第五章
35題,36題已經做了更正,特別感謝粉絲奈七七的答案,
1.試說明運輸層在協議堆疊中的地位和作用,運輸層的通信和網路層的通信有什么重要區別?為什么運輸層是必不可少的?
答:運輸層處于面向通信部分的最高層,同時也是用戶功能中的最低層,向它上面的應用層提供服務 運輸層為應用行程之間提供端到端的邏輯通信,但網路層是為主機之間提供邏輯通信(面向主機,承擔路由功能,即主機尋址及有效的分組交換), 各種應用行程之間通信需要“可靠或盡力而為”的兩類服務質量,必須由運輸層以復用和分用的形式加載到網路層,
2.網路層提供資料報或虛電路服務對上面的運輸層有何影響?
答:網路層提供資料報或虛電路服務不影響上面的運輸層的運行機制, 但提供不同的服務質量,
3.當應用程式使用面向連接的TCP和無連接的IP時,這種傳輸是面向連接的還是面向無連接的?
答:都是,這要在不同層次來看,在運輸層是面向連接的,在網路層則是無連接的,
4.試用畫圖解釋運輸層的復用,畫圖說明許多個運輸用戶復用到一條運輸連接上,而這條運輸連接有復用到IP資料報上,
答:
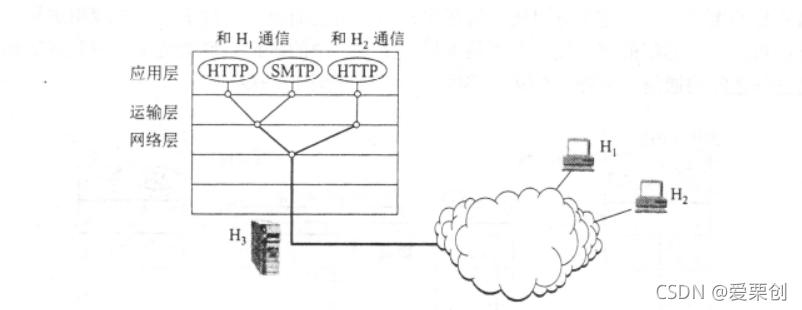
在圖中,主機H3同時和主機H1和主機H2進行通信,H1和H3兩個應用行程(HTTP和SMTP)進行通信,這需要使用兩個TCP連接,這兩個TCP連接所傳送的報文段,使用下面的網路層IP資料報進行傳送,H2和H3的應用行程(HTTP)進行通信,這需要使用一個TCP進行連接,這個TCP連接所傳送的報文段,也要使用下面的網路層IP資料報進行傳送,在網路層所傳送的IP資料報已看不到運輸層以上的復用情況,
5.試舉例說明有些應用程式愿意采用不可靠的UDP,而不用采用可靠TCP,
答:VOIP:由于語音資訊具有一定的冗余度,人耳對VOIP資料報損失由一定的承受度,但對傳輸時延的變化較敏感,有差錯的UDP資料報在接收端被直接拋棄,TCP資料報出錯則會引起重傳,可能帶來較大的時延擾動,因此VOIP寧可采用不可靠的UDP,而不愿意采用可靠的TCP,
6.接收方收到有差錯的UDP用戶資料報時應如何處理?
答:丟棄,
7.如果應用程式愿意使用UDP來完成可靠的傳輸,這可能嗎?請說明理由,
答:可能,但應用程式中必須額外提供與TCP相同的功能,
8.為什么說UDP是面向報文的,而TCP是面向位元組流的?
答:發送方 UDP 對應用程式交下來的報文,在添加首部后就向下交付 IP 層,UDP 對應用層交下來的報文,既不合并,也不拆分,而是保留這些報文的邊界,接收方 UDP 對 IP 層交上來的 UDP 用戶資料報,在去除首部后就原封不動地交付上層的應用行程,一次交付一個完整的報文,發送方TCP對應用程式交下來的報文資料塊,視為無結構的位元組流(無邊界約束,課分拆/合并),但維持各位元組,
9.埠的作用是什么?為什么埠要劃分為三種?
答:埠的作用是對TCP/IP體系的應用行程進行統一的標志,使運行不同作業系統的計算機的應用行程能夠互相通信,熟知埠,數值一般為0——1023.標記常規的服務行程;登記埠號,數值為1024——49151,標記沒有熟知埠號的非常規的服務行程,
10.試說明運輸層中偽首部的作用,
答:用于計算運輸層資料報校驗和,
11.某個應用行程使用運輸層的用戶資料報UDP,然而繼續向下交給IP層后,又封裝成IP資料報,既然都是資料報,可否跳過UDP而直接交給IP層?哪些功能UDP提供了但IP沒提提供?
答:不可跳過UDP而直接交給IP層IP資料報IP報承擔主機尋址,提供報頭檢錯;只能找到目的主機而無法找到目的行程,UDP提供對應用行程的復用和分用功能,以及提供對資料差分的差錯檢驗,
12.一個應用程式用UDP,到IP層把資料報在劃分為4個資料報片發送出去,結果前兩個資料報片丟失,后兩個到達目的站,過了一段時間應用程式重傳UDP,而IP層仍然劃分為4個資料報片來傳送,結果這次前兩個到達目的站而后兩個丟失,試問:在目的站能否將這兩次傳輸的4個資料報片組裝成完整的資料報?假定目的站第一次收到的后兩個資料報片仍然保存在目的站的快取中,
答:不行,重傳時,IP資料報的標識欄位會有另一個識別符號,僅當識別符號相同的IP資料報片才能組裝成一個IP資料報,前兩個IP資料報片的識別符號與后兩個IP資料報片的識別符號不同,因此不能組裝成一個IP資料報,
13.一個UDP用戶資料的資料欄位為8192位元組,在資料鏈路層要使用以太網來傳送,試問應當劃分為幾個IP資料報片?說明每一個IP資料報欄位長度和片偏移欄位的值,
答:UDP資料報 = 首部8位元組 + 資料部分組成,
因為資料欄位為8192位元組,所以資料報總長度 = 8192 + 8 = 8200 位元組,
以太網的最大傳輸單元MTU = 1500,
因為要劃分為幾個IP資料報,而每個IP資料報的首部占20位元組,所以欄位部分最大占1480位元組,
劃分的時候,可以劃分為 8200 / 1480 = 5,余 800 位元組,
所以應當劃分為 6 個IP資料報片,前 5 個都是 1480 位元組,第 6 個是 800 位元組,一個欄位即為8個位元組,
第一個IP資料報欄位長度:1480,第一片偏移欄位:1480 * 0 / 8 = 0
第二個IP資料報欄位長度:1480,第二片偏移欄位:1480 * 1 / 8 = 185
第三個IP資料報欄位長度:1480,第三片偏移欄位:1480 * 2 / 8 = 370
第四個IP資料報欄位長度:1480,第四片偏移欄位:1480 * 3 / 8 = 555
第五個IP資料報欄位長度:1480,第五片偏移欄位:1480 * 4 / 8 = 740
第六個IP資料報欄位長度:800, 第六片偏移欄位:1480 * 5 / 8 = 925
UDP資料報的首部存在于第一個IP資料報片中,所以第一個IP資料報欄位為:首部8位元組 + 1472資料部分,
14.一UDP用戶資料報的首部十六進制表示是:06 32 00 45 00 1C E2 17.試求源埠、目的埠、用戶資料報的總長度、資料部分長度,這個用戶資料報是從客戶發送給服務器還是服務器發送給客戶?使用UDP的這個服務器程式是什么?
解:源埠:1586(前4個位元組0632)
目的埠:69(00 45)
用戶資料報總長度:28 位元組(00 1C,其中首部占8位元組)
資料部分長度:20 位元組
這個用戶資料報是:從客戶發送給服務器
服務器程式:TFTP,
UDP資料報由首部欄位和資料欄位組成,其中首部占8個位元組(TCP資料報首部占20位元組),格式如下:
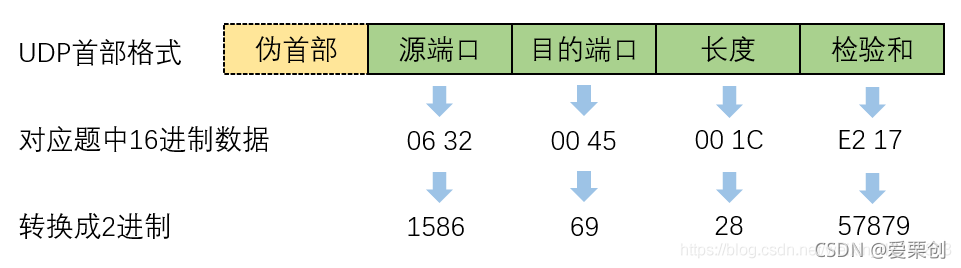
以上求出的長度為UDP資料報的總長度28位元組,由于UDP資料報的首部占8位元組,所以資料欄位長度占20位元組
因為目的埠號 69 < 1023,是常用的服務埠,所以這個資料報是發往服務器端的
0~1023:常用的服務埠
1024~49151是被注冊的埠,也成為“用戶埠”
其中 1024~5000為臨時埠
因為埠號為69,所以使用 UDP 的這個服務器程式是TFTP
TFTP:是TCP/IP協議族中的一個用來在客戶機與服務器之間進行簡單檔案傳輸的協議,提供不復雜、開銷不大的檔案傳輸服務,埠號為69,
15.使用TCP對實時話音資料的傳輸有沒有什么問題?使用UDP在傳送資料檔案時會有什么問題?
答:如果語音資料不是實時播放(邊接受邊播放)就可以使用TCP,因為TCP傳輸可靠,接收端用TCP講話音資料接受完畢后,可以在以后的任何時間進行播放,但假定是實時傳輸,則必須使用UDP, UDP不保證可靠付,但UCP比TCP的開銷要小很多,因此只要應用程式接受這樣的服務質量就可以使用UDP,
16.在停止等待協議中如果不使用編號是否可行?為什么?
答:不可行,分組和確認分組都必須進行編號,才能明確哪個分則得到了確認,
17.在停止等待協議中,如果收到重復的報文段時不予理睬(即悄悄地丟棄它而其他什么也沒做)是否可行?試舉出具體的例子說明理由,
答:可行,比如收到重復的報文段不確認相當于確認丟失,
18.假定在運輸層使用停止等待協議,發送發在發送報文段M0后再設定的時間內未收到確認,于是重傳M0,但M0又遲遲不能到達接收方,不久,發送方收到了遲到的對M0的確認,于是發送下一個報文段M1,不久就收到了對M1的確認,接著發送方發送新的報文段M0,但這個新的M0在傳送程序中丟失了,正巧,一開始就滯留在網路中的M0現在到達接收方,接收方無法分辨M0是舊的,于是收下M0,并發送確認,顯然,接收方后來收到的M0是重復的,協議失敗了,試畫出類似于圖5-9所示的雙方交換報文段的程序,
答: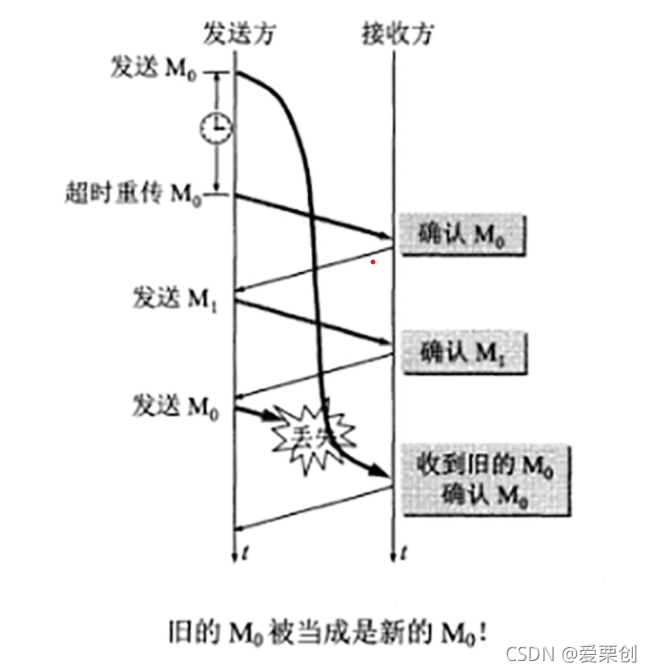
我們可以看出,舊的M0被當成是新的M0!可見運輸層不能使用停止等待協議(編號只有 0 和1 兩種),
19.試證明:當用 n 位元進行分組的編號時,若接收到視窗等于 1(即只能按序接收分組),當僅在發送視窗不超過
2
n
?
1
2^n-1
2n?1時,連接 ARQ 協議才能正確運行,視窗單位是分組,
答:
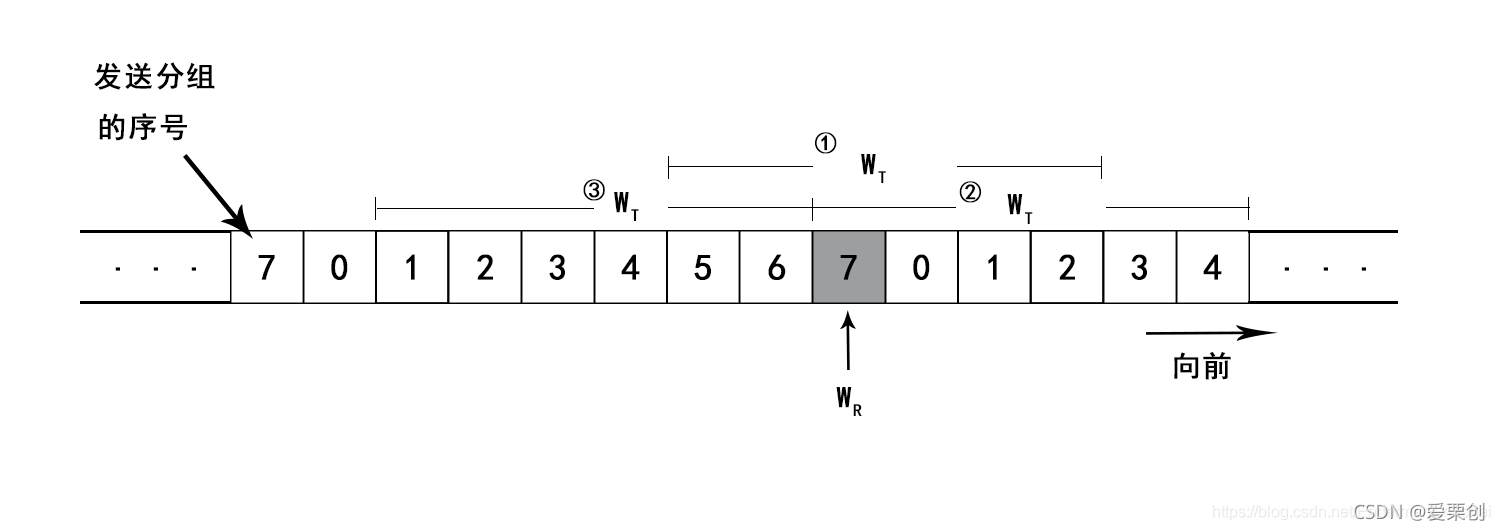
Ⅰ、設發送視窗記為 WT,接收視窗記為 WR,假定用 3 位元進行編號,設接收視窗正好在 7 號分組處(有陰影的分組),
Ⅱ、發送視窗 WT的位置不可能比 ② 的位置更靠前,因為接收視窗的位置表明接收方正在等待接收 7 號分組,而這時的發送方不可能已經收到了對 7 號分組的確認,因此發送視窗必須包括 7 號分組,也就是不可能比 ② 的位置更靠前(前方就是圖的右方),
Ⅲ、發送視窗 WT的位置不可能比 ③ 的位置更靠后,因為接收視窗的位置表明接收方已經對 6 號分組(以及以前的分組)發送了確認,但如果發送視窗 WT的位置再靠后一個分組,即在 6 號分組的左邊,那就表明還沒有發送 6 號分組,但接收方的位置表明接收方已經發送了對 6 號分組的確認,這顯然是不可能的,
Ⅳ、發送視窗 WT的位置可能在某個位置的中間,如 ①,
對于 ① 和 ② 的情況,在 WT的范圍內必須無重復序號,即 WT ?
2
n
2^n
2n,
對于 ③ 的情況,在 WT+ WR的范圍內無重復序號,即 WT + WR ?
2
n
2^n
2n,
現在 WR = 1,故發送視窗的最大值:WT ?
