文章目錄
- 一、概述
- 1)Elasticsearch 存盤
- 2)Filebeat 日志資料采集
- 3)Kafka
- 4)Logstash 過濾
- 5)Kibana 展示
- filebeat和logstash的關系
- 二、helm3安裝ELK
- 1)準備條件
- 2)helm3安裝elasticsearch
- 1、自定義values
- 2、開始安裝Elasitcsearch
- 3、驗證
- 4、清理
- 3)helm3安裝Kibana
- 1、自定義values
- 2、開始安裝Kibana
- 3、驗證
- 4、清理
- 4)helm3安裝Filebeat
- 1、自定義values
- 2、開始安裝Filefeat
- 3、驗證
- 4、清理
- 5)helm3安裝Logstash
- 1、自定義values
- 2、開始安裝Logstash
- 3、驗證
- 4、清理
- 三、ELK相關的備份組件和備份方式
- 1)Elasticsearch的snapshot快照備份
- 2)elasticdump備份遷移es資料
- 3)esm備份遷移es資料
一、概述
ELK是三個開源軟體的縮寫,分別表示:Elasticsearch , Logstash, Kibana , 它們都是開源軟體,新增了一個FileBeat,它是一個輕量級的日志收集處理工具(Agent),Filebeat占用資源少,適合于在各個服務器上搜集日志后傳輸給Logstash,官方也推薦此工具,
大致流程圖如下:
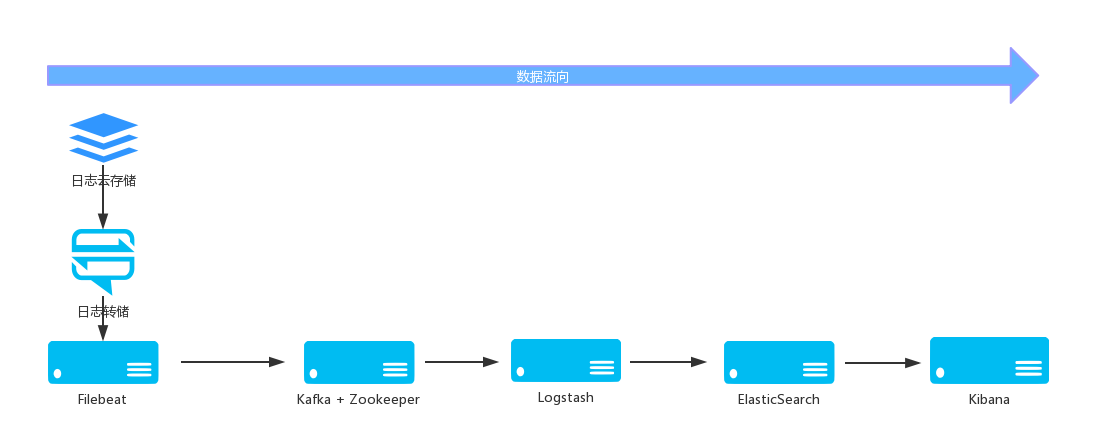
1)Elasticsearch 存盤
Elasticsearch是個開源分布式搜索引擎,提供搜集、分析、存盤資料三大功能,它的特點有:分布式,零配置,自動發現,索引自動分片,索引副本機制,restful風格介面,多資料源,自動搜索負載等,
2)Filebeat 日志資料采集
filebeat是Beats中的一員,Beats在是一個輕量級日志采集器,其實Beats家族有6個成員,早期的ELK架構中使用Logstash收集、決議日志,但是Logstash對記憶體、cpu、io等資源消耗比較高,相比Logstash,Beats所占系統的CPU和記憶體幾乎可以忽略不計,
Filebeat是用于轉發和集中日志資料的輕量級傳送工具,Filebeat監視您指定的日志檔案或位置,收集日志事件,
目前Beats包含六種工具:
- Packetbeat:網路資料(收集網路流量資料)
- Metricbeat:指標(收集系統、行程和檔案系統級別的CPU和記憶體使用情況等資料)
- Filebeat:日志檔案(收集檔案資料)
- Winlogbeat:windows事件日志(收集Windows事件日志資料)
- Auditbeat:審計資料(收集審計日志)
- Heartbeat:運行時間監控(收集系統運行時的資料)
作業的流程圖如下:
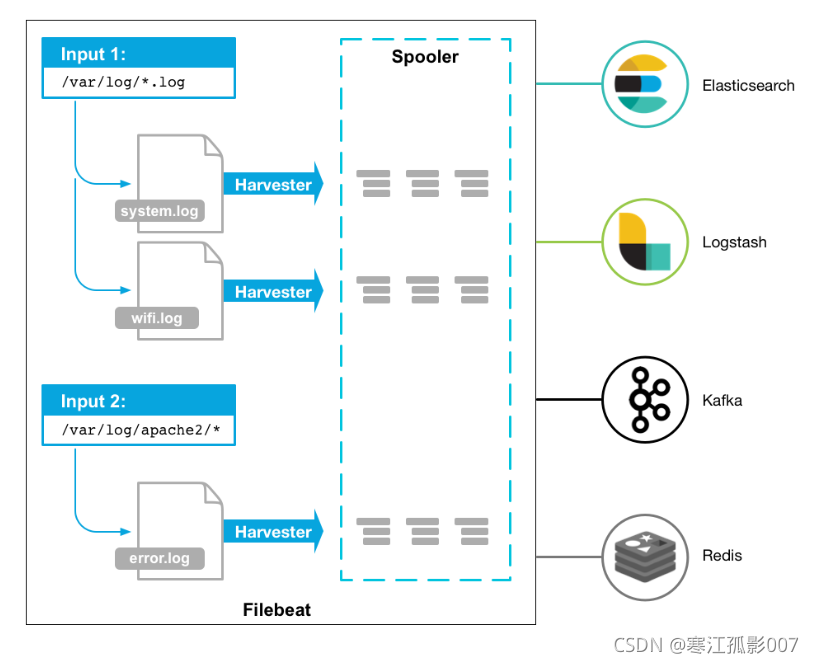
優點
- Filebeat 只是一個二進制檔案沒有任何依賴,它占用資源極少,
缺點
- Filebeat 的應用范圍十分有限,因此在某些場景下咱們會碰到問題,在 5.x 版本中,它還具有過濾的能力,
3)Kafka
