協議)
- 采用有狀態的通訊機制進行傳輸,在通訊時會通過三次握手機制保證與一個指定節點的資料傳輸的可靠性,在通訊完畢會通過四次揮手的機制關閉連接,由于每次資料的通訊前都需要消耗大量的時間進行連接控制,所以執行性能低,且資源占用較大
- UDP(資料報協議 /用戶資料報協議)
- 采用無狀態的通訊機制進行傳輸,沒有了TCP中復雜的握手與揮手處理機制,這樣就節約了大量的系統資源,同時資料傳輸性能較高,但由于不保存單個節點的連接狀態,所以發送的資料不一定可以被全部接受,
- UDP不需要鏈接就可以直接發送資料,并且多個接受端都可以同時接受同樣的資訊,所以UDP適合于廣播操作
不論是TCP還是UDP協議,都是對傳輸層操作的保證,資料按照OSI 七層模型來說 一定要通過網路層進行路由的配置,同時利用資料鏈路層添加資料幀,最終利用物理層發出,但是由于Socket機制的存在,所以開發者只需要撰寫處理的核心代碼,而具體的傳輸,協議操作就完全被包裝了
3.TCP通訊
TCP是面向連接的網路傳輸協議,在進行TCP通訊的程序中其安全性以及穩定性都是最高的,雖然性能會差些,但是對于當前網路環境來講主要還是使用TCP協議的居多
python中使用socket.socket類即可實作TCP程式開發:
| No | 函式 | 型別 | 描述 |
|---|---|---|---|
| 1 | socket() | 構造 | 獲取socket類物件 |
| 2 | bind(hostname,port) | 方法 | 在指定主機的埠系結監聽 |
| 3 | listen() | 方法 | 在系結的埠上開啟監聽 |
| 4 | accept() | 方法 | 等待客戶端連接,連接后回傳客戶端地址 |
| 5 | send(data) | 方法 | 發送資料 |
| 6 | recv(buffer) | 方法 | 接收資料 |
| 7 | close() | 方法 | 關閉套接字連接 |
| 8 | connect(hostname,port) | 方法 | 設定連接的主機名稱與埠號 |
- 客戶端開發程序:
- 創建TCP客戶端套接字
- 和服務端套接字建立連接
- 發送資料給服務端
- 接收服務端資料
- 關閉套接字
- 服務端開發程序
- 創建服務端套接字物件
- 設定埠埠號復用–讓服務端關閉后埠號立即釋放
- 系結埠號
- 設定監聽
- 等待接受客戶端連接(接收客戶端的套接字與埠)
- 接受資料
- 發送資料
- 關閉套接字(關閉客戶端套接字與服務端套接字)
整個Socket網路編程之中基本的核心流程就是服務端開啟監聽埠,等待客戶端連接,而客戶端想要訪問服務器就必須進行服務器的地址連接,而后進行回應的資料的請求或回應內容的接收
#-------------這是服務端--------
import socket
#服務端的地址埠
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket網路服務每一次處理完成之后一定要使用close()關閉,所以使用with結構定義
with socket.socket() as server_socket:#創建服務端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#系結服務端主機與埠
server_socket.listen()#開啟監聽
print('[服務端]服務端啟動完成,在%s埠上監聽等待客戶端連接,,,'%SERVER_PORT)
new_socket,iport=server_socket.accept()#等待客戶端連接,處于阻塞狀態
new_socket.send('你好,這里是服務端!'.encode())
print(iport,'連接成功! 回應:',new_socket.recv(128).decode())
if __name__ == '__main__':
main()
#------------這是客戶端----------
import socket
SERVER_HOST='127.0.0.1'#要連接的服務端的主機名稱或ip地址
SERVER_PORT=8080
def main():
with socket.socket() as client_socket:#建立客戶端socket
client_socket.connect((SERVER_HOST,SERVER_PORT))#連接服務器
print('服務端回應資料:%s'%client_socket.recv(128).decode())#接收資料長度為128字
client_socket.send('你好,這里是客戶端!'.encode())#發送訊息
if __name__ == '__main__':
main()
4.echo模型
echo程式模型來源于echo命令,在作業系統內部提供一個echo命令進行內容的回顯
echo指令 輸入什么–回傳什么
將echo的概念擴大到網路環境中,就可以理解為客戶端輸入一組資料發送到服務端,那么服務端接受之后對該資料進行回應,這種模型就是網路編程echo模型
在整個網路編程中,由于所有網路程式一定要有一個系結的埠號存在,所以一個埠只允許系結一個服務,如果出現埠被占用的情況,那么程式將無法正常啟動
對于當前服務端程式如果想要測驗,簡單可以直接通過telnet命令來完成,每當用戶輸入一個內容之后就會立即將此內容發送到服務端,但window命令列采用的GBK編碼,會造成亂碼,但是可以測驗服務端是正確的
#-------------這是服務端--------
import socket
#服務端的地址埠
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket網路服務每一次處理完成之后一定要使用close()關閉,所以使用with結構定義
with socket.socket() as server_socket:#創建服務端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#系結服務端主機與埠
server_socket.listen()#開啟監聽
print('[服務端]服務端啟動完成,在%s埠上監聽等待客戶端連接,,,'%SERVER_PORT)
cli_socket,iport=server_socket.accept()#等待客戶端連接,處于阻塞狀態
with cli_socket:#進行客戶端的處理
while True:#不斷進行資訊的接收與回應
data = cli_socket.recv(128).decode() # 接收客戶端傳過來的資料
if data.upper()=='BYEBYE':#客戶端輸入此指令
cli_socket.send('exit'.encode())
break#結束回圈
else:#進行正常的回應
cli_socket.send(('echo %s'%data).encode())#向客戶端進行去請求回應
if __name__ == '__main__':
main()
#------------這是客戶端----------
import socket
SERVER_HOST='127.0.0.1'#要連接的服務端的主機名稱或ip地址
SERVER_PORT=8080
def main():
with socket.socket() as client_socket:#建立客戶端socket
client_socket.connect((SERVER_HOST,SERVER_PORT))#連接服務器
while True:#客戶端要不斷與服務端互動
input_data=input('請輸入要發送的資料(輸入byebye結束):')
client_socket.send(input_data.encode())#資料發送
echo_data=client_socket.recv(100).decode()