2
n
?
1
2^n ? 1
2n?1,
20.在連續 ARQ 協議中,若發送視窗等于 7,則發送端在開始時可連續發送 7 個分組,因此,在每一分組發送后,都要置一個超時計時器,現在計算機里只有一個硬時鐘,設這 7 個分組發出的時間分別為 t0,t1,…t6,且tout都一樣大,試問如何實作這 7 個超時計時器(這叫軟體時鐘法)?
答:
方法1:可采用鏈表記錄,其資訊域為分組的相對發送時間和分組編號來實作,當編號為 0 的分組定時時鐘到期后,修改鏈表指標并重發此分組,同時將頭指標指向編號為 1 的分組,以此類推,此類方法相當于資料結構演算法里的鏈表建立的程序,我有一篇C++的鏈表文章,可以參考,
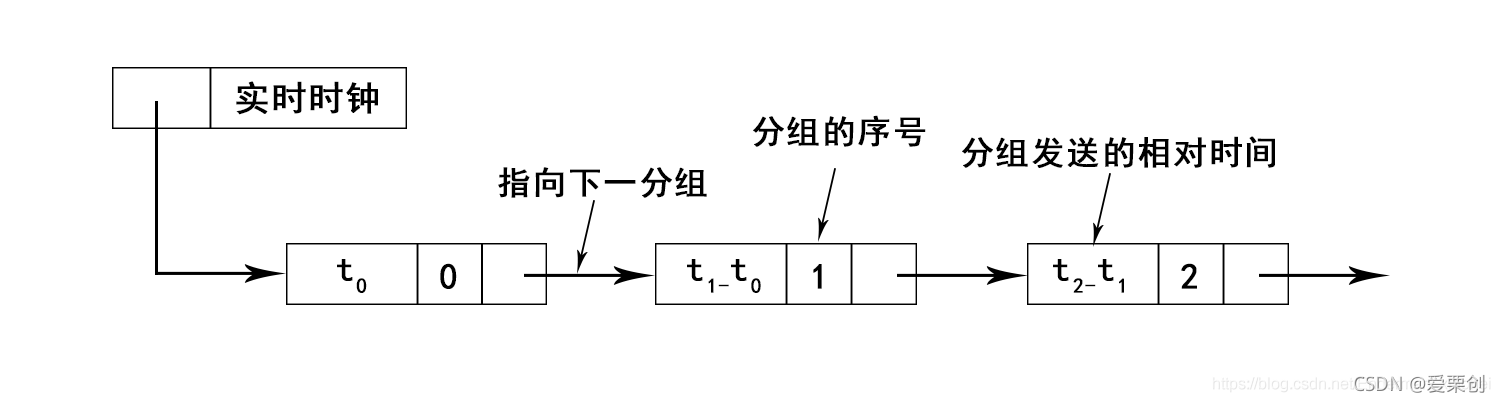
方法2:可以定義一個含有7個資料的陣列,陣列中的資料表示時間,當該組資料發送出去時,在對應序號的陣列中填入時間值,該時間值是該組發送出去的時間+超時時間得到,如何不停的對該陣列的值進行掃描,當接收到接收端的確認分組時,即將對應陣列序號的時間值設定為空,準備記錄下一個資料發發送時間,當系統時間大于陣列中某一個時間值時,說明該分組以及超時了,需要進行重傳,
21.使用連續 ARQ 協議中,發送視窗大小是 3,而序列范圍 [0, 15],而傳輸媒體保證在接收方能夠按序收到分組,在某時刻,接收方,下一個期望收到序號是 5,試問:
(1)在發送方的發送視窗中可能有出現的序號組合有哪幾種?
(2)接收方已經發送出去的、但在網路中(即還未到達發送方)的確認分組可能有哪些?說明這些確認分組是用來確認哪些序號的分組,
答:
(1)在接收方,下一個期望收到的序號是 5,這表明序號到 4 為止的分組都已收到,若這些確認都已到達發送方,則發送視窗最靠前,其范圍是 [5, 7],
假定所有的分組都丟失了,發送方都沒有收到這些確認,這時,發送視窗最靠后,應為 [2, 4],因此,發送視窗可以是 [2, 4],[3, 5],[4, 6],[5, 7] 中的任何一個,
(2)接收方期望收到的序號 5 的分組,說明序號為 2,3,4 的分組都已收到,并且發送了確認,對序號為 1 的分組的確認肯定被發送方收到了,否則發送方不可能發送 4 號分組,可見,對序號為 2,3,4 的分組的確認有可能仍滯留在網路中,這些確認是用來確認序號為 2,3,4 的分組的,
22.主機 A 向主機 B 發送一個很長的檔案,其長度為 L 位元組,假定 TCP 使用的 MSS 有 1460 位元組,
(1)在 TCP 的序號不重復使用的條件下,L 的最大值是多少?
(2)假定使用上面計算出檔案長度,而運輸層、網路層和資料鏈路層所使用的首部開銷共 66 位元組,鏈路的資料率為 10 Mb/s,試求這個檔案所需的最短發送時間
答:(1)可能的序號共
2
32
2^{32}
232=4294967296 個,TCP 的序號是資料欄位中每一個位元組的編號,而不是每一個報文段的編號,因此,這一小題與報文段的長度無關,即用不到題目給出的 MSS 值,這個檔案 L 的最大值就是可能的序號數,即 4294967296 位元組,若1GB=
2
30
2^{30}
230B,則 L 的最大值為 4 GB,
(2)發送幀數等于資料位元組/每幀的資料位元組=
2
32
2^{32}
232/1460=2941758.422,需要發送 2941759 個幀,
幀首部的開銷是 66×2941759 = 194156094 位元組,
發送的總位元組數 =
2
32
2^{32}
232 + 194156094 = 4489123390位元組,
資料率 10 Mbilt/s = 1.25 MB/s = 1250000 位元組/秒,
發送 4489123390 位元組需時間為:4489123390/1250000 =3591.3 秒,
即 59.85 分,約 1 小時,
23.主機 A 向主機 B 連續發送了兩個 TCP 報文段,其序號分別為 70 和 100,試問:
(1)第一個報文段攜帶了多少個位元組的資料?
(2)主機 B 收到第一個報文段后發回的確認中的確認號應當是多少?
(3)如果主機 B 收到第二個報文段后發回的確認中的確認號是 180,試問 A 發送的第二個報文段中的資料有多少位元組?
(4)如果 A 發送的第一個報文段丟失了,但第二個報文段到達了 B,B 在第二個報文段到達后向 A 發送確認,試問這個確認號應為多少?
答:
(1)第一個報文段的資料序號是 70 到 99,共 30 位元組的資料,
(2)B 期望收到下一個報文段的第一個資料位元組的序號為 100,因此確認號為 100,
(3)A 發送的第二個報文段中的資料中的位元組數是 180 - 100 = 80 位元組(實際上,就是序號 100 到序號 179 的位元組,即 179 - 100 + 1 = 80 位元組)
(4)B 在第二個報文段到達后向 A 發送確認,其確認號應為 70,(報文段丟失,就會重復發送確認上一個未收到的報文段第一個序號,即 70)
24.一個 TCP 連接下面使用 256 kb/s 的鏈路,其端到端時延為 128 ms,經測驗,發現吞吐量只有 120 kb/s,試問發送視窗 W 是多少?(提示:可以有兩種答案,取決于接收端發出確認的時機),
答:設發送視窗 = W(bit),再設發送端連續發送完視窗內的資料所需要的時間 = T,有兩種情況:
(a)接收端在收完一批資料的最后才發出確認,因此發送端經過 (256 ms + T) 后才能發送下一個視窗的資料,
(b)接收端每收到一個很小的報文段就發回確認,因此發送端經過比 256 ms 略多一些的時間即可在發送資料,因此每經過 256 ms 就能發送一個視窗的資料,
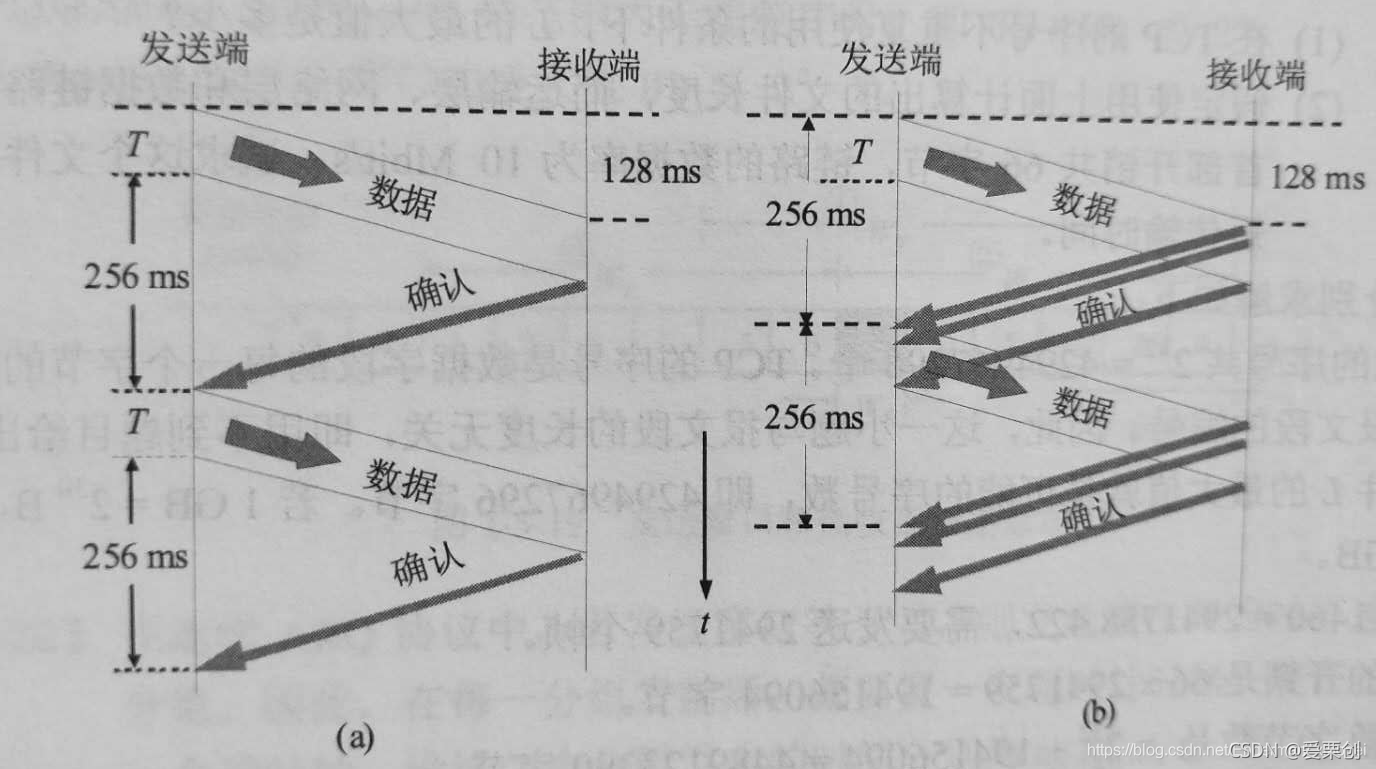
(a):吞吐量=資料量/時間
資料量=W;時間=發送時延+往返時延=W/256kbit/s+256ms;
吞吐量=W/[(W/256kbit/s)+256ms]=120kbit/s;
求得W=57825.88bit,約等于7228位元組,
(b):吞吐量=資料量/時間
資料量=W;時間=發送時延+往返時延=256ms(這里b是發送一點就確認接收一點,所以發送時延可以忽略不計,)
吞吐量=W/256ms=120kbit/s;
求得W=30720bit=3840位元組,
25.為什么在 TCP 首部中要把 TCP 埠號放入最開始的 4 個位元組?
答:在 ICMP 的差錯報文中要包含 IP 首部后面的8個位元組的內容,而這里面有 TCP 首部中的源埠和目的埠,當 TCP 收到 ICMP 差錯報文時需要用這兩個埠來確定是哪條連接出了差錯,
26.為什么在 TCP 首部中有一個首部長度欄位,而 UDP 的首部中就沒有這個這個欄位?
TCP 首部除固定長度部分外,還有選項,因此 TCP 首部長度是可變的,UDP 首部長度是固定的,
27.一個 TCP 報文段的資料部分最多為多少個位元組?為什么?如果用戶要傳送的資料的位元組長度超過 TCP 報文欄位中的序號欄位可能編出的最大序號,問還能否用 TCP 來傳送?
答:(1) 一個 TCP 那段的資料部分最多為 65495 位元組,此資料部分加上 TCP 首部的 20 位元組,再加上 IP 首部的 20 位元組,正好是 IP 資料報的最大長度 65535,(當然,若 IP 首部包含了選擇,則 IP 首部長度超過20位元組,這時 TCP 報文段的資料部分的長度將小于 65495 位元組,)
(2)如果資料的位元組長度超過 TCP 報文段中的序號欄位可能編出的最大序號,仍可用 TCP 傳送,編號用完后可重復使用,但應設法保證不出現編號的混亂,
IP 資料報的最大長度 =
2
1
6
2^16
216 ? 1 = 65535 位元組
TCP 報文段的資料部分 = IP 資料報的最大長度 - IP 資料報的首部 - TCP 報文段的首部 = 65535 - 20 - 20 = 65495 位元組
一個 TCP 報文段的最大載荷是 65515 位元組.
IP資料報的最大長度為
2
1
6
2^16
216 ? 1= 65535 位元組,減去 IP 資料報首部 20 位元組和 TCP 首部 20 位元組后的 TCP 報文段的資料部分為 65495 位元組,
28.主機 A 向主機 B 發送 TCP 報文段,首部中的源埠是 m 而目的埠是n,當 B 向 A 發送回信時,其 TCP 報文段的首部中源埠和目的埠分別是什么?
答:當 B 向 A 發送回信時,其 TCP 報文段的首部中得到源埠就是 A 發送的 TCP 報文段首部的目的埠 n,而 B 發送的 TCP 報文段首部中的目的埠就是 A 發送的 TCP 報文段首都的源埠 m,
29.在使用 TCP 傳送資料時,如果有一個確認報文段丟失了,也不一定會引起與該確認報文段對應的資料的重傳,試說明理由,
答:還未重傳就收到了對更高序號的確認,因為 TCP 接收方只會對按序到達的最后一個分組發送確認,當對更高的序號確認了,意味著已經到達了,即不用重傳了,
30.設 TCP 使用的最大視窗為 65535 位元組,而傳輸信道不產生差錯,帶寬也不受限制,若報文段的平均往返時延為 20 ms,問所能得到的最大吞吐量是多少?
解: 最大吞吐量那就是單位時間內的最大發送資料量,
即每20ms可以發送65535×8=524280bit,
吞吐量=524280bit/20ms=26.2Mb/s,
31.通信信道帶寬為 1 Gb/s,端到端時延為 10 ms,TCP 的發送視窗為 65535 位元組,試問:可能達到的最大吞吐量是多少?信道的利用率是多少?
解:吞吐量=發送資料/時間
發送資料最大=65535×8=524280bit,
時間=發送時延+往返時延=524280bit/(1Gbit/s)+20ms=20.524ms,
最大吞吐量=524280bit/20.524ms=25.5Mbit/s,
信道利用率=吞吐量/帶寬=(25.5Mbit/s)/(1Gbit/s)×100%=2.55%,
32.什么是 Karn 演算法?在 TCP 的重傳機制中,若不采用 Karn 演算法,而是在收到確認時都認為是對重傳報文段的確認,那么由此得出的往返時延樣本和重傳時間都會偏小,試問:重傳時間最后會減小到什么程度?