kafka能幫助我們削峰,ELK可以使用redis作為訊息佇列,但redis作為訊息佇列不是強項而且redis集群不如專業的訊息發布系統kafka,kafka安裝請看這里,
4)Logstash 過濾
Logstash 主要是用來日志的搜集、分析、過濾日志的工具,支持大量的資料獲取方式,一般作業方式為c/s架構,client端安裝在需要收集日志的主機上,server端負責將收到的各節點日志進行過濾、修改等操作在一并發往elasticsearch上去,
優點
- 可伸縮性
節拍應該在一組Logstash節點之間進行負載平衡,
建議至少使用兩個Logstash節點以實作高可用性,
每個Logstash節點只部署一個Beats輸入是很常見的,但每個Logstash節點也可以部署多個Beats輸入,以便為不同的資料源公開獨立的端點,
- 彈性
Logstash持久佇列提供跨節點故障的保護,對于Logstash中的磁盤級彈性,確保磁盤冗余非常重要,對于內部部署,建議您配置RAID,在云或容器化環境中運行時,建議您使用具有反映資料SLA的復制策略的永久磁盤,
- 可過濾
對事件欄位執行常規轉換,您可以重命名,洗掉,替換和修改事件中的欄位,
缺點
- Logstash耗資源較大,運行占用CPU和記憶體高,另外沒有訊息佇列快取,存在資料丟失隱患,
5)Kibana 展示
Kibana 也是一個開源和免費的工具,Kibana可以為 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以幫助匯總、分析和搜索重要資料日志,
filebeat和logstash的關系
因為logstash是jvm跑的,資源消耗比較大,所以后來作者又用golang寫了一個功能較少但是資源消耗也小的輕量級的logstash-forwarder,不過作者只是一個人,加入http://elastic.co公司以后,因為es公司本身還收購了另一個開源專案packetbeat,而這個專案專門就是用golang的,有整個團隊,所以es公司干脆把logstash-forwarder的開發作業也合并到同一個golang團隊來搞,于是新的專案就叫filebeat了,
二、helm3安裝ELK
詳細流程圖如下:
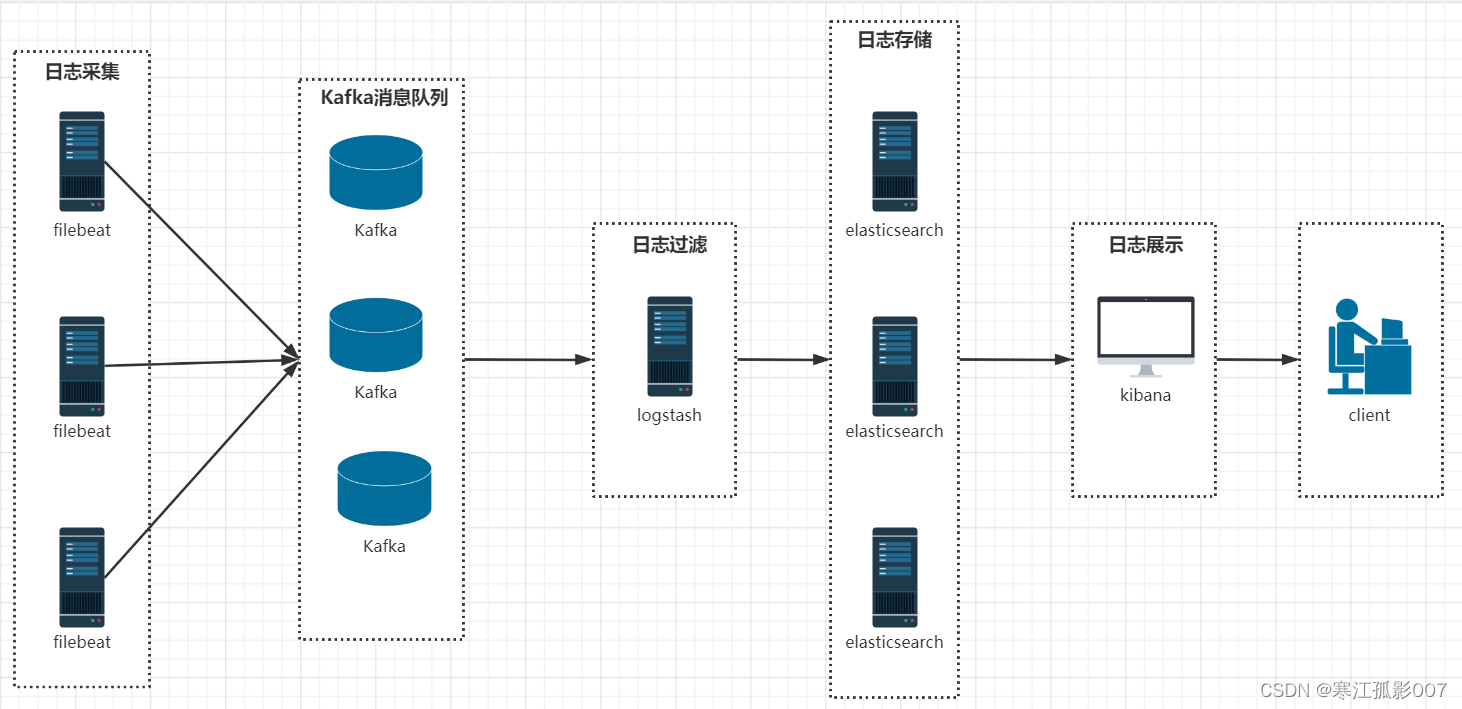
1)準備條件
1、添加helm倉庫
$ helm repo add elastic https://helm.elastic.co
2)helm3安裝elasticsearch
1、自定義values
主要是設定storage Class 持久化和資源限制,本人電腦資源有限,所以這里就把資源調小了很多,小伙伴們可以根據自己配置自定義哈,
$ cat <<EOF> my-values.yaml
resources:
requests:
memory: 1Gi
volumeClaimTemplate:
storageClassName: "bigdata-nfs-storage"
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 3Gi
service:
type: NodePort
port: 9000
nodePort: 31311
EOF
2、開始安裝Elasitcsearch
安裝程序比較慢,因為官方鏡像下載比較慢
