該篇章將開始整理MySQL的優化,不過開始之前,我們想了解清楚那就是MySQL是怎么執行的,
文章目錄
- 1.MySQL驅動
- 2.應用系統資料庫連接池
- 3.MySQL資料庫連接池
- 4.SQL執行程序
- 4.1.執行緒監聽:監聽網路請求中的SQL陳述句
- 4.2.SQL介面:負責處理接收到的SQL陳述句
- 4.3.查詢決議器:讓MySQL能看懂SQL陳述句
- 4.4.查詢優化器:選擇最優的查詢路徑
- 4.5.存盤引擎介面:真正執行SQL陳述句
- 4.6.執行器:根據執行計劃呼叫存盤引擎的介面
- 5.總結
1.MySQL驅動
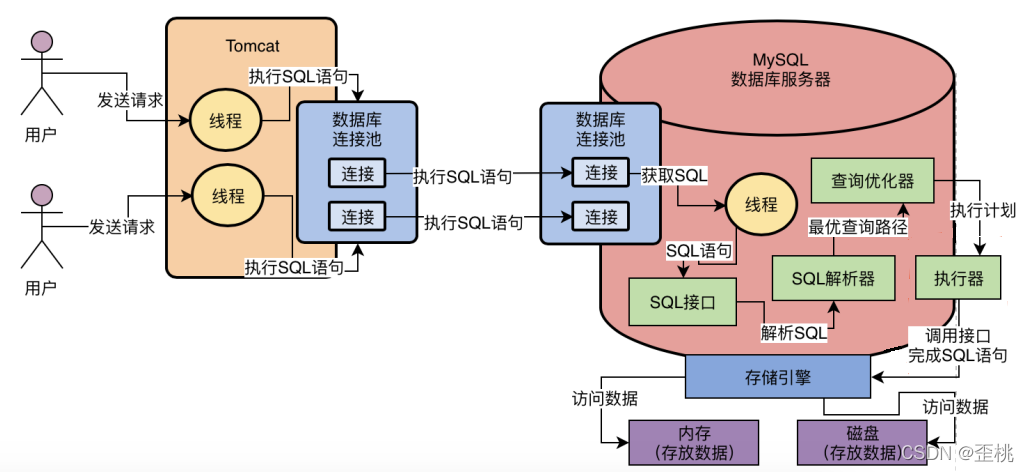
大家都知道,我們如果要在Java系統中去訪問一個MySQL資料庫,必須得在系統的依賴中加入一個MySQL驅動,有了這個MySQL驅動才能跟MySQL資料庫建立連接,然后執行各種各樣的SQL陳述句,
MySQL驅動,他會在底層跟資料庫建立網路連接,有網路連接,接著才能去發送請求給資料庫服務器!當我們跟資料庫之間有了網路連接之后,我們的Java代碼才能基于這個連接去執行各種各樣的增刪改查SQL陳述句,
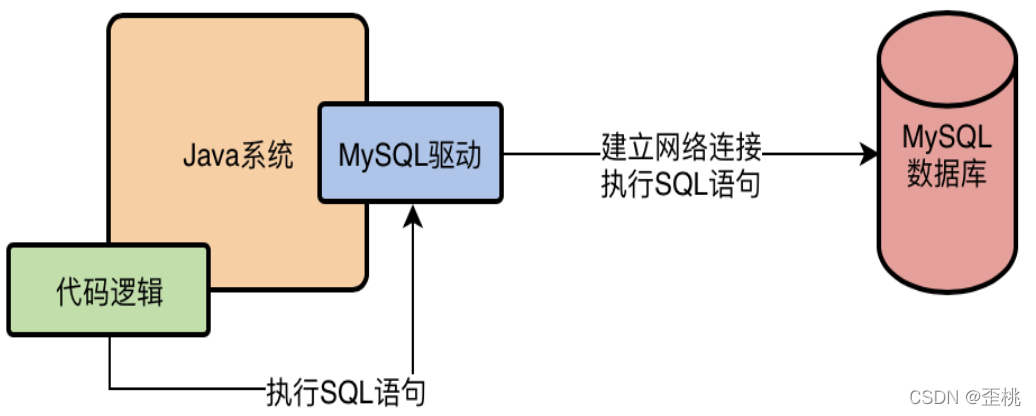