答:Karn 演算法允許 TCP 能夠區分開有效的和無效的往返時間樣本,從而改進往返時間的估算,
若不采用 Karn 演算法,而是在收到確認時都認為是對重傳報文段的確認,那么由此得出的往返時間樣本和重傳時間都會偏小,如下圖所示,TCP 發送了報文段后,沒有收到確認,于是超時重傳報文段,但剛剛重傳了報文段后,馬上就收到了確認,顯然,這個確認是對原來發送的報文段的確認,
但是,根據題意,我們就認為這個確認是對重傳的報文段的確認,這樣得出的往返時間就會很小,這樣的往返時間最后甚至可以減小到很接近于零、
因此,上述的這種做法是不可取的,
33.假定 TCP 在開始建立連接時,發送方設定超時重傳時間是RTO = 6秒,
(1)當發送方接到對方的連接確認報文段時,測量出 RTT 樣本值為1.5秒,試計算現在的RTO值,
(2)當發送方發送資料報文段并接收到確認時,測量出RTT樣本值為2.5秒,試計算現在的RTO值,
解:(1)當第一次測量RTT樣本時,RTTS就取值RTT樣本值為1.5s,RTTS=1.5s
根據RFC2988的建議,RTTD取值為RTT樣本值的一半,
RTTD=0.75s
根據公式可得:RTO=RTTS+4RTTD=1.5s+3s=4.5s
(2)新的RTT樣本為2.5s,(根據RFC6298推薦,α取1/8,β取1/4,)
即新的RTTS=(1-α)×(舊的RTTS)+α×(新的RTT樣本)=1.625s
新的RTTD=(1-β)×(舊的RTTD)+β×|RTTS-新的RTT樣本|=0.78s
根據公式:RTO=RTTS+4RTTD=1.625s+4×0.78s=4.75s
34.已知第一次測得 TCP 的往返時延的當前值 RTT 是 30 ms,現在收到了三個接連的確認報文段,它們比相應的資料報文段的發送時間分別滯后的時間是:26 ms,32 ms 和24 ms,設 α = 0.1,試計算每一次的新的加權平均往返時間值RTTS,討論所得出的結果,
解:公式:即新的RTTS=(1-α)×(舊的RTTS)+α×(新的RTT樣本)
第一次:RTTs=(1-0.1)×30ms+0.1×26ms=29.6ms
第二次:RTTS=(1-0.1)×29.6ms+0.1×32ms=29.86ms
第三次:RTTS=(1-0.1)×29.86ms+0.1×24ms=29.256ms
三次的加權平均時間相差不大,當RTT樣本值變化不大時,RTTs的變化也是很小的,
35.用TCP通過速率為1Gbit/s的鏈路傳送一個10MB的檔案,假定鏈路的往返時延RTT=50ms,TCP選用了視窗擴大選項,使視窗達到可選用的最大值,在接收端,TCP的接收視窗為1MB,而發送端采用擁塞控制演算法,從慢開始傳送,假定擁塞視窗以分組為單位計算,在一開始發送1個分組,而每個分組長度都是1KB.假定網路不會發生擁塞和分組丟失,并且發送端發送資料的速率足夠快,因此發送時延可以忽略不計,而接收端每一次收完一批分組后就立即發送確認ACK分組,
(1)經過多少個RTT后,發送視窗大小達到1MB?
(2)發送端把整個10MB檔案傳送成功共需要多少個RTT?傳送成功是指發送完整個檔案,并收到所有的確認,TCP擴大的視窗夠用么?
(3)根據整個檔案發送成功所花費的時間(包括收到所有的確認),計算此傳輸鏈路的有效吞吐率,鏈路帶寬的利用率是多少?
解:(1)根據擁塞演算法,就是每一次接收端發出確認時,發送埠就會增加為原來的2倍,則1MB=1024KB,那么就是
2
10
2^{10}
210KB=1MB,也就是來回十次就可以了,經過10個RTT,發送視窗大小達到1MB,

(2)從圖中可看出,當第10個RTT結束時,已傳送成功的分組是
2
10
?
1
2^{10}-1
210?1個分組,正好比1MB少一個分組,一個分組只有1KB,可先不考慮,可以這樣分析:在第10個RTT結束時,發送視窗為1MB,已傳送成功的資料量約為1MB(準確的是1MB-1 KB),因此在此基礎上,我們還需要再傳送9MB(實際上還需要再傳送9MB+ 1 KB),由于每經過一個RTT,發送視窗就加倍,因此在第11個RTT結束時,又成功發送了1MB,第12個RTT結束時,又成功發送了2MB,第13個RTT結束時,又成功發送了4MB,至此,一共又成功傳送了I+2+4=7MB,與9MB 相比還差2MB,因此還要經過一個RTT,在第14個RTT開始時把所有剩下的資料2MB(實際上是2MB+1KB)都發送完畢,這樣,全部10MB的資料成功發送完畢需要14個 RTT,
(3)吞吐率=資料量/時間
資料量=10MB=10×
2
20
2^{20}
220B=10×
2
20
2^{20}
220×8bit
時間=14×50ms=0.7s
有效吞吐率=10×
2
20
2^{20}
220×8bit/0.7s=119.8Mbit/s
帶寬利用率=吞吐量/帶寬
帶寬利用率=119.8Mbit/s/1Gbit/s×100%=11.98%
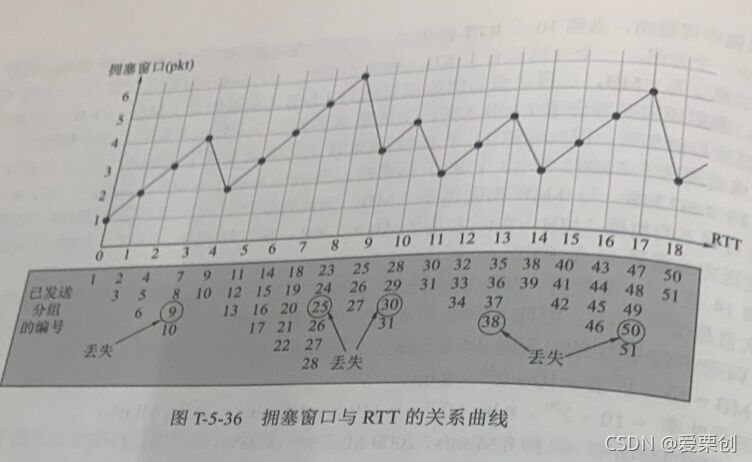
36.假定TCP采用一種僅使用線性增大和乘法減小的簡單擁塞控制演算法,而不使用慢開始,發送視窗不采用位元組為計算單位,而是使用分組pkt為計算單位,在一開始發送視窗為1pkt,假定分組的發送時延非常小,可以忽略不計,所有產生的時延就是傳播時延,假定發送視窗總是小于接收視窗,接收端每收到一分組后,就立即發回確認ACK,假定分組的編號為i,在一開始發送的是i=1的分組,以后當i=9,25,30,38,50時,發生了分組的丟失,再假定分組的超時重傳時間正好是下一個RTT開始的時間,試畫出擁塞視窗(也就是發送視窗)與RTT的關系曲線,畫到發送第51個分組為止,
答:開始時擁塞視窗(發送視窗)為1 pkt,發送編號為1的分組,
當RTT=1時(即第1個RTT結束時),收到確認,擁塞視窗增大到2 pkt,發送2個分組,其編號為2和3,
當RTT=2時(即第2個RTT結束時),收到確認,擁塞視窗增大到3 pkt,發送3個分組,其編號為4~~6,
當RTT=3時(即第3個RTT結束時),收到確認,擁塞視窗增大到4 pkt,發送4個分組,其編號為7~10,
但在RTT=4時(即第4個RTT結束時),發送端發現編號為9的分組丟失了,沒有收到相應的確認,于是這時把擁塞視窗減半,從前面的4減到2,請注意,擁塞視窗的值僅在RTT為整數值時才有意義,因為只有在這些時刻,確定了發送端能夠發送幾個分組,分組一旦發送出去,發送視窗就不再起作用,只有到了下一個RTT 結束時,發送視窗才再次起作用,
后面的分組發送,在圖中表示,就不再作過多的解釋了,但最后,在RTT=18時,由于編號為50的分組丟失,擁塞視窗應減半,從5 pkt減小到2.5 pkt,但分組組不能只發送半個,因此實際上擁塞視窗就是2,如果在圖中把擁塞視窗設定為2.5 pkt,那么在發送時也只能發送2個分組,因此在RTT -18時,發送的分組編號是50和51,
37.在 TCP 的擁塞控制中,什么是慢開始、擁塞避免、快重傳和快恢復演算法?這里每一種演算法各起什么作用? “乘法減小”和“加法增大”各用在什么情況下?
答:
① 慢開始:
在主機剛剛開始發送報文段時可先將擁塞視窗 cwnd 設定為一個最大報文段 MSS 的數值,在每收到一個對新的報文段的確認后,將擁塞視窗增加至多一個 MSS 的數值,用這樣的方法逐步增大發送端的擁塞視窗 cwnd,可以分組注入到網路的速率更加合理,
② 擁塞避免:
當擁塞視窗值大于慢開始門限時,停止使用慢開始演算法而改用擁塞避免演算法,擁塞避免演算法使發送的擁塞視窗每經過一個往返時延 RTT 就增加一個 MSS 的大小,
③ 快重傳演算法規定:
發送端只要一連收到三個重復的 ACK 即可斷定有分組丟失了,就應該立即重傳丟手的報文段而不必繼續等待為該報文段設定的重傳計時器的超時,
④ 快恢復演算法:
當發送端收到連續三個重復的 ACK 時,就重新設定慢開始門限 ssthresh 與慢開始不同之處是擁塞視窗 cwnd 不是設定為 1,而是設定為 ssthresh 若收到的重復的 ACK 為 n 個(n>3),則將 cwnd 設定為 ssthresh 若發送視窗值還容許發送報文段,就按擁塞避免演算法繼續發送報文段,若收到了確認新的報文段的 ACK,就將 cwnd 縮小到 ssthresh,
⑤ 乘法減小:
是指不論在慢開始階段還是擁塞避免階段,只要出現一次超時(即出現一次網路擁塞),就把慢開始門限值 ssthresh 設定為當前的擁塞視窗值乘以 0.5,當網路頻繁出現擁塞時,ssthresh 值就下降得很快,以大大減少注入到網路中的分組數,
⑥ 加法增大:
是指執行擁塞避免演算法后,在收到對所有報文段的確認后(即經過一個往返時間),就把擁塞視窗 cwnd 增加一個 MSS 大小,使擁塞視窗緩慢增大,以防止網路過早出現擁塞,
38.設 TCP 的 ssthresh 的初始值為 8 (單位為報文段),當擁塞視窗上升到 12 時網路發生了超時,TCP 使用慢開始和擁塞避免,試分別求出第 1 次到第 15 次傳輸的各擁塞視窗大小,你能說明擁塞控制視窗每一次變化的原因嗎?
答:擁塞視窗大小及變化原因見下表:
| 輪次 | 擁塞視窗 | 擁塞視窗變化的原因 |
|---|---|---|
| 1 | 1 | 網路發生了超時,TCP 使用慢開始演算法 |
| 2 | 2 | 擁塞視窗值加倍 |
| 3 | 4 | 擁塞視窗值加倍 |
| 4 | 8 | 擁塞視窗值加倍,這是 ssthresh 的初始值 |
| 5 | 9 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 6 | 10 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 7 | 11 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 8 | 12 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 9 | 1 | 網路發生了超時,TCP 使用慢開始演算法 |
| 10 | 2 | 擁塞視窗值加倍 |
| 11 | 4 | 擁塞視窗值加倍 |
| 12 | 6 | 擁塞視窗值加倍,但到達 12 的一半時,改為擁塞避免演算法 |
| 13 | 7 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 14 | 8 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
| 15 | 9 | TCP 使用擁塞避免演算法,擁塞視窗值加 1 |
注:依照原理,首先執行 TCP 連接初始化,將擁塞視窗 cwnd 值置為 1;其次執行慢開始演算法,cwnd 按指數規律增長,因此隨后視窗大小分別為 2,4,8,當擁塞視窗 cwnd = ssthresh 時,進入擁塞避免階段,其視窗大小依次是 9,10,11,12,直到上升到 12 為止發生擁塞;然后把門限值 ssthresh 設定為當前的擁塞視窗值乘以 0.5,門限值 ssthresh 變為6,;然后進入慢開始,cwnd 值置為1,cwnd 按指數規律增長,隨后視窗大小分別為 1,2,4,6,當擁塞視窗 cwnd = ssthresh 時,進入擁塞避免階段,其視窗大小依次是 7,8,9,
39.TCP 的擁塞視窗 cwnd 大小與傳輸輪次 n 的關系如表所示:

(1)試畫出如教材中圖 5-25 所示的擁塞視窗與傳輸輪次的關系曲線,
(2)指明 TCP 作業在慢開始階段的時間間隔,
(3)指明 TCP 作業在擁塞避免階段的時間間隔,
(4)在第 16 輪次和第 22 輪次之后發送方是通過收到三個重復的確認還是通過超時檢測到丟失了報文段?
(5)在第 1 輪次,第 18 輪次和第 24 輪次發送時,門限 ssthresh 分別被設定為多大?
(6)在第幾輪次發送出第 70 個報文段?
(7)假定在第 26 輪次之后收到了三個重復的確認,因而檢測出了報文段的丟失,那么擁塞視窗 cwnd 和門限 ssthresh 應設定為多大?
