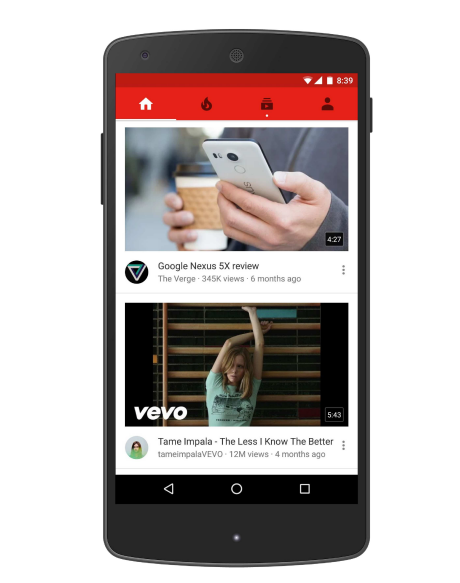
YouTube是世界上最大的創建、分享和發現視頻內容的平臺,YouTube的建議負責幫助超過10億用戶從不斷增長的視頻語料庫中發現個性化內容,在本文中,我們將重點關注深度學習最近對YouTube視頻推薦系統所產生的巨大影響,該圖說明了在YouTube移動應用程式主頁上的建議,從三個主要的角度來看,推薦YouTube上的視頻是極具挑戰性的:
- 規模:許多現有的推薦演算法被證明適用于小問題,但都不能在我們的規模上運行,高度專業化的分布式學習演算法和高效的服務系統對于處理YouTube龐大的用戶群和語料庫至關重要,
- 新鮮度:YouTube有一個非常動態的語料庫,每秒可以上傳很多小時的視頻,推薦系統應該有足夠的回應能力,以模擬新上傳的內容以及用戶所采取的最新行動,平衡新內容有了完善的視頻,就可以從探索/開發的角度來理解,
- 噪聲:由于稀疏性和各種難以觀察到的外部因素,在YouTube上的歷史用戶行為本質上難以預測,我們很少得到用戶滿意度的基本真相,而是建模有噪聲的隱式反饋信號,此外,與內容相關聯的元資料結構不佳,而沒有一個定義良好的本體,我們的演算法需要對我們的訓練資料的這些特殊特征具有魯棒性,
YouTube推薦系統架構如下:
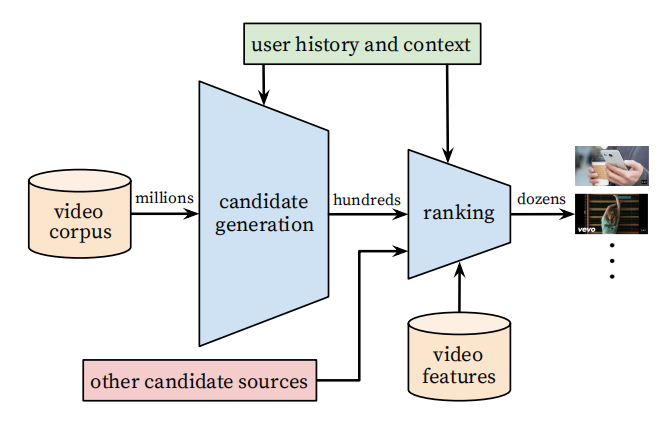
- Candidate Generation:這個部分相當于召回層,從幾億視頻語料庫中篩選出幾百個候選視頻
- Ranking:這個部分對于海選出的幾百個視頻進行精排,加入更加細粒化的特征用于構建模型,進而找出評分最高的topN視頻推薦給用戶
Candidate Generation DNN模型
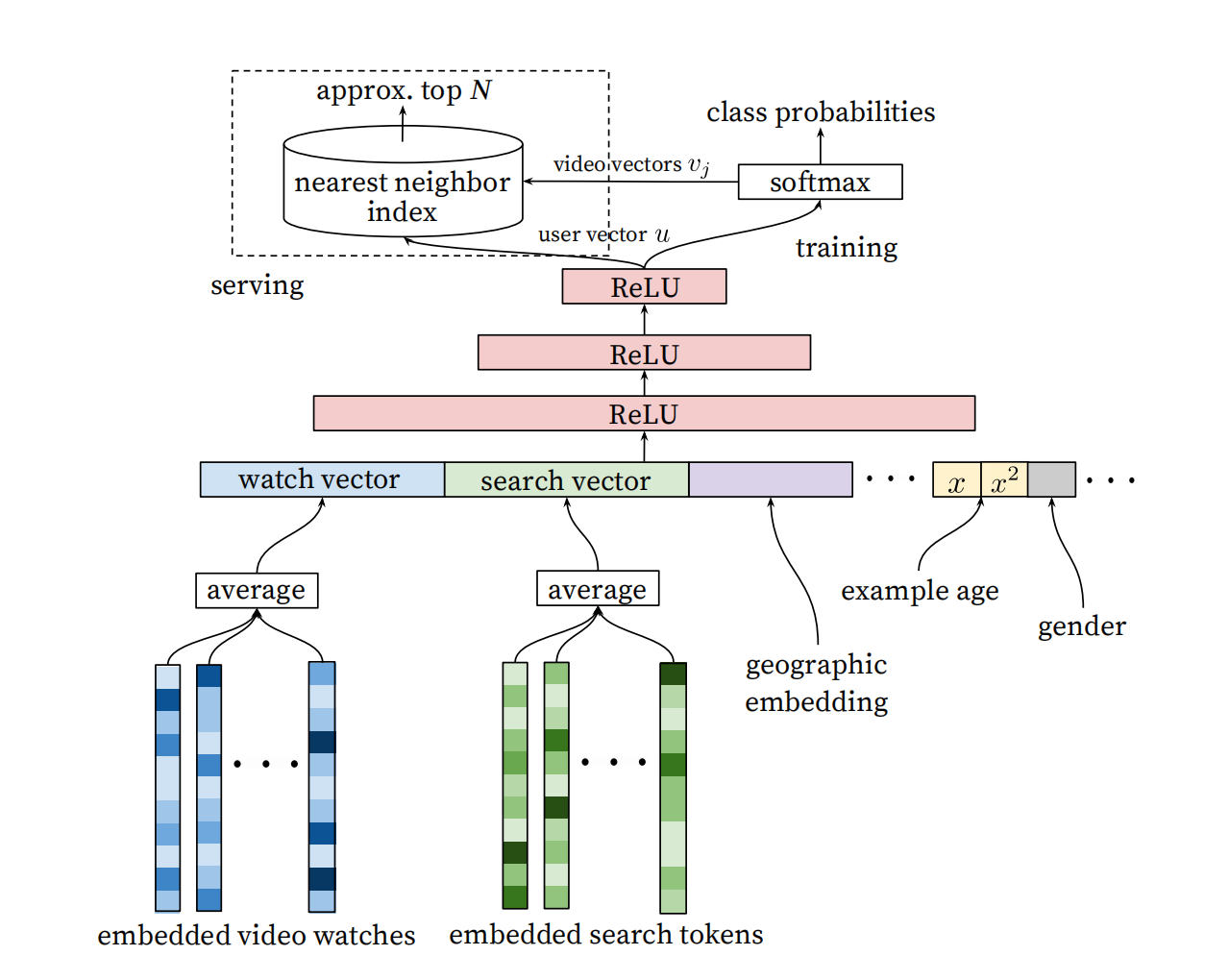
DNN輸入層的特征總共分為3個部分:
- embedde video watches:該特征為所有video的特征資訊,這里為了將其統一輸入模型進行了Embedding處理,然后使用平均池化Embedding
- embedded search tokens:該特征使用戶搜索詞進行Embedding處理
- 用戶特征:包括用戶的年齡、性別等粗粒化的特征資訊