if echo_data.upper()=='EXIT':#結束
break#斷開連接
else:
print(echo_data)#輸出服務端回應內容
if __name__ == '__main__':
main()
當服務器端引入并發編程的概念之后,那么就可以同時進行多個客戶端的請求處理,在開發行業內有一個“高并發”指的就是連接客戶端比較多,所以這個時候如何處理好服務端處理性能就成為專案設計的關鍵
#-------------這是服務端--------
import multiprocessing
import socket
#服務端的地址埠
SERVER_HOST='localhost'
SERVER_PORT=8080
def echo_handle(cli_socket,iport):#行程處理函式
print('[服務端],在%s埠上監聽客戶端,,,' % iport[1])
with cli_socket: # 進行客戶端的處理
while True: # 不斷進行資訊的接收與回應
data = cli_socket.recv(128).decode() # 接收客戶端傳過來的資料
if data.upper() == 'BYEBYE': # 客戶端輸入此指令
cli_socket.send('exit'.encode())
break # 結束回圈
else: # 進行正常的回應
cli_socket.send(('echo %s' % data).encode()) # 向客戶端進行去請求回應
def main():
#socket網路服務每一次處理完成之后一定要使用close()關閉,所以使用with結構定義
with socket.socket() as server_socket:#創建服務端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#系結服務端主機與埠
server_socket.listen()#開啟監聽
while True:#不斷接受請求
print('[服務端]服務端啟動完成,在%s埠上監聽等待客戶端連接,,,' % SERVER_PORT)
cli_socket, iport = server_socket.accept() # 等待客戶端連接,處于阻塞狀態
process=multiprocessing.Process(target=echo_handle,args=(cli_socket,iport),name='客戶端行程-%s'%iport[1])#定義行程
process.start()#啟動行程
if __name__ == '__main__':
main()
5.UDP
UDP也是網路傳輸層上的一種協議,但與TCP相比,UDP本身采用的是不安全的連接,所以來講每一次通過UDP發送對1資料不一定可以接收到,但是由于其性能比較好,所以未來會有廣闊的發展前景
在Python中對于TCP/UDP本身的實作結構差別不大,都是通過socket.socket類完成的,只需要設定一些引數即可將其設為UDP(資料報協議)
UDP與TCP服務端最大的區別是不再需要過多的考慮到資料穩定性的連接問題了,所以也不再設定有具體的監聽操作,在每次接收到請求之后只需要獲取客戶端的原始地址,直接根據原路回傳即可
#-------------這是服務端--------
import socket
#服務端的地址埠
SERVER_HOST='localhost'
SERVER_PORT=8080
def main():
#socket網路服務每一次處理完成之后一定要使用close()關閉,所以使用with結構定義
#socket.AF_INET ip4網路協議進行服務端創建
#socket.SOCK_DGRAM創建一個資料報協議的服務端(UDP)
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as server_socket:#創建服務端Socket
server_socket.bind((SERVER_HOST,SERVER_PORT))#系結服務端主機與埠
print('[服務端]服務端啟動完成,在%s埠上監聽等待客戶端連接,,,'%SERVER_PORT)
while True:#不斷進行接收
data,iport=server_socket.recvfrom(30)#接收客戶端發送的資料
print(iport, '連接成功! 回應:')
echo_data=('echo %s'%data.decode()).encode()#回應資料 從哪來會那去
server_socket.sendto(echo_data,iport)#將內容回應到發送端上
if __name__ == '__main__':
main()
#------------這是客戶端----------
import socket
SERVER_HOST='127.0.0.1'#要連接的服務端的主機名稱或ip地址
SERVER_PORT=8080
def main():
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as client_socket:#建立客戶端socket
while True:#客戶端要不斷與服務端互動
input_data=input('請輸入要發送的資料(輸入byebye結束):')
client_socket.sendto(input_data.encode(),(SERVER_HOST,SERVER_PORT))#資料發送
if input_data:#如果有資料
echo_data=client_socket.recv(100).decode()#回應資料
print('服務端回應資料: %s'%echo_data)#輸出內容
else:#沒有資料 (直接回車表示程式結束)
break #退出互動
if __name__ == '__main__':
main()
6.UDP廣播
使用UDP除了可以建立快速的網路通訊之外,實際還有一個主要的功能就是實作資料廣播的操作,它可以實作一個局域網內的所有主機資訊的廣播處理,要實作UDP廣播操作,則一定要在程式之中使用如下的方法進行定義:
setsockopt(self,level:int,optname:int,value:Union[int,bytes])
#level:設定選項所在的協議層編號,有如下四個可用的配置項
#socket.SOL_SOCKET:基本套接字介面
#socket.IPPROTO_IP:IP4套接字介面
#socket.IPPROTO_IPV6:IPv6套接字介面
#socket.IPPROTO_TCP:TCP套接字介面
#optname:設定選項名稱,例如,如果要進行廣播則可以使用 socket.BROADCAST
#value:設定選項的具體內容
如果要進行廣播肯定要有廣播的接收端,而接收端不一定可以接收到廣播,但只要打開接收端就可以接收到廣播
#------------這是廣播接收端----------
import socket
BROADCAST_CLIENT_ADDR=('0.0.0.0',21567)#客戶端的系結地址 當前主機
SERVER_HOST='127.0.0.1'#要連接的服務端的主機名稱或ip地址
SERVER_PORT=8080
def main():
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as client_socket:#建立客戶端socket
client_socket.setsockopt(socket.SOL_SOCKET,socket.SO_BROADCAST,1)#設定廣播模式
client_socket.bind(BROADCAST_CLIENT_ADDR)#系結廣播客戶端地址
while True:#不斷進行接收