答:(1)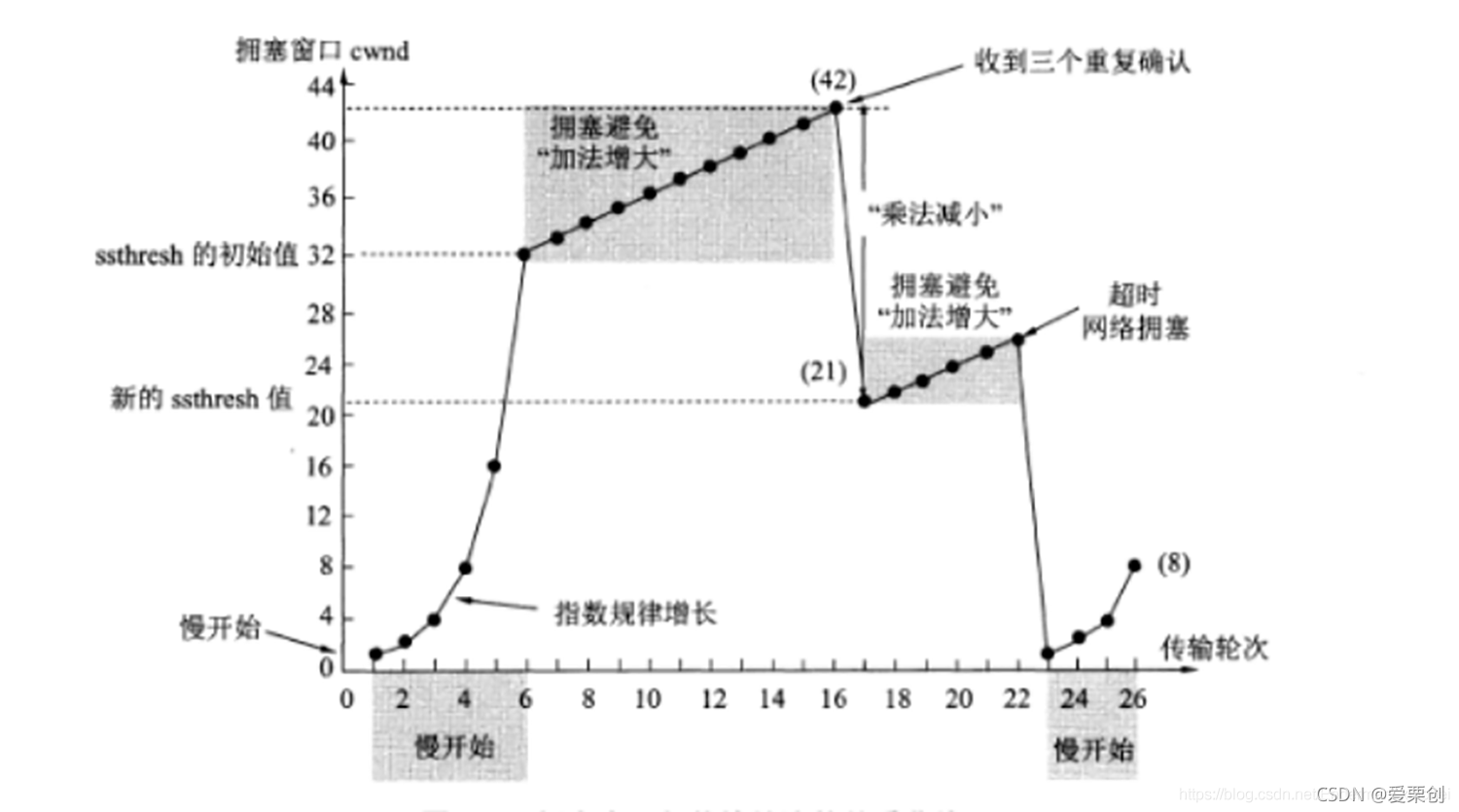
(2)慢開始時間間隔:[1, 6] 和 [23, 26]
(3)擁塞避免時間間隔:[6, 16] 和 [17, 22]
(4)在第 16 輪次之后發送方通過收到三個重復的確認,檢測到丟失了報文段,因為題目給出,下一個輪次的擁塞視窗減半了,在第 22 輪次之后發送方通過超時,檢測到丟失了報文段,因為題目給出,下一個輪次的擁塞視窗下降到 1了,
(5)在第 1 輪次發送時,門限 ssthresh 被設定為 32,因為從第 6 輪次起就進入了擁塞避免狀態,擁塞視窗每個輪次加 1,
在第 18 輪次發送時,門限 ssthresh 被設定為發生擁塞時擁塞視窗 42 的一半,即 21,
在第 24 輪次發送時,門限 ssthresh 被設定為發生擁塞時擁塞視窗 26 的一半,即 13,
(6)第 1 輪次發送報文段 1,(cwnd = 1)
第 2 輪次發送報文段 2, 3,(cwnd = 2)
第 3 輪次發送報文段 4 ~ 7,(cwnd = 4)
第 4 輪次發送報文段 8 ~ 15,(cwnd = 8)
第 5 輪次發送報文段 16 ~ 31,(cwnd = 16)
第 6 輪次發送報文段 32 ~ 63,(cwnd = 32)
第 7 輪次發送報文段 64 ~ 96,(cwnd = 33)
因此第 70 報文段在第 7 輪次發送出,
(7)檢測出了報文段的丟失時擁塞視窗 cwnd 是 8,因此擁塞視窗 cwnd 的數值應當減半,等于 4,而門限 ssthresh 應設定為檢測出報文段丟失時的擁塞視窗 8 的一半,即 4,
40.TCP 在進行流量控制時是以分組的丟失作為產生擁塞的標志,有沒有不是因擁塞而引起的分組丟失的情況?如有,請舉出三種情況,
答:不是因為擁塞而引起分組丟失的情況是有的,舉例如下:
① 當 IP 資料報在傳輸程序中需要分片,但其中一個資料報片未能及時到達終點,而終點組裝 IP 資料報已超時,因而只能丟棄該資料報,
② IP 資料報已經到達終點,但終點的快取沒有足夠的空間存放此資料報,
③ 資料報在轉發程序中經過一個局域網的網橋,但網橋在轉發該資料報的幀時沒有足夠的儲存空間而只好丟棄,
41.用 TCP 傳送 512 位元組的資料,設視窗為 100 位元組,而 TCP 報文段每次也是傳送 100 位元組的資料,再設發送端和接收端的起始序號分別選為 100 和 200,試畫出類似于教材中圖 5-31 的作業示意圖,從連接建立階段到連接釋放都要畫上,
要傳送的 512 B 的資料必須劃分為 6 個報文段傳送,前 5 個報文段各 100 B,最后一個報文段傳送 12 B,下圖是雙方互動的示意圖,下面進行簡單的解釋,
【----- 進行三報文握手 -----】
報文段 #1:A 發起主動打開,發送 SYN 報文段,除以 SYN-SENT 狀態,并選擇初始序號 seq = 100,B 處于 LISTEN 狀態,
報文段 #2:B 確認 A 的 SYN 報文段,因此 ack = 101(是 A 的初始序號加 1),B選擇初始序號 seq = 200,B 進入到 SYN-RCVD 狀態,
報文段 #3:A 發送 ACk 報文段來確認報文段 #2,ack = 201(是 B 的初始序號加 1),A 沒有在這個報文段中放入資料,因為 SYN 報文段 #1 消耗了一個序號,因此報文段 #3 的序號是 seq = 101,這樣,A 和 B 都進入了 ESTABLISHED 狀態,
【----- 三報文握手完成 -----】
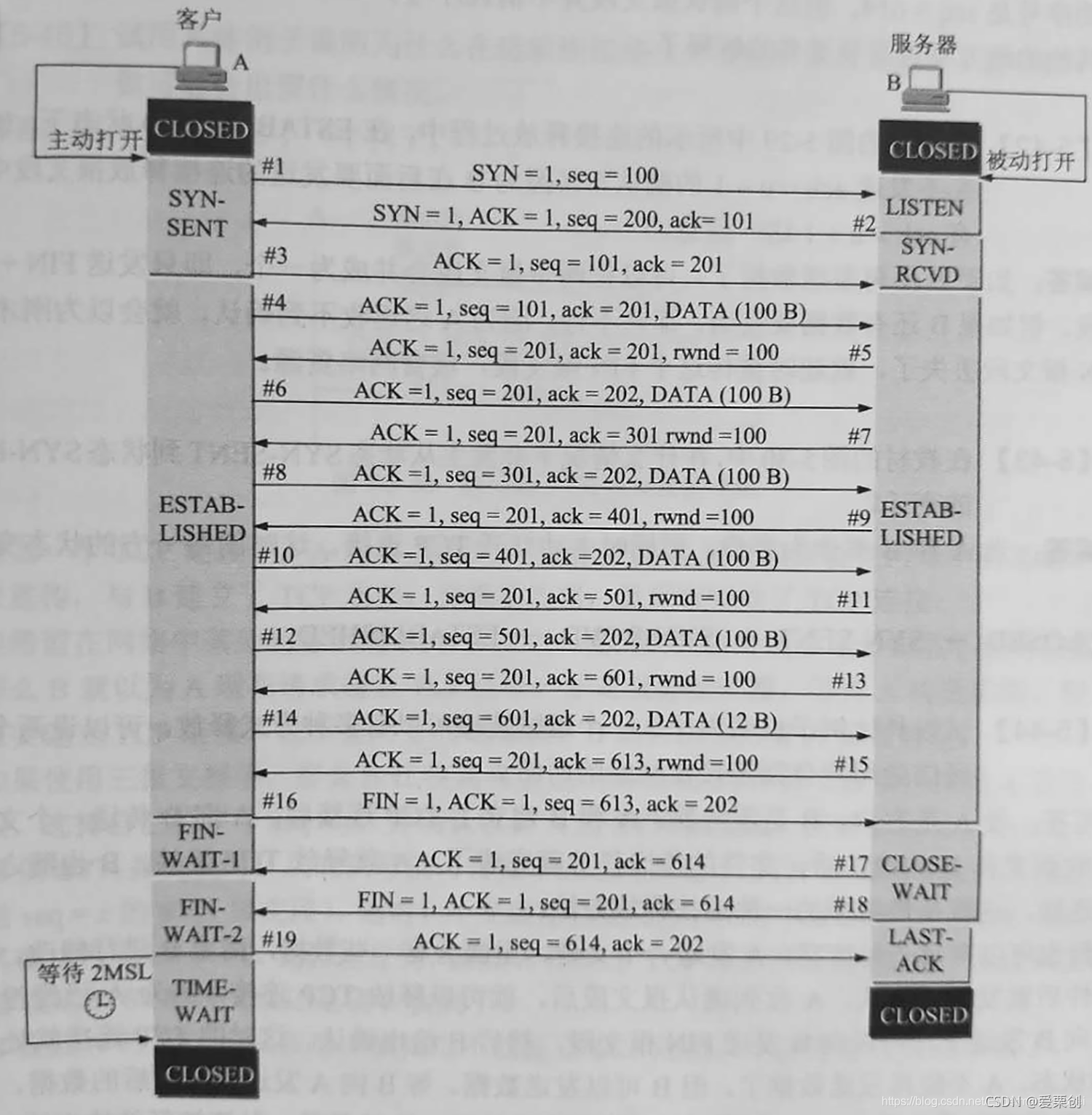
【----- 開始資料傳送 -----】
報文段 #4:A 發送 100 位元組的資料,報文段 #3 是確認報文段,沒有資料發送,報文段 #3 并不消耗序號,因此報文段 #4 的序號仍然是 seq = 101,A 在發送資料的同時,還確認 B 的報文段 #2,因此 ack = 201,
報文段 #5:B 確認 A 的報文段 #4,由于收到了從序號 101 到 200 共 100 位元組的資料,因此在報文段 #5 中,ack = 201(所期望收到的下一個資料位元組的序號),B 發送的 SYN 報文段 #2 消耗了一個序號,因此報文段 #5 的序號是 seq = 201,比報文段 #2 的序號多了一個序號,在這個報文段中,B 給出了接收視窗 rwnd = 100,
從報文段 #6 到報文段 # 13 都不需要更多的解釋,到此為止,A 已經發送了 500 位元組 的資料,值得注意的是,B 發送的所有確認報文都不消耗序號,其序號都是 seq = 201,
報文段 #14:A 發送最后 12 位元組的資料,報文段 #14 的序號是 seq = 601,
報文段 #15:B 發送對報文段 #14 的確認,B 收到從序號 601 到 602 共 12 位元組的資料,因此,報文段 #15 的確認號是 ack = 613(所期望收到的下一個資料位元組的序號),
需要注意的是,從報文段 #5 一直到 報文段 #15,B 一共發送了 6 個確認,都不消耗序號,因此 B 發送的報文段 #15 的序號仍然和報文段 #5 的序號一樣,即 seq = 201,
【-----資料傳送完畢-----】
【-----進行四報文揮手------】
報文段 #16:A 發送 FIN 報文段,前面所發送的資料報文段 #14 已經用掉了序號 601 到 612,因此報文段 #16 序號是 seq = 613,A 進入 FIN-WAIT-1 狀態,報文段 #16 的確認號 ack = 202,
報文段 #17:B發送確認報文段,確認號為 614,進入 CLOSE-WAIT 狀態,由于確認報文段不消耗序號,因此報文段 #17 的序號仍然和報文段 #15 的一樣,即 seq = 201
報文段 #18:B 沒有資料要發送,就發送 FIN 報文段 #18,其序號仍然是 seq = 201,這個 FIN 報文會消耗一個報文,
報文段 #19:A 發送最后的確認報文段,報文段 #16 的序號是 613,已經消耗掉了,因此,現在的序號是 seq = 614,但這個確認報文段并不消耗序號,
【-----四報文揮手結束-----】
42.在圖 5-29 中所示的連接釋放程序中,主機 B 能否先不發送 ACK = x + 1 的確認?(因為后面要發送的連接釋放報文段中仍有 ACK = x + 1 這一資訊)
答: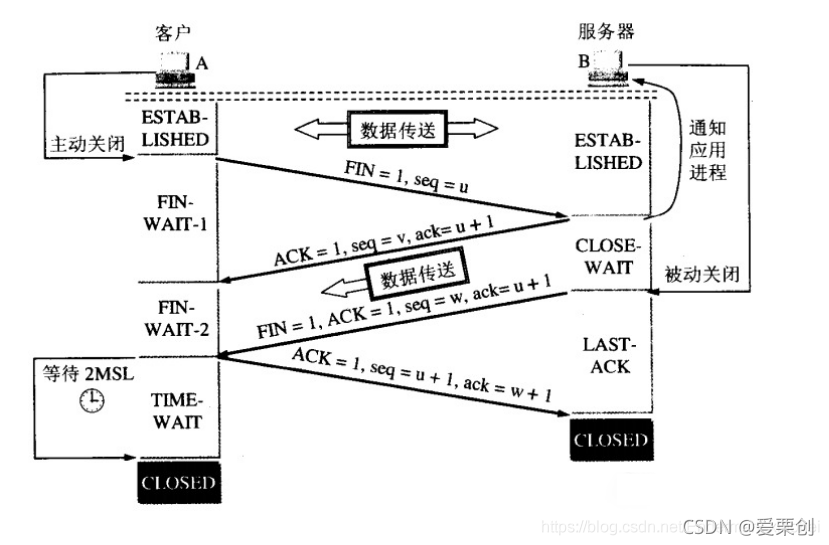
如果 B 不再發送資料了,是可以把兩個報文段合并成為一個,即只發送 FIN+ACK 報文段,但如果 B 還有資料報要發送,而且要發送一段時間,那就不行,因為 A 遲遲收不到確認,就會以為剛才發送的 FIN 報文段丟失了,就超時重傳這個 FIN 報文段,浪費網路資源,
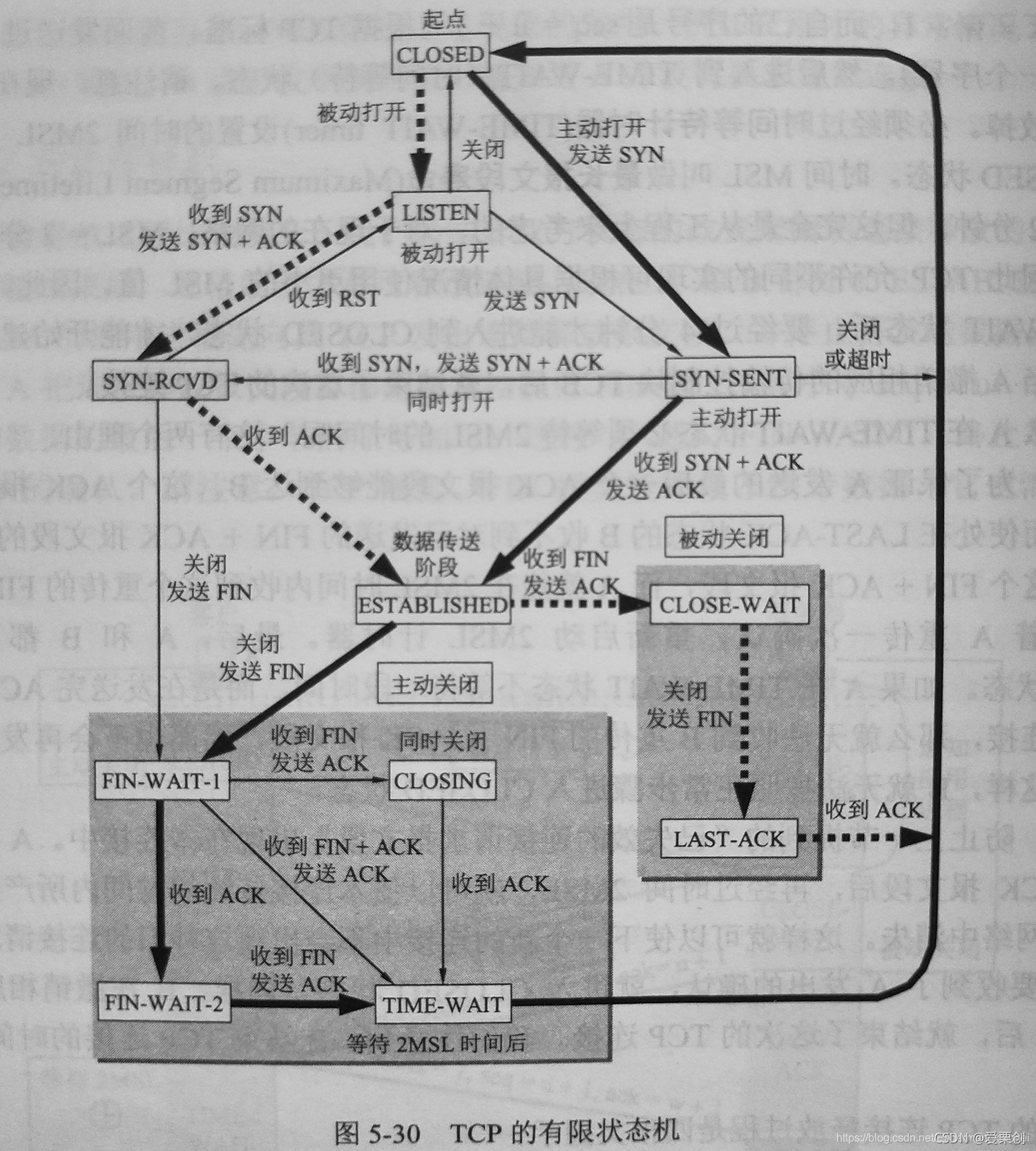
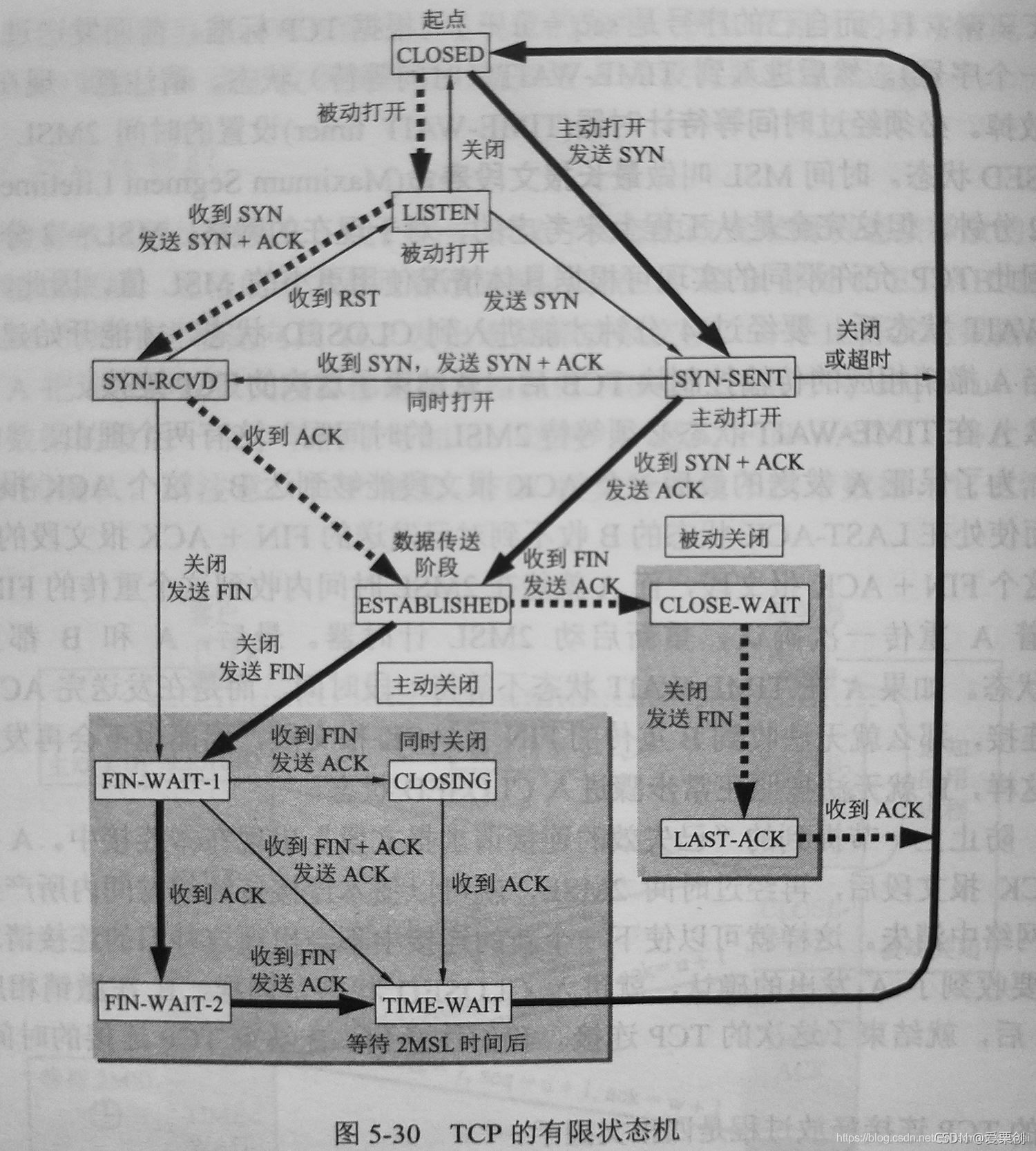
43.在圖 5-30 中,在什么情況下會發生從狀態 SYN-SENT 到狀態 SYN-RCVD 的變遷?