$ helm install es elastic/elasticsearch -f my-values.yaml --namespace bigdata

W1207 23:10:57.980283 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
W1207 23:10:58.015416 21465 warnings.go:70] policy/v1beta1 PodDisruptionBudget is deprecated in v1.21+, unavailable in v1.25+; use policy/v1 PodDisruptionBudget
NAME: es
LAST DEPLOYED: Tue Dec 7 23:10:57 2021
NAMESPACE: bigdata
STATUS: deployed
REVISION: 1
NOTES:
1. Watch all cluster members come up.
$ kubectl get pods --namespace=bigdata -l app=elasticsearch-master -w2. Test cluster health using Helm test.
$ helm --namespace=bigdata test es
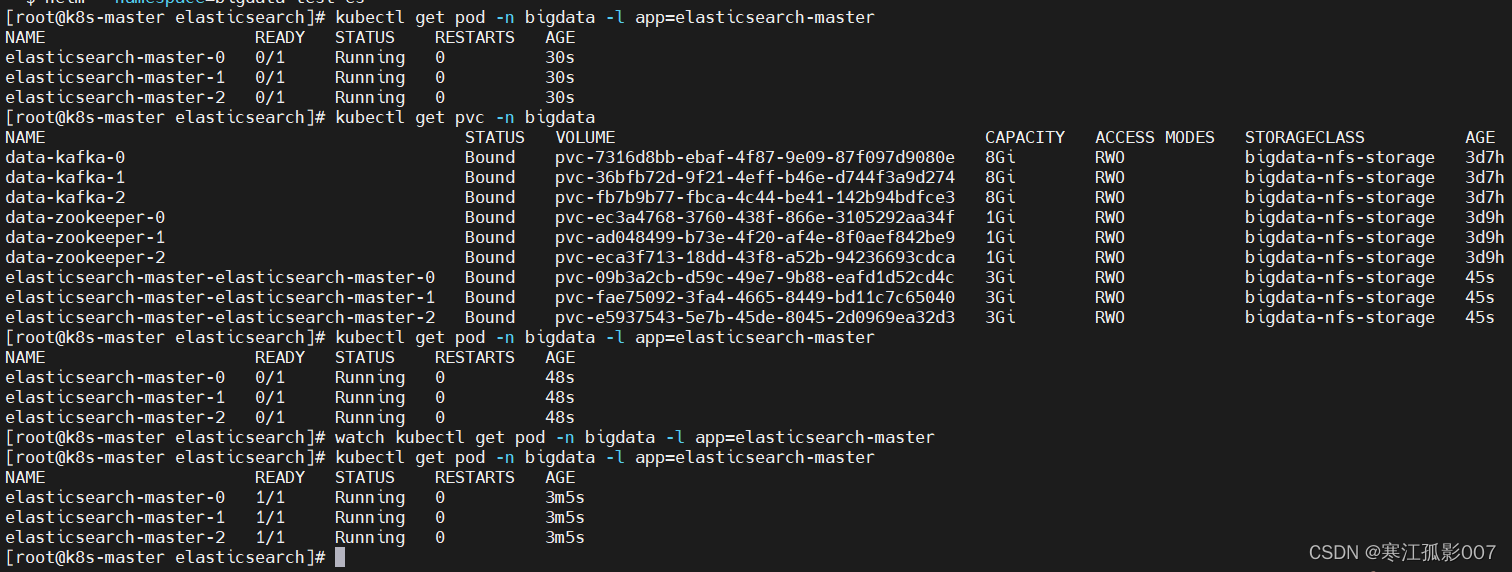
查看,需要所有pod都正常運行才正常,下載鏡像有點慢,需要稍等一段時間再查看
$ kubectl get pod -n bigdata -l app=elasticsearch-master
$ kubectl get pvc -n bigdata
$ watch kubectl get pod -n bigdata -l app=elasticsearch-master
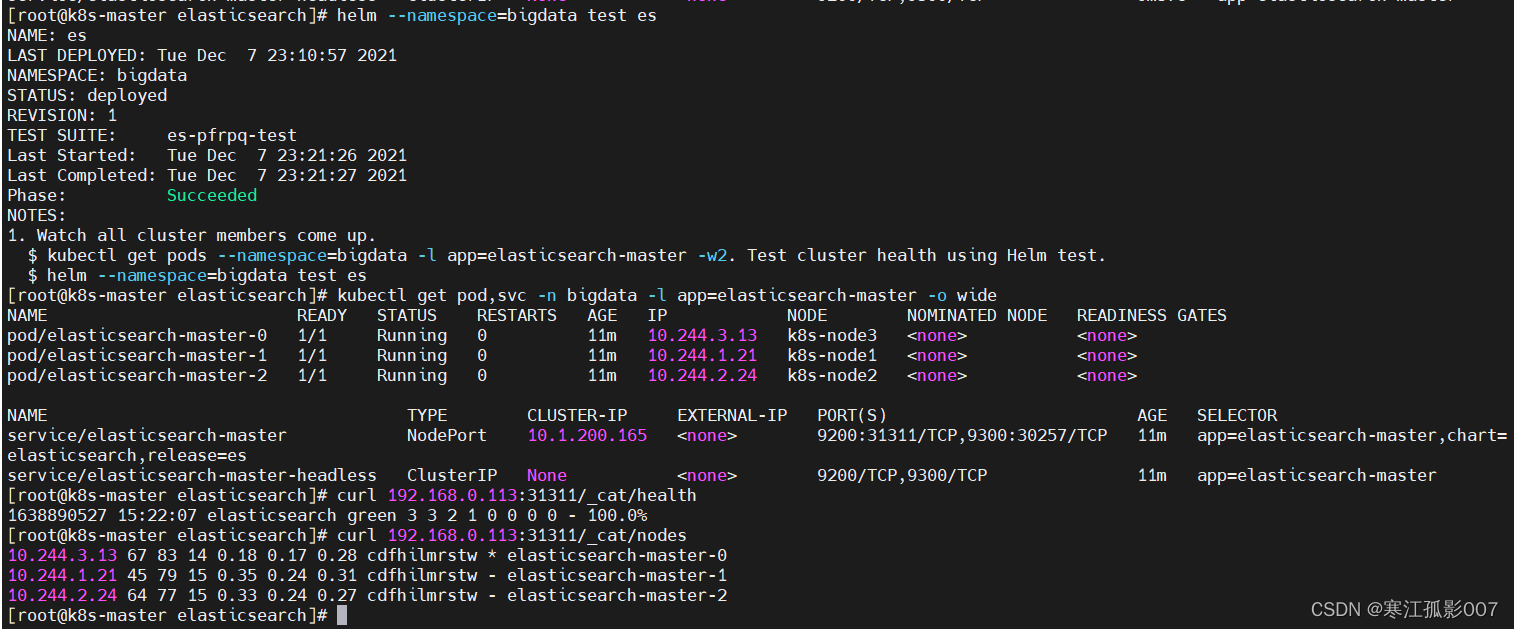
3、驗證
$ helm --namespace=bigdata test es
$ kubectl get pod,svc -n bigdata -l app=elasticsearch-master -o wide
$ curl 192.168.0.113:31311/_cat/health
$ curl 192.168.0.113:31311/_cat/nodes
4、清理
$ helm uninstall es -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-0 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-1 -n bigdata
$ kubectl delete pvc elasticsearch-master-elasticsearch-master-2 -n bigdata
3)helm3安裝Kibana
1、自定義values
$ cat <<EOF> my-values.yaml
#此處修改了kibana的組態檔,默認位置/usr/share/kibana/kibana.yaml
kibanaConfig:
kibana.yml: |
