shell編程
概述
Shell是一個命令列解釋器,它接收應用程式/用戶命令,然后呼叫作業系統內核

Shell還是一個功能相當強大的編程語言,易撰寫、易除錯、靈活性強,
注:Centos默認決議器時bash
shell腳本入門
#!/root/bash
echo "hello Word!!"
執行:
- **方式一:**采用bash或sh+腳本的相對路徑或絕對路徑(不用賦予腳本+x權限)
- **方式二:**采用輸入腳本的絕對路徑或相對路徑執行腳本(必須具有可執行權限+x)
變數
-
系統變數:使用工具查看所屬位置
H O M E 、 HOME、 HOME、PWD、 S H E L L 、 SHELL、 SHELL、USER等
-
自定義變數
-
定義變數 變數名=變數值,注:定義變數不能有空格,做特殊處理,一切皆字串
-
撤銷變數 unset 變數名
-
靜態變數 readonly D=10 注:不能直接更改,也不能直接撤銷,除非直接重新加載
-
變數如果有空格,需要使用單引號或雙引號
-
提升全域變數,使用export,可以讓其他shell使用
[root@pier shells]# export B [root@pier shells]# ./helloworld.sh helloworld 10 -
變數規則: 和Java類似 環境變數名建議大寫
單引號雙引號,基本上類似于編程語言中的參考字串
區別在于單引號’ '內剝奪所有字符的特殊含義,所有字符都是單純的字串而沒有特殊功能,比如$取引數等命令都是無效的
而雙引號" "中除了字串,特殊字符是沒有被轉義的,$等特殊字符一樣可以使用其功能,
反引號``是命令替換,通常用于把命令輸出結果傳給入變數中,類似變數后$=(命令)如:
-
-
特殊變數
- $n (功能描述,n為數字,%0代表該腳本名稱,$1-
9
代
表
第
一
到
第
九
個
參
數
,
十
以
上
的
參
數
需
要
用
大
括
號
包
含
,
如
9代表第一到第九個引數,十以上的引數需要用大括號包含,如
9代表第一到第九個參數,十以上的參數需要用大括號包含,如{10})
- 例:
vim param.sh
- 例:
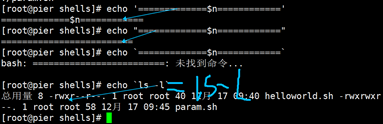
#!/bin/bash echo '=============$n============' echo $0 echo $1 echo $2 :wq執行
[root@pier shells]# ./param.sh a b =============$n============ ./param.sh a b- $# 列印執行腳本時傳入變數的個數
- $* / $@ 列印傳入變數
- $? 判斷上一次命令是否正確0為true 非0為false
- $n (功能描述,n為數字,%0代表該腳本名稱,$1-
9
代
表
第
一
到
第
九
個
參
數
,
十
以
上
的
參
數
需
要
用
大
括
號
包
含
,
如
9代表第一到第九個引數,十以上的引數需要用大括號包含,如
9代表第一到第九個參數,十以上的參數需要用大括號包含,如{10})
運算子
加上(())或者[]就可以正常運行了
條件判斷
基礎語法
-
test condition
[ condition ](注意判別式前后一定要有空格)
常用判斷條件
- 1、兩個整數之間的判斷
| 比較 | 符號 | 來源記憶 |
|---|---|---|
| 大于 | -gt | greater than |
| 大于等于 | -ge | grreater equal |
| 小于 | -lt | less than |
| 小于等于 | -le | less equal |
| 等于 | -eq | equal |
| 不等于 | -ne | not equal |
實操:
判斷2和3的大小:
[root@pier shells]# [ 2 -gt 3 ]
[root@pier shells]# echo $?
1
[root@pier shells]# [ 2 -lt 3 ]
[root@pier shells]# echo $?
0
- 2、字串之間的比較
- ==
實操,判斷字串s="== n = = " 和 s 1 = ′ = = n=="和s1='== n=="和s1=′==n=='是否一致
[root@pier shells]# s="==$n=="
[root@pier shells]# s1='==$n=='
[root@pier shells]# [ s1==s ]
[root@pier shells]# echo $?
0
[root@pier shells]# echo '==$n=='
==$n==
[root@pier shells]# echo "==$n=="
====
這里就讓我不解了,于是,我們找找為什么會出現相同的呢?
