如果 ' value' 從day1到day7中等于(或相同),dplyr我如何將n列相加?另外,我怎么能filter只n擁有與7
首選輸出:
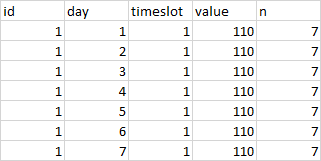
資料樣本:
structure(list(id = c(1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2,
2, 3, 3, 3, 3, 3, 3), day = c(1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4,
5, 6, 7, 1, 2, 3, 4, 5, 6), timeslot = c(1, 1, 1, 1, 1, 1, 1,
2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3), value = c(110, 110, 110,
110, 110, 110, 110, 9990, 110, 110, 110, 110, 110, 9990, 110,
110, 110, 110, 8310, 110), n = c(1L, 1L, 1L, 1L, 1L, 1L, 1L,
1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L, 1L)), row.names = c(NA,
-20L), groups = structure(list(id = c(1, 1, 1, 1, 1, 1, 1, 2,
2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3), day = c(1, 2, 3, 4, 5, 6,
7, 1, 2, 3, 4, 5, 6, 7, 1, 2, 3, 4, 5, 6), timeslot = c(1, 1,
1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3, 3, 3, 3, 3, 3), value = c(110,
110, 110, 110, 110, 110, 110, 9990, 110, 110, 110, 110, 110,
9990, 110, 110, 110, 110, 8310, 110), .rows = structure(list(
1L, 2L, 3L, 4L, 5L, 6L, 7L, 8L, 9L, 10L, 11L, 12L, 13L, 14L,
15L, 16L, 17L, 18L, 19L, 20L), ptype = integer(0), class = c("vctrs_list_of",
"vctrs_vctr", "list"))), row.names = c(NA, -20L), class = c("tbl_df",
"tbl", "data.frame"), .drop = TRUE), class = c("grouped_df",
"tbl_df", "tbl", "data.frame"))
uj5u.com熱心網友回復:
嘗試這個:
dat %>%
group_by(id) %>%
## test whether there is only one unique value per ID
filter(length(unique(value)) == 1) %>%
## sum up n
mutate(n = sum(n)) %>%
filter(n==7)
# A tibble: 7 × 5
# Groups: id [1]
id day timeslot value n
<dbl> <dbl> <dbl> <dbl> <int>
1 1 1 1 110 7
2 1 2 1 110 7
3 1 3 1 110 7
4 1 4 1 110 7
5 1 5 1 110 7
6 1 6 1 110 7
7 1 7 1 110 7
uj5u.com熱心網友回復:
library(data.table)
setDT(df)
df[, if (sum(n) == 7 && uniqueN(value) == 1) .SD, by = id]
#> id day timeslot value n
#> 1: 1 1 1 110 1
#> 2: 1 2 1 110 1
#> 3: 1 3 1 110 1
#> 4: 1 4 1 110 1
#> 5: 1 5 1 110 1
#> 6: 1 6 1 110 1
#> 7: 1 7 1 110 1
由reprex 包(v2.0.1)于 2021 年 11 月 23 日創建
uj5u.com熱心網友回復:
我會偷偷地介紹一下 data.table 方法,因為它總是很流行——它計算觀察的數量和唯一值的數量(這兩個都是每個 id),然后生成一個帶有 id 的 data.table 和評估的邏輯條件,然后將其合并到原始資料上,最后進行過濾。
library(data.table)
setDT(data1)
data1[data1[, .(.N, uniqueN(value)), by=id][, .(id, N==7 & V2==1)], on="id"][V2==TRUE, -c("V2")]
編輯:感謝 IceCreamToucan 在這個解決方案中的主要作業 - 我只是想在它周圍添加一些細節并進行一些細微的調整。這將if宣告放入jof DT[i, j, by](有關詳細資訊,請參閱[(https://cran.r-project.org/web/packages/data.table/vignettes/datatable-intro.html))。當該if陳述句決議為 時TRUE,它將回傳由特殊字符給出的選定變數,.SD—.SDcols缺失,因此默認為所有列。此版本還使用.N 特殊字符 — 的同義詞nrows()。此j-process 已完成byid。
data1[, if(.N==7 & uniqueN(value)==1){.SD}, by=id]
uj5u.com熱心網友回復:
讓我們將您的資料框命名為 df。
所以你可以使用這個:
# Add up column "n"
df %>%
left_join(df %>% group_by(id) %>% summarise(total_n = sum(n)) ) %>%
select(everything(), - n) %>%
filter(total_n == 7)
輸出:
# A tibble: 20 x 5
# Groups: id, day, timeslot, value [20]
id day timeslot value total_n
<dbl> <dbl> <dbl> <dbl> <int>
1 1 1 1 110 7
2 1 2 1 110 7
3 1 3 1 110 7
4 1 4 1 110 7
5 1 5 1 110 7
6 1 6 1 110 7
7 1 7 1 110 7
8 2 1 2 9990 7
9 2 2 2 110 7
10 2 3 2 110 7
11 2 4 2 110 7
12 2 5 2 110 7
13 2 6 2 110 7
14 2 7 2 9990 7
uj5u.com熱心網友回復:
澄清后更新(感謝 rg255):
library(dplyr)
df %>%
group_by(id) %>%
mutate(n=ifelse(n_distinct(value)==1, n(), 0)) %>%
filter(n == 7)
id day timeslot value n
<dbl> <dbl> <dbl> <dbl> <dbl>
1 1 1 1 110 7
2 1 2 1 110 7
3 1 3 1 110 7
4 1 4 1 110 7
5 1 5 1 110 7
6 1 6 1 110 7
7 1 7 1 110 7
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/364193.html
上一篇:根據條件值按組創建新變數