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: [ "http://elasticsearch-master-0:9200","http://elasticsearch-master-1:9200","http://elasticsearch-master-2:9200" ]
resources:
requests:
cpu: "1000m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
service:
#type: ClusterIP
type: NodePort
loadBalancerIP: ""
port: 5601
nodePort: "30026"
EOF
2、開始安裝Kibana
$ helm install kibana elastic/kibana -f my-values.yaml --namespace bigdata

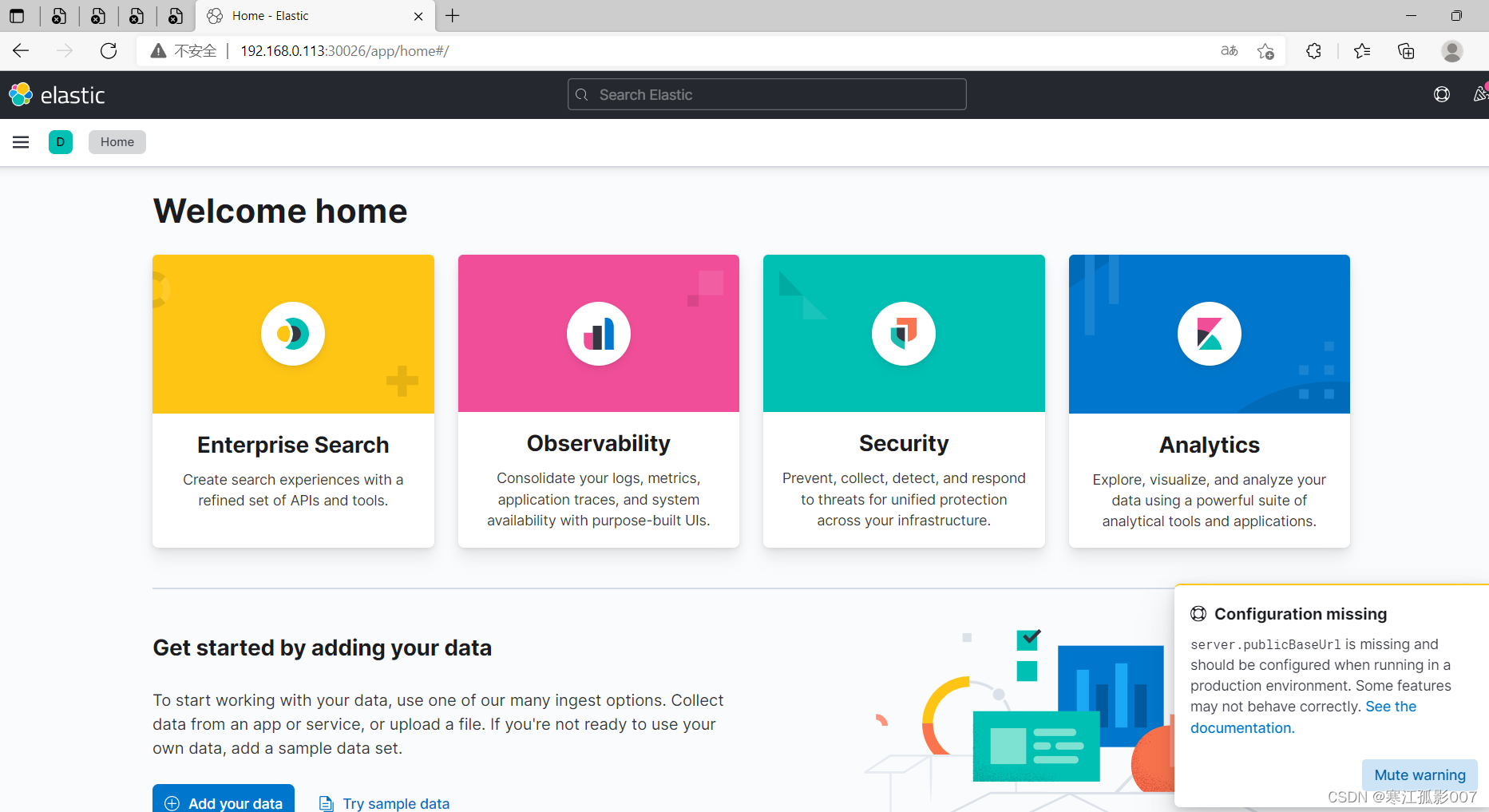
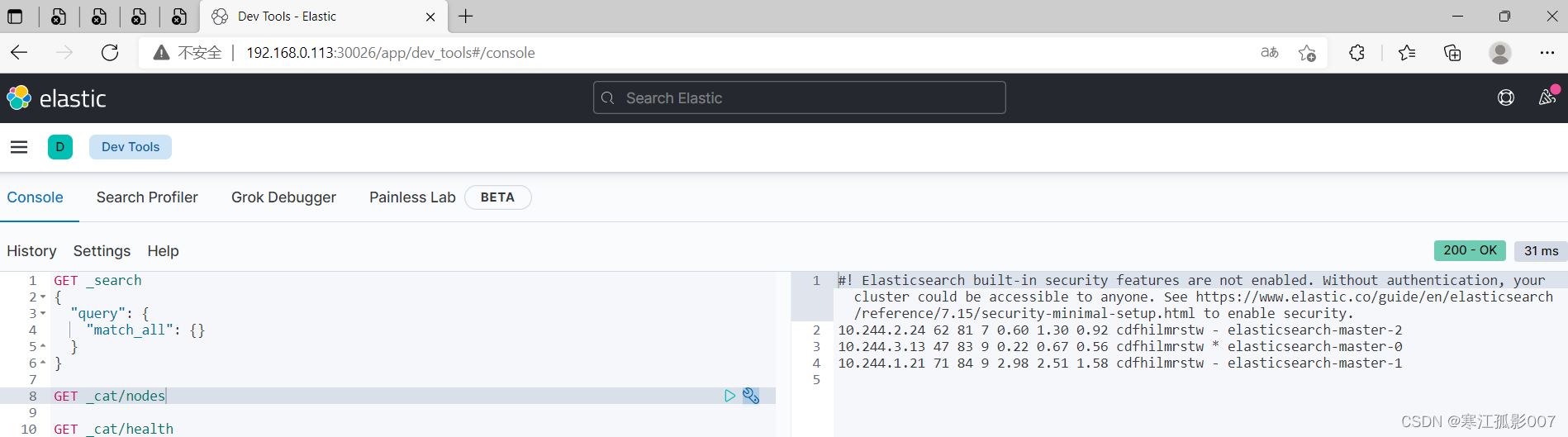
3、驗證
$ kubectl get pod,svc -n bigdata -l app=kibana
瀏覽器訪問:http://192.168.0.113:30026/
4、清理
$ helm uninstall kibana -n bigdata
4)helm3安裝Filebeat
filebeat默認收集宿主機上docker的日志路徑:/var/lib/docker/containers,如果我們修改了docker的安裝路徑要怎么收集呢,很簡單修改chart里的DaemonSet檔案里邊的hostPath引數:
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containers #改為docker安裝路徑
當然也可以自定義values修改,這里推薦自定義values方式修改采集日志路徑
1、自定義values
默認是將資料存盤到ES,這里做修改資料存盤到Kafka,kafka的部署可以看這里
$ cat <<EOF> my-values.yaml
daemonset:
filebeatConfig:
filebeat.yml: |
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
output.elasticsearch:
enabled: false
host: '${NODE_NAME}'
hosts: '${ELASTICSEARCH_HOSTS:elasticsearch-master:9200}'
output.kafka:
enabled: true
hosts: ["kafka-0.kafka-headless.bigdata.svc.cluster.local:9092","kafka-1.kafka-headless.bigdata.svc.cluster.local:9092","kafka-2.kafka-headless.bigdata.svc.cluster.local:9092"]
topic: test
EOF
2、開始安裝Filefeat