答:
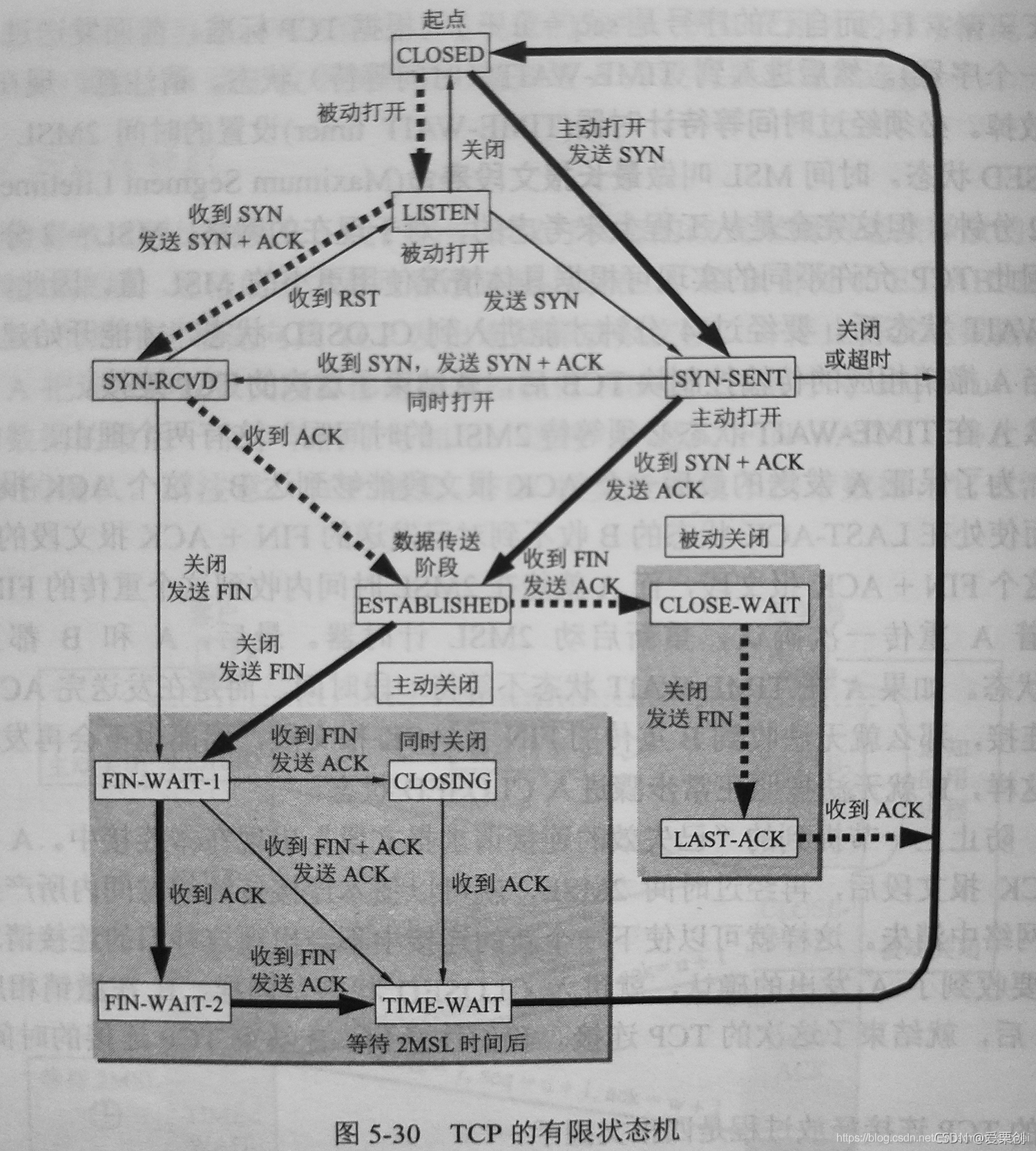
當 A 和 B 都作為客戶,即同時主動打開 TCP 連接,這時的每一方的狀態變遷都是:
CLOSED -> SYN-SENT -> SYN-RCVD -> ESTABLISHED
44.試以具體例子說明為什么一個運輸連接可以有多種方式釋放,可以設兩個互相通信的用戶分別連接在網路的兩結點上,
答:設 A,B建立了運輸連接,
協議應考慮一下實際可能性: A 或 B 故障,應設計超時機制,使對方退出,不至于死鎖;
A主動退出,B被動退出
B主動退出,A被動退出
45.解釋為什么突然釋放運輸連接就可能會丟失用戶資料,而使用 TCP 的連接釋放方法就可保證不丟失資料,
答:當主機 1 和主機 2 之間連接建立后,主機 1 發送了一個 TCP 資料段并正確抵達主機 2,接著主機 1 發送另一個TCP資料段,這次很不幸,主機 2 在收到第二個 TCP 資料段之前發出了釋放連接請求,如果就這樣突然釋放連接,顯然主機 1 發送的第二個 TCP 報文段會丟失,
而使用 TCP 的連接釋放方法,主機 2 發出了釋放連接的請求,那么即使收到主機 1 的確認后,只會釋放主機 2 到主機 1 方向的連接,即主機 2 不再向主機 1 發送資料,而仍然可接收主機 1 發來的資料,所以可保證不丟失資料,
46.試用具體例子說明為什么在運輸連接建立時要使用三次握手,說明如不這樣做可能會出現什么情況,
答:3 次握手完成兩個重要的功能,既要雙方做好發送資料的準備作業(雙方都知道彼此已準備好),也要允許雙方就初始序列號進行協商,這個序列號在握手程序中被發送和確認,
假定 B 給 A 發送一個連接請求分組,A 收到了這個分組,并發送了確認應答分組,按照兩次握手的協定,A 認為連接已經成功地建立了,可以開始發送資料分組,可是,B 在 A 的應答分組在傳輸中被丟失的情況下,將不知道 A 是否已準備好,不知道 A 建議什么樣的序列號,B 甚至懷疑 A 是否收到自己的連接請求分組,在這種情況下,B 認為連接還未建立成功,將忽略 A 發來的任何資料分組,只等待連接確認應答分組,而 A 發出的分組超時后,重復發送同樣的分組,這樣就形成了死鎖,
47.一個客戶向服務器請求建立 TCP 連接,客戶在 TCP 連接建立的三次握手中的最后一個報文段中捎帶上一些資料,請求服務器發送一個長度為 L 位元組的檔案,假定:
(1)客戶和服務器之間的資料傳輸速率是 R 位元組/秒,客戶與服務器之間的往返時間是 RTT(固定值),
(2)服務器發送的 TCP 報文段的長度都是 M 位元組,而發送視窗大小是 nM 位元組,
(3)所有傳送的報文段都不會出錯(無重傳),客戶收到服務器發來的報文段后就及時發送確認,
(4)所有的協議首部開銷都可忽略,所有確認報文段和連接建立階段的報文段的長度都可忽略(即忽略這些報文段的發送時間),
試證明,從客戶開始發起連接建立到接收服務器發送的整個檔案多需的時間 T 是:T = 2RTT + L/R,當 nM > R(RTT) + M
或 T= 2RTT + L/R + (K - 1)[ M/R + RTT - nM/R],當 nM < R(RTT) + M
其中,K=『L/nM』,符號『x』表示若 x 不是整數,則把 x 的整數部分加 1,
(提示:求證的第一個等式發生在發送視窗較大的情況,可以連續把檔案發送完,求證的第二個等式發生在發送視窗較小的情況,發送幾個報文段后就必須停頓下來,等收到確認后再繼續發送,建議先畫出雙方互動的時間圖,然后再進行推導,)
答:
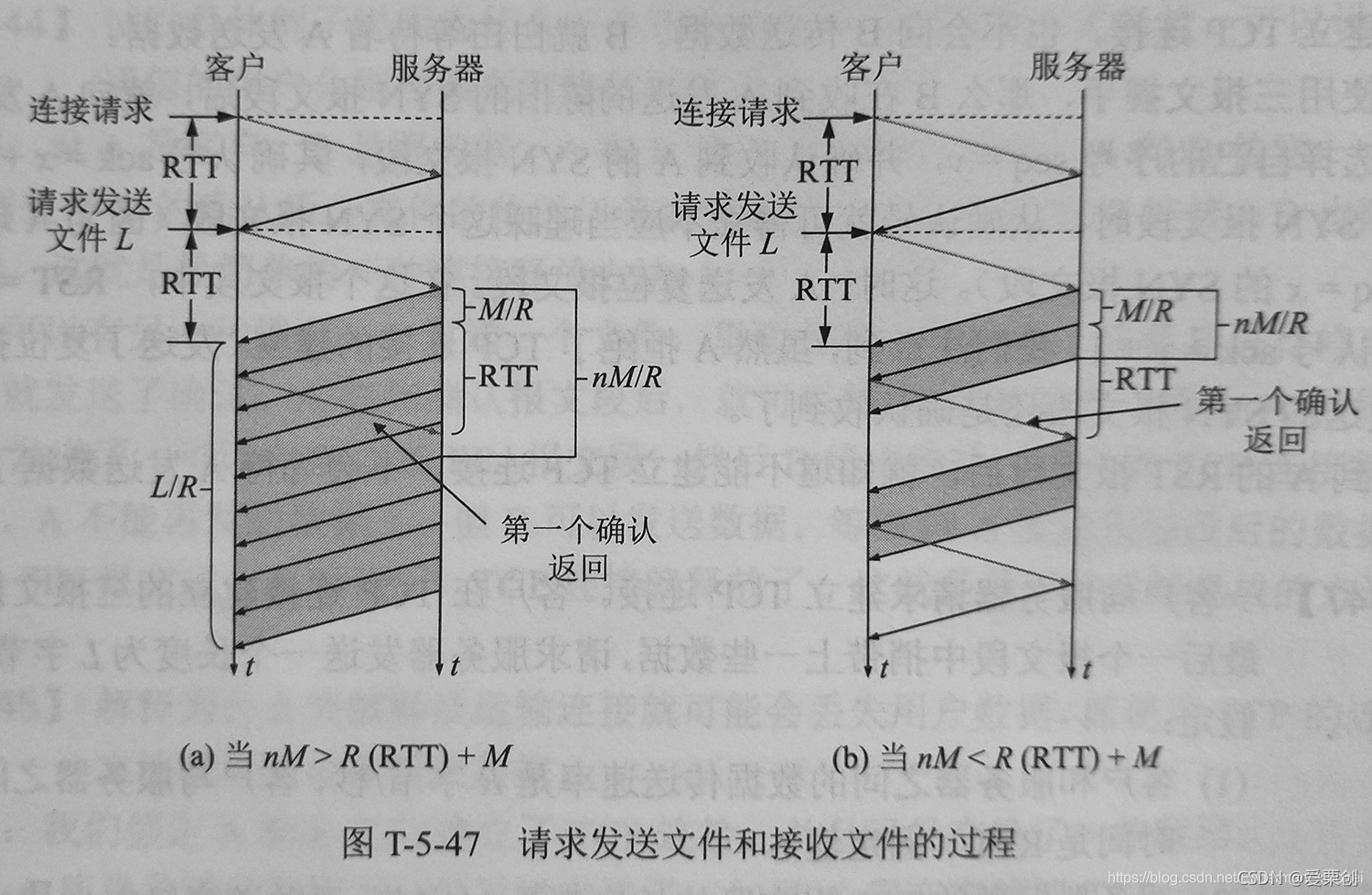
先看圖(a):
M/R 是一個報文段的發送時間(一個報文段的長度除以資料率)
nM 是視窗大小,nM/R 是把視窗內的資料都發送完所需要的時間,
如果 nM/R > M/R + RTT ,那么服務器在發送視窗內的資料還沒有發送完,就收到客戶的確認,因此,服務器可以連續發送,直到全部資料發送完畢,
這個不等式兩邊都乘以 R,就得出等效的條件:
當 nM > R(RTT) + M 發送視窗內的資料還沒有發送完就收到確認,因此,服務器可以連續發送,直到全部資料發送完畢,
因此,客戶接收全部資料所需的時間是:
T = 2RTT + L/R,當 nM > R(RTT) +
再看圖(b):
當 nM > R(RTT) + M 時,服務器把發送視窗內的資料發送完畢時還收不到確認,因此必須停止發送,從圖中可知,停止的時間間隔是 M/R + RTT - nM/R,
整個檔案 L 要劃分為 K =『L/nM』次傳送,停止的時間間隔有(K-1)個,這樣就證明了求證的公式:
T = 2RTT + L/R + (K-1)[M/R + RTT - nM/R],當 nM < R(RTT) + M
48.網路允許的最大報文段長度為 128 位元組,序號用 8 位元表示,報文段在網路中的壽命為 30 s,求發送報文段的一方所能達到的最高資料率,
解:根據題意,先可以做出以下一些假設:
(1)本題不是使用 TCP 協議,因為序號欄位是 8 位,而不是 TCP 的 32 位,
(2)既然不是使用 TCP 協議,當然也不是使用 TCP 協議得到首部,現在的報文段的首部是什么樣子,和我們解題沒有關系,我們不用管它,我們只需要知道的是,現在的報文段的首部有一個序號欄位,
(3)顯然,現在不是給報文中的每一個位元組編上序號,而是給每一個報文編上序號,
(4)報文段的傳送應當使用滑動視窗協議(而不是停止等待協議),這樣可得到較高的效率,
我們知道,在使用滑動視窗協議時,在沒有收到確認的情況下,8 位的序號欄位可連續發送 255 個序號(
2
n
?