2.應用系統資料庫連接池
假設我們的系統是部署在Tomcat中的,那么Tomcat本身肯定是有多個執行緒來并發的處理同時接收到的多個請求的,如果Tomcat中的多個執行緒并發處理多個請求的時候,都要去搶奪一個連接去訪問資料庫的話,那效率肯定是很低下的,
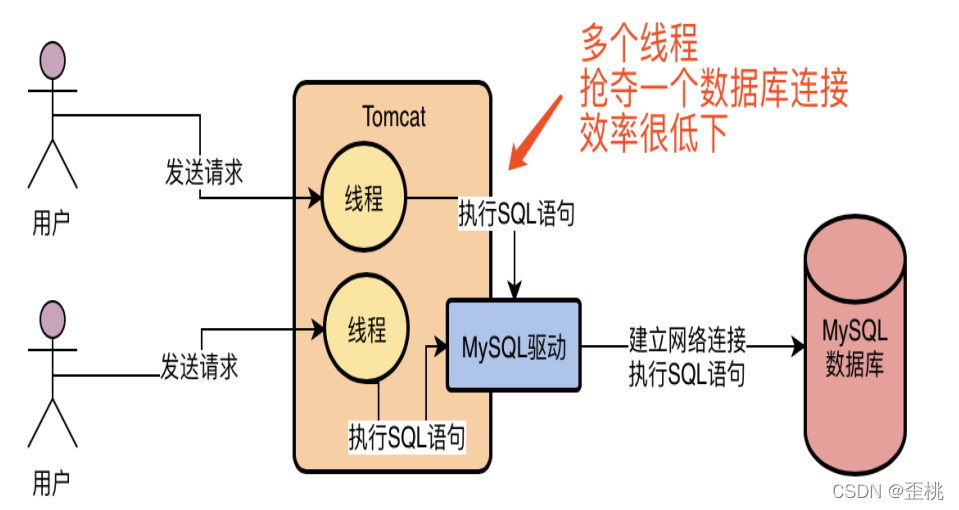
如果Tomcat中的每個執行緒在每次訪問資料庫的時候,都基于MySQL驅動去創建一個資料庫連接,然后執行SQL陳述句,然后執行完之后再銷毀這個資料庫連接,可能Tomcat中上百個執行緒會并發的頻繁創建資料庫連接,執行SQL陳述句,然后頻繁的銷毀資料庫連接,也是非常不好的,因為每次建立一個資料庫連接都很耗時,好不容易建立好了連接,執行完了SQL陳述句,你還把資料庫連接給銷毀了,下一次再重新建立資料庫連接,那肯定是效率很低下的!
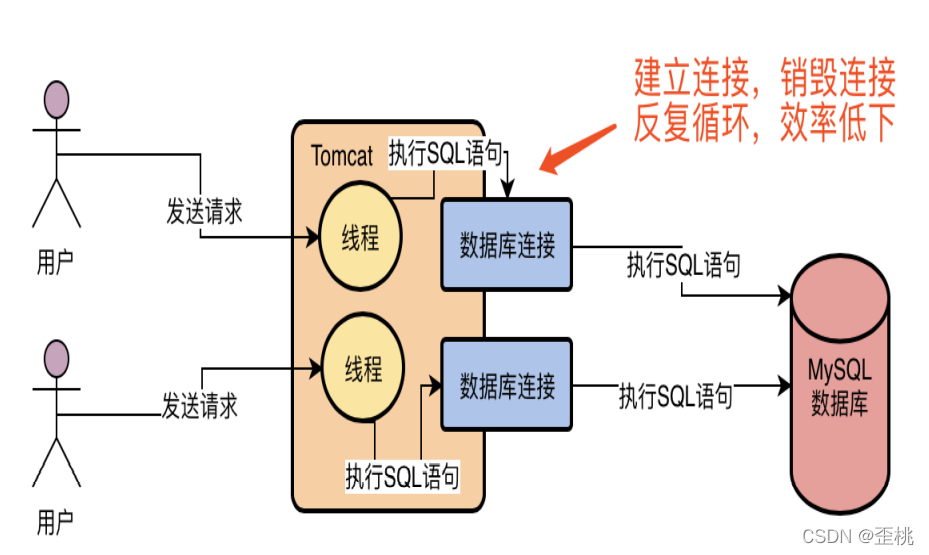
所以一般我們必須要使用一個資料庫連接池,也就是說在一個池子里維持多個資料庫連接,讓多個執行緒使用里面的不同的資料庫連接去執行SQL陳述句,然后執行完SQL陳述句之后,不要銷毀這個資料庫連接,而是把連接