message,iport=client_socket.recvfrom(100)#接收廣播資訊
print('接收的訊息內容為%s,訊息來源%s,訊息埠%s'%(message.decode(),iport[0],iport[1]))
if __name__ == '__main__':
main()
當客戶端執行后就持續等待服務端訊息的發送,就跟所有手機一樣,如果手機沒有待機的狀態輪詢服務器,那么就不可能接聽電話或者短息,
#-------------這是廣播發送端--------
import socket
BROADCAST_SERVER_ADDR=('<broadcast>',21567)#設定廣播地址
def main():
#socket網路服務每一次處理完成之后一定要使用close()關閉,所以使用with結構定義
#socket.AF_INET ip4網路協議進行服務端創建
#socket.SOCK_DGRAM創建一個資料報協議的服務端(UDP)
with socket.socket(socket.AF_INET,socket.SOCK_DGRAM) as server_socket:#創建服務端Socket
server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_BROADCAST,1)#設定廣播模式
server_socket.sendto('這是廣播發送端'.encode(),BROADCAST_SERVER_ADDR)
if __name__ == '__main__':
main()
在進行廣播處理的時候只需要設定一個《 broadcast》地址就可以實作廣播的處理,而對于接收端而言則不能保證資訊可以正常接收
7.HTTP
在標準的網路通信之中使用的是socket編程,而socket編程是對TCP/UDP協議進行抽象實作,在整個實作之中,可以清楚的發現,幾乎不需要過多的考慮TCP/UDP實作細節,而后完全基于socket就可以非常簡單的實作了
但是socket編程本身會存在一個問題,就是必須提供兩個程式端:客戶端/服務端,服務端是整個網路編程的核心所在,但是如果每一次服務端的升級都需要進行客戶端的強制更新,那么這種做法就會顯得非常麻煩了,所以在傳統網路編程的基礎上就形成了HTTP協議(是針對TCP協議的一種更高級的包裝,TCP協議本身存有性能問題,所以HTTP實作也可能產生更大的性能問題,所以未來可能在UDP協議基礎上實作HTTP協議),
HTTP協議是一種應用在www萬維網上實作資料傳輸的一種資料互動協議,客戶端基于瀏覽器向服務器端發送HTTP服務請求,服務端會根據用戶的請求進行資料檔案的加載,并將要回應的資料資訊以HTML檔案格式進行傳輸,當瀏覽器接收到此資料資訊時就可以直接進行代碼的決議并將資料資訊顯示給用戶瀏覽
在整個的HTTP開發流程之中,最為重要的設計就放在HTML代碼的撰寫上,對于WEB服務器開發者而言更為重要是清楚HTTP服務器的開發
雖然HTTP是基于TCP協議基礎之上開發的新協議,但其本質并沒有脫離傳統的TCP協議(可靠連接,資料互動),隨后在TCP協議的基礎上擴充了HTTP自己的內容,就成為了新的協議,而這些內容實際上都是隨著每一次請求和回應的頭部資訊來進行發送的
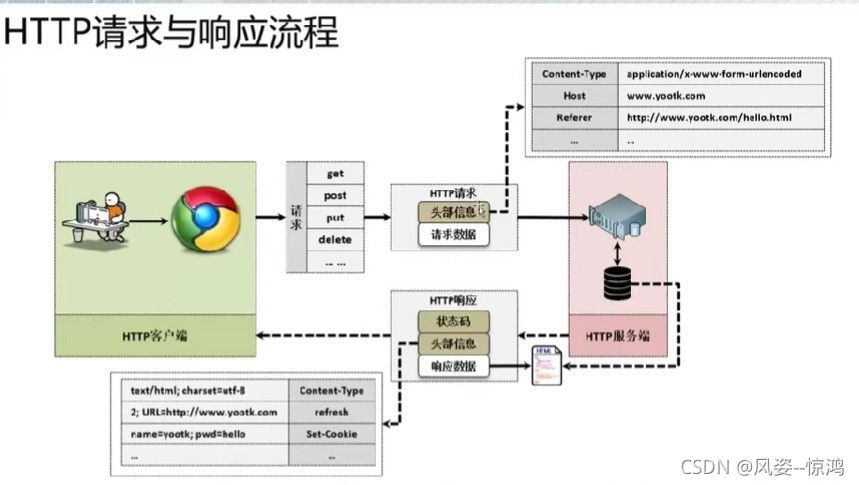
在整個HTTP請求和回應的處理程序中,核心問題就在于:請求和回應的頭部資訊有哪些,回應狀態碼(HTTP服務請求之后的狀態碼是確定回應能否正確執行的關鍵部分)
在HTTP協議之中,為了便于用戶的請求,所以設計有多種請求模式(比較常見的就是get/post),對于一些流行的Restful設計的結構,有可能會進行這些不同模式的請求區分,隨著HTTP版本的不斷提升,請求的模式也在不斷的增加
| No | 方法 | 描述 |
|---|---|---|
| 1 | GET | 請求指定的頁面資訊,并回傳物體主體 |
| 2 | HEAD | 類似于get請求,只不過回傳的回應中沒有具體的內容,用于獲取請求頭部資料 |
| 3 | POST | 向指定的資源提交資料進行處理請求(例如提交表單或上傳檔案) |
| 4 | PUT | 從客戶端向服務器傳輸資料取代替指定檔案的內容 |
| 5 | DELETE | 請求服務器洗掉指定的頁面 |
| 6 | CONNECT | HTTP/1.1協議中預留給能夠將連接改為管道方式的代理服務器 |
| 7 | OPTIONS | 允許客戶端查看服務器的性能 |
| 8 | TRACE | 回顯服務器接收到的請求,主要用于測驗或診斷 |
在每一次客戶端發送HTTP請求的時候除了真實的內容之外,還會包含有許多的頭部資訊
| No | 頭部資訊 | 描述 | 實體 |
|---|---|---|---|
| 1 | Accept | 設定客戶端顯示型別 | Accept: text/html,application |
| 2 | Accept-Encoding | 設定瀏覽器可以支持的壓縮編碼型別 | Accept-Encoding: gzip, deflate, br |
| 3 | Accept-Language | 瀏覽器可接受的語言 | Accept-Language: zh-CN,zh;q=0.9 |
| 4 | Cookie | 將客戶端保存的資料發送到服務器 | Cookie:name=lsf |
| 5 | Content-Length | 請求內容的長度 | Content-Length:348 |
| 6 | Content-Type | 請求與物體對應的MIME資訊 | |
| 7 | HOST | 請求主機 | HOST:www.baidu.com |
| 8 | Referer | 訪問來路 | Referer:https://www.baidu.com.html |
服務器能否正常運行,還有一個關鍵性的問題,就是服務器端對于請求的回應編碼回應
| 分類 | 描述 |
|---|---|
| 1** | 資訊,服務器接收到請求,需要請求者繼續執行操作 |
| 2** | 成功,操作被成功接收并處理 |
| 3** | 重定向,需要進一步的操作以完成請求 |
| 4** | 客戶端錯誤,請求包含語法錯誤或無法完成請求 |
| 5** | 服務器錯誤,服務器在處理請求的程序中發送了錯誤 |
在每一次HTTP服務器回應的時候實際也存在各種頭資訊,這些頭資訊實際上就是告訴瀏覽器該如何解釋代碼
| No | 頭資訊 | 描述 |
|---|---|---|
| 1 | Content-Encoding | 回傳壓縮編碼型別 |
| 2 | Content-Language | 回應內容支持的語言 |
| 3 | Content-Length | 回應內容的長度 |
| 4 | Content-Type | 回應資料的MIME型別 |
| 5 | Last-Modified | 請求資源的最后修改時間 |
| 6 | Location | 重定向路徑 |
| 7 | refersh | 資源定時重繪配置 |
| 8 | Server | web服務器軟體名稱 |
| 9 | Set-Cookie | 設定Http C ookie |
8.HTTP回應
在HTTP編程之中核心的本質依舊是進行請求和回應,只不過這個回應處理資料之外還需包含頭資訊,這些內容一定要被瀏覽器進行決議,瀏覽器在進行請求的時候需要依據服務器的主機名稱和訪問埠進行請求的發送,
所有的HTTP服務器一定要通過瀏覽器進行訪問,服務器系結在本機的80埠上,那么就可直接進行本地服務訪問,瀏覽器輸入:http://localhost
#---------------http基礎服務端---------
import socket #http是基于TCP協議,所以一定使用socket
import multiprocessing #考慮到性能問題,為每一次請求開啟一個新的行程