1
2^n-1
2n?1)的報文段,
那么一共可以發送的位元數為255×128×8=261120bit
資料率=位元數/時間
最高資料率=261120bit/30s=8704bit/s
49.下面是以十六進制格式存盤的一個 UDP 首部:
CB84000D001C001C
試問:
(1) 源埠號是什么?
(2) 目的埠號是什么?
(3) 這個用戶資料報的總長度是什么?
(4) 資料長度是多少?
(5)這個分組是從客戶到服務器還是從服務器到客戶?
(6) 客戶行程是什么?
答:(1)源埠號是最前面的四位十六進制數(CB84)16=(52100)10
(2)目的埠號是五到八位的十六進制數(000D)16=(13)10
(3)用戶資料報的長度由九到十二位十六進制數決定(001C)16=(28)10位元組,
(4)資料長度=資料報長度-首部長度=28位元組-8位元組=20位元組,
(5)因為目的埠是 13 (熟知埠),所以這個分組是從客戶到目的埠,
(6)從 RFC 867 可以得知,這個客戶行程是 Daytime,當 Daytime 服務器收到客戶發送的 UDP 用戶資料報后,就把現在的日期和時間以 ASCII 碼字串的形式回傳給客戶,
50.把教材上的圖 5-7 計算 UDP 檢驗和的例子自己具體演算一下,看是否能夠得出書上的計算結果,
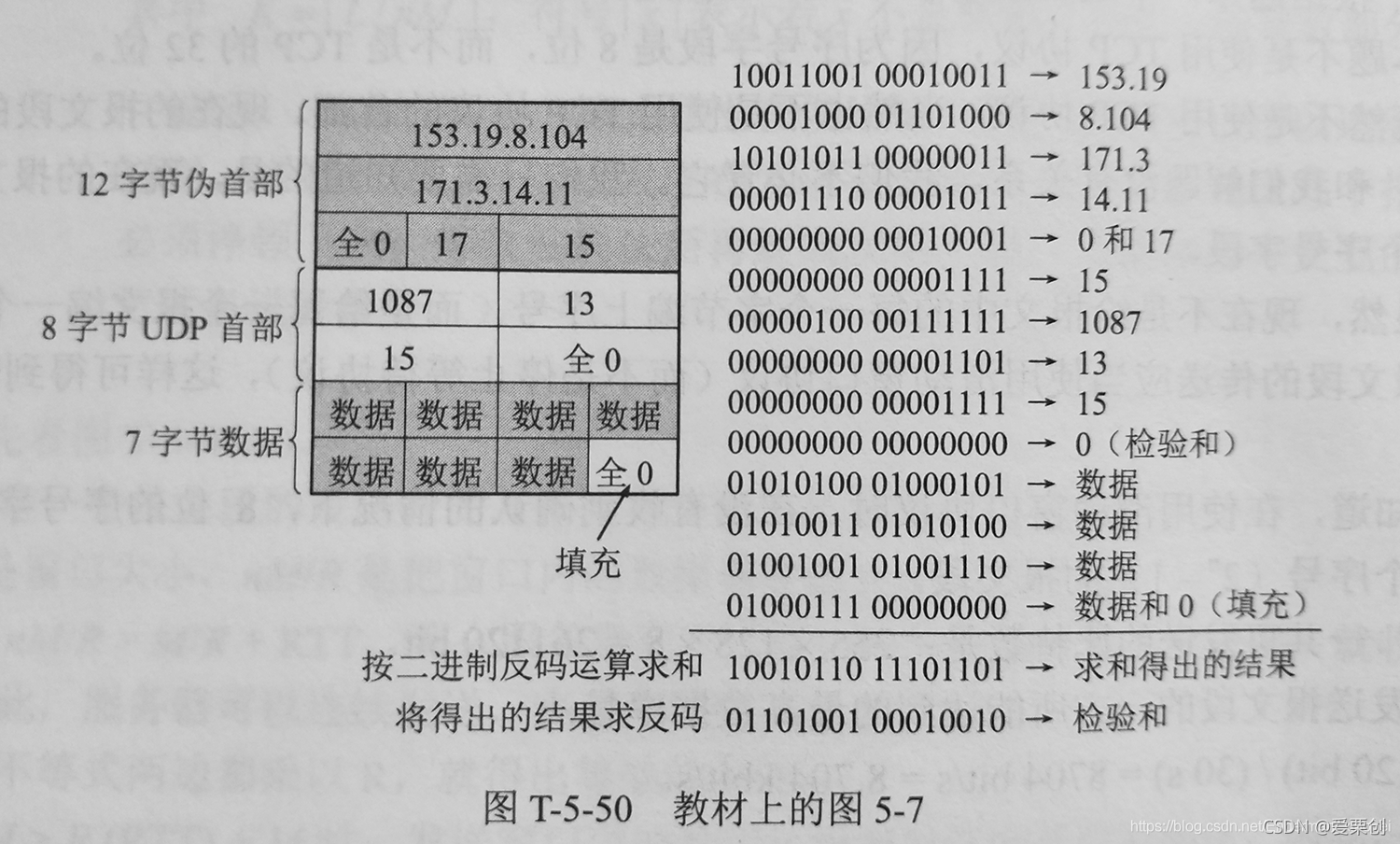 可以使用兩種方法進行二進制反碼求和的運算,一種方法是把這 14 行的 16 位資料一起從低位到高位逐位相加,另一種方法是把這 14 行的 16 位資料兩行兩行地相加(即二進制反碼求和)
可以使用兩種方法進行二進制反碼求和的運算,一種方法是把這 14 行的 16 位資料一起從低位到高位逐位相加,另一種方法是把這 14 行的 16 位資料兩行兩行地相加(即二進制反碼求和)
我們這里使用后一種方法,這里要相加 13 次,
第 1 行和 第 2 行相加,得 10100001 01111011
再和第 3 行相加,得 1 01001100 011111110,請注意,最左邊(最高位)的 1 是進位得到的 1,這要和最低位相加,因此和第 3 行相加后,得 01001100 01111111,最低位的 1 就是由最高位的進位得到的,這叫做 “回卷”,
再和第 4 行相加,得 01011010 10001010,
再和第 5 行相加,得 01011010 10011011,
再和第 6 行相加,得 01011010 10101010,
再和第 7 行相加,得 01011110 11101001,
再和第 8 行相加,得 01011110 11110110,
再和第 9 行相加,得 01011111 00000101,
第 10 行是全 0,不用再計算相加,
再和第 11 行相加,得 10110011 01001010,
再和第 12 行相加,得 00000110 10011111,這里的最低位的 1 由最高位的進位回卷得到的,
再和第 13 行相加,得 01001111 11101101,
再和第 14 行相加,得 10010110 11101101,這就是二進制反碼求和的結果,把這個結果求反碼(1 換成 0 而 0 換成 1),得出:01101001 00010010,這就是應當寫在檢驗和欄位的數,和書上給出的結果是一致的,
UDP 用戶資料報傳送到接收端后,再進行檢驗和計算,這就是把收到的 UDP 用戶資料報連同偽首部(以及可能的填充全零位元組)一起,按二進制反碼求這些 16 位字的和,當無差錯時其結果應當全 1,否則就表明有差錯出現,接收方就應丟棄這個 UDP 用戶資料報(也可以上交應用層,但附上出現差錯的警告),
51.在以下幾種情況下,UDP 的檢驗和在發送時數值分別是多少?
(1)發送方決定不使用檢驗和,
(2)發送方使用檢驗和,檢驗和的數值是全 1,
(3)發送方使用檢驗和,檢驗和的數值是全 0,
答:(1)UDP 規定,UDP 的上層用戶可以關閉檢驗和的計算(即在 UDP 的傳送程序中,不使用檢驗和這個檢錯功能),這樣做的好處是可以提高 UDP 的傳送速度(但要犧牲一些可靠性),如果發送方決定不使用檢驗和,那么發送方的檢驗和的值應當置為全 0,這表示這個數值不是計算出來的,而是發送方關閉了檢驗和這個功能,
(2)如果發送方使用檢驗和,但檢驗和的數值是全 1,
我們可以想一想,怎么會出現這種情況,如果計算檢驗和最后的結果是全 1,就表明得出這個結果的前一個步驟(即二進制反碼求和)的結果是全 0,在什么情況下,偽首部和整個 UDP 按 16 位字進行二進制反碼求和的結果是全 0 ?這就是偽首部和整個 UDP 的所有欄位都是 0,但很明顯,這是不可能的,所有的地址和資料都是 0,還有什么意義?不要以為兩個 1 相加就是 0,不對,兩個 1 相加按二進制反碼求和的結果是 1 0,這里的 1 是進位,因為此按照計算檢驗和的規矩來計算,對真實的 UDP 用戶資料報不可能得出檢驗和的數值是全 1,
但是,計算檢驗和時的倒數第二步,即按二進制反碼求和的結果卻有可能是全 1,在這種情況下,最后一步求反碼,就會得出檢驗和是全 0,但是前面我們已經講過,檢驗和置為全 0是表示發送方不使用檢驗和,這樣就產生了疑問:如果檢驗和是全 0,是發送方不使用檢驗和?還是使用了檢驗和但檢驗和的結果碰巧全是 0?無法確定,于是 UDP 協議就規定:如果計算檢驗和的結果剛好是全 0,那么就把它人為的置為全 1,因為前面已經講過,全 1 的檢驗和是不可能由計算出來的,因此接收方一旦收到檢驗和為全 1 的 UDP 用戶資料報,就知道這是人為的,真正地檢驗和其實是全 0,
(3)發送方使用檢驗和,檢驗和的數值是全 0,
前面已經講過,這是不可能的,如果發送方計算出來的檢驗和是全 0,那也要把它變成全 1 再發送出去,
52.UDP 和 IP 的不可靠程度是否相同? 請加以解釋,
答:① UDP 和 IP 都是無連接的協議和不可靠傳輸的協議,UDP 用戶資料報和 IP 資料報的首部都有檢驗和欄位,當檢驗出現差錯時,就把收到的 UDP 用戶資料報或 IP 資料報丟棄,這是它們的相同之處,
② 但 UDP 和 IP 的可靠性是有些區別的,UDP 用戶資料報的檢驗和是既檢驗 UDP 用戶資料報的首部又檢驗整個的 UDP 用戶資料報的資料部分,而 IP 資料報的檢驗和僅僅檢驗 IP 資料報的首部,UDP 用戶資料報的檢驗和還增加了偽首部,即還檢驗了下面的 IP 資料報的源 IP 地址和目的 IP 地址,
53.UDP 用戶資料報的最小長度是多少?用最小長度的 UDP 用戶資料報構成的最短 IP 資料報的長度是多少?
答:UDP 用戶資料報的最小長度是 8 位元組,即僅有首部而沒有資料,用最小長度的 UDP 源用戶資料報構成的最短 IP 資料報的長度為 28 位元組,此 IP 資料報具有 20 位元組的固定首部,首部中沒有可選欄位,
54.某客戶使用 UDP 將資料發送給一服務器,資料共 16 位元組,試計算在運輸層的傳輸效率(有用位元組與總位元組之比),
解:UDP的資料報總長度=16+8=24位元組
傳輸效率=(16/24)×100%=66.7%
55.重做 54,但在 IP 層計算傳輸效率,假定 IP 首部無選項,
解:IP資料報總長度=24+20=44位元組
傳輸效率=(16/44)×100%=32.4%
56.重做 54,但在資料鏈路層計算傳輸效率,假定 IP 首部無選項,在資料鏈路層使用以太網,
解:以太網有 14 位元組的首部,4 位元組的尾部(FCS 欄位),發送以太網的幀之前還有 8 位元組的前同步碼,但其資料欄位的最小長度是 46 位元組,而我們的 IP 資料報僅有 44 位元組,因此還必須加上 2 位元組的填充,這樣,以太網的總長度 = 14 + 4 + 8 + 2 + 44 = 72 位元組,
傳輸效率=(16/72)×100%=22.2%
57.某客戶有 67000 位元組的分組,試說明怎樣使用 UDP 用戶資料將這個分組進行傳送,
答:一個 UDP 用戶資料報的最大長度為 65535 位元組,現在的長度超過了這個限度,因此不能使用一個 UDP 用戶資料報來傳送,必須進行切割(例如,分割為兩個 UDP 用戶資料報),使其長度不超過以上的限度,
58.TCP 在 4:30:20 發送了一個報文段,它沒有收到確認,在 4:30:25 它重傳了前面這個報文段,它在 4:30:27 收到確認,若以前的 RTT 值為 4 秒,根據 Karn 演算法,新的 RTT 值為多少?