放回池子里,后續還可以繼續使用,基于這樣的一個資料庫連接池的機制,就可以解決多個執行緒并發的使用多個資料庫連接去執行SQL陳述句的問題,而且還避免了資料庫連接使用完之后就銷毀的問題,
常見的資料庫連接池有DBCP,C3P0,Druid
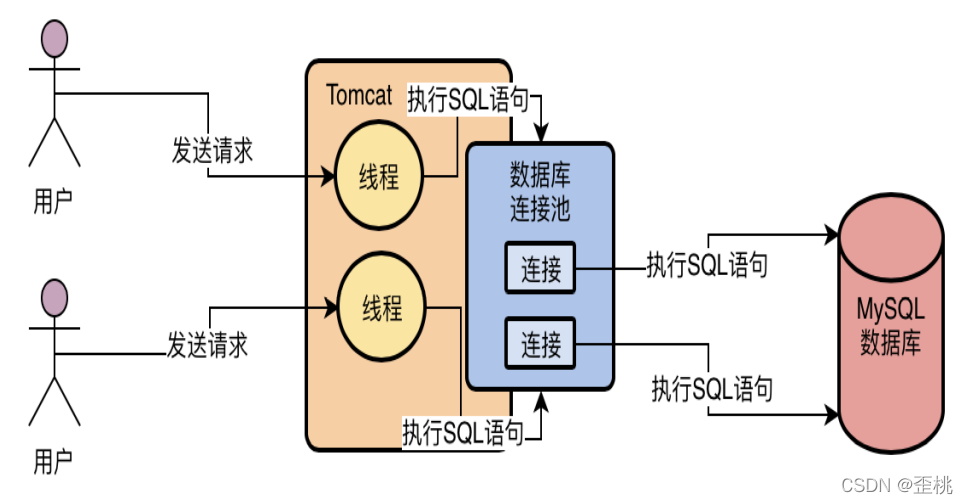
3.MySQL資料庫連接池
任何一個系統都會有一個資料庫連接池去訪問資料庫,也就是說這個系統會有多個資料庫連接,供多執行緒并發的使用,同時我們可能會有多個系統同時去訪問一個資料庫,這都是有可能的,MySQL也必然要維護與系統之間的多個連接,
實際上MySQL中的連接池就是維護了與系統之間的多個資料庫連接,除此之外,你的系統每次跟MySQL建立連接的時候,還會根據你傳遞過來的賬號和密碼,進行賬號密碼的驗證,庫表權限的驗證,
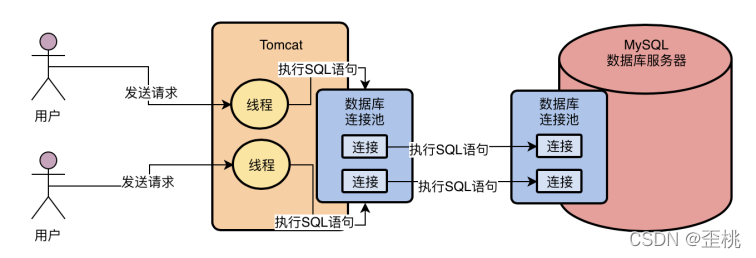
4.SQL執行程序
4.1.執行緒監聽:監聽網路請求中的SQL陳述句
現在假設我們的資料庫服務器的連接池中的某個連接接收到了網路請求,假設就是一條SQL陳述句,那么大家先思考一個問題,誰負責從這個連接中去監聽網路請求?誰負責從網路連接里把請求資料讀取出來?
