快速背景調查:我正在開展一個將于周五到期的 uni 專案,并且正在處理關于山地探險的三個資料集。一個被命名peaks并包含有關山峰的資訊。另一個被命名expeditions并提供了在這些山峰上發生的各種旅行的資訊。它們都有共同的列peak_name(str)。在 中expeditions,我像這樣計算每個峰的成功率:
exped_peak=expeditions.groupby('peak_name').mean()
peak_success=exped_peak['success']
peak_success
Success是一列填充布林值的列,顯示探險是成功還是失敗。輸出是這樣的: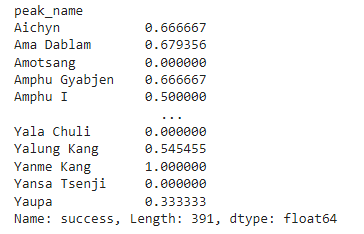
我想在其中創建一個列peaks,給出每個峰值的成功率。我這樣做了:peaks['success_rate']=peaks_success,但我的新列充滿了 NaN 值。我怎樣才能做到正確?
我認為它可能與列“peak_name”有關,但我從未像這樣鏈接過兩個資料幀,所以對我來說有點困惑。誰能告訴我如何使它作業?
謝謝!
uj5u.com熱心網友回復:
您需要根據“peak_name”列將 peak_success 資料框與 peaks 資料框合并,并將其分配回 peaks 資料框。
peaks = peaks.merge(peak_success, how='left', on='peak_name')
這類似于 SQL 中的左連接,其中 merge() 查看每個資料幀中的“peak_name”列,并根據匹配值將“success_rate”列正確對齊到 peaks 資料幀。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/381280.html
下一篇:在熊貓資料框中查找上一個組的名稱