解:根據 Karn 演算法,只要是 TCP 報文段重傳了,就不采用其往返時間樣本,本題中收到的確認是在重傳后收到的,因此 RTT 沒有變化,仍然是以前的數值(4 秒),
Karn演算法:運輸層用來控制流量演算法,在計算平均往返時延 RTT 時,只要報文段重傳了,就不采用其往返時延樣本,這樣得出的平均往返時延 RTT 和重傳時間就較準確,
59.TCP 連接使用 1000 位元組的視窗值,而上一次的確認號是 22001,它收到了一個報文段,確認號是 22401.,試用圖來說明在這之前與之后的視窗情況,
答:在這之前和在這之后的視窗情況如下圖所示,
這里要注意的是:發送視窗為 1000 位元組,視窗里面的序號也正好是 1000 個,號碼小在后面,即在圖的左方,另外一點要注意的是,發送方收到的確認號表示接收方期望能夠收到序號,這個序號應當在發送視窗的最前面,
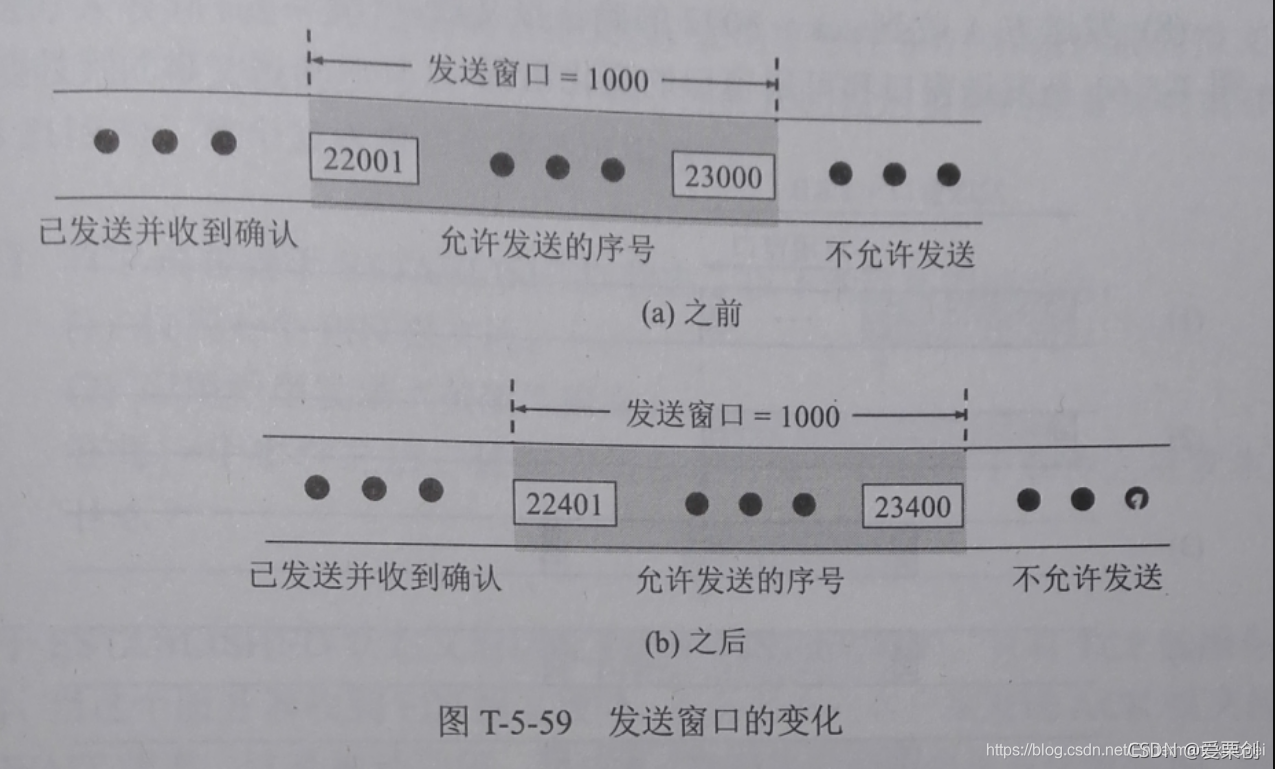
60.同上題,但在接收方收到的位元組為 22401 的報文段時,其視窗欄位變為 1200 位元組,試用圖來說明在這之前與之后的視窗情況,
答:在這之前與之后的視窗情況如下圖所示:
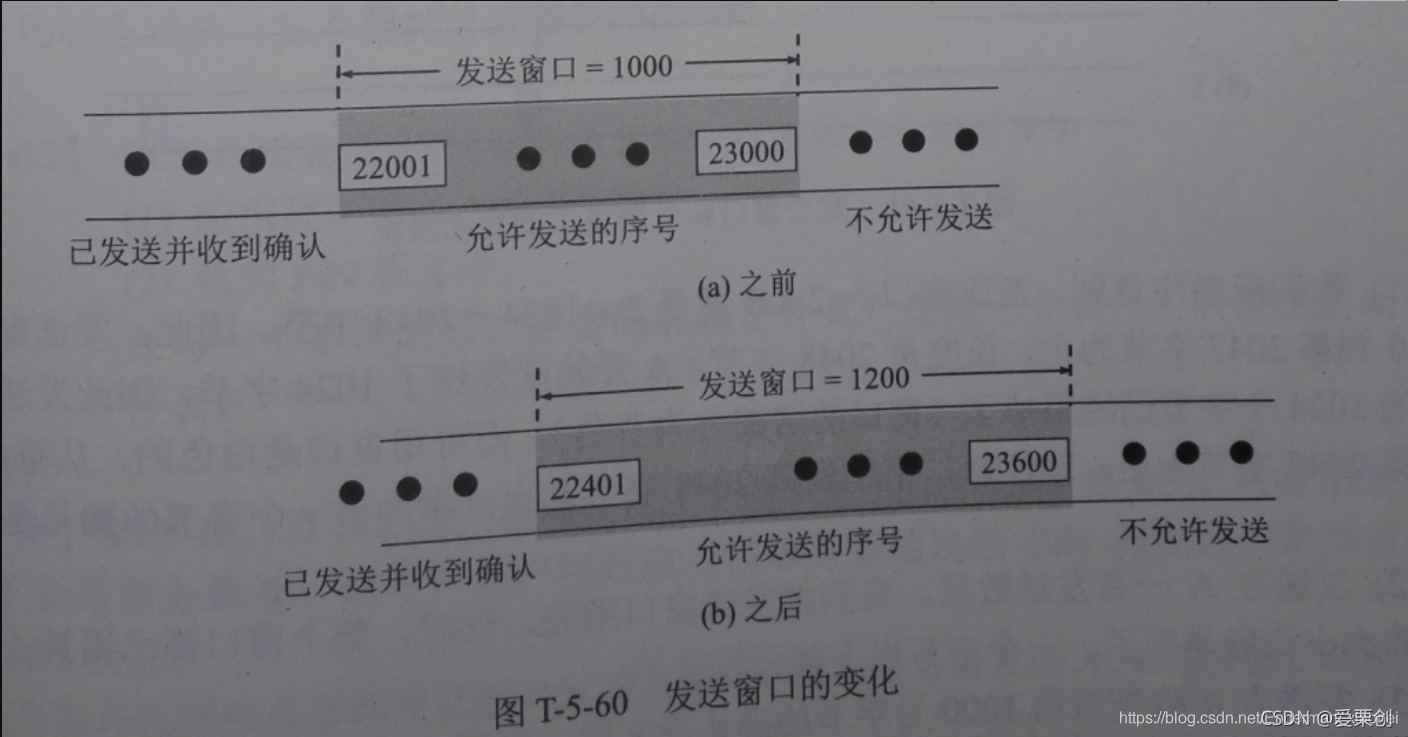
61.在本題中列出的 8 種情況下,畫出發送視窗的變化,并標明可用視窗的位置,已知主機 A 要向主機 B 發送 3 KB 的資料,在 TCP 連接建立后,A 的發送視窗大小是 2 KB,A 的初始序號是 0,
(1) 一開始 A 發送 1 KB的資料,
(2) 接著 A 就一直發送資料,直到把發送視窗用完,
(3) 發送方 A 收到對第 1000 號位元組的確認報文段,
(4) 發送方 A 再發送 850 B的資料,
(5) 發送方 A 收到 ack = 900 的確認報文段,
(6) 發送方 A收到對第 2047 號位元組的確認報文段,
(7) 發送方 A把剩下的資料全部都發送完,
(8) 發送方 A 收到 ack = 3072 的確認報文段,
答:
(1)我們應當注意到,發送視窗 = 2 KB 就是 2 ×1024 = 2048 位元組,因此,發送視窗應當是從 0 到第 2047 位元組為止,長度是 2048 位元組,A 開始就發送了 1024 位元組,因此發送視窗中左邊的 1024 個位元組已經用掉了(視窗的這部分為灰色),而可用視窗是白色的,從第 1024 位元組到第 2047 位元組位置,請注意,不是到第 2048 位元組位置,因此第一個編號是 0 而不是 1,
(2)發送方 A 一直發送資料,直到把發送視窗用完,這時,整個視窗都已用掉了,可用視窗的大小已經是零了,一個位元組也不能發送了,
(3)發送方 A 收到對第 1000 位元組的確認報文段,表明 A 收到確認號 ack = 1001 的確認報文段,這時,發送視窗的后沿向前移動,發送視窗從第 1001 位元組(不是從第 1000 位元組)到第 3048 位元組(不是第 3047 位元組)為止,可用視窗從第 2048 位元組到第 3048 位元組,【注意,因為從 1001 起,3048 - 1001 + 1 = 2048】
(4)發送方 A 再發送 850 位元組,使得可用視窗的后沿向前移動 850 位元組,即移動到 2898 位元組,現在的可用視窗從第 2898 位元組到 3048 位元組,
(5)發送方 A 收到 ack = 900 的確認報文段,不會對其視窗狀態有任何影響,這是個遲到的確認,
(6)發送方 A 收到對第 2047 號位元組的確認報文段,A 的發送視窗再向前移動,現在的發送視窗從第 2048 位元組開始到第 4095 位元組,可用視窗增大了,從第 2898 位元組第 4095 位元組,
(7)發送方 A 把剩下的資料全部發送完,發送方 A 共有 3 KB(即 3072 位元組)的資料,其編號從 0 到 3071,因此現在的可用視窗變小了,從第 3072 位元組到第 4095 位元組,
(8)發送方 A 收到 ack = 3072 的確認報文段,表明序號在 3071 和這以前的報文段都收到了,后面期望收到的報文段的序號熊 3072 開始,因此新的發送視窗的位置又向前移動,從第 3072 號位元組到第 5119 號位元組,整個發送視窗也就是可用視窗,
62.TCP 連接處于 ESTABLISHED 狀態,以下的事件相繼發生:
(1)收到一個 FIN 報文段,
(2)應用程式發送 “關閉” 報文,
在每一個事件之后,連接的狀態是什么?在每一個事件之后發生的動作是什么?
答:(1)處于 ESTABLISHED 狀態又能夠收到一個 FIN 報文段,只有 TCP 的服務器端而不會是客戶端,當這個服務器端收到 FIN 時,服務器就向客戶端發送 ACK 報文段,并進入到 CLOSE-WAIT 狀態,這是被動關閉,請注意,這時客戶端不會再發送資料了,但服務器端如還有資料要發送給客戶端,那么還是可以繼續發送的,
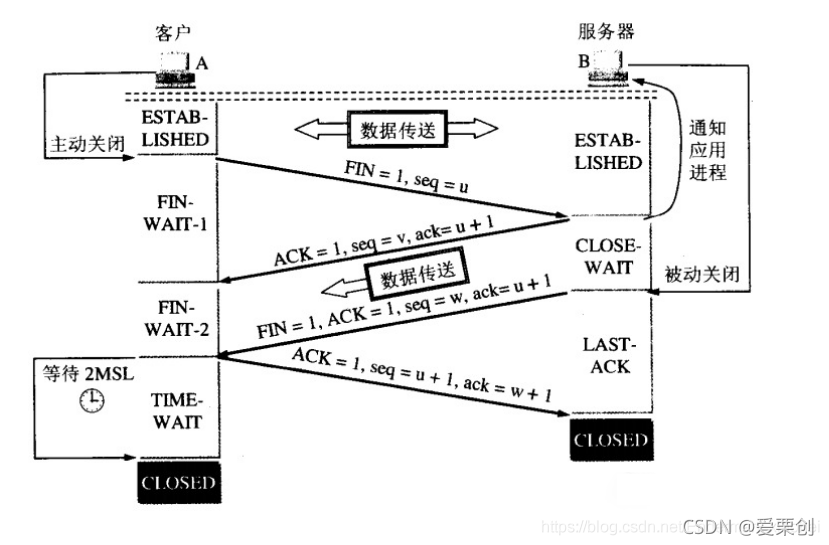
(2)應用程式發送 “關閉” 報文給服務器,表明沒有資料要發送了,這時服務器就應當發送 FIN 報文段給客戶,然后轉換到 LAST-ACK 狀態,并等待來自客戶端的最后的確認,
以上的狀態轉換可參考教材上的圖 5-30,
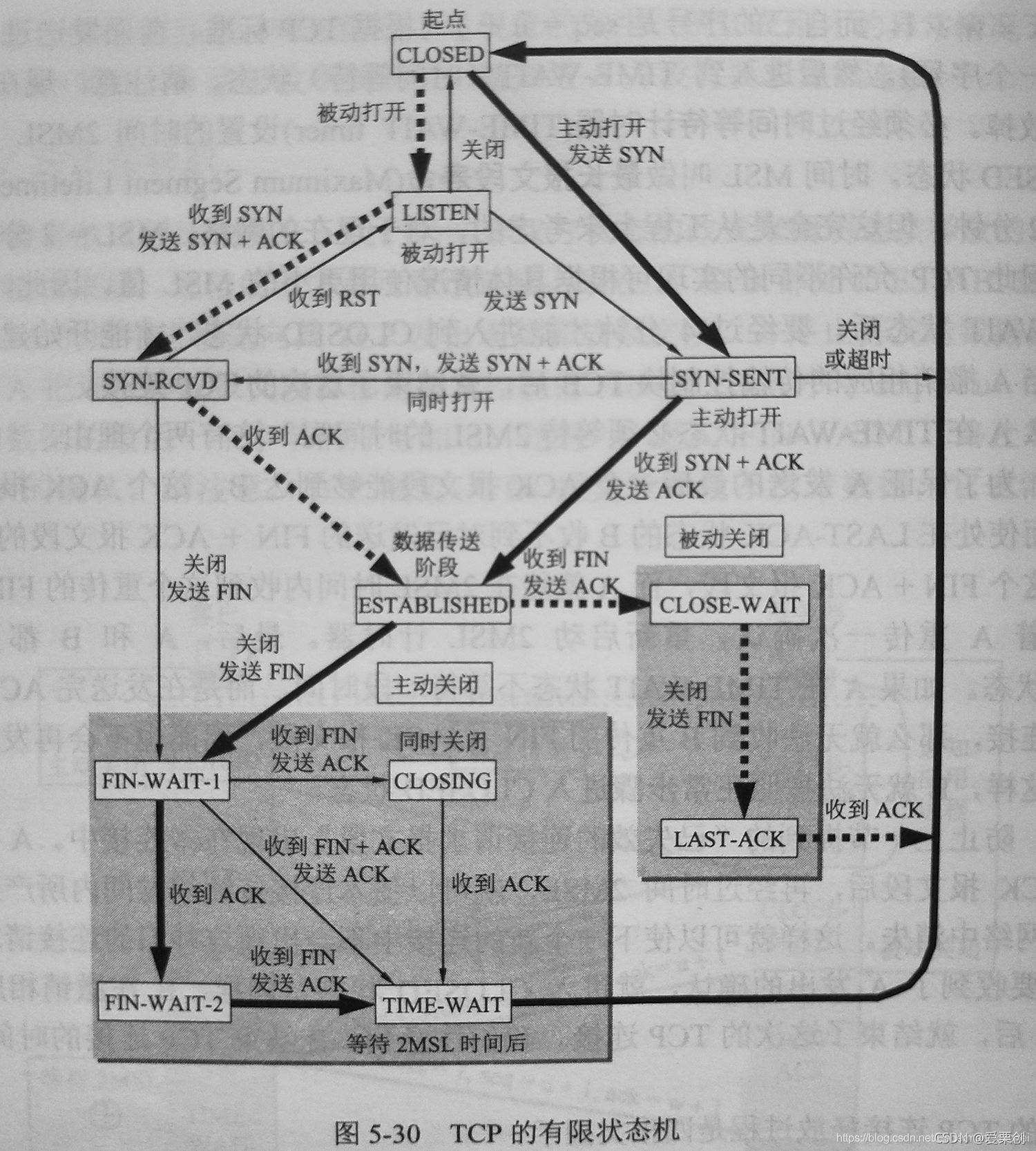
63.TCP 連接處于 SYN-RCVD 狀態,以下的事件相繼發生:
(1)應用程式發送 “關閉” 報文,
(2)收到 FIN 報文段,
在每一個事件之后,連接的狀態是什么?在每一個事件之后發生的動作是什么?
答:(1)處于 SYN-RCVD 狀態而又能夠收到應用程式發送的 “關閉” 報文的,只有 TCP 的客戶端而不會是服務器端,這時,客戶端就應當向服務器端發送 FIN 報文段,然后進入到 FIN-WAIT-1 狀態,
(2)當客戶收到服務器端發送的 FIN 報文段后,就向服務器發送 ACK 報文段,并進入到 CLOSED 狀態,
以上的狀態轉換可參考教材上的圖 5-30,
64.TCP 連接處于 FIN-WAIT-1 狀態,以下的事件相繼發生:
(1)收到 ACK 報文段,
(2)收到 FIN 報文段,
(3)發生了超時,
在每一個事件之后,連接的狀態是什么?在每一個事件之后發生的動作是什么?
答:(1)處于 FIN-WAIT-1 狀態的只有 TCP 的客戶,當收到 ACK 報文段后,TCP 客戶不發送任何報文段,只是從 FIN-WAIT-1 狀態進入到 FIN-WAIT-2 狀態,
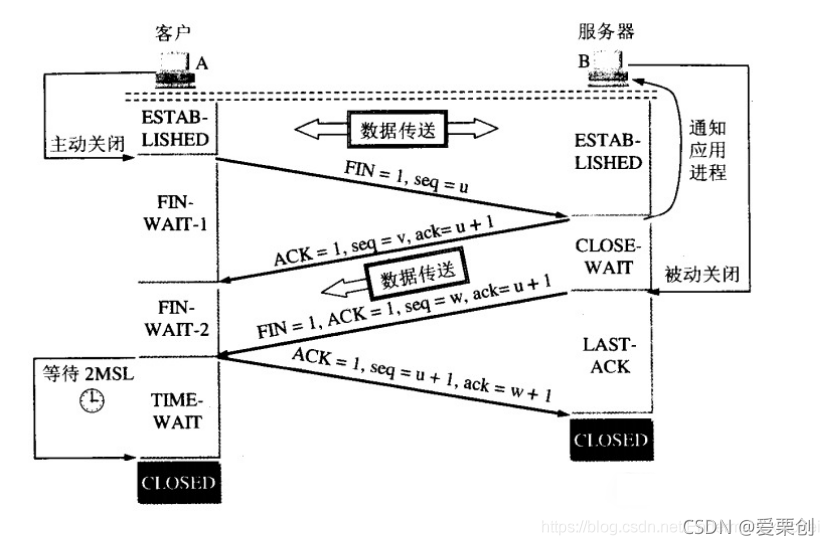
(2)在收到 FIN 報文段后,TCP 客戶發送 ACK 報文段,并進入到 TIME-WAIT 狀態,
(3)當發生了超時,也就是經過了 2 MSL時間后,TCP 客戶進入到 CLOSED 狀態,
以上的狀態轉換可參考教材上的圖 5-30,
65.假定主機 A 向 B 發送一個 TCP 報文段,在這個報文段中,序號是 50,而資料一共有 6 位元組長,試問,在這個報文段中的確認欄位是否應當寫入 56?
