貪心演算法
1)最自然智慧的演算法
2)用一種區域最功利的標準,總是做出在當前看來是最好的選擇
3)難點在于證明區域最功利的標準可以得到全域最優解
4)對于貪心演算法的學習主要以增加閱歷和經驗為主
從頭到尾利用貪心演算法求解
給定一個由字串組成的陣列strs,必須把所有的字串拼接起來,回傳所有可能的拼接結果中,字典序最小的結果
字典序:兩個字串如果要放入字典中,誰放在前面誰的字典序就小,
- 如果兩個字串長度一樣,將其視為K進制的正數進行比較(K=26)
- 如果兩個字串長度不一樣,短的要補的和長的一樣長(補0,0就是比a的ASCII碼還小的一個值),比如 str1=“ac” 和 str2=“b”,str2補齊后為 “b0”,str2雖然低位比str1的低位小,但是高位比str1的大,所以"ac"的字典序比"b"小(“ac”<“b0”)
所以什么是字典序?總的一句話概括就是:兩個個字串一樣長的話,直接當作K進制的正數進行比較;如果兩個字串長度不一樣,短的那一個在后面用0補齊再進行比較,(Java中字串的compareTo方法就是在比字典序)
排序策略1.0:x的字典序 <= y的字典序,x放前;否則,y放前(單獨拿單個字串的字典序拼大小,然后決定誰放前),大多數情況正確,但是本題不行,比如:[ba,b],按照單個字符從字典序來拼大小的話,結果是"bba",但字典序最小的拼接結果是"bab"
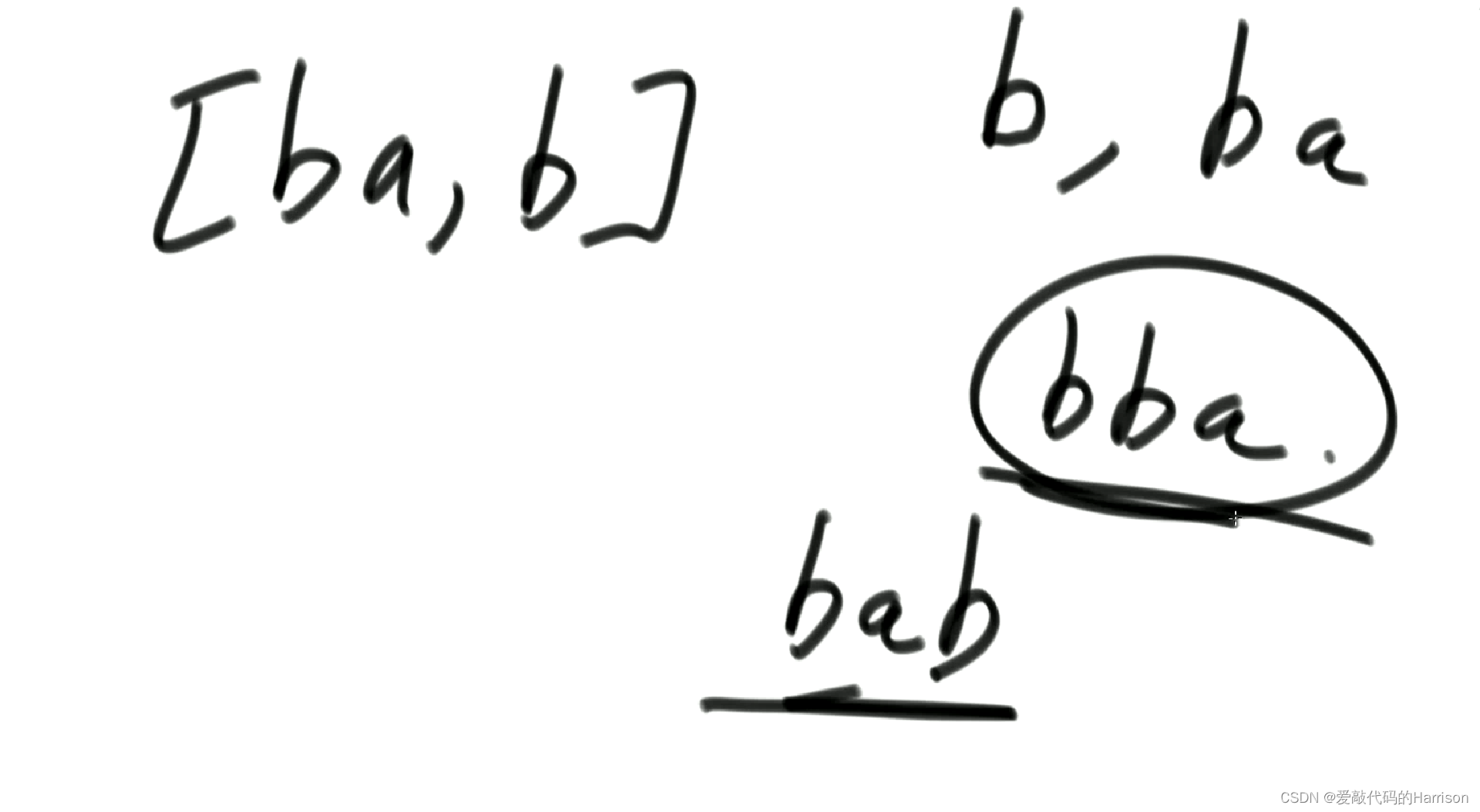
排序策略2.0:x拼接y的字典序 <= y拼接x的字典序,x放前(即x作為前綴比y作為前綴要好);否則,y放前,同樣可以用上圖來舉例,確實是正確的,
但是如果能舉出反例呢?所以怎么證明第二種策略是正確的呢?
證明
排序的傳遞性
雖然生活中常見的列子都天然具有傳遞性,所以很容易忽視,但自己所定義的排序策略不一定具有傳遞性