class HttpServer:
'''服務器的程式類'''
def __init__(self,port):#服務器要有一個監聽的埠
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#創建socket實體
#考慮到不同系統的問題,80埠是一個必爭埠,該埠屬于系統的核心埠,所以將核心任務與核心埠系結
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#系結核心埠
self.server_socket.listen()#啟動監聽
def start(self):
'''服務器開始提供服務'''
while True:#持續提供服務
cli_socket,iport=self.server_socket.accept()#接收客戶端請求
print('新的客戶端連接,客戶端ip:%s,客戶端埠:%s'%(iport[0],iport[1]))#輸出客戶端資訊
#將客戶端都設定為一個獨立的行程存在 都分別進行請求的回應
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#行程啟動
def handle_response(self,cli_socket):
'''對每一個指定的客戶端進行回應'''
request_headers=cli_socket.recv(1024)#用戶通過瀏覽器發送的請求本身就攜帶頭資訊
print('客戶端請求頭資訊:%s'%request_headers.decode())#輸入用戶請求頭資訊
response_start_line='HTTP/1.1 200 OK'#本次的回應成功
response_headers='Server: wph Server\r\nContent-Type:text/html\r\n'#可以添加更多的回應頭資訊
response_body= '<html>'\
' <head>'\
' <title>測驗</title>'\
' <meta charset="UTF-8"/>'\
' </head>'\
'<body>'\
' <h1>測驗頁面</h1>'\
'</body>'\
'</html>'
response=response_start_line+response_headers+'\r\n'+response_body#最終的回應內容
cli_socket.send((response).encode())#服務端回應
cli_socket.close()#HTTP不保留用戶狀態,所以每次處理后都斷開連接,否則會造成性能開支,且這些開支是無意義的
def main():
http_server=HttpServer(80)#80為服務器的默認埠,可以不用輸入,直接輸入域名即可
http_server.start()#開啟服務
if __name__ == '__main__':
main()
9.建立回應目錄
如果html代碼以字串的形式出現在整個Python程式里面,那么這樣的HTML代碼是很難被前端進行維護的,前端需要的是一個可以進行回應的處理目錄,相當于建立一個專屬的html回應代碼目錄,而后所有要回應的內容都要保存在此目錄之中
#---------------http基礎服務端---------
import socket #http是基于TCP協議,所以一定使用socket
import re
import os #進行檔案路徑的定義
#os.getcwd() 當前檔案的根目錄 os.sep \
HTML_ROOT_DIR=os.getcwd()+os.sep#回應目錄
import multiprocessing #考慮到性能問題,為每一次請求開啟一個新的行程
class HttpServer:
'''服務器的程式類'''
def __init__(self,port):#服務器要有一個監聽的埠
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#創建socket實體
#考慮到不同系統的問題,80埠是一個必爭埠,該埠屬于系統的核心埠,所以將核心任務與核心埠系結
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#系結核心埠
self.server_socket.listen()#啟動監聽
def start(self):
'''服務器開始提供服務'''
while True:#持續提供服務
cli_socket,iport=self.server_socket.accept()#接收客戶端請求
print('新的客戶端連接,客戶端ip:%s,客戶端埠:%s'%(iport[0],iport[1]))#輸出客戶端資訊
#將客戶端都設定為一個獨立的行程存在 都分別進行請求的回應
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#行程啟動
def handle_response(self,cli_socket):
'''對每一個指定的客戶端進行回應'''
request_headers=cli_socket.recv(1024)#用戶通過瀏覽器發送的請求本身就攜帶頭資訊
#使用正則提取請求頭資訊
file_name=re.match(r'\w+ +(/[^ ]*)',request_headers.decode().split('\r\n')[0]).group(1)
# file_name=request_headers.decode().split(' ',2)[1]
if file_name=='/':
file_name= 'wenjian/index.html' #為根目錄
if file_name.endswith('.wenjian') or file_name.endswith('.htm'):
cli_socket.send(self.get_html_data(file_name).encode())#服務端回應
else:#二進制圖表內容
cli_socket.send(self.get_binary_data(file_name))#回應二進制資料
cli_socket.close()#HTTP不保留用戶狀態,所以每次處理后都斷開連接,否則會造成性能開支,且這些開支是無意義的
def read_file(self,file_name):#讀檔案資料
file_path=os.path.normpath(HTML_ROOT_DIR+file_name)#檔案的完整路徑
file=open(file_path,'rb')#采用二進制流的形式讀取
file_data=file.read()#讀取檔案內容
file.close()
return file_data #回傳讀取的資料
def get_binary_data(self,file_name):#二進制檔案的讀取
response_body=self.read_file(file_name)
return response_body
def get_html_data(self,file_name):#讀取指定檔案
response_start_line = 'HTTP/2 200 OK\r\n'
# 回應頭
response_headers = 'Server PWS/2.0\r\n' # 可以添加更多的回應頭資訊
response_body =self.read_file(file_name).decode()#設定回應內容
response = response_start_line + response_headers + '\r\n' + response_body # 最終的回應內容
return response
def main():
http_server=HttpServer(80)#80為服務器的默認埠,可以不用輸入,直接輸入域名即可