之后將這3部分的Embedding向量進行橫向拼接,然后送入后面的MLP層,進行訓練,這里YouTube是將預測作為多分類,分別對應幾百萬個視頻的概率情況,也就是SoftMax,
Ranking DNN模型
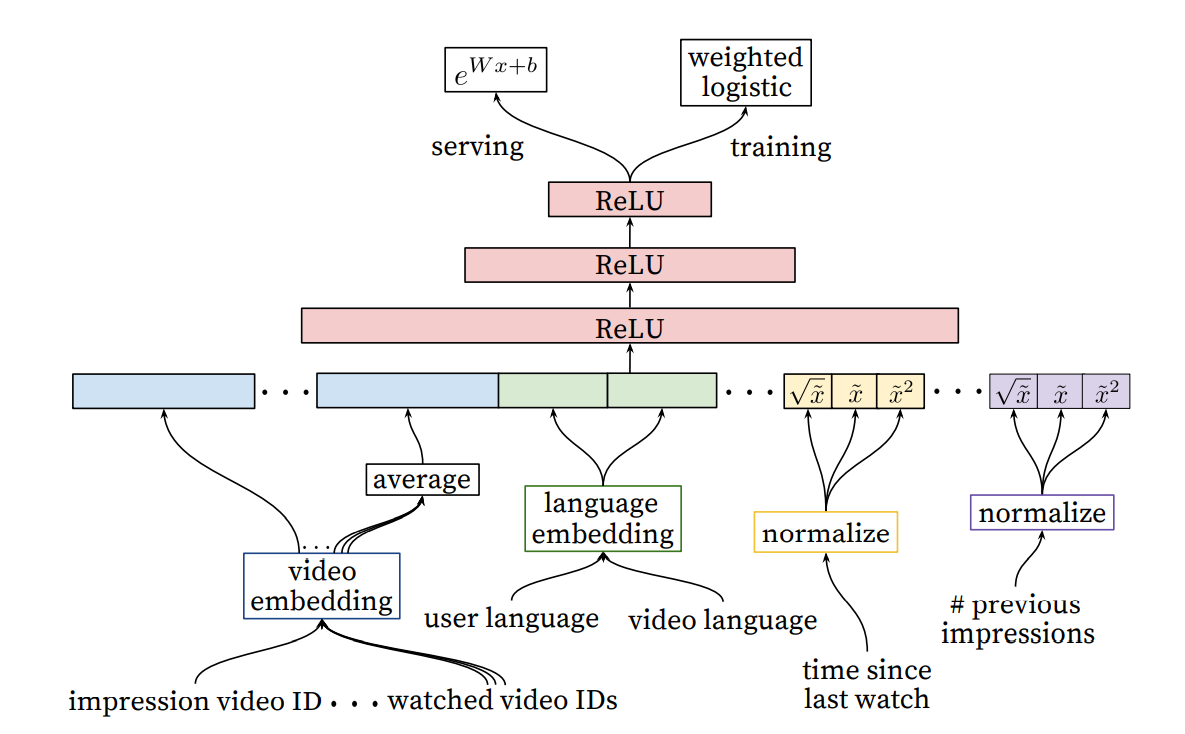
DNN輸入層的特征總共分為5個部分:
- impression video ID:候選視頻的特征資訊,這里將其進行Embedding
- watched video IDs:用戶已經看過的視頻的特征資訊,將每個看過的視頻進行平均化Embedding
- language embedding:該特征是候選視頻的語言和用戶的語言的Embedding
- time since last watch:用戶上次看相似視頻的時間
- previous impressions:用戶先前看過的候選視頻
YouTube推薦模型架構的十大工程問題
這里是看了王喆老師的文章獲得的感想,將其總結記錄
1、文中把推薦問題轉換成多分類問題,在next watch的場景下,每個video都會是一個分類,因此總共的分類將會有數百萬之巨,這在使用softmax訓練時無疑是非常低效的,這個問題YouTube是如何解決的?
YouTube團隊進行了負采樣并采用importance weighting的方法對采用進行calibration,
2、在candidate generation model的serving程序中,YouTube為什么不直接采用訓練時的model進行預測,而是采用了一種最近鄰搜索的方法?
由于在model serving程序中對幾百萬個候選集逐一跑一遍模型的時間開銷顯然太大了,因此在通過candidate generation model得到user 和 video的embedding之后,通過最近鄰搜索的方法的效率高很多,只需要將用戶和視頻的Embedding存到記憶體即可,
3、Youtube的用戶對新視頻有偏好,那么在模型構建的程序中如何引入這個feature?
模型引入了“Example Age”這個特征,它代表著視頻距離當前的發布時間間隔,
4、在對訓練集的預處理程序中,YouTube沒有采用原始的用戶日志,而是對每個用戶提取等數量的訓練樣本,這是為什么?
這是為了減少高度活躍用戶對于loss的過度影響,
