近些年,CPU等通用處理器的性能提升速度放緩,為了繼續滿足各行各業對高能效計算日益增長的需求,以FPGA,GPU,DSP,ASIC,NPU等為代表的異構算例,一夜之間在眾多的新型熱點領域受到廣泛關注,
首先結合市面上能夠看到的具體的產品來展示這些異構核之間的不同,
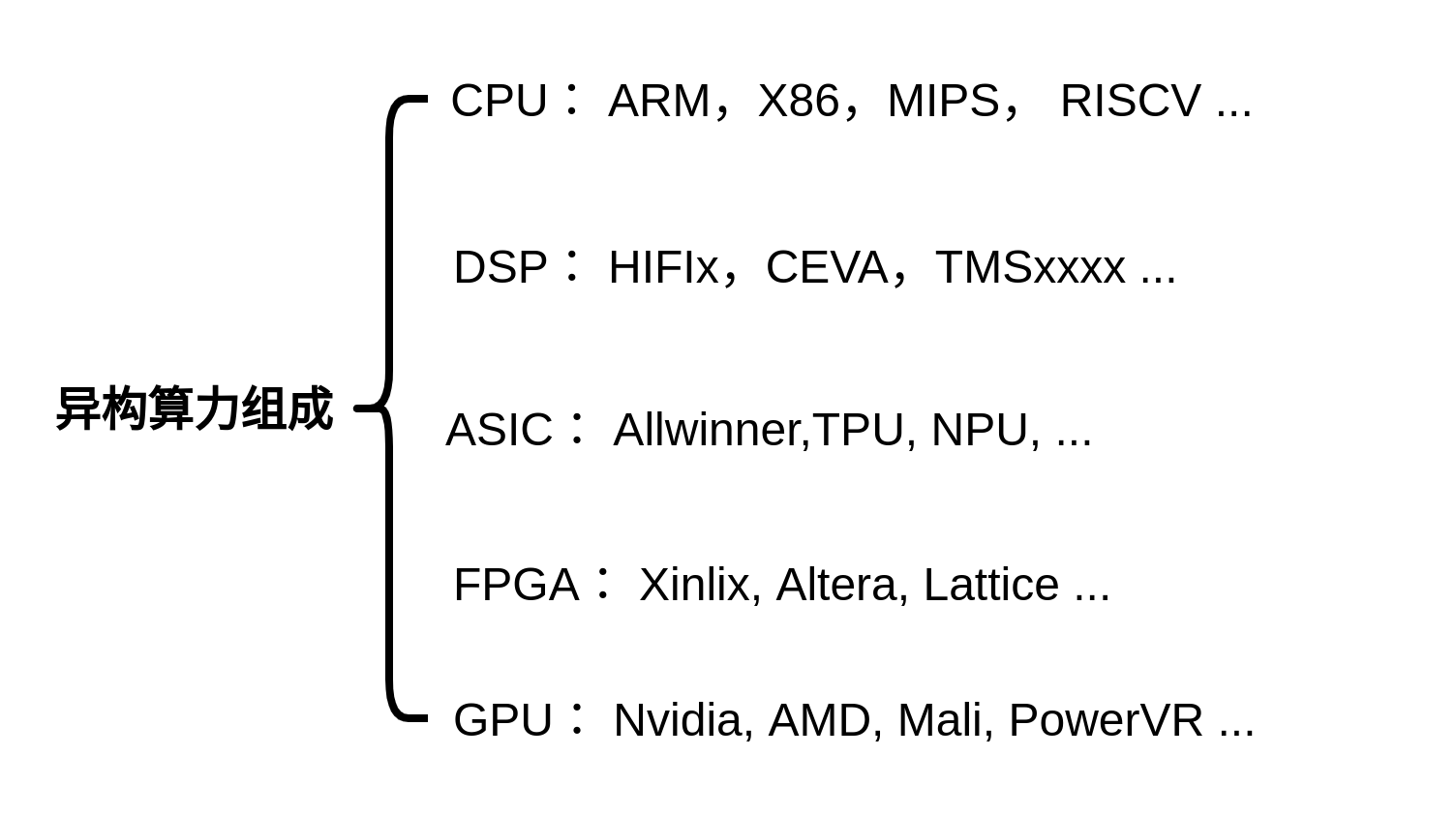
CPU、GPU 都屬于馮·諾依曼結構,指令譯碼執行、共享記憶體,馮氏結構中,由于執行單元(如 CPU 核)可能執行任意指令,就需要有指令存盤器、譯碼器、各種指令的運算器、分支跳轉處理邏輯,由于指令流的控制邏輯復雜,不可能有太多條獨立的指令流,因此 GPU 使用 SIMD(單指令流多資料流)來讓多個執行單元以同樣的步調處理不同的資料,CPU 也支持 SIMD 指令,
FPGA 之所以比 CPU 甚至 GPU 能效高,本質上是無指令、無需共享記憶體的體系結構帶來的福利, FPGA 每個邏輯單元的功能在重編程(燒寫)時就已經確定,不需要指令,
谷歌發布了人工智能芯片:Tensor Processing Unit,這是ASIC,TPU兼具了CPU與ASIC的特點,可編程,高效率,低能耗,還有多種多樣的各類用于CNN深度學習的NPU,它們也都可以歸為ASIC的一種,
DSP有些類似于CPU,但是它擁有更強的并行計算能力,支持多發射,VLIW指令以及單精度,雙精度浮點運算和專門用于SIMD加速的MAC陣列等,使其能耗比遠高于CPU,
GPU的峰值性能要高于FPGA,PPA,性能功耗比也要更優一些,FPGA基本單元的計算能力有限,為了實作可重構特性,FPGA 內部有大量極細粒度的基本單元,但是每個單元的計算能力(主要依靠LUT 查找表)都遠遠低于CPU 和GPU 中的ALU模塊,單位面積的功耗高,算力弱于GPU,價格高,PPA沒有優勢,
FPGA的強項是能夠實作可重構計算,
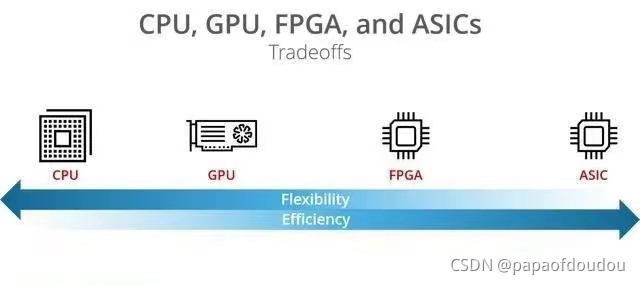
總體上看,各類異構芯片品類各有優劣,短時間內誰也替代不了誰,處于共存競爭的局面,
下面從軟體角度,分析幾類適用于異構芯片的并行處理方案,
1.CUDA