http_server.start()#開啟服務
if __name__ == '__main__':
main()
10.動態請求處理
對于web開發來說,分為兩個處理階段:靜態web處理,動態web處理,在之前設定的回應目錄實際上就是屬于靜態web處理,而動態web是可以進行動態的判斷來決定最侄訓傳的資料內容,
#---------------http基礎服務端---------
import socket #http是基于TCP協議,所以一定使用socket
import re
import os #進行檔案路徑的定義
import sys #模塊加載定位
sys.path.append('page')#追加模塊加載路徑
#os.getcwd() 當前檔案的根目錄 os.sep \
# HTML_ROOT_DIR=os.getcwd()+os.sep#回應目錄
# HTML_ROOT_DIR=r'F:\pythonstudy\python-Study\靜態Web服務器搭建\wenjian\static'#回應目錄
HTML_ROOT_DIR=r'F:\pythonstudy\python-Study\靜態Web服務器搭建\wenjian'#回應目錄
import multiprocessing #考慮到性能問題,為每一次請求開啟一個新的行程
class HttpServer:
'''服務器的程式類'''
def __init__(self,port):#服務器要有一個監聽的埠
self.server_socket=socket.socket(socket.AF_INET,socket.SOCK_STREAM)#創建socket實體
#考慮到不同系統的問題,80埠是一個必爭埠,該埠屬于系統的核心埠,所以將核心任務與核心埠系結
self.server_socket.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
self.server_socket.bind(('0.0.0.0',port))#系結核心埠
self.server_socket.listen()#啟動監聽
def start(self):
'''服務器開始提供服務'''
while True:#持續提供服務
cli_socket,iport=self.server_socket.accept()#接收客戶端請求
print('新的客戶端連接,客戶端ip:%s,客戶端埠:%s'%(iport[0],iport[1]))#輸出客戶端資訊
#將客戶端都設定為一個獨立的行程存在 都分別進行請求的回應
handle_cli_process=multiprocessing.Process(target=self.handle_response,args=(cli_socket,))
handle_cli_process.start()#行程啟動
def handle_response(self,cli_socket):
'''對每一個指定的客戶端進行回應'''
request_headers=cli_socket.recv(1024)#用戶通過瀏覽器發送的請求本身就攜帶頭資訊
print(request_headers.decode())
#使用正則提取請求頭資訊
# file_name=re.match(r'\w+ +(/[^ ]*)',request_headers.decode().split('\r\n')[0]).group(1)
file_name=request_headers.decode().split(' ',2)[1]
if file_name.startswith('/page'):#要訪問的是一個動態頁面
request_name=file_name[file_name.index('/',1)+1:]#訪問路徑
print('訪問路徑:"',request_name)
param_value=""#請求引數
if request_name.__contains__('?'):#引數路徑分隔符
request_param=request_name[request_name.index('?')+1:]
param_value=request_param.split('=')[1]#獲取引數名稱
request_name=request_name[0:request_name.index('?')]#獲取模塊名稱
model_name=request_name.split('/')[0]#模塊名稱
method_name=request_name.split('/')[1]#函式名稱
model=__import__(model_name)#加載模塊
method=getattr(model,method_name)
response_body=method(param_value)
response_start_line = 'HTTP/2 200 OK\r\n'
response_headers = 'Server PWS/2.0\r\n' # 可以添加更多的回應頭資訊
response = response_start_line + response_headers + '\r\n' + response_body # 最終的回應內容
cli_socket.send(response.encode())
cli_socket.close()#HTTP不保留用戶狀態,所以每次處理后都斷開連接,否則會造成性能開支,且這些開支是無意義的
def main():
http_server=HttpServer(80)#80為服務器的默認埠,可以不用輸入,直接輸入域名即可
http_server.start()#開啟服務
if __name__ == '__main__':
main()
#page包中echo.py檔案
def service(param):#回應的處理函式
if param:#如果此時的param有資料
return '<h1>'+param+'</h1>'
else:
return '<h1>NO found</h1>'
#訪問路徑:http://localhost/page/echo/service?param=
11.urllib3
urllib是Python中提供的一個url請求訪問的模塊,利用該模塊可以實作瀏覽器的模擬訪問,而urllib3是此模塊的升級版,主要是為Python3服務的,兩者功能類似,只不過有一些細微的差別
#--------------urllib3--------------
import urllib3
url='http://www.baidu.com'#頁面的訪問路徑
def main():
request_headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4676.0 Safari/537.36'
}
http=urllib3.PoolManager(num_pools=5,headers=request_headers)#獲取urllib3行程管理物件
response=http.urlopen('GET',url)#發送get請求
print(response.headers)#回應頭資訊
print(response.data.decode())#回應檔案
pass
if __name__ == '__main__':
main()
12.twisted模塊認識
java中的IO:
- 傳統BIO模型–同步阻塞IO
- 偽異步IO模型–以BIO為基礎,通過執行緒方式維護所有IO執行緒,實作相對高效的執行緒開銷及管理
- NIO模型–一種同步非阻塞IO
twisted類似NIO,是Python之中提供的專門實作異步處理的IO概念,它的主要功能是提升服務端資料的處理能力
難道使用多行程,多執行緒等并發技術不能良好的解決性能問題嗎?