$ helm install filebeat elastic/filebeat -f my-values.yaml --namespace bigdata
$ kubectl get pods --namespace=bigdata -l app=filebeat-filebeat -w


3、驗證
# 先登錄kafka客戶端
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
# 再消費資料
$ kafka-console-consumer.sh --bootstrap-server kafka.bigdata.svc.cluster.local:9092 --topic test
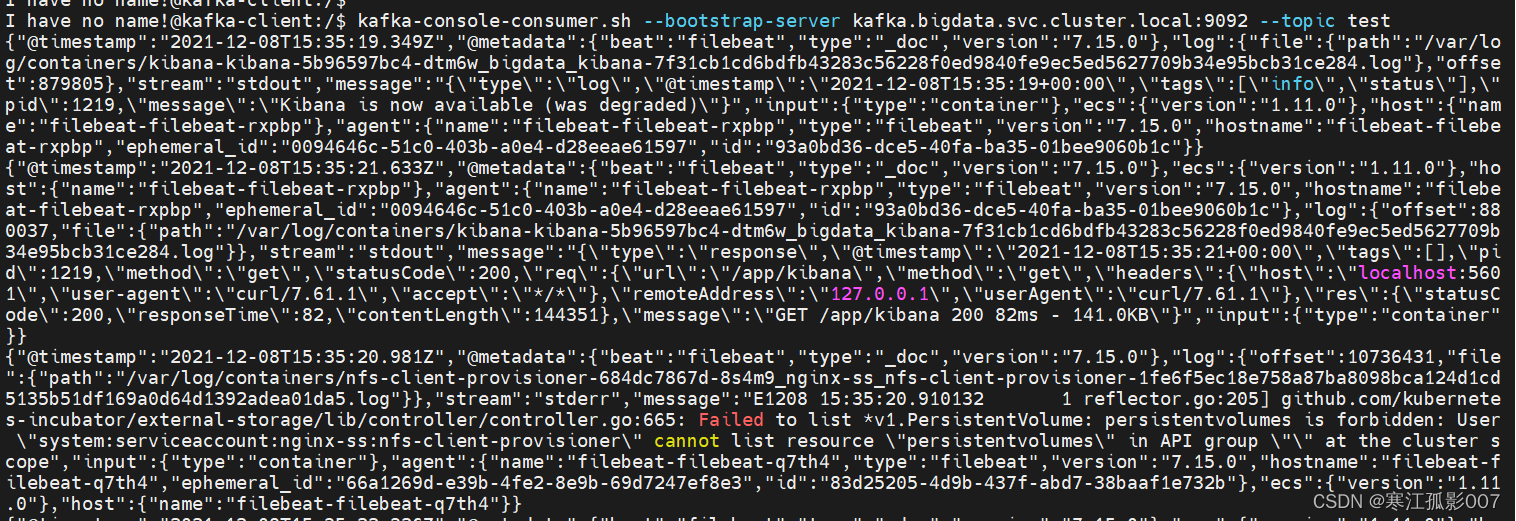
看到已經可以消費資料了,說明資料已經存盤到kafka了,
查看kafka資料積壓情況
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup
發現大量資料都是處于積壓的狀態
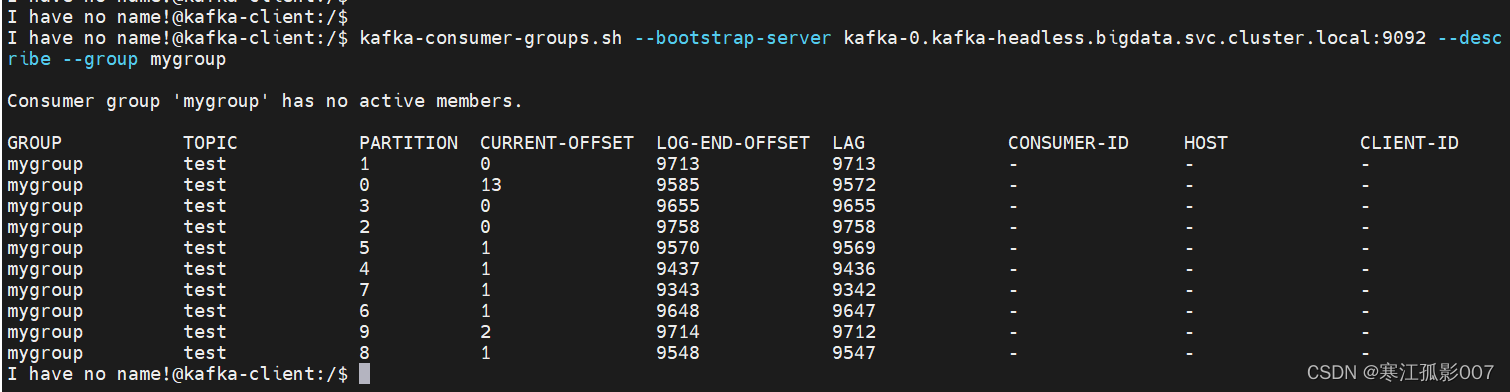
接下來就是部署logstash去消費kafka資料,最后存盤到ES,
4、清理
$ helm uninstall filebeat -n bigdata
5)helm3安裝Logstash
1、自定義values
【注意】記得把ES和kafka的地址換成自己環境的,
$ cat <<EOF> my-values.yaml
logstashPipeline:
logstash.yml: |
input {
kafka {
bootstrap_servers => "kafka-0.kafka-headless.bigdata.svc.cluster.local:9092"
topics => ["test"]
group_id => "mygroup"
#如果使用元資料就不能使用下面的byte位元組序列化,否則會報錯
#key_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
#value_deserializer_class => "org.apache.kafka.common.serialization.ByteArrayDeserializer"
consumer_threads => 1
#默認為false,只有為true的時候才會獲取到元資料
decorate_events => true
auto_offset_reset => "earliest"
}
}
filter {
mutate {
#從kafka的key中獲取資料并按照逗號切割
split => ["[@metadata][kafka][key]", ","]
add_field => {
#將切割后的第一位資料放入自定義的“index”欄位中
"index" => "%{[@metadata][kafka][key][0]}"
}
}
}
output {
elasticsearch {
pool_max => 1000
pool_max_per_route => 200