我想很多人恐怕都沒思考過這個問題,但是如果大家對計算機基礎知識有一個簡單了解的話,應該或多或少知道一點,那就是網路連接必須得分配給一個執行緒去進行處理,由一個執行緒來監聽請求以及讀取請求資料,比如從網路連接中讀取和決議出來一條我們的系統發送過去的SQL陳述句,如下圖所示
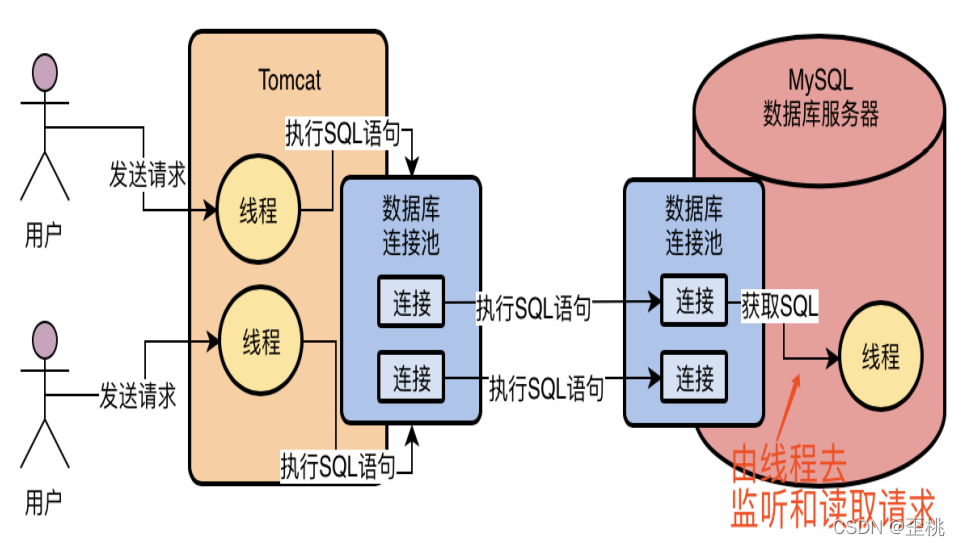
4.2.SQL介面:負責處理接收到的SQL陳述句
當MySQL內部的作業執行緒從一個網路連接中讀取出來一個SQL陳述句之后,此時會如何來執行這個SQL語
句呢?
MySQL內部首先提供了一個組件,就是SQL介面(SQL Interface),他是一套執行SQL陳述句的介面,專門用于執行我們發送給MySQL的那些增刪改查的SQL陳述句,因此MySQL的作業執行緒接收到SQL陳述句之后,就會轉交給SQL介面去執行,如下圖:
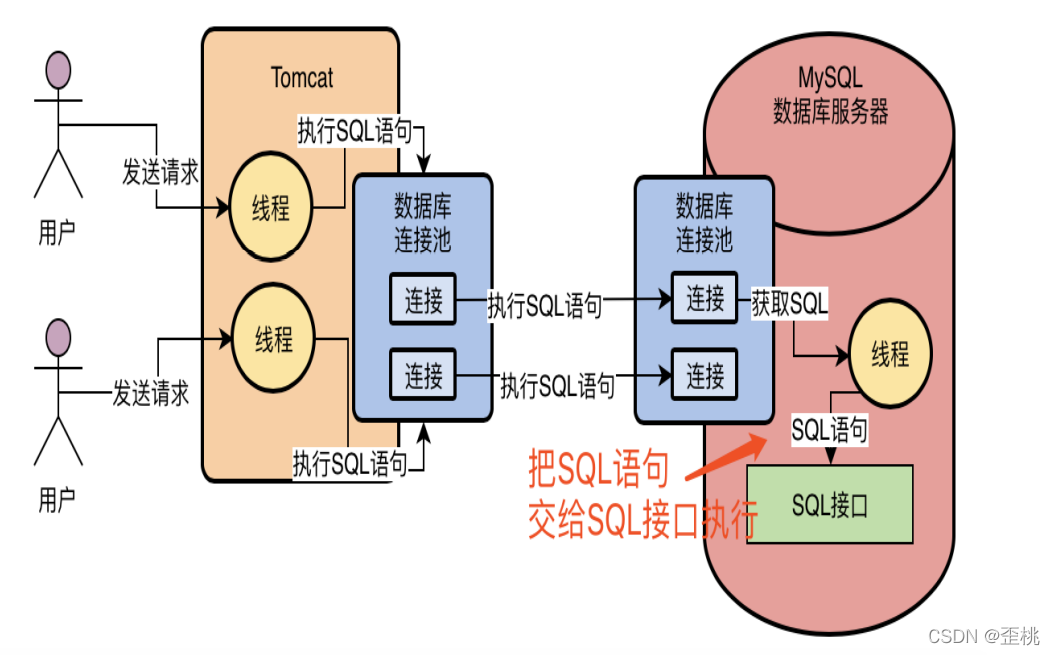
4.3.查詢決議器:讓MySQL能看懂SQL陳述句
SQL介面怎么執行SQL陳述句呢?你直接把SQL陳述句交給MySQL,他能看懂和理解這些SQL陳述句嗎?