要想理解twisted設計思想,那么首先就必須清楚傳統服務器端程式開發中存在的問題?
為了讓服務端的程式更加高效的客戶端請求處理,所以引入并發編程,將每一個客戶端單獨啟動一個行程或執行緒,這樣就可以實作服務器的并發回應
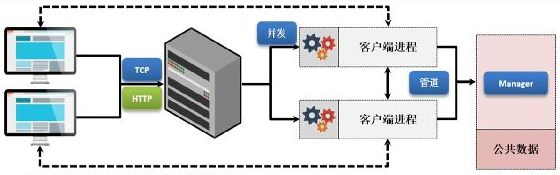
對于此時的開發架構已經充分的發揮出了電腦硬體性能的作用,使用硬體提供的核心支持,進行并發編程實作,但需要清楚的是早期的電腦硬體是沒有這樣所謂的多核CPU概念的,早期的設計里面使用的單核CPU,需要非常細致的解決不同行程以及執行緒彼此間所謂的等待與喚醒機制(死鎖問題),雖然單行程性能不高,但是卻可以有效的解決所謂的不同行程或執行緒之間可能產生的死鎖問題,
如果不使用并發編程的形式,那么就不會有并發編程之中的問題(資源切換,系統調度,同步與等待所帶來的性能損耗)
所有的傳統服務端,如果采用的是阻塞的模式,那么就會持續發生等待的操作問題,而這種等待的問題是嚴重的損耗服務端性能的,即便服務端硬體在強大,損耗也挺嚴重,
阻塞IO本質:使用水壺燒開水,在旁邊盯著看,怕水開后,水壺啥訓
非阻塞IO本質:不盯著水壺,對水壺進行定期的不斷輪詢,沒開就繼續干其他事,開了就結束燒水
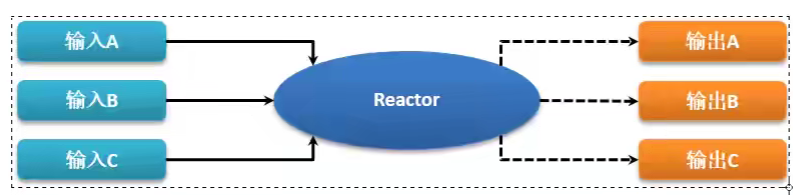
twisted是一個事件驅動的網路引擎,最大特點是提供有一個事件回圈處理,當外部事件發生時使用回呼機制來觸發相應的處理操作,多個任務在一個執行緒中執行,,這種方式可以使程式盡可能的減少對于其他執行緒的依賴,也使得程式開發人員不在關注執行緒安全問題
twsited中所有處理事件(注冊,注銷,運行,回呼處理等)全部交由reactor進行統一管理,在整個程式運行程序中,reactor回圈會以單執行緒的模式持續運行,當需要執行回呼處理時reactor會暫停回圈,當回呼操作執行完畢后將繼續采用回圈的形式進行其他任務處理,由于這種操作是從平臺行為中抽象出來的,這樣就使得網路協議堆疊的任何位置很容易的進行事件回應
13.twisted開發TCP程式
使用twisted最大的特點是進行服務端程式的開發,這樣的開發會為服務端的資源利用帶來極大的便利
使用twisted實作echo程式
如果要實作echo服務端程式的開發,那么讓服務端的處理類繼承一個twisted.internet.protocol.Protocol 父類,隨后就根據自己的需要來選擇要復寫的方法
#-------twisted服務端程式----------
import twisted #pip install Twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_PORT=8080#設定監聽埠
class Server(twisted.internet.protocol.Protocol):#服務端一定要設定一個繼承父類
def connectionMade(self):#客戶端連接時觸發
print('客戶端地址:%s'%self.transport.getPeer().host)
def dataReceived(self,data):#接收客戶端資料
print('服務端接受到的資料%s'%data.decode())#輸出接收到的資料
self.transport.write(('echo %s'%data.decode()).encode())#回應
class DefaultServerFactory(twisted.internet.protocol.Factory):#定義處理工廠類
protocol=Server#注冊回呼操作
def main():
twisted.internet.reactor.listenTCP(SERVER_PORT,DefaultServerFactory())#服務監聽
print('服務啟動完畢,等待客戶端連接,,,')
twisted.internet.reactor.run()#事件輪詢
if __name__ == '__main__':
main()
處理流程:定義事件的處理回呼操作程式–工廠中注冊–Reactor依據工廠來獲得相應的事件回呼處理操作類
#---------------twisted客戶端----------
import twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_HOST='localhost'#服務主機
SERVER_PORT=8080#連接埠
class Client(twisted.internet.protocol.Protocol):#定義用戶端處理類
def connectionMade(self):
print('服務器連接成功,可以進行資料互動,若要結束,則直接回車,,')
self.send()#建立連接后就進行資料的發送
def dataReceived(self,data):#接收服務端的資料
print('服務端 接收到資料:%s'%data.decode())#輸出接收到的資料
self.send()#繼續發送
def send(self):#資料發送 自定義的方法
input_data=input('請輸入要發送的資料:')
if input_data:#如果有資料
self.transport.write(input_data.encode())
else:#沒有輸入內容,表示操作的結束
self.transport.loseConnection()#關閉連接
class DefaultClientFactory(twisted.internet.protocol.ClientFactory):#客戶端工廠
protocol=Client#定義回呼