我貌似有一點點的傻,這個引數,在賦值的時候,僅僅是一個字串,我們在判斷的時候,也只是判斷這兩個字串是否一樣,二并沒有去執行,因此,在下面的echo輸出結果不一致,二在比較s和s1兩個字串是判斷為正確,
- 3、按照檔案權限進行判斷
- -r 有讀的權限(read)
- -w 有寫的權限(write)
- -x 有執行的權限 (execute)
實操:
[root@pier shells]# test -x 200
[root@pier shells]# echo $?
1
[root@pier shells]# ll
總用量 8
-rw-r--r--. 1 root root 0 12月 17 10:39 200
- 4、按照檔案型別進行判斷
- -f檔案存在并且是一個常見的檔案(file)
- -e 檔案存在(existence)
- -d 檔案存在并且是一個目錄(directory)
實操:判斷檔案abc是否存在,abd呢?
[root@pier shells]# [ -e abc ]
[root@pier shells]# echo $?
0
[root@pier shells]# ll
總用量 8
-rw-r--r--. 1 root root 0 12月 17 10:39 200
drwxr-xr-x. 2 root root 6 12月 17 15:20 abc
-rwxr--r--. 1 root root 40 12月 17 09:40 helloworld.sh
-rwxrwxr--. 1 root root 151 12月 17 10:29 param.sh
[root@pier shells]# [ -e abd ]
[root@pier shells]# echo $?
1
- 5、多重判斷
- || && 運算,和Java類似
實操:
[root@pier shells]# [ 100 -lt 200 ] && [ 100 -gt 50 ]
[root@pier shells]# echo $?
0
[root@pier shells]# [ 100 -lt 200 ] && [ 100 -lt 50 ]
[root@pier shells]# echo $?
1
[root@pier shells]# [ 100 -gt 200 ] && [ 100 -gt 50 ]
[root@pier shells]# echo $?
1
[root@pier shells]# [ 100 -gt 200 ] && [ 100 -gt 50 ]
[root@pier shells]# echo $?
1
[root@pier shells]# [ 100 -gt 200 ] || [ 100 -gt 50 ]
[root@pier shells]# echo $?
0
流程控制
流程控制的作用:
繼續運行位在不同位置的一段指令(無條件分支指令),
若特定條件成立時,運行一段指令,例如C語言的switch指令,是一種有條件分支指令,
運行一段指令若干次,直到特定條件成立為止,例如C語言的for指令,仍然可視為一種有條件分支指令,
運行位于不同位置的一段指令,但完成后會繼續運行原來要運行的指令,包括子程式、協程(coroutine)及延續性(continuation),
停止程式,不運行任何指令(無條件的終止),
if判斷
基本語法
#!/bin/bash
if [ condition1 ]#這是開始陳述句
then
陳述句1
elif [ condition2 ]
then
陳述句2
·
·
·
else
echo 陳述句n
fi#這是結束陳述句的標志
實體:
#!/bin/bash
#if測驗腳本
if [ $1 -eq 1 ]
then
echo "大資料,我來了!!!"
elif [ $1 -eq 2 ]
then
echo "大資料,pier又回歸!!!"
else
echo "都不留爺,pier要離開了!"
fi
執行:
[root@pier shells]# ./if.sh 2
大資料,pier又回歸!!!
[root@pier shells]# vim if.sh
[root@pier shells]# ./if.sh 2
大資料,pier又回歸!!!
[root@pier shells]# ./if.sh 1
大資料,我來了!!!
[root@pier shells]# ./if.sh 3
都不留爺,pier要離開了!
[root@pier shells]# ./if.sh
./if.sh: 第 3 行:[: -eq: 期待一元運算式
./if.sh: 第 6 行:[: -eq: 期待一元運算式
都不留爺,pier要離開了!
這里我們發現這個他居然有錯誤提示,于是發現了,報錯的兩行正好是我們需要傳入引數的兩行,所以,我們就可以在if判斷外邊再加一個判斷引數不為空的函式就可以了,
if [ $# -lt 1 ]
then
echo "請傳參!"
exit
fi
case分支
#!/bin/bash
case $1 in
"1")
echo "這是1分支! ! !"
;;#這個相當于break
"2")
echo "這是2分支!!!"
;;
echo "default結束了!!!"
