目錄
- 🌹前言
- 爬取目標(效果展示)
- 準備作業
- 代碼分析
- 第一步
- 第二步
- 第三步
- 第四步
- 完整代碼
- 啟動
🌹前言
博主開始更新爬蟲實戰教程了,期待你的關注!!!
第一篇:Python爬蟲實戰(一):翻頁爬取資料存入SqlServer
第二篇:Python爬蟲實戰(二):爬取快代理構建代理IP池
第三篇:Python爬蟲實戰(三):定時爬取微博熱榜資訊并存入SqlServer
點贊收藏博主更有創作動力喲,以后常更!!!

爬取目標(效果展示)
我們要爬取的網頁是:https://weibo.com/newlogin?tabtype=search&url=https%3A%2F%2Fweibo.com%2F
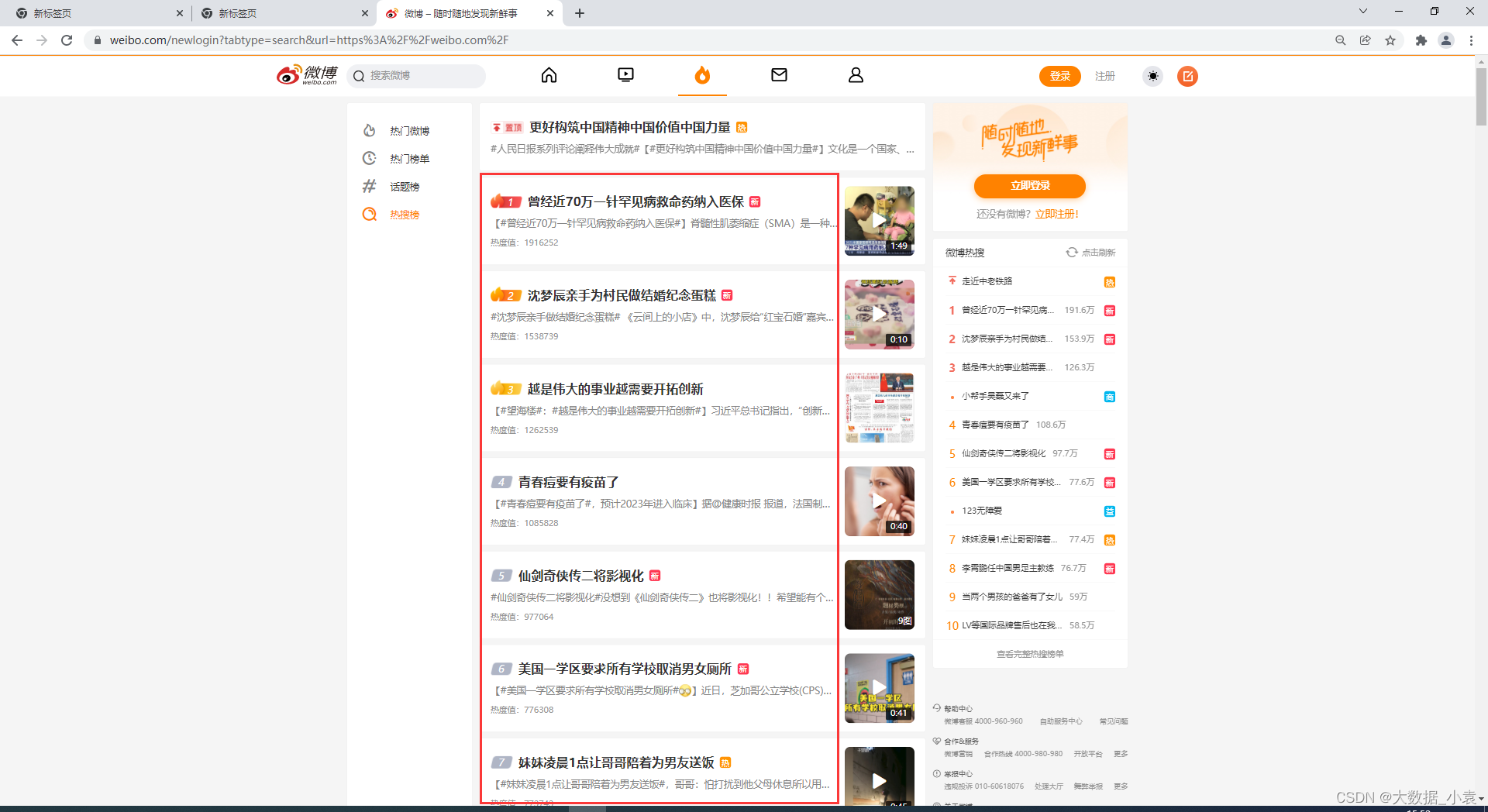
效果展示:
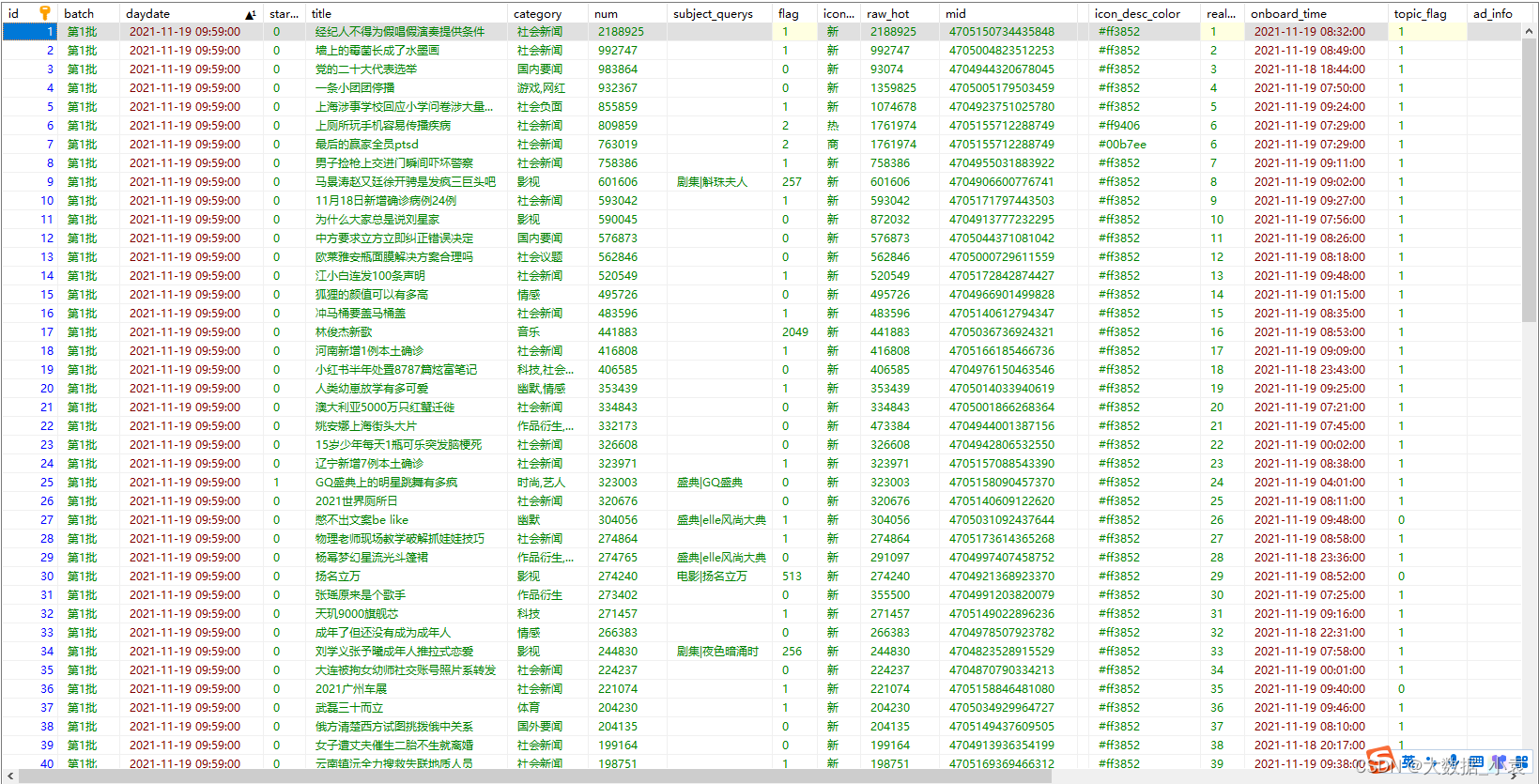
爬取的內容是:標題、榜單、熱度值、新聞型別、時間戳、url地址等
準備作業
建表:
CREATE TABLE "WB_HotList" (
"id" INT IDENTITY(1,1) PRIMARY key,
"batch" NVARCHAR(MAX),
"daydate" SMALLDATETIME,
"star_word" NVARCHAR(MAX),
"title" NVARCHAR(MAX),
"category" NVARCHAR(MAX),
"num" NVARCHAR(MAX),
"subject_querys" NVARCHAR(MAX),
"flag" NVARCHAR(MAX),
"icon_desc" NVARCHAR(MAX),
"raw_hot" NVARCHAR(MAX),
"mid" NVARCHAR(MAX),
"emoticon" NVARCHAR(MAX),
"icon_desc_color" NVARCHAR(MAX),
"realpos" NVARCHAR(MAX),
"onboard_time" SMALLDATETIME,
"topic_flag" NVARCHAR(MAX),
"ad_info" NVARCHAR(MAX),
"fun_word" NVARCHAR(MAX),
"note" NVARCHAR(MAX),
"rank" NVARCHAR(MAX),
"url" NVARCHAR(MAX)
)
為防止,欄位給的不夠,直接給個MAX!