clientConnectionLost=clientConnectionFailed=lambda self,connector,reason:twisted.internet.reactor.stop()#停止回圈
def main():
twisted.internet.reactor.connectTCP(SERVER_HOST,SERVER_PORT,DefaultClientFactory())#連接主機服務
twisted.internet.reactor.run()#程式運行
if __name__ == '__main__':
main()
通程序式執行結果可以發現,此處避免了非常繁瑣的并發控制的操作,沒有了多行程或多執行緒的操作控制部分,整個執行流程都是基于單執行緒的運行模式完成(Python中的多執行緒存在GIL全域鎖問題,這就解決了此類問題)
14.使用twisted開發UDP程式
TCP是面向連接的可靠的網路服務,所以不管使用的是socket還是twisted都需要進行連接的操作控制,這樣一定會造成不必要的性能開支,所以twisted內部也支持有UDP程式開發,因為UDP不需要保證可靠連接,所以只需要定義好用戶的處理回呼操作即可,
#----------UDP twisted服務端-------
import twisted
import twisted.internet.protocol
import twisted.internet.reactor
SERVER_PORT=8080
class EchoServer(twisted.internet.protocol.DatagramProtocol):#資料報協議
def datagramReceived(self,datagram,addr):#接收資料處理
print('服務端 接收到訊息,訊息來源IP:%s,來源埠:%s'% addr)
print('服務端 接收到資料訊息:%s'%datagram.decode())
echo_data='echo %s'%datagram.decode()#設定回應資訊
self.transport.write(echo_data.encode(),addr)#將資訊回傳給指定客戶端
def main():
twisted.internet.reactor.listenUDP(SERVER_PORT,EchoServer())#服務監聽
print('服務器啟動完成,等待客戶端連接,,,')
twisted.internet.reactor.run()#事件回圈
if __name__ == '__main__':
main()
使用UDP進行處理的時候不在需要使用那些連接的控制,同時也不在需要通過工廠才可以與Reactor進行銜接,從結構上更加的簡單了
#------------UDP twisted客戶端操作---------
import twisted
import twisted.internet.reactor
import twisted.internet.protocol
SERVER_HOST='127.0.0.1'
SERVER_PORT=8080
CLIENT_PORT=0#客戶端地址
class EchoClient(twisted.internet.protocol.DatagramProtocol):#UDP客戶端1
def startProtocol(self):#連接的回呼
self.transport.connect(SERVER_HOST,SERVER_PORT)#連接
print('服務器連接成功,可以進行資料互動,如果要結束會話,直接回車')
self.send()#訊息發送
def datagramReceived(self,datagram,addr):#接收資料處理
print(datagram.decode())
self.send()#下一次資料發送
def send(self):#資料發送 自定義方法
input_data=input('請輸入要發送的資訊:')
if input_data:
self.transport.write(input_data.encode())
else:
twisted.internet.reactor.stop()#停止輪詢
def main():
twisted.internet.reactor.listenUDP(CLIENT_PORT,EchoClient())#服務監聽
twisted.internet.reactor.run()#開啟事件回圈
if __name__ == '__main__':
main()
所有網路程式進行開發的程序中實際上只有一個核心的目的:提升服務端的資源的可用性(發揮出最大的性能),減少操作的延遲,但是,UDP當今的應用都是在即時訊息通訊操作上,而對于TCP的開發操作依然是主流
15.Deferred
在網路開發之中,對于服務端性能提升可以使用twisted直接完成,但是在一些客戶端與網路服務器端互動的程序之中,有可能下載需要下載一些比較龐大的檔案內容(圖片,視頻等等),按照傳統的客戶端的開發模型來講,此時就需要持續進行下載,而對于當前的客戶端也將進入到一個阻塞的開發狀態,那么在這樣的情況下為了解決客戶端的阻塞問題,就提供了Deferred的概念
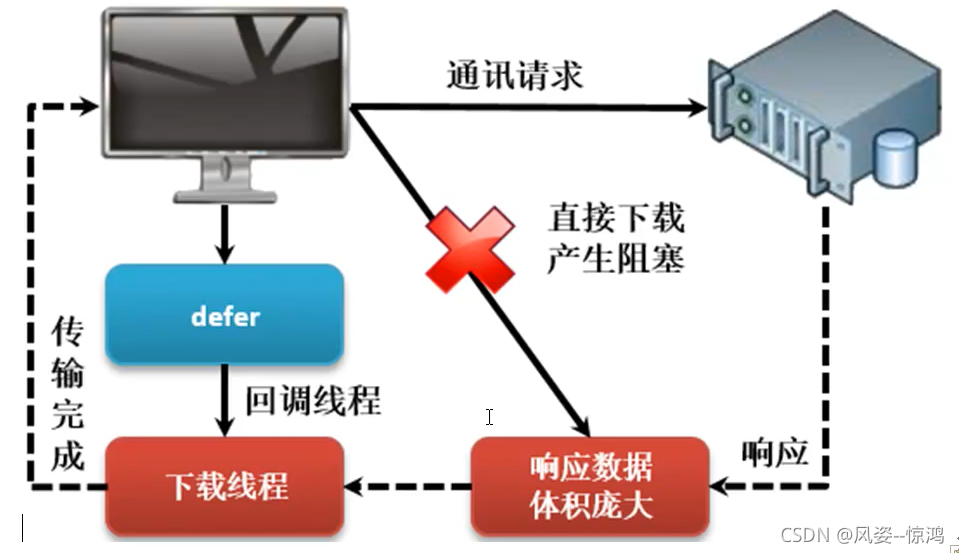
在twisted設計之中最大的特點就是持續的強調采用非阻塞的形式來完成,同時盡可能的減少并發操作,通過事件輪詢的方式來提升程式的可用資源,基于事件輪詢的機制設計出一套Deferred的模型
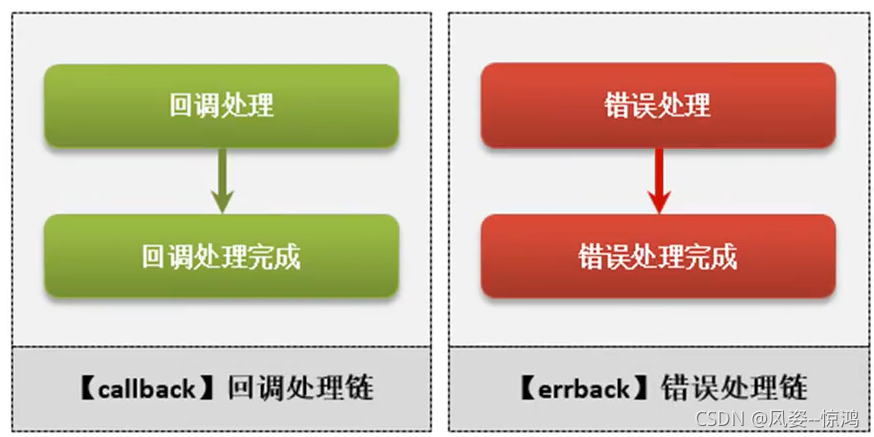
#------------defered模擬--------
import twisted
import twisted.internet.reactor