5、YouTube為什么不采取類似RNN的Sequence model,而是完全摒棄了用戶觀看歷史的時序特征,把用戶最近的瀏覽歷史等同看待,這不會損失有效資訊嗎?
會導致模型過度擬合上個時間段的資料,如果一個用戶剛剛點開某個領域的視頻,會導致模型過度推薦這個領域的視頻給用戶造成不好的體驗感,
6、在處理測驗集的時候,YouTube為什么不采用經典的隨機留一法(random holdout),而是一定要把用戶最近的一次觀看行為作為測驗集?
主要是為了避免引入future information,產生與事實不符的資料穿越,
7、在確定優化目標的時候,YouTube為什么不采用經典的CTR,或者播放率(Play Rate),而是采用了每次曝光預期播放時間(expected watch time per impression)作為優化目標?
因為 watch time更能反應用戶的真實興趣,從商業模型角度出發,因為watch time越長,YouTube獲得的廣告收益越多,而且增加用戶的watch time也更符合一個視頻網站的長期利益和用戶粘性,
8、在進行video embedding的時候,為什么要直接把大量長尾的video直接用0向量代替?
把大量長尾的video截斷掉,主要還是為了節省online serving中寶貴的記憶體資源,
9、針對某些特征,比如#previous impressions,為什么要進行開方和平方處理后,當作三個特征輸入模型?
這是為了引入非線性特征,提高模型的擬合能力,
10、為什么ranking model不采用經典的logistic regression當作輸出層,而是采用了weighted logistic regression?
我們已經知道模型采用了expected watch time per impression作為優化目標,所以如果簡單使用LR就無法引入正樣本的watch time資訊,因此采用weighted LR,將watch time作為正樣本的weight,在線上serving中使用e(Wx+b)做預測可以直接得到expected watch time的近似,完美,
參考文章
王喆-YouTube推薦系統
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/386534.html
標籤:其他
下一篇:Nginx學習筆記(1).尚硅谷