代碼分析
第一步
發送請求,獲取網頁資訊
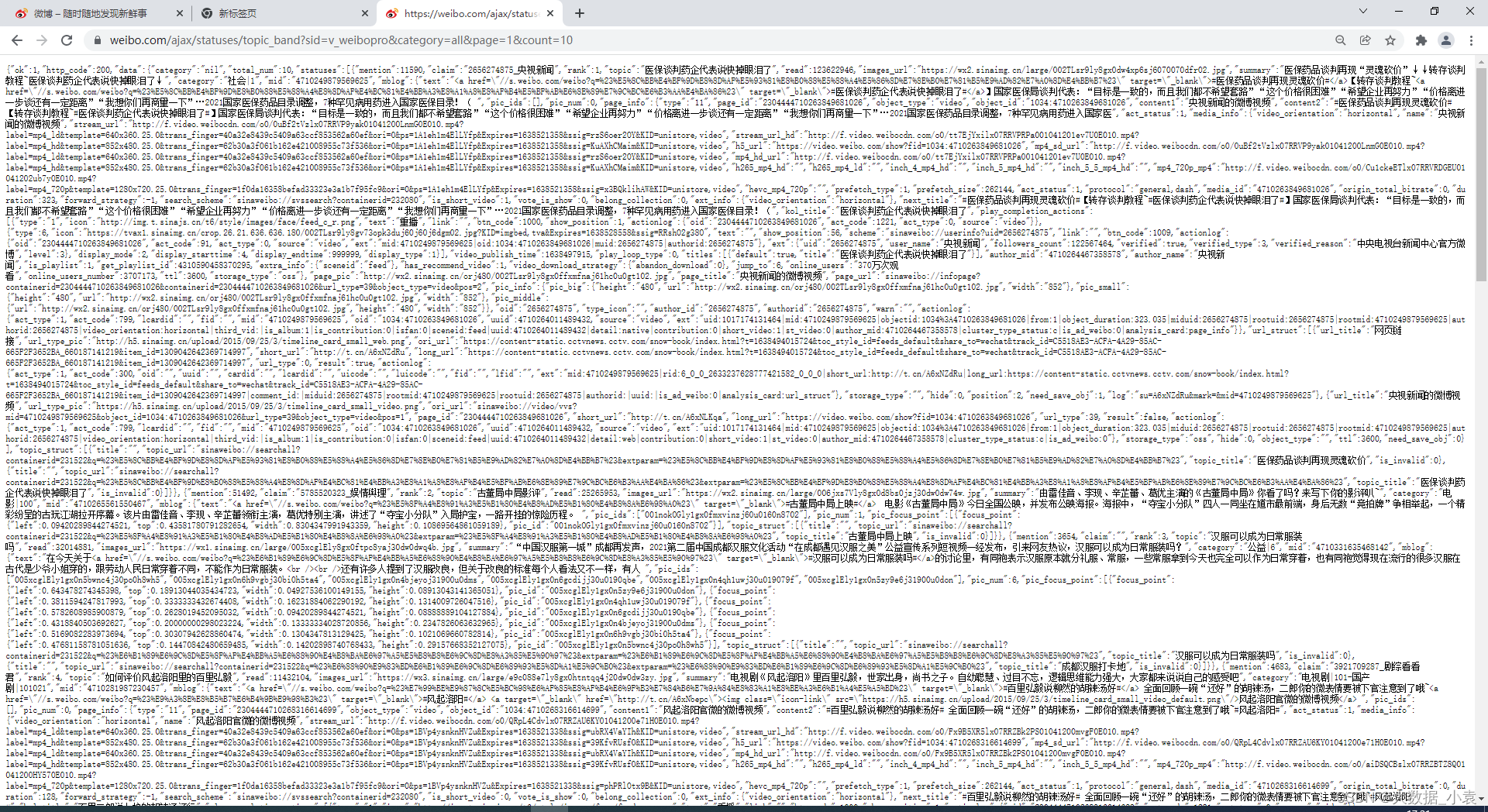
微博提供了資料的介面,所以我們直接訪問介面就行,如下圖(json格式):
介面地址:https://weibo.com/ajax/statuses/hot_band
def __init__(self) :
self.url = "https://weibo.com/ajax/statuses/hot_band"
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
# 發送請求,獲取相應
def parse_url(self):
response = requests.get(self.url,headers=self.headers)
time.sleep(2) # 休息兩秒
return response.content.decode()
第二步
決議資料,提取我們所需要的資料
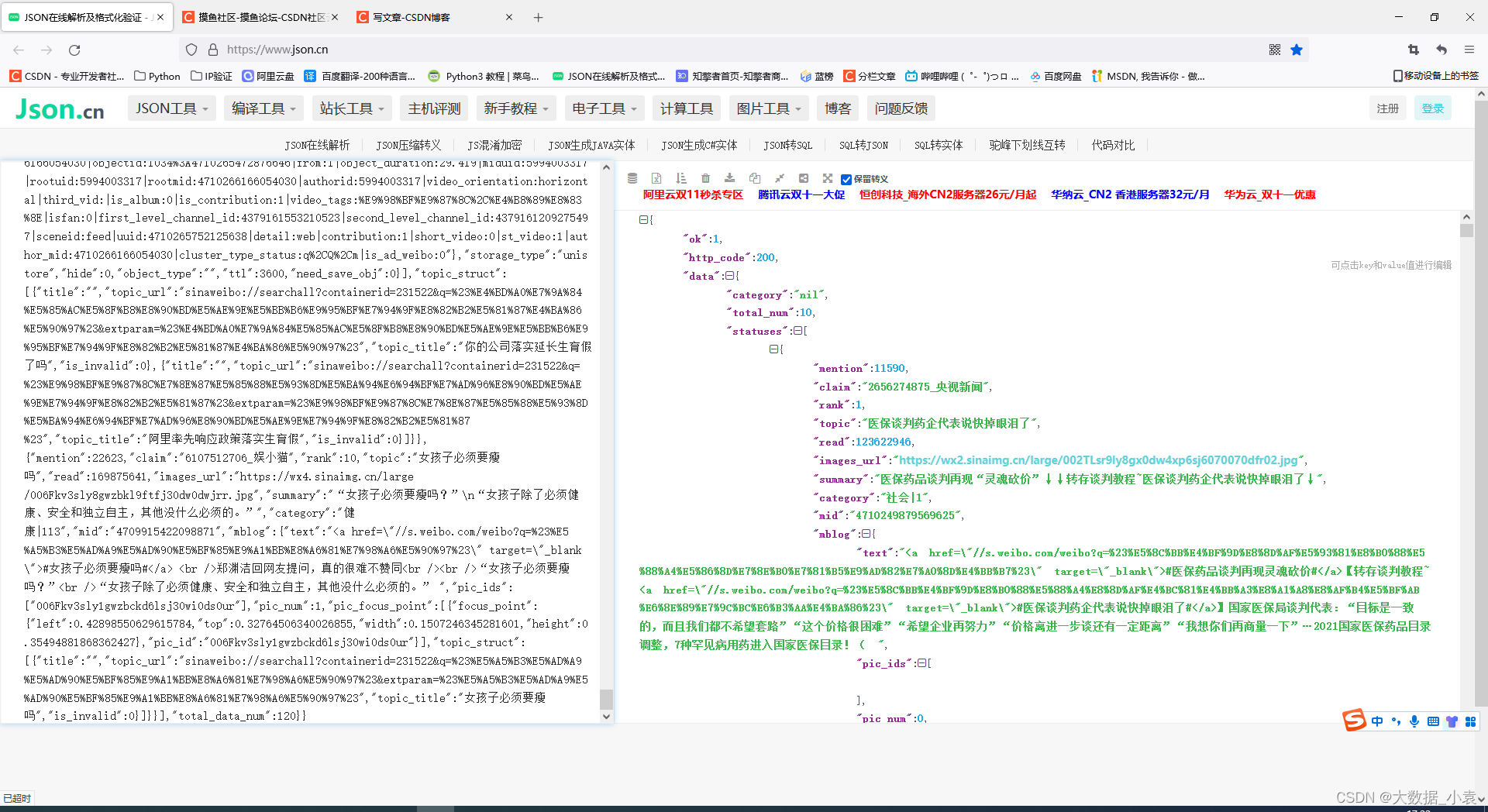
介面中的資料如下(只需提取我們所需要的):
for i in range(50):
ban_list = json_data['data']['band_list'][i]
batch = f'第{a}批'
try:
star_word = ban_list['star_word']
except Exception as e:
print(e)
try:
title = ban_list['word']
except Exception as e:
print(e)
try:
category = ban_list['category']
except Exception as e:
print(e)
try:
num = ban_list['num']