;;
esac
for 回圈
for(( 初始值;回圈控制條件;變數變化 ))
do
程式陳述句
done
注:在回圈控制條件中使用><=這類符號,不識別-gt這類符號
注意點$@和$*的的區別:在列印時,不加雙引號時都是回圈呼叫,主要是注意在在輸出"$*"時,是一次性拿進來所有的引數,而其他的情況,都是一次只拿一個引數,回圈呼叫,
[root@pier shells]# ./for1.sh 劉亦菲 小阿七 Gai
==輸出不加引號的$*==
你好美女--劉亦菲
你好美女--小阿七
你好美女--Gai
==輸出不加引號的$@==
你好美女--劉亦菲
你好美女--小阿七
你好美女--Gai
==輸出加引號的$*==
你好美女--劉亦菲 小阿七 Gai
==輸出加引號的$@==
你好美女--劉亦菲
你好美女--小阿七
你好美女--Gai
while
while [ 條件判斷式 ]
do
程式
done
read讀取控制臺輸入
read(選項)(引數)
選項:
-p :指定讀取值的提示符
-t :指定讀取值等待的時間
引數:
? 變數:指定讀取值的變數名
實體:
[root@pier shells]# read -t 5 -p "請在五秒內輸入名字:" NAME
請在五秒內輸入名字:jiu
[root@pier shells]# echo $NAME
jiu
函式
系統函式
basename:獲取路徑的最后的檔案名
dirname : 獲取檔案的上一層的絕對路徑
[root@pier shells]# basename root/shells/
shellss
[root@pier shells]# dirname /root/shells/cash.sh
/root/shells
自定義函式
基本語法
[function] funname[()]
{
Action;#執行或計算的任務
[return int;]
}
#呼叫函式
funname
定義函式:
使用1
#/bin/bash
#定義函式
total=0
function sum(){
total=$[$1+$2];
#注意:這里回傳的值不能超過0-255,
#一旦操過,會回傳對255取余的值
return $total;
}
#read 輸入引數
read -t 5 -p "請輸入第一個數字:" n1
read -t 5 -p "請輸入第二個數字:" n2
#呼叫函式
sum $n1 $n2
#輸出結果
echo "sum=$?"
測驗:
[root@pier shells]# ./fun.sh
請輸入第一個數字:2
請輸入第二個數字:43
sum=45
[root@pier shells]# ./fun.sh
請輸入第一個數字:100
請輸入第二個數字:500
sum=88
**小問題:**那我們輸出的結果應該是600,但是是88是對256取余的結果,我們應該怎么解決呢?
我們既然知道了是
return $total;的問題,那么我們便不要這一句,直接注釋掉,再在最后的輸出是,將輸出的結果編程echo "sum=$total"就可以了,
[root@pier shells]# ./fun.sh
請輸入第一個數字:100
請輸入第二個數字:500
sum=600
注:shell編程并不是很適合計算,因此我們盡量只在里面寫邏輯關系,運算交給擅長的工具來,
Shell工具
cut
cut的作業就是“剪”,具體的說就是在檔案中負責剪切資料用的,cut 命令從檔案的每一行剪切位元組、字符和欄位并將這些位元組、字符和欄位輸出,
基本語法
-
cut [選項引數] filename
說明:默認分隔符是制表符
選項引數說明
| 選項引數 | 功能 |
|---|---|
| -f | 列號,提取第幾列 |
| -d | 分隔符,按照指定分隔符分割列 |
| -c | 指定具體的字符 |
案例
- 1)資料準備
[root@pier shells]$ cat cut.txt
dong shen
guan zhen
wo wo
lai lai
le le
- 2)切割cut.txt第一列
[root@pier shells]$ cut -d " " -f 1 cut.txt
dong
guan
wo
lai
le
- 3)切割cut.txt第二、三列
[root@pier shells]$ cut -d " " -f 2,3 cut.txt
shen
zhen
wo
lai
le
- 4)在cut.txt檔案中切割出guan
[root@pier shells]$ cat cut.txt | grep "guan" | cut -d " " -f 1
guan
- 5)選取系統PATH變數值,第2個“:”開始后的所有路徑:
[root@pier shells]$ echo $PATH
/usr/lib64/qt-3.3/bin:/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
[root@pier shells]$ echo $PATH | cut -d: -f 2-
/usr/local/bin:/bin:/usr/bin:/usr/local/sbin:/usr/sbin:/sbin:/home/atguigu/bin