CUDA是一種新的操作GPU計算的硬體和軟體架構,它將GPU視作一個資料并行計算設備,而且無需把這些計算映射到圖形API,GPU 編程早期被稱為 通用GPU編程(General-popuse GPU programing,GPGPU),這一時期的程式員借助 Direct3D 和 OpenGL 的圖形 API 通過迷惑圖形硬體來執行非圖形的計算任務,CUDA (自2007年)的出現改變了這一切,
CUDA的架構如下圖所示:
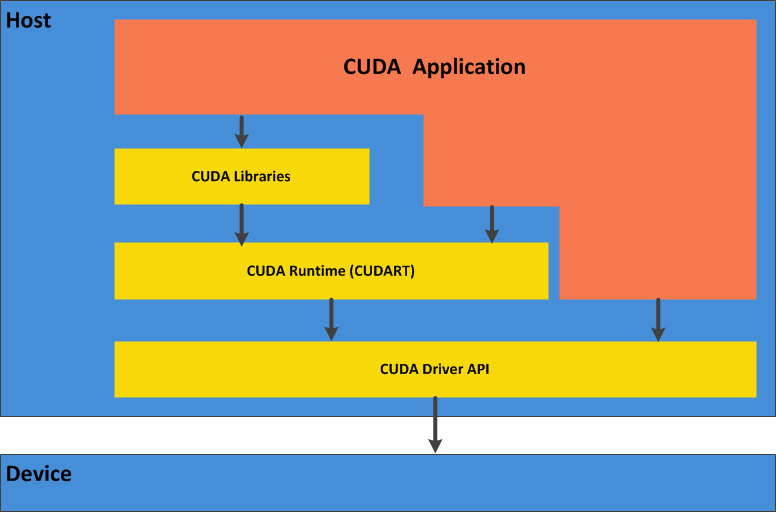
CUDA在軟體方面組成有:一個CUDA庫、一個應用程式編程介面(API)及其運行庫(Runtime)、幾個較高級別的通用數學庫,即CUFFT,CUDANN和CUBLAS,CUDA改進了DRAM的讀寫靈活性,使得GPU與CPU的機制相吻合,另一方面,CUDA提供了片上(on-chip)共享記憶體,使得執行緒之間可以共享資料,應用程式可以利用共享記憶體來減少DRAM的資料傳送,更少的依賴DRAM的記憶體帶寬,
CUDA程式構架分為兩部分:Host和Device,一般而言,Host指的是CPU,Device指的是GPU,在CUDA程式構架中,主程式還是由CPU 來執行,而當遇到資料并行處理的部分,CUDA 就會將程式編譯成 GPU能執行的程式,并傳送到GPU,而這個程式在CUDA里稱做核(kernel),CUDA允許程式員定義稱為核的C語言函式,從而擴展了C語言,在呼叫此類函式時,它將由N個不同的CUDA執行緒并行執行N次,這與普通的C語言函式只執行一次的方式不同,執行核的每個執行緒都會被分配一個獨特的執行緒ID,可通過內置的threadIdx變數在內核中訪問此ID,在 CUDA 程式中,主程式在呼叫任何 GPU內核之前,必須對核進行執行配置,即確定執行緒塊數和每個執行緒塊中的執行緒數以及共享記憶體大小,
關于CUDA的編程例子,可以參考這篇博客:
Darknet環境安裝CUDANN實作推理加速_tugouxp的專欄-CSDN博客首先參考下面幾篇文章安裝darknet,cuda的基礎環境:Yolov3網路的物體檢測_tugouxp的專欄-CSDN博客1.Get darknet 代碼$ git clone https://github.com/pjreddie/darknet$ cd darknet$ makecaozilong@caozilong-Vostro-3268:~/yolo$ git clone https://github.com/pjreddie/darknet正克隆到 'darknet'...remote: Enhttps://blog.csdn.net/tugouxp/article/details/121306727
采用這種方式進行計算加速的專案有比如darknet,在darknet/Makefile中通過開啟GPU=1,CUDNN=1來進行計算加速,
![]()
2.OpenMP(AVX)
OpenMP是用來對CPU計算進行加速的機制,penMP采用fork-join的執行模式,開始的時候只存在一個主執行緒,當需要進行并行計算的時候,派生出若干個分支執行緒來執行并行任務,當并行代碼執行完成之后,分支執行緒會合,并把控制流程交給單獨的主執行緒,
一個典型的fork-join執行模型的示意圖如下:
OpenMP編程模型以執行緒為基礎,通過編譯Directive指令指導并行化,有三種編程要素可以實作并行化控制,他們分別是編譯directive、API函式集和環境變數,
OpenMP具體使用可以參考這篇文章:GCC使用OpenMP_tugouxp的專欄-CSDN博客![]() https://blog.csdn.net/tugouxp/article/details/119210576
https://blog.csdn.net/tugouxp/article/details/119210576
3.SIMD(vector,neon)
這種方式是利用CPU,DSP中的專用VFP,SRAM硬體,在ISA層實作的加速指令,
4.NN Library.
這是比較常見的一種加速實作機制,比如CMSIS NN,BLAS,cudaNN等機制加速,
結束!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/357075.html
標籤:其他
下一篇:華為網路配置(ACL)