答:在這個報文段中的確認欄位應當寫入的是B期望下次收到A發送的資料中的第一個位元組的編號,而這個數值是B已經收到的資料的最后一個位元組的編號加 1,然而這些在題目中并未給出,題目給出的是 A 向 B 發送的資料中第一個位元組的編號是 50,并且在這個報文段中共有 6 位元組的資料,這些都和此報文段中的確認欄位是什么毫無關系,因此,現在我們無法知道這個報文段中的確認欄位應當寫入的數值,
66.主機 A 通過 TCP 連接向 B 發送一個很長的檔案,因此這需要分成很多個報文段來發送,假定某一個 TCP 報文段的序號是 x,那么下一個報文段的序號是否就是 x + 1 呢?
答:假定某一個 TCP 報文段的序號是 x,那么下一個報文段的序號應當是 x+n,這里的 n 是這個報文段中的資料長度的位元組數,如 n = 4000,那么下一個報文段的序號應當是 x + 4000,若此報文段中僅有一個位元組的資料,則下一個報文段的序號才是 x + 1,
67.TCP 的吞吐量應當是每秒發送的資料位元組數,還是每秒發送的首部和資料之和的位元組數?吞吐量應當是每秒發送的位元組數,還是每秒發送的位元數?
答:① TCP 的吞吐量本來并沒有標準的定義,可以計入首部,也可以不計入首部,但應當說清楚,不過,從擁塞控制來看,擁塞視窗和發送視窗針對的都是 TCP 報文段中的資料欄位,而重要的引數 MSS 也是指 TCP 報文段中的資料欄位的長度,因此,把 TCP 的吞吐量定義為每秒發送的資料位元組數是比較方便的,
② 計算機內部的資料傳送是以每秒多少位元組作為單位的,而在通信線路上的資料率則常用每秒多少位元作為單位,這兩種表示方法并無實質上的差別,在上面的習題中,因為 MSS 用位元組作為單位,因此,用每秒發送多少位元組作為 TCP 吞吐量的單位就比較簡單一些,
68.在 TCP 的連接建立的三報文握手程序中,為什么第三個報文段不需要對方的確認?這會不會出現問題?
答:① 關于這個問題,還不能簡單地用 “是” 或 “否” 來回答,
② 我們假定 A 是客戶端,是發起 TCP 連接建立一方,現在假定三報文握手程序中的第三個報文段(也就是 A 發送的第二個報文段 —— 確認報文)丟失了,而 A 并不知道,這是,A 以為對方收到了這個報文段,以為 TCP 連接已經建立,于是就開始發送資料報文段給 B,
③ B 由于沒有收到三報文握手中的最后一個報文段(A 發送的確認報文段),因此 B 就不能進入 TCP 的 ESTABLISHED 狀態(“連接已建立” 狀態),B 的這種狀態可以叫做 “半開連接” ,即僅僅把 TCP 連接打開了一半,在這種狀態下,B 雖然已經初始化了連接變數和快取,但是不能接收資料,通常,B 在經過一段時間后(例如,一分鐘后) ,如果還沒有收到來自 A 的確認報文段,就終止這個半開連接狀態,那么 A 就必須重新建立 TCP 連接,因此,在這種情況下,第三個報文段(A 發送的第二個報文段)的丟失,就導致了 TCP 連接無法建立,
④ 但是,假定 A 在這段時間內,緊接著就發送了資料,我們知道,TCP 具有累計確認的功能,在 A 發送的資料報文段中,自己的序號也沒有改變,仍然是和丟失的確認真的序號一樣(丟失的那個確認幀不消耗序號),并且確認位 ACK = 1,確認號也是 B 的初始序號加 1,當 B 收到這個報文段后,從 TCP 的首部就可以知道,A 已確認了 B 剛才發送的 SYN + ACK 報文段,于是就進入了 ESTABLISHED 狀態(“連接已建立” 狀態),接著,就接收 A 發送的資料,在這種情況下,A 丟失的第二個報文段對 TCP 的連接建立就沒有影響,
⑤ 大家知道,A 在發送第二個報文段時,可以有兩種選擇:
(1)僅僅是確認而不攜帶資料,資料接著在后面發送,
(2)不僅是確認,而且攜帶上自己的資料,
⑥ 在第一種選擇時,A 在下一個報文段發送自己的資料,但下一個報文的首部中仍然包括了對 B 的 SYN + ACK 報文段的確認,即和第二種選擇發送的報文段一樣,
⑦ 在第二種選擇時,A 省略了單獨發送一個確認報文段,
從這里也可以看出,A 發送的第二個僅僅是確認的報文段,是個可以省略的報文段,即使丟失了也無妨,只要下面緊接著就可以發送資料報文段即可,
69.現在假定使用類似 TCP 的協議(即使用滑動視窗可靠傳送位元組流),資料傳輸速率是 1 Gbit/s,而網路的往返時間 RTT = 140 ms,假定報文段的最大生存時間是 60 秒,如果要盡可能快的傳送資料,在我們的通信協議的首部中,發送視窗和序號欄位至少各應當設為多大?
解:發送視窗至少能夠容納的位元數=傳輸速率×RTT=1Gbit/s × 140ms=1.75×
1
0
7
10^7
107bit
我們知道,每一個位元組的資料需要有一個編號,假定發送視窗一共有 w 位,那么總的號碼數應當大于1.75×
1
0
7
10^7
107位元組,即:
2
w
2^w
2w>17500000,那么w>24.06,那么發送視窗至少為25位,
可見只用 24 位的發送視窗差一點,必須使用 w = 25 位的發送視窗才行,TCP 的視窗欄位為 16 位,
再看看 60 秒鐘以1Gbit/s 的速率可以發送 60s×
1
0
9
10^9
109bit/s=7.5×
1
0
9
10^9
109位元組的資料,
假定需要 n 位的序號欄位,那么總的序號數應當大于 7.5×
1
0
9
10^9
109位元組,即:
2
n
2^n
2n > 7.5 ×
1
0
9
10^9
109,求得n=32.8
因此,取序號欄位長度 n = 33 位即可保證在報文段的最大生產時間內沒有重復的序號,但TCP 的序號欄位為 32 位(因為TCP的序號欄位范圍是0~32位),
70.假定用 TCP 協議在 40 Gbit/s 的線路上傳送資料,
(1)如果 TCP 充分利用了線路的帶寬,那么需要多長的時間 TCP 會發生序號繞回?
(2)假定現在 TCP 的首部中采用了時間戳選項,時間戳占用了 4 位元組,共 32 位,每隔一定的時間(這段時間叫做一個滴答)時間戳的數值加 1,假定設計的時間戳是每隔 859 微秒,時間戳的數值加 1,試問要經過多長時間才發生時間戳數值的繞回,
解:(1)40Gbit/s的線路上每秒可以傳送5×
1
0
9
10^9
109個位元組,TCP序號共有
2
32
2^{32}
232個,那么需要經過
2
32
2^{32}
232/
5
×
1
0
9
5×10^9
5×109=0.859s就會發生TCP序號繞回,
(2)時間戳繞回時間:
2
3
2
2^32
232×0.000859s=3.69×
1
0
6
10^6
106=42.7天,
71. 5.5 節中指出:例如,若用 2.5 Gbit/s 速率發送報文段,則不到 14 秒鐘序號就會重復,請計算驗證這句話,
證明:2.5Gbit/s的速率,那么每秒就可以發送0.3125×
1
0
9
10^9
109個位元組,一共有
2
32
2^{32}
232個序號,
2
32
2^{32}
232/0.3125×
1
0
9
10^9
109=13.74S,所以這不到14秒,TCP序號就會發生繞回,
72.已知 TCP 的接收視窗大小是 600(單位是位元組,為簡單起見以后就省略了單位),已經確認了的序號是 300,試問,在不斷的接收報文段和發送確認報文段的程序中,接收視窗也可能會發生變化(增大或縮小),請用具體的例子(指出接收方發送的確認報文段中的重要資訊)來說明哪些情況是可能發生的,而哪些情況是不允許發的,
答: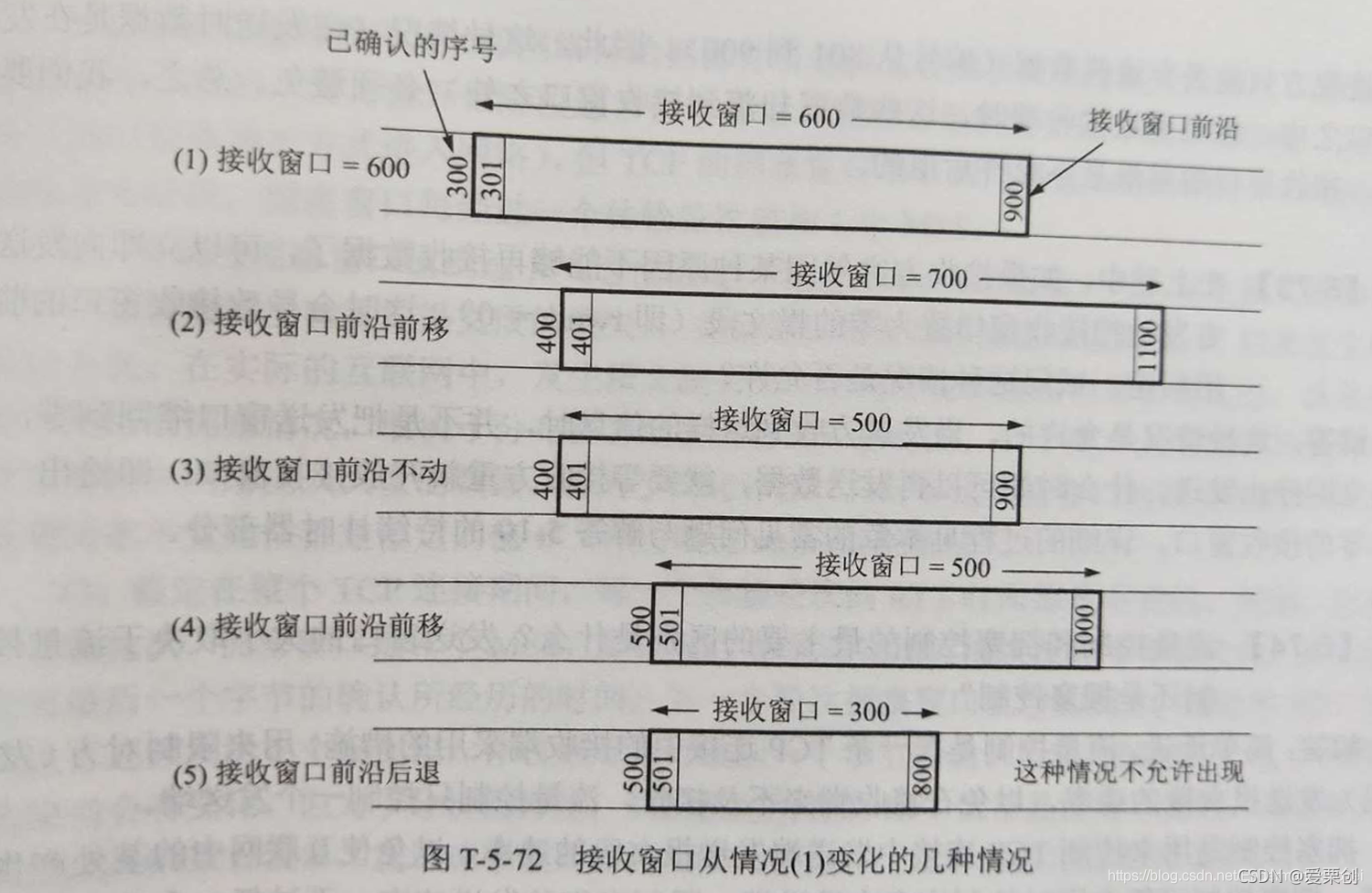
(1)這是題目開始的情況,接收方發送的確認報文段中的接收視窗 rwnd = 600,已確認的序號是 300,接收方發送的確認報文段的 ack = 301,表示期望收到開始的序號為 301 的資料,我們看到,序號 301 到 900 都在接收視窗內,
(2)接收視窗增大總是不受限制的,這就是說,只要接收端的 TCP 能夠拿出更多的空間來接收發來的資料,就可以這樣做,圖中給出的例子是:已確認的序號是 400,接收方發送的確認報文段為 ack = 401,假定現在接收視窗從情況(1)的 600 增大到了 700,即 rwnd = 700,現在接收視窗的范圍是從 401 到 1100,當接收視窗增大時,接收視窗的前沿總是向前移動的,
(3)這種情況是接收視窗變小了,但接收視窗的前沿沒有變化,例如,現在的已確認的序號是 400,接收方發送的確認報文段的 ack = 401,假定現在接收視窗從情況(1)的 600 減少到了 500,即 rwnd = 500,接收視窗的范圍是從 501 到 1000,
(4)這種情況是接收視窗變小了,同時接收視窗的前言頁向前移動了,例如,現在已確認的序號是 500,接收方發送的確認報文段的 ack = 501,假定現在接收視窗從情況 (1) 的 600 減少到了 500,即 rwnd = 500,接收視窗的范圍是從 501 到 1000,
(5)這種情況是接收視窗變小了,但接收視窗的前沿是后退的,例如,現在已確認的序號是 500,接收方發送的確認報文段的 ack = 501,假定現在接收視窗從情況(1)的 600 減小到了 300,即 rwnd = 300,接收視窗的范圍是從 501 到800,但請注意,這種情況是不允許出現的,也就是說,接收視窗的前沿是不允許后退的,在開始時,接收視窗的前沿的編號是 900,不管是接收視窗是變大還是變小,這個視窗的前沿的編號可以不動,也可以前移,但是不允許后退,
為什么不允許出現這種情況呢?可以先觀察一下發送方的情況,在一開始,發送方收到接收視窗 = 600 的報文段后(其中 ack = 301),發送方就把發送視窗設定為 600,可以發送的資料的序號從 301 到 900,假定發送方發送了在發送視窗內的全部資料,這本來正好落入到接收視窗之內,但這些資料正在網路中傳輸時,接收方卻縮小了接收視窗,只接收序號從 501 到 800 之間的資料,這就導致最后的一些資料(編號從 801 到 900)落入接收視窗之外,使得接收方只能丟棄這些資料(編號從 801 到 900),因此,這種情況(在發送時資料是在發送視窗之內,但到達接收端,這些資料卻落入到接收視窗之外)必須避免,總之,我們要記住,接收視窗是不允許后退的,
73.在上題中,如果接收方突然因某種原因不能夠再接收資料了,可以立即向發送方發送把接收視窗置為零的報文段(即 rwnd = 0),這時會導致接收視窗的前沿后退,試問這種情況是否允許?
答:這種情況是允許的,當發送方收到這樣的資訊,并不是把發送視窗碩訓到零,而是立即停止發送,什么時候可以再發送資料,就要等接收方重新開放接收視窗,即給出一個非零的接收視窗,
74.流量控制和擁塞控制的最主要的區別是什么?發送視窗的大小取決于流量控制還是擁塞控制?
簡單地說,流量控制是在一條 TCP 連接中的接收端才用的措施,用來限制對方(發送端)發送報文的速率,以免在接收端來不及接收,流量控制只控制一個發送端,
擁塞控制是用來控制 TCP 連接中發送端發送報文段的速率,以免使互聯網中的某處產生過載,擁塞控制可能會同時控制許多個發送端,限制它們的發送速率,不過每一個發送端只知道自己應當怎樣調整發送速率,而不知道在互聯網中還有哪些主機被限制了發送速率,
我們知道,發送視窗的上限值是 Min [rwnd, cwnd],即發送視窗的數值不能超過接收視窗和擁塞視窗中嬌小的一個,接收視窗的大小體現了接收端對發送端施加的流量控制,而擁塞視窗的大小則是整個互聯網的負載情況對發送端施加的擁塞控制,因此,當接收視窗小于擁塞視窗時,發送視窗的大小取決于流量控制,即取決于接收端的接收能力,但當擁塞視窗小于接收視窗時,則發送視窗的大小取決于擁塞控制,即取決于整個網路的擁塞狀況,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/374691.html
標籤:其他
上一篇:厲害了,有人這樣對Ansible Playbook做簡介
下一篇:計算機網路——常見協議