import twisted.internet.defer
import time
class DeferHandle:#設定一個回呼處理類
def __init__(self):
self.defer=twisted.internet.defer.Deferred()#獲取defer物件
def get_defer(self):#讓外部獲得實體物件
return self.defer
def work(self):#模擬網路下載
print('模擬網路下載延時操作,等待3秒,,,')
time.sleep(3)
self.defer.callback('finish')#執行回呼
def handle_success(self,result):
print('處理完成,進行引數的接收:%s'%result)#處理完畢后的資訊輸出
def handle_error(self,exp):#錯誤回呼
print('程式出錯:%s'%exp)
def stop():
twisted.internet.reactor.stop()
print('服務呼叫結束~~~~')
def main():
defer_client=DeferHandle()#獲得當前的回呼操作
twisted.internet.reactor.callWhenRunning(defer_client.work)#執行耗時操作
defer_client.get_defer().addCallback(defer_client.handle_success)#設定回呼處理 執行完畢后的回呼
defer_client.get_defer().addErrback(defer_client.handle_error)#錯誤輸出時的回呼
twisted.internet.reactor.callLater(5,stop)#5秒后停止Reactor呼叫
twisted.internet.reactor.run()#啟用事件的回圈
if __name__ == '__main__':
main()
在整個程式執行完畢后,就可以直接利用所設定的calback()操作進行操作完成后的呼叫,基于這樣的操作模型就減少了并發編程的使用,但使用twisted程式都是在解決網路通訊的性能問題,那么最佳的做法肯定就是Defered應用在網路的開發環境中,
通過Deffer模型實作TCP的echo客戶端
#----------defer TCP 客戶端-------
import twisted
import twisted.internet.defer
import twisted.internet.protocol
import twisted.internet.reactor
import twisted.internet.threads#自己控制的執行緒
import time
SERVER_HOST='localhost'
SERVER_PORT=8080
class DeferClient(twisted.internet.protocol.Protocol):#回呼處理類
def connectionMade(self):#創建連接
print('服務器連接成功,可以進行通信,如果要結束會話,直接回車即可')
self.send()#資訊發送
def dataReceived(self,data):#接收服務端發送的資料
content=data.decode()#接收服務端發送的資料
twisted.internet.threads.deferToThread(self.handle_request,content).addCallback(self.handle_success)
def handle_request(self,content):#資料處理程序
print('客戶端 對服務端的資料 %s 進行處理,可能會產生1~2秒延遲,,,'%content)
time.sleep(1)
return content #回傳處理結果
def handle_success(self,result):#操作處理完畢
print('處理完成,進行引數的接收:%s'%result)
self.send()#下一的資料發送
def send(self):#資料發送 自定義方法
input_data=input('請輸入要發送的資訊:')
if input_data:
self.transport.write(input_data.encode())
else:
self.transport.loseConnection()#關閉連接
class DefaultClientFactory(twisted.internet.protocol.ClientFactory):#客戶端工廠
protocol=DeferClient#設定回呼處理
clientConnectionLost=clientConnectionFailed=lambda self,connector,reason:twisted.internet.reactor.stop()
def main():
twisted.internet.reactor.connectTCP(SERVER_HOST,SERVER_PORT,DefaultClientFactory())#服務監聽
twisted.internet.reactor.run()#程式運行
if __name__ == '__main__':
main()
這種互動的模型主要是Deferred優化了客戶端之中的處理結構,在實際開發中,一個服務端有可能繼續呼叫其他的服務器端,而這個服務器還有可能同時要處理用戶的請求
- 無智亦無得,以無所得故
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/356766.html
標籤:其他