except Exception as e:
print(e)
try:
subject_querys = ban_list['subject_querys']
except Exception as e:
print(e)
try:
flag = ban_list['flag']
except Exception as e:
print(e)
try:
icon_desc = ban_list['icon_desc']
except Exception as e:
print(e)
try:
raw_hot = ban_list['raw_hot']
except Exception as e:
print(e)
try:
mid = ban_list['mid']
except Exception as e:
print(e)
try:
emoticon = ban_list['emoticon']
except Exception as e:
print(e)
try:
icon_desc_color = ban_list['icon_desc_color']
except Exception as e:
print(e)
try:
realpos = ban_list['realpos']
except Exception as e:
print(e)
try:
onboard_time = ban_list['onboard_time']
onboard_time = datetime.datetime.fromtimestamp(onboard_time)
except Exception as e:
print(e)
try:
topic_flag = ban_list['topic_flag']
except Exception as e:
print(e)
try:
ad_info = ban_list['ad_info']
except Exception as e:
print(e)
try:
fun_word = ban_list['fun_word']
except Exception as e:
print(e)
try:
note = ban_list['note']
except Exception as e:
print(e)
try:
rank = ban_list['rank'] + 1
except Exception as e:
print(e)
try:
url = json_data['data']['band_list'][i]['mblog']['text']
url = re.findall('href="(.*?)"',url)[0]
第三步
資料庫的batch用于判斷,每次插入的批次(50個一批),如果爬蟲斷了,寫個方法還能接著上次的批次
如圖:

# 把資料庫batch列存入串列并回傳(用于判斷批次號)
def batch(self):
conn=pymssql.connect('.', 'sa', 'yuan427', 'test')
cursor=conn.cursor()
cursor.execute("select batch from WB_HotList") #向資料庫發送SQL命令
rows=cursor.fetchall()
batchlist=[]
for list in rows:
batchlist.append(list[0])
return batchlist
第四步
把資料存入資料庫
# 連接資料庫服務,創建游標物件
db = pymssql.connect('.', 'sa', 'yuan427', 'test') #服務器名,賬戶,密碼,資料庫名
if db:
print("連接成功!")