比如我們來舉一個例子,現在我們有這么一個SQL陳述句:
select id,name,age from users where id=1
MySQL自己本身也是一個系統,是一個資料庫管理系統,他沒法直接理解這些SQL陳述句!
所以此時有一個關鍵的組件要出場了,那就是查詢決議器,
這個查詢決議器(Parser)就是負責對SQL陳述句進行決議的,比如對上面那個SQL陳述句進行一下拆解,拆解成以下幾個部分:
- 我們現在要從“users”表里查詢資料(from users)
- 查詢“id”欄位的值等于1的那行資料(where id=1)
- 對查出來的那行資料要提取里面的“id,name,age”三個欄位(select id,name,age)
所謂的SQL決議,就是按照既定的SQL語法,對我們按照SQL語法規則撰寫的SQL陳述句進行決議,然后理解這個SQL陳述句要干什么事情,如下圖所示
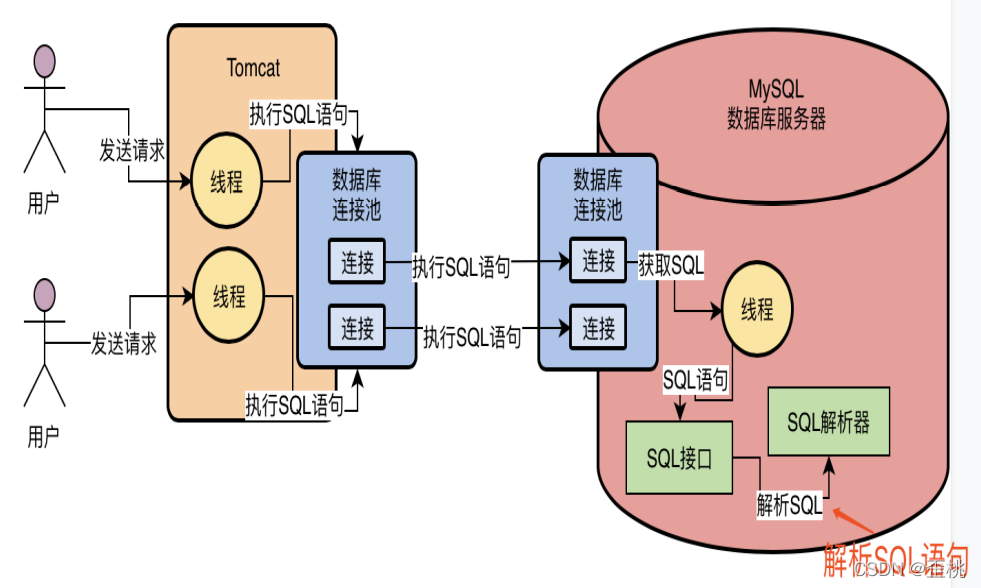
4.4.查詢優化器:選擇最優的查詢路徑
當我們通過決議器理解了SQL陳述句要干什么之后,接著會找查詢優化器(Optimizer)來選擇一個最優的查詢路徑,
在語法分析階段:會對SQL陳述句進行分析,比如如下sql陳述句
select A.name, A.age from tb_student A where A.age=18 and A.name='張三'
該SQL在被執行之前,會先進行語法檢測,判斷有無錯誤,之后會分析出如下兩個sql查詢條件,
- where A.age=18
- where A.name=‘張三’
問題就來了,這兩個條件誰先執行有區別嗎?答案是肯定的,在我們撰寫SQL的時候,都會遵循一個原則,就是把區分度最高的放在左側,