為什么一定要糾結有沒有傳遞性:證明在陣列中,任何一個在前的和任何一個在后的,都有前結合后 <= 后結合前,(即**[前…后] => 前+后 <= 后+前**)
如何證明:a.b <= b.a && b.c <= c.b --> a.c <= c.a
先弄懂什么是字串拼接:“ks”+“te” --> “kste”,字串就是K進制的正數,K==26,所以就是 “ks” * 26^2 + “te”,( a * K^b長度 + b)
K^(x長度) 記為 m(x)
所以條件1和2分別變為:
- a * m(b) + b <= b * m(a) + a 不等式1
- b * m( c ) + c <= c * m(b) + b 不等式2
不等式1兩側都 減b乘c:a * m(b) * c <= b * m(a) * c + a * c - b * c(因為字串都是正數,所以不等號不用改變方向)
不等式2兩側都 減b乘a:b * m ( c ) * a + c * a - b * a <= c * m (b) * a
所以 b * m ( c ) * a + c * a - b * a <= b * m(a) * c + a * c - b * c
所以 m ( a ) * c - c >= m ( c ) * a - a
所以 m ( a ) * c + a >= m ( c ) * a + c
所以最終證明了排序策略2.0有傳遞性,它可以得到一個序列 [前…后] --> 前+后 <= 后+前
接下來還要證明為什么這個序列最后拼起來的字典序是最小呢?
假設經過排序策略2.0得到一個陣列 […a…b…],先證明一件事情,任何一個在前的字串和任何一個在后的字串,這兩個字串交換位置得到的結果都一定會得到更大的字典序,什么意思?
