我有以下 df:
import pandas as pd
df = pd.DataFrame({'C':[5,4],'P':[2.3,5.6]})
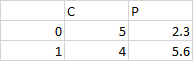
我想將第 1 行加入第 0 行,如下所示:

我知道重復的列被分配了一個“_1”。
uj5u.com熱心網友回復:
您的實際用例可能更復雜,但對于您的簡單示例,您可以執行以下操作。
選項 1 - 使用 unstack()
df.unstack().reset_index().drop('level_1', axis=1).set_index('level_0').T
level_0 C C P P
0 5.0 4.0 2.3 5.6
選項 2 - 使用 concat()
pd.concat([df.iloc[0], df.iloc[1]], axis=0).to_frame().T
C P C P
0 5.0 2.3 4.0 5.6
選項 3 - 使用 merge()
(df.iloc[0].to_frame().T.reset_index(drop=True)).merge((df.iloc[1].to_frame().T.reset_index(drop=True)), left_index=True, right_index=True)
C_x P_x C_y P_y
0 5.0 2.3 4.0 5.6
選項 4 - 使用 numpy.reshape()
pd.DataFrame(np.reshape(df.to_numpy(),(1,-1)))
0 1 2 3
0 5.0 2.3 4.0 5.6
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/365135.html
上一篇:使用正則運算式,Python
下一篇:帶句子的字謎程式