- where A.name=‘張三’ AND A.age=18
- where A.age=18 AND A.name=‘張三’
上面這就是一個最簡單的SQL陳述句的兩種實作路徑,其實我們會發現,要完成這個SQL陳述句的目標,兩個路徑都可以做到,但是哪一種更好呢?顯然感覺上是第一種查詢路徑更好一些,因為在我們資料庫系統中,叫張三的人可能只有幾百個,但是年齡為18歲的,可能有幾萬個,
所以查詢優化器大概就是干這個的,他會針對你撰寫的幾十行、幾百行甚至上千行的復雜SQL陳述句生成查詢路徑樹,然后從里面選擇一條最優的查詢路徑出來,相當于他會告訴你,你應該按照一個什么樣的步驟和順序,去執行哪些操作,然后一步一步的把SQL陳述句就給完成了,
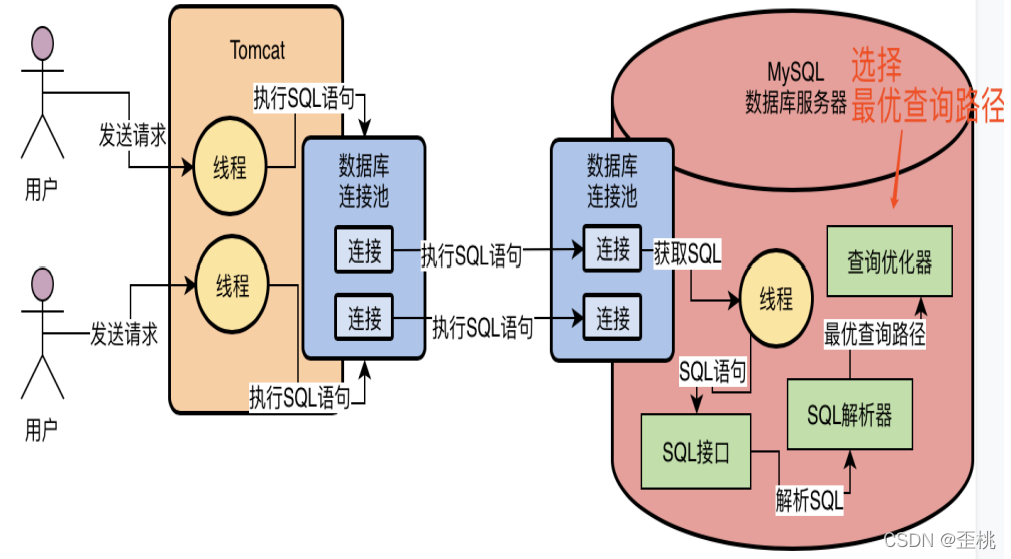
4.5.存盤引擎介面:真正執行SQL陳述句
把查詢優化器選擇的最優查詢路徑,也就是你到底應該按照一個什么樣的順序和步驟去執行這個SQL陳述句的計劃,把這個計劃交給底層的存盤引擎去真正的執行,這個存盤引擎是MySQL的架構設計中很有特色的一個環節,
真正在執行SQL陳述句的時候,要不然是更新資料,要不然是查詢資料,那么資料你覺得存放在哪里?
以對資料庫而言,我們的資料要不然是放在記憶體里,要不然是放在磁盤檔案里,
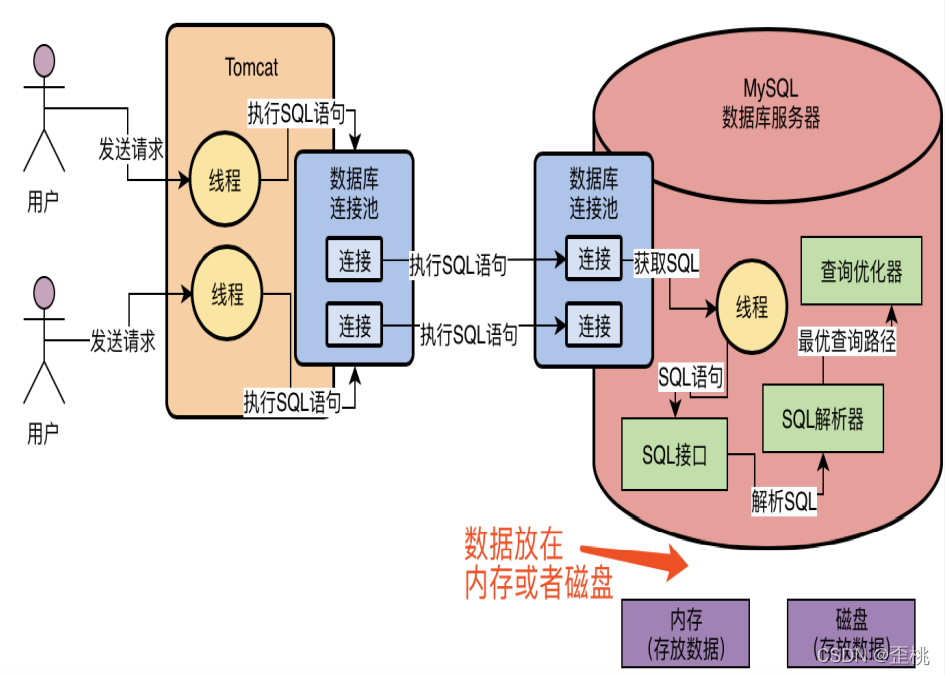
那么現在問題來了,我們已經知道一個SQL陳述句要如何執行了,但是我們現在怎么知道哪些資料在記憶體里?哪些資料在磁盤里?我們執行的時候是更新記憶體的資料?還是更新磁盤的資料?我們如果更新磁盤的資料,是先查詢哪個磁盤檔案,再更新哪個磁盤檔案?