假設a和b中間有兩個字串 […a…m1…m2…b…],證明所得到的新的序列 […b…m1…m2…a…] 拼起來的字典序一定更大,證明任意兩個調換會更大,任意三個調換會更大,四個…數學歸納法
如何證明:
- 原序列 […a…m1…m2…b…] <= […m1…a…m2…b…],因為 a.m1 <= m1.a(原序列中a在m1前)
- […m1…a…m2…b…] <= […m1…m2…a…b…],因為 a.m2 <= m2.a (原序列中a在m2前)
- […m1…m2…a…b…] <= […m1…m2…b…a…],因為 a.b <= b.a
- […m1…m2…b…a…] <= […m1…b…m2…a…],因為 m2.b <= b.m2
- […m1…b…m2…a…] <= […b…m1…m2…a…],因為 m1.b <= b.m1
回到題目
給定一個由字串組成的陣列strs,必須把所有的字串拼接起來,回傳所有可能的拼接結果中,字典序最小的結果
方法一:全排列暴力解決,時間復雜度O(N!)*O(M),因為兩個字串拼接也有代價(跟字串的平均長度有關),
方法二:用貪心,每一種貪心都有自己獨特的證明,每一個貪心演算法的證明都不一樣,難道一定要通過證明才能找到貪心策略嗎?不用,不通過證明同樣可以得到貪心策略,后面文章會繼續貪心的練習,敬請關注哈哈哈哈!
附上這題完整代碼:
package com.harrison.class09;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.HashSet;
public class Code01_LowestLexicography {
// strs 放著所有的字串
// use 已經使用過的字串的下標,在use里登記過了,不要再使用了
// path 之前已經使用過的字串,拼接成了path
// all 收集所有可能拼接的結果
public static void process1(
String[] strs, HashSet<Integer> use,String path,ArrayList<String> all) {
// 所有字串都已經使用過了,path就是拼接的一種結果
if(use.size()==strs.length) {
all.add(path);
}else {// strs里的字串還沒有使用完,遍歷strs中所有的字串
for(int i=0; i<strs.length; i++) {
if(!use.contains(i)) {// 如果當前的字串是沒有使用過的,將其加入到use里
use.add(i);
// 每一個沒有使用過的字串都這么處理
process1(strs, use, path+strs[i], all);
// 恢復現場!!!(深度優先遍歷的常見做法)
use.remove(i);
}
}
}
}
// 暴力解:全排列
public static String lowestLexicography1(String[] strs) {
if(strs==null || strs.length==0) {
return "";
}
ArrayList<String> all=new ArrayList<>();
HashSet<Integer> use=new HashSet<>();
process1(strs, use, "", all);
String lowest=all.get(0);
for(int i=1; i<all.size(); i++) {
if(all.get(i).compareTo(lowest)<0) {
lowest=all.get(i);
}
}
return lowest;
}
public static class Comparator implements java.util.Comparator<String>{
@Override
public int compare(String a, String b) {
return (a+b).compareTo(b+a);
}
}
public static String lowestLexicography2(String[] strs) {
if(strs==null || strs.length==0) {
return "";
}
Arrays.sort(strs, new Comparator());
String ans="";
for(int i=0; i<strs.length; i++) {
ans+=strs[i];
}
return ans;
}
public static String generateRandomString(int strLen) {
char[] ans = new char[(int) (Math.random() * strLen) + 1];
for (int i = 0; i < ans.length; i++) {
int value = (int) (Math.random() * 5);
ans[i] = (Math.random() <= 0.5) ? (char) (65 + value) : (char) (97 + value);
}
return String.valueOf(ans);
}
public static String[] generateRandomStringArray(int arrLen, int strLen) {
String[] ans = new String[(int) (Math.random() * arrLen) + 1];
for (int i = 0; i < ans.length; i++) {
ans[i] = generateRandomString(strLen);
}
return ans;
}
public static String[] copyStringArray(String[] arr) {
String[] ans = new String[arr.length];
for (int i = 0; i < ans.length; i++) {
ans[i] = String.valueOf(arr[i]);
}
return ans;
}
public static void main(String[] args) {
int arrLen = 6;
int strLen = 5;
int testTimes = 10000;
System.out.println("test begin");
for (int i = 0; i < testTimes; i++) {
String[] arr1 = generateRandomStringArray(arrLen, strLen);
String[] arr2 = copyStringArray(arr1);
if (!lowestLexicography1(arr1).equals(lowestLexicography2(arr2))) {
for (String str : arr1) {
System.out.print(str + ",");
}
System.out.println();
System.out.println("Oops!");
}
}
System.out.println("finish!");
}
}
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/382927.html
標籤:其他
下一篇:i++ 和++i的區別