hosts => ["http://elasticsearch-master-0:9200","http://elasticsearch-master-1:9200","http://elasticsearch-master-2:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
# 資源限制
resources:
requests:
cpu: "100m"
memory: "256Mi"
limits:
cpu: "1000m"
memory: "1Gi"
volumeClaimTemplate:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 3Gi
EOF
output plugin 輸出插件,將事件發送到特定目標:
- stdout :標準輸出,將事件輸出到螢屏上
output{
stdout{
codec => "rubydebug"
}
}
- file :將事件寫入檔案
output{
file {
path => "/data/logstash/%{host}/{application}
codec => line { format => "%{message}"} }
}
}
- kafka :將事件發送到kafka
output{
kafka{
bootstrap_servers => "localhost:9092"
topic_id => "test_topic" #必需的設定,生成訊息的主題
}
}
- elasticseach :在es中存盤日志
output{
elasticsearch {
#user => elastic
#password => changeme
hosts => "localhost:9200"
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
}
2、開始安裝Logstash
$ helm install logstash elastic/logstash -f my-values.yaml --namespace bigdata

$ kubectl get pods --namespace=bigdata -l app=logstash-logstash
3、驗證
1、登錄kibana查看索引是否創建
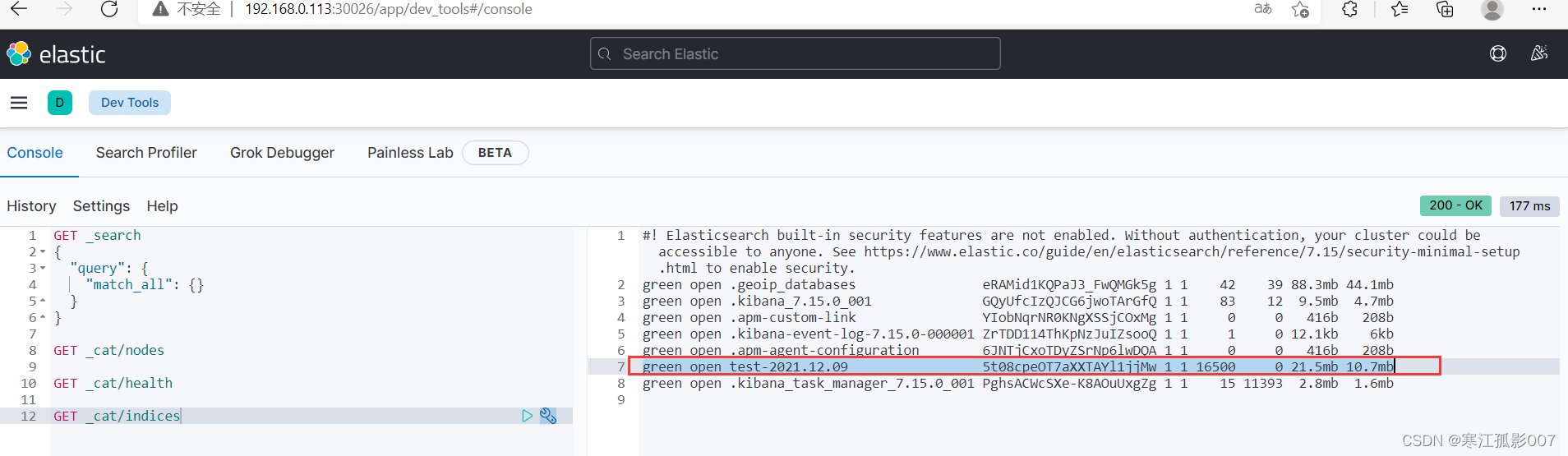
2、查看logs
$ kubectl logs -f logstash-logstash-0 -n bigdata >logs
$ tail -100 logs
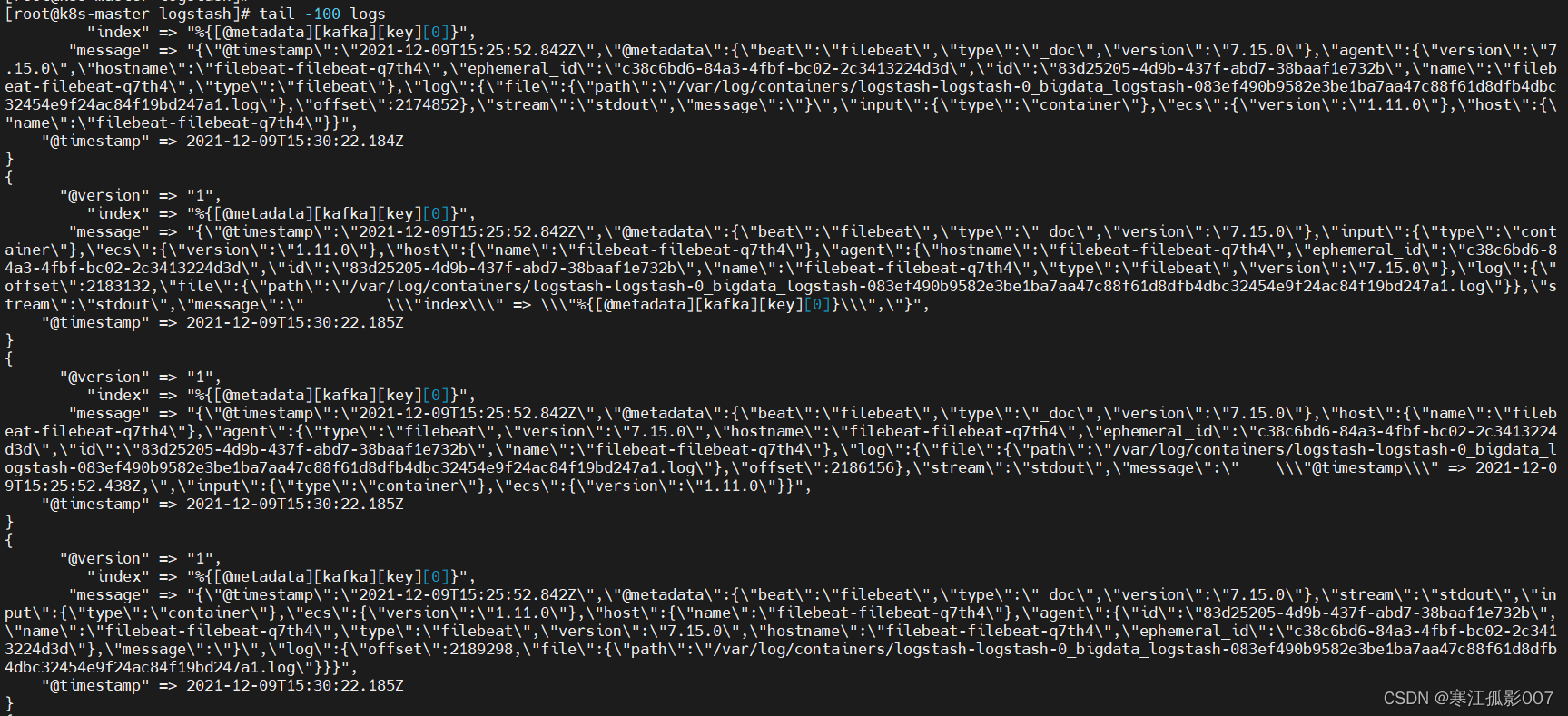
3、查看kafka消費情況
$ kubectl exec --tty -i kafka-client --namespace bigdata -- bash
$ kafka-consumer-groups.sh --bootstrap-server kafka-0.kafka-headless.bigdata.svc.cluster.local:9092 --describe --group mygroup

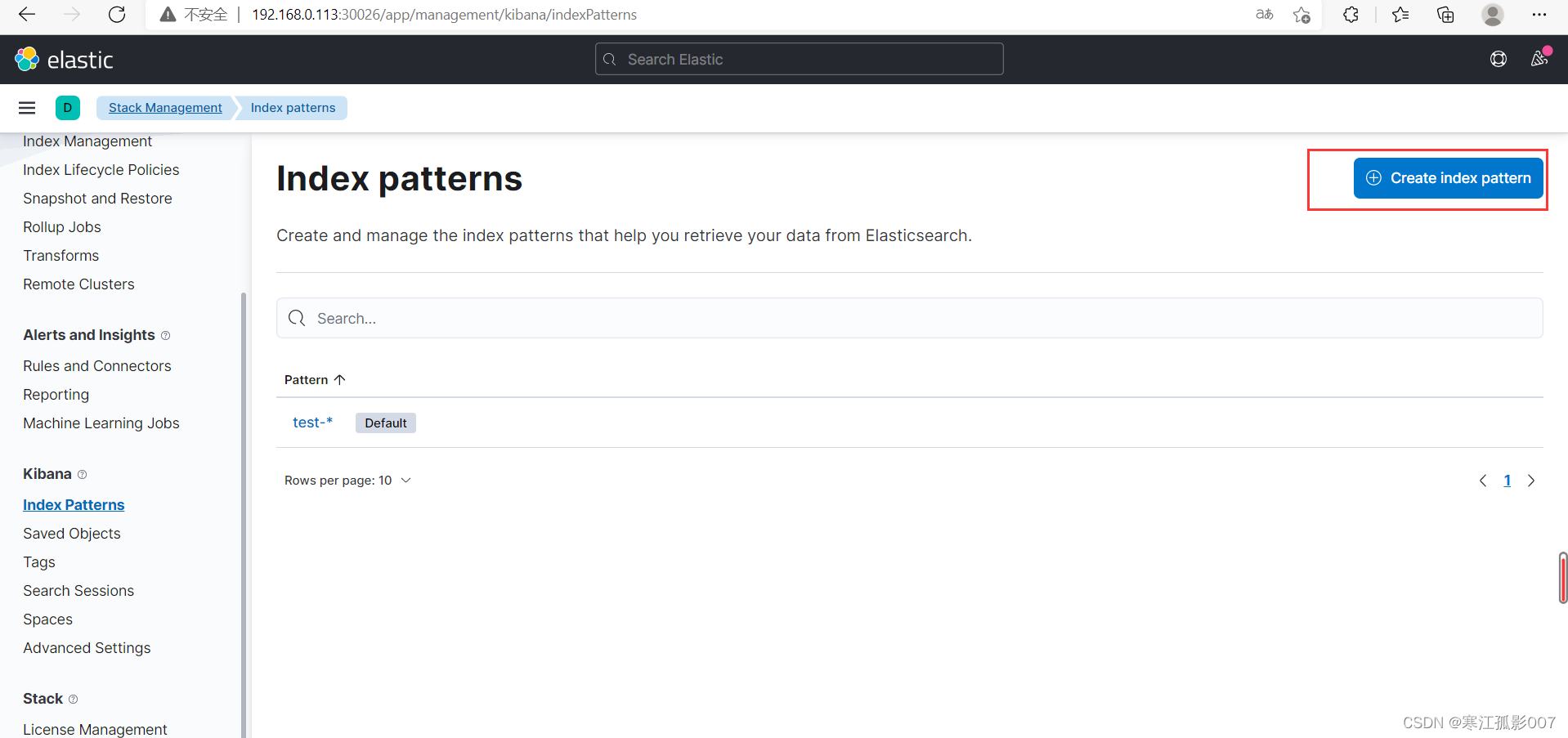
4、通過kibana查看索引資料(Kibana版本:7.15.0)
創建索引模式