所以這個時候就需要存盤引擎了,存盤引擎其實就是執行SQL陳述句的,他會按照一定的步驟去查詢記憶體快取資料,更新磁盤資料,查詢磁盤資料,等等,執行諸如此類的一系列的操作,如下圖所示,
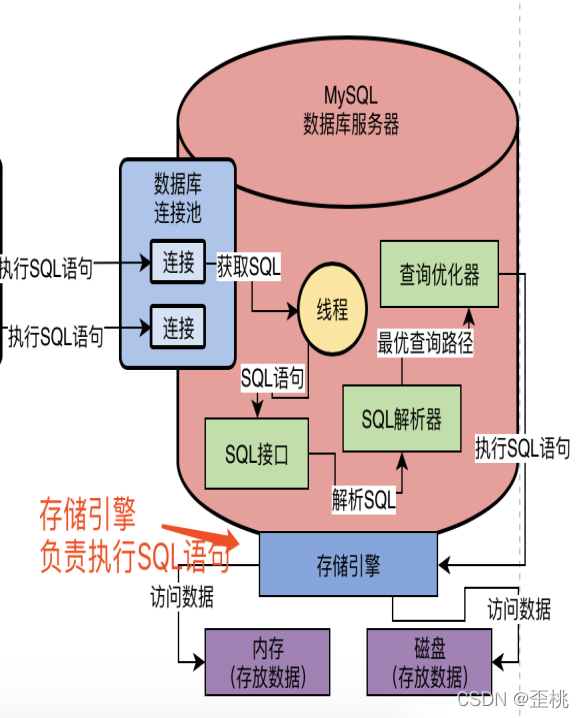
存盤引擎支持各種各樣的存盤引擎的,比如我們常見的InnoDB、MyISAM、Memory等等,我們是可以選擇使用哪種存盤引擎來負責具體的SQL陳述句執行的,當然現在MySQL一般都是使用InnoDB存盤引擎,
4.6.執行器:根據執行計劃呼叫存盤引擎的介面
存盤引擎可以幫助我們去訪問記憶體以及磁盤上的資料,那么是誰來呼叫存盤引擎的介面呢?
其實我們現在還漏了一個執行器的概念,這個執行器會根據優化器選擇的執行方案,去呼叫存盤引擎的介面按照一定的順序和步驟,就把SQL陳述句的邏輯給執行了,
執行器就會去根據我們的優化器生成的一套執行計劃,然后不停的呼叫存盤引擎的各種介面去完成SQL
陳述句的執行計劃,大致就是不停的更新或者提取一些資料出來,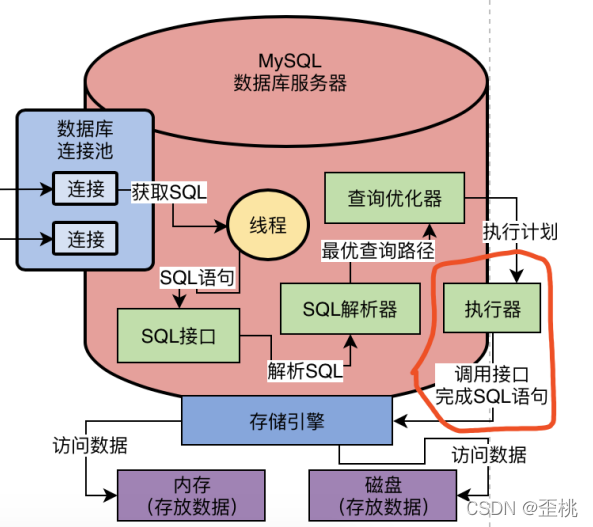
5.總結
本文介紹內容總體如下流程圖所示
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/374842.html
標籤:其他
上一篇:《九國列車》(學習報告)《leecode零基礎指南》(第8天) ——貪心,對題目的處理及題解和錯題的總結
下一篇:Hadoop環境搭建筆記