我是 SHAP 的新手,并試圖在我的 RandomForestClassifier 之上使用它。這是我已經運行后的代碼片段clf.fit(train_x, train_y):
explainer = shap.Explainer(clf)
shap_values = explainer(train_x.to_numpy()[0:5, :])
shap.summary_plot(shap_values, plot_type='bar')
這是結果圖:
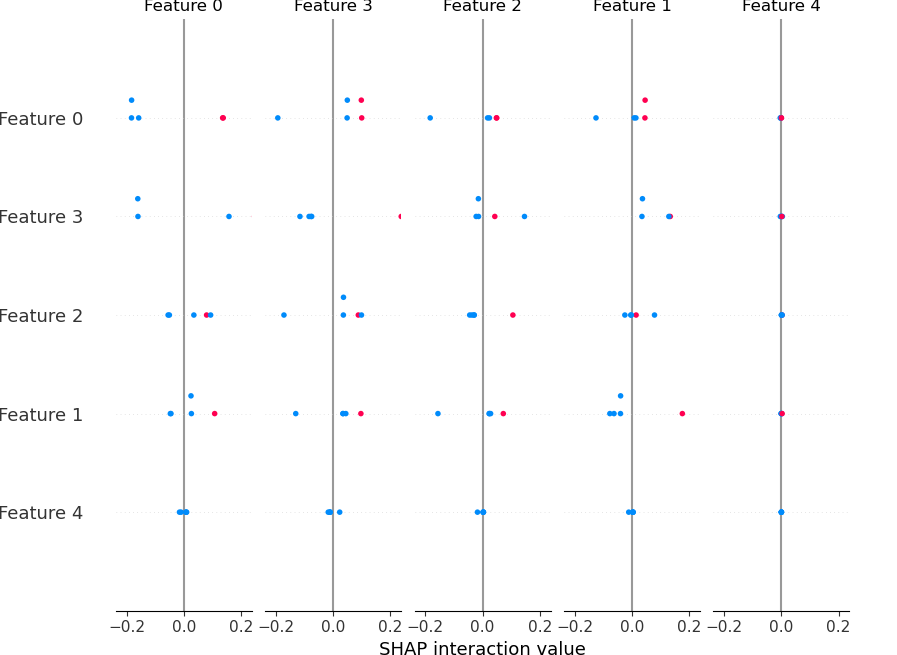
現在,這有兩個問題。一是即使我設定了plot_type引數,它也不是條形圖。另一個是我似乎以某種方式丟失了我的功能名稱(是的,呼叫時它們確實存在于資料框中clf.fit())。
我嘗試用以下內容替換最后一行:
shap.summary_plot(shap_values, train_x.to_numpy()[0:5, :], plot_type='bar')
這沒有任何改變。我還嘗試將其替換為以下內容,以查看是否至少可以恢復我的功能名稱:
shap.summary_plot(shap_values, train_x.to_numpy()[0:5, :], feature_names=list(train_x.columns.values), plot_type='bar')
但這引發了一個錯誤:
Traceback (most recent call last):
File "sklearn_model_runs.py", line 41, in <module>
main()
File "sklearn_model_runs.py", line 38, in main
shap.summary_plot(shap_values, train_x.to_numpy()[0:5, :], feature_names=list(train_x.columns.values), plot_type='bar')
File "C:\Users\kapoo\anaconda3\envs\sci\lib\site-packages\shap\plots\_beeswarm.py", line 554, in summary_legacy
feature_names=feature_names[sort_inds],
TypeError: only integer scalar arrays can be converted to a scalar index
在這一點上,我有點不知所措。我只是用 5 行訓練集嘗試過,但是一旦我克服了這個絆腳石,就想使用整個東西。如果有幫助,分類器有 5 個標簽,我的 SHAP 版本是 0.40.0。
uj5u.com熱心網友回復:
好吧,問題就在這里。替換這個:
shap_values = explainer(train_x.to_numpy()[0:5, :])
有了這個:
shap_values = explainer.shap_values(train_x) # Use whole thing as dataframe
然后您可以在繪圖期間使用它:
feature_names=list(train_x.columns.values)
這里的檔案真的應該更新......
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/366469.html