Management-》Stack Management-》Kibana-》Index patterns
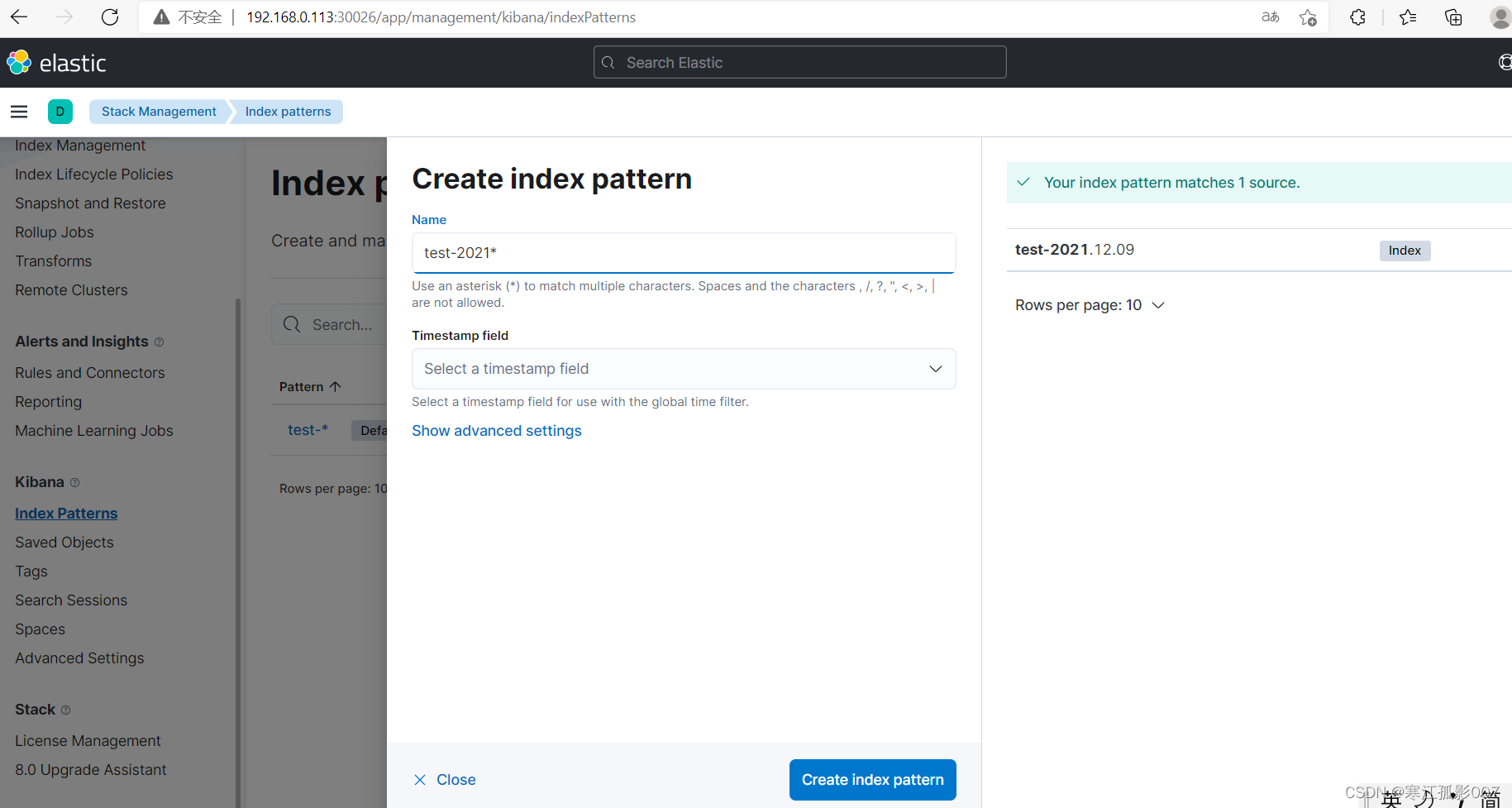
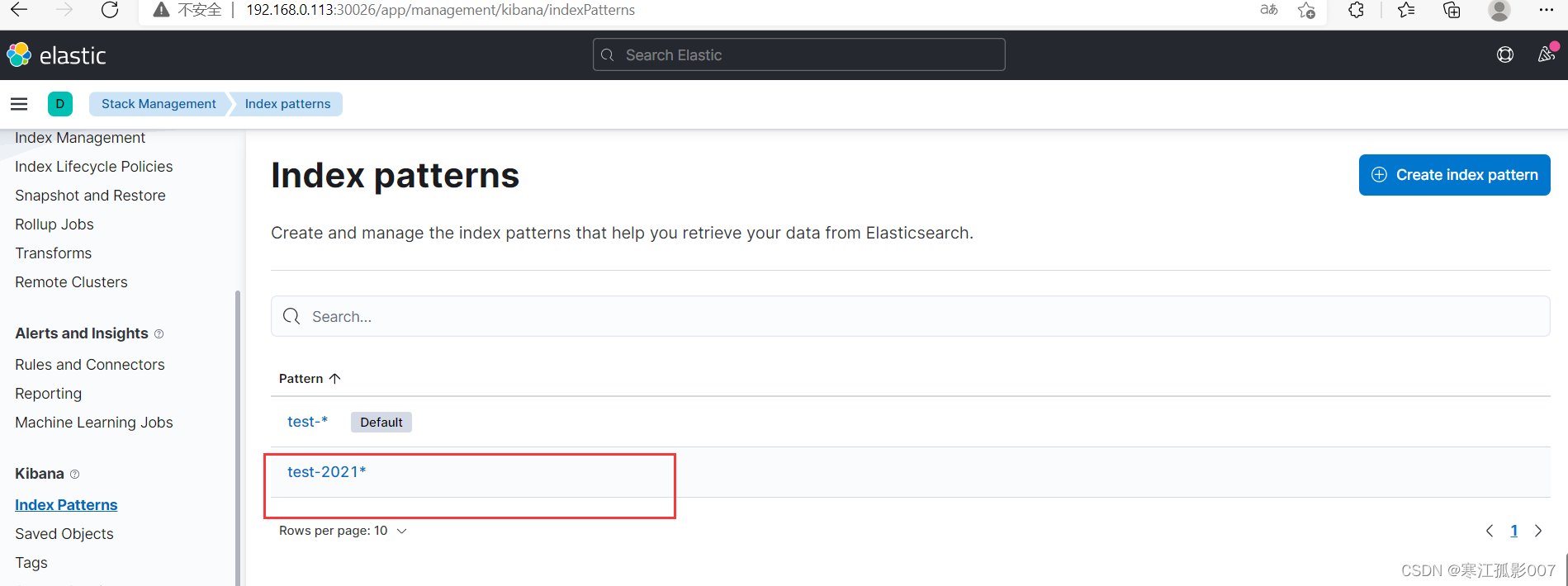
通過上面創建的索引模式查詢資料(Discover)
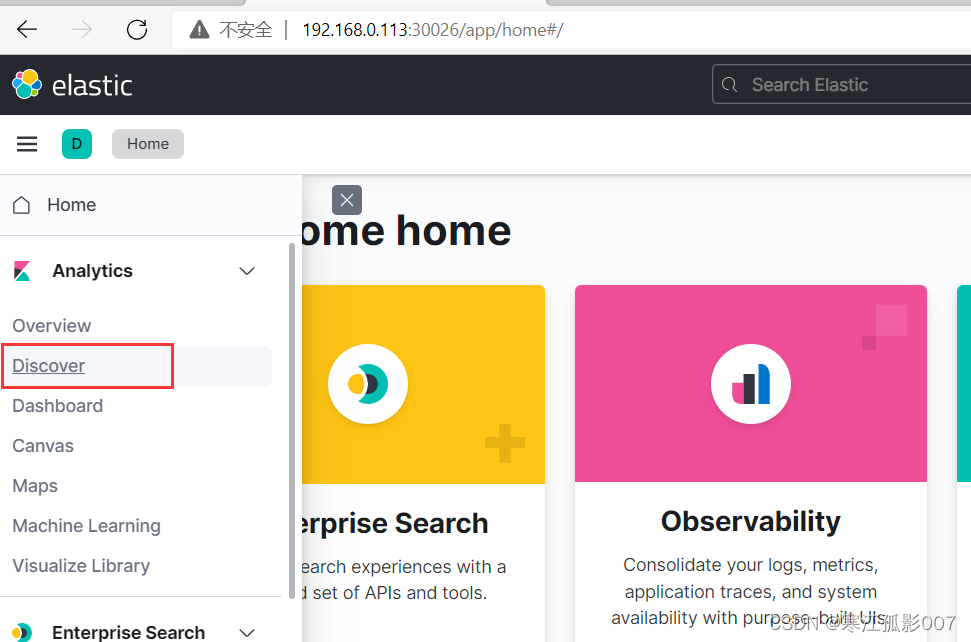
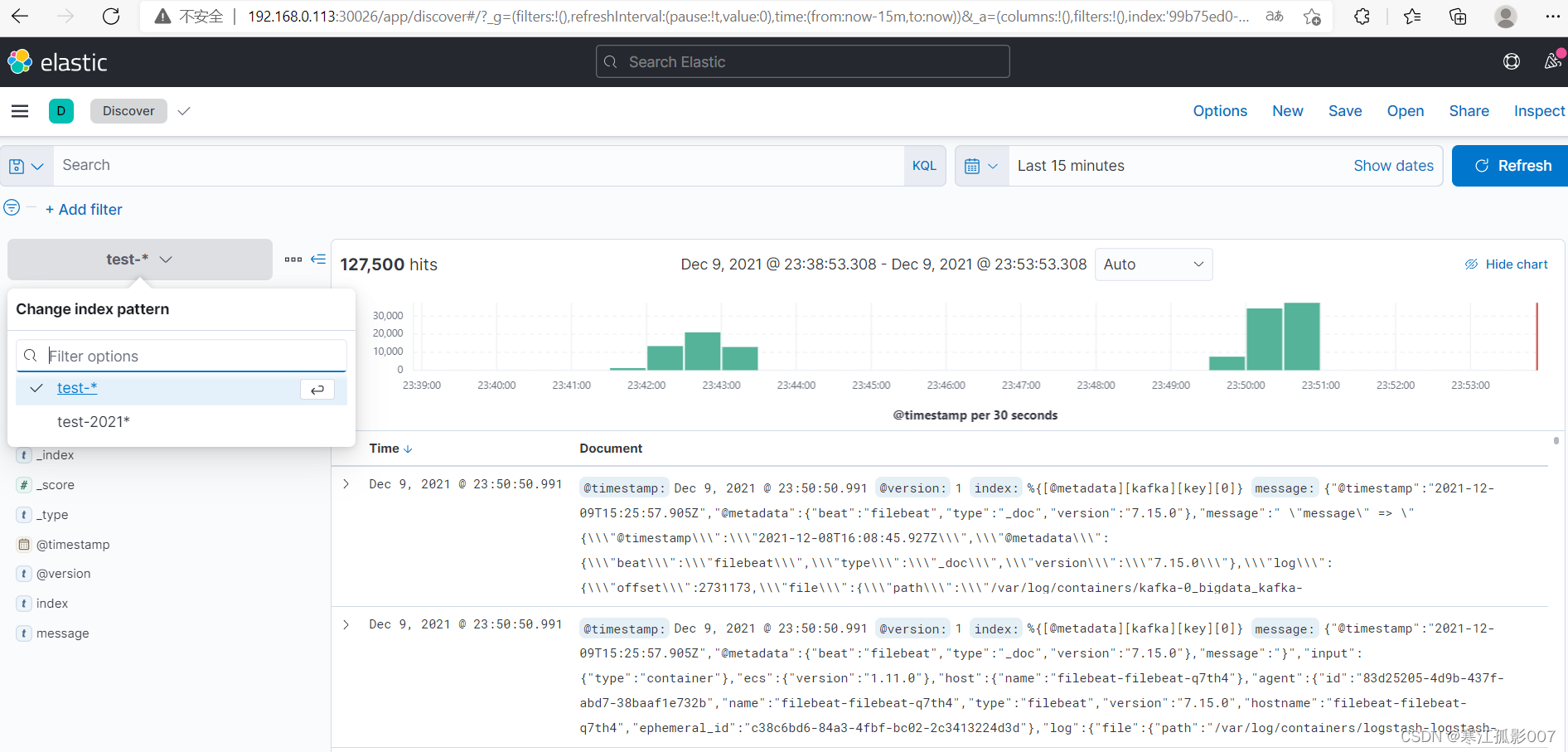
4、清理
$ helm uninstall logstash -n bigdata
三、ELK相關的備份組件和備份方式
Elasticsearch備份兩種方式:
- 將資料匯出成文本檔案,比如通過 elasticdump、esm 等工具將存盤在 Elasticsearch 中的資料匯出到檔案中,適用資料量小的場景,
- 備份 elasticsearch data 目錄中檔案的形式來做快照,借助 Elasticsearch 中 snapshot 介面實作的功能,適用大資料量的場景,
1)Elasticsearch的snapshot快照備份
- 優點:通過snapshot拍攝快照,然后定義快照備份策略,能夠實作快照自動化存盤,可以定義各種策略來滿足自己不同的備份
- 缺點:還原不夠靈活,拍攝快照進行備份很快,但是還原的時候沒辦法隨意進行還原,類似虛擬機快照
1、配置備份目錄
在 elasticsearch.yml 的組態檔中注明可以用作備份路徑 path.repo ,如下所示:
path.repo: ["/mount/backups", "/mount/longterm_backups"]
配置好后,就可以使用 snapshot api 來創建一個 repository 了,如下我們創建一個名為 my_backup 的 repository,
PUT /_snapshot/my_backup
{
"type": "fs",
"settings": {
"location": "/mount/backups/my_backup"
}
}
2、開始通過API介面備份
有了 repostiroy 后,我們就可以做備份了,也叫快照,也就是記錄當下資料的狀態,如下所示我們創建一個名為 snapshot_1 的快照,
PUT /_snapshot/my_backup/snapshot_1?wait_for_completion=true
【溫馨提示】wait_for_completion 為 true 是指該 api 在備份執行完畢后再回傳結果,否則默認是異步執行的,我們這里為了立刻看到效果,所以設定了該引數,線上執行時不用設定該引數,讓其在后臺異步執行即可,
3、增量備份
PUT /_snapshot/my_backup/snapshot_2?wait_for_completion=true
當執行完畢后,你會發現 /mount/backups/my_backup 體積變大了,這說明新資料備份進來了,要說明的一點是,當你在同一個 repository 中做多次 snapshot 時,elasticsearch 會檢查要備份的資料 segment 檔案是否有變化,如果沒有變化則不處理,否則只會把發生變化的 segment file 備份下來,這其實就實作了增量備份,
4、資料恢復
