自然語言處理非常重要的兩個模型, 當我們在讀一句話的時候,首先大腦會記住重要的詞匯,把這中方式放入到自然語言處理任務當中,就根據人腦處理資訊的方式,提出Attention機制,
Attention機制的計算程序
注意力機制模型(Attention):
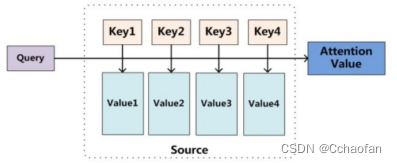
計算程序:第一個程序是根據Q和K計算權重系數,第二個程序根據權重系數對V進行加權求和,
第一個階段,可以引入不同函式和計算機制,根據Q和K,計算兩者的相似性和相關性,可以根據以下方法:
 第二個階段引入類似的softmax的計算方式對第一階段得分進行數值轉換,一方面可以進行歸一化,計算所有元素權重之和為1,另一方面可以通過softmax突出元素的權重,
第二個階段引入類似的softmax的計算方式對第一階段得分進行數值轉換,一方面可以進行歸一化,計算所有元素權重之和為1,另一方面可以通過softmax突出元素的權重,
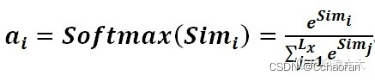
第三階段,通過計算結果a和V對應的權重系數,然后加權求和得到Attention數值:
![]()
簡單總結:
Self-attention自注意力機制
計算程序:
- 將輸入的單詞轉化成嵌入向量
- 根據嵌入的向量得到,q,k,v三個向量
- 計算每一個向量score:score=q.k
- Transformer使用了score歸一化,除以 根號下d.k
- 對score,進行 softmax激活函式
- Softmax點乘V,得到加權的每個輸入向量評分
- 相加之后得到最終結果z:z=∑v
Self-attention 詳細講解:
Self-attention會提出三個新的向量,在論文中向量的維度是512,把這三個向量分別稱為q,k,v,是通過embedding向量與矩陣相乘得到的,矩陣是隨機初始化的,維度(64,512),
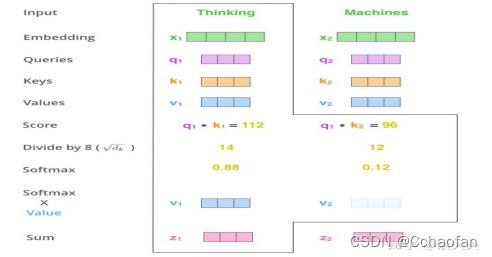
計算self-attention的分數值,該分數決定了我們在某個位置encode一個詞時,對輸入句子的其他部分的關注程度,計算方法是q.k.以下圖為例,首先對Thinking詞,計算其他詞對該詞的一個分數值,首先針對自己本身q1.k1,然后針對第二個詞q1.q2
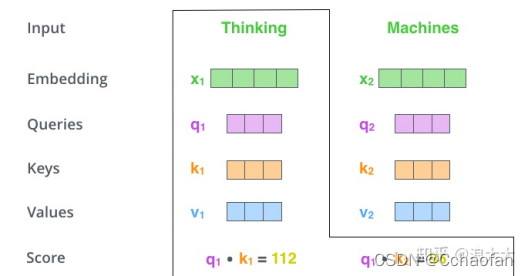 、
、
然后把結果除以一個常數,一般采用第一個維度的開方,這里是8,然后把得到的結果做一個softmax的計算,得到的結果做一個softmax的計算,得到的結果是每個詞對當前位置的詞的相關性,當前位置的詞相關性會很大,
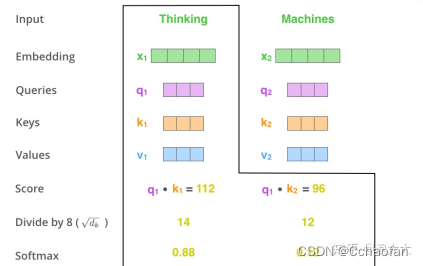
把v和softmax得到的值相乘,并相加,得到的結果是self-attention在當前節點的值
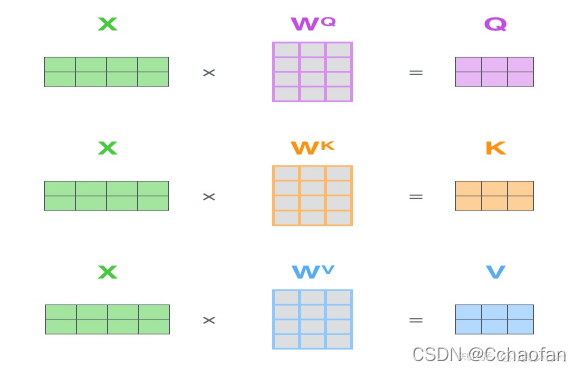
在實際應用的場景,為了提高計算速度,我們采用矩陣的方式,直接計算出q,k,v的矩陣,然后把embedding的值與三個矩陣直接相乘,把得到的新矩陣q和k相乘,乘以一個常數,做softmax,最后乘上v矩陣
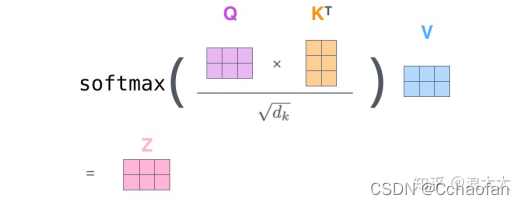
注意力機制的優點:引數少,速度快,效果好
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/384323.html
標籤:其他
上一篇:R語言ggplot2可視化:通過水平半小提琴圖和抖動資料點可視化雨云圖(Rain Cloud plots)、自定義雨云圖中資料點的顏色(資料點的顏色和半小提琴圖一致)
下一篇:vector模擬實作