cursor= db.cursor()
try:
# 插入sql陳述句
sql = "insert into test4(batch,daydate,star_word,title,category,num,subject_querys,flag,icon_desc,raw_hot,mid,emoticon,icon_desc_color,realpos,onboard_time, \
topic_flag,ad_info,fun_word,note,rank,url) values (%s,getdate(),%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# 執行插入操作
cursor.execute(sql,(batch,star_word,title,category,num,subject_querys,flag,icon_desc,raw_hot,mid,emoticon,icon_desc_color,realpos,onboard_time,topic_flag,ad_info, \
fun_word,note,rank,url))
db.commit()
print('成功載入......' )
except Exception as e:
db.rollback()
print(str(e))
# 關閉游標,斷開資料庫
cursor.close()
db.close()
完整代碼
import requests,pymssql,time,json,re,datetime
from threading import Timer
class Spider:
def __init__(self) :
self.url = "https://weibo.com/ajax/statuses/hot_band"
self.headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
# 發送請求,獲取相應
def parse_url(self):
response = requests.get(self.url,headers=self.headers)
time.sleep(2)
return response.content.decode()
# 決議資料,入庫
def parse_data(self,data,a):
json_data = json.loads(data)
# 連接資料庫服務,創建游標物件
db = pymssql.connect('.', 'sa', 'yuan427', 'test') #服務器名,賬戶,密碼,資料庫名
cursor= db.cursor()
for i in range(50):
ban_list = json_data['data']['band_list'][i]
batch = f'第{a}批'
try:
star_word = ban_list['star_word']
except Exception as e:
print(e)
try:
title = ban_list['word']
except Exception as e:
print(e)
try:
category = ban_list['category']
except Exception as e:
print(e)
try:
num = ban_list['num']
except Exception as e:
print(e)
try:
subject_querys = ban_list['subject_querys']
except Exception as e:
print(e)
try:
flag = ban_list['flag']
except Exception as e:
print(e)
try:
icon_desc = ban_list['icon_desc']
except Exception as e:
print(e)
try:
raw_hot = ban_list['raw_hot']
except Exception as e:
print(e)
try:
mid = ban_list['mid']
except Exception as e:
print(e)
try:
emoticon = ban_list['emoticon']
except Exception as e:
print(e)
try:
icon_desc_color = ban_list['icon_desc_color']
except Exception as e:
print(e)
try:
realpos = ban_list['realpos']
except Exception as e:
print(e)
try:
onboard_time = ban_list['onboard_time']
onboard_time = datetime.datetime.fromtimestamp(onboard_time)
except Exception as e:
print(e)
try:
topic_flag = ban_list['topic_flag']
except Exception as e:
print(e)
try:
ad_info = ban_list['ad_info']
except Exception as e:
print(e)
try:
fun_word = ban_list['fun_word']
except Exception as e:
print(e)
try:
note = ban_list['note']
except Exception as e:
print(e)
try:
rank = ban_list['rank'] + 1
except Exception as e:
print(e)
try:
url = json_data['data']['band_list'][i]['mblog']['text']
url = re.findall('href="(.*?)"',url)[0]
except Exception as e:
print(e)
try:
# 插入sql陳述句
sql = "insert into test4(batch,daydate,star_word,title,category,num,subject_querys,flag,icon_desc,raw_hot,mid,emoticon,icon_desc_color,realpos,onboard_time, \
topic_flag,ad_info,fun_word,note,rank,url) values (%s,getdate(),%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
# 執行插入操作
cursor.execute(sql,(batch,star_word,title,category,num,subject_querys,flag,icon_desc,raw_hot,mid,emoticon,icon_desc_color,realpos,onboard_time,topic_flag,ad_info, \
fun_word,note,rank,url))
db.commit()
print('成功載入......' )
except Exception as e:
db.rollback()
print(str(e))
# 關閉游標,斷開資料庫
cursor.close()
db.close()
# 把資料庫batch列存入串列并回傳(用于判斷批次號)
def batch(self):
conn=pymssql.connect('.', 'sa', 'yuan427', 'test')
cursor=conn.cursor()
cursor.execute("select batch from WB_HotList") #向資料庫發送SQL命令
rows=cursor.fetchall()
batchlist=[]
for list in rows:
batchlist.append(list[0])
return batchlist
# 實作主要邏輯
def run(self, a):
# 根據資料庫批次號給定a的值
batchlist = self.batch()
if len(batchlist) != 0:
batch = batchlist[len(batchlist) -1]
a = re.findall('第(.*?)批',batch)
a = int(a[0]) + 1
data = self.parse_url()
self.parse_data(data,a)
a +=1
# 定時呼叫
t = Timer(1800, self.run, (a, )) # 1800表示1800秒,半小時呼叫一次
t.start()
if __name__ == "__main__":
spider = Spider()
spider.run(1)
啟動
因為需要一直運行,所以就在 cmd 掛著
運行成功后,去資料庫看看:
O了O了!!!

有講的不對的地方,希望各位大佬指正!!!,如果有不明白的地方評論區留言回復!兄弟們來個點贊有空就更新爬蟲實戰!!!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/375962.html
標籤:其他
下一篇:快速冪 (競賽必備)