通過呼叫如下 api 即可快速實作恢復功能:
POST /_snapshot/my_backup/snapshot_1/_restore?wait_for_completion=true
{
"indices": "index_1",
"rename_replacement": "restored_index_1"
}
2)elasticdump備份遷移es資料
索引資料匯出為檔案(備份)
# 匯出索引Mapping資料
elasticdump \
--input=http://es實體IP:9200/index_name/index_type \
--output=/data/my_index_mapping.json \ # 存放目錄
--type=mapping
# 匯出索引資料
elasticdump \
--input=http://es實體IP:9200/index_name/index_type \
--output=/data/my_index.json \
--type=data
索引資料檔案匯入至索引(恢復)
# Mapping 資料匯入至索引
elasticdump \
--output=http://es實體IP:9200/index_name \
--input=/home/indexdata/roll_vote_mapping.json \ # 匯入資料目錄
--type=mapping
# ES檔案資料匯入至索引
elasticdump \
--output=http:///es實體IP:9200/index_name \
--input=/home/indexdata/roll_vote.json \
--type=data
可直接將備份資料匯入另一個es集群
elasticdump --input=http://127.0.0.1:9200/test_event --output=http://127.0.0.2:9200/test_event --type=data
type型別
type是ES資料匯出匯入型別,Elasticdump工具支持以下資料型別:
| type型別 | 說明 |
|---|---|
| mapping | ES的索引映射結構資料 |
| data | ES的資料 |
| settings | ES的索引庫默認配置 |
| analyzer | ES的分詞器 |
| template | ES的模板結構資料 |
| alias | ES的索引別名 |
3)esm備份遷移es資料
備份es資料
esm -s http://10.33.8.103:9201 -x "petition_data" -b 5 --count=5000 --sliced_scroll_size=10 --refresh -o=./es_backup.bin
-w 表示執行緒數
-b 表示一次bulk請求資料大小,單位MB默認 5M
-c 一次scroll請求數量
匯入恢復es資料
esm -d http://172.16.20.20:9201 -y "petition_data6" -c 5000 -b 5 --refresh -i=./dump.bin
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/379171.html
標籤:其他