- 6)切割每一行的第一個字母(這里中文也是一個字符)
[root@pier shells]# cut -c 1 cut.txt
d
g
w
l
l
- 7)切割ifconfig 后列印的IP地址
[root@pier shells]# ifconfig | grep netmask | awk -F "inet " '{print $2}' | awk -F " " '{print $1}'
192.168.40.100
127.0.0.1
192.168.122.1
awk
概述
一個強大的文本分析工具,把檔案逐行的讀入,以空格為默認分隔符將每行切片,切開的部分再進行分析處理,
基本用法
awk [選項引數] ‘pattern1{action1} pattern2{action2}…’ filename
pattern:表示AWK在資料中查找的內容,就是匹配模式
action:在找到匹配內容時所執行的一系列命令
選項引數說明
| 選項引數 | 功能 |
|---|---|
| -F | 指定輸入檔案折分隔符 |
| -v | 賦值一個用戶定義變數 |
案例
(1)資料準備
[root@pier shells]$ sudo cp /etc/passwd ./
(2)搜索passwd檔案以root關鍵字開頭的所有行,并輸出該行的第7列,
[root@pier shells]$ awk -F: '/^root/{print $7}' passwd
/bin/bash
(3)搜索passwd檔案以root關鍵字開頭的所有行,并輸出該行的第1列和第7列,中間以“,”號分割,
[root@pier shells]$ awk -F: '/^root/{print $1","$7}' passwd
root,/bin/bash
注意:只有匹配了pattern的行才會執行action
(4)只顯示/etc/passwd的第一列和第七列,以逗號分割,且在所有行前面添加列名user,shell在最后一行添加"dahaige,/bin/zuishuai",
[root@pier shells]$ awk -F : 'BEGIN{print "user, shell"} {print $1","$7} END{print "dahaige,/bin/zuishuai"}' passwd
user, shell
root,/bin/bash
bin,/sbin/nologin
,,,
atguigu,/bin/bash
dahaige,/bin/zuishuai
注意:BEGIN 在所有資料讀取行之前執行;END 在所有資料執行之后執行,
(5)將passwd檔案中的用戶id增加數值1并輸出
[root@pier shells]$ awk -v i=1 -F: '{print $3+i}' passwd
1
2
3
4
awk的內置變數
| 變數 | 說明 |
|---|---|
| FILENAME | 檔案名 |
| NR | 已讀的記錄數(行數) |
| NF | 瀏覽記錄的域的個數(切割后,列的個數) |
案例:
- 統計passwd檔案名,每行的行號,每行的列數
[root@pier shells]# awk -F: '{print "filename:" FILENAME ", 行號:" NR ",列號:" NF}' passwd
filename:passwd, 行號:1,列號:7
filename:passwd, 行號:2,列號:7
filename:passwd, 行號:3,列號:7
filename:passwd, 行號:4,列號:7
2)切割IP
[root@pier shells]# ifconfig | grep netmask | awk -F "inet " '{print $2}' | awk -F " " '{print $1}'
192.168.40.100
127.0.0.1
192.168.122.1
sort
sort命令是在Linux里非常有用,它將檔案進行排序,并將排序結果標準輸出,
1)基本語法
sort(選項)(引數)
| 選項 | 說明 |
|---|---|
| -n | 依照數值的大小排序 |
| -r | 以相反的順序來排序 |
| -t | 設定排序時所用的分隔字符 |
| -k | 指定需要排序的列 |
引數:指定待排序的檔案串列
2)案例實操
(1)資料準備
[root@pier shells]$ touch sort.sh
[root@pier shells]$ vim sort.sh
bb:40:5.4
bd:20:4.2
xz:50:2.3
cls:10:3.5
ss:30:1.6
(2)按照“:”分割后的第三列倒序排序,
[root@pier shells]$ sort -t : -nrk 3 sort.sh
bb:40:5.4
bd:20:4.2
cls:10:3.5
xz:50:2.3
ss:30:1.6
正則運算式
含義:
正則運算式是用于描述字符排列和匹配模式的一種語法規則. 它主要用于字串的模式分割、匹配、查找及替換操作.
特殊使用;
注:這里我們學習前找一份檔案,做測驗,沒有用檔案的小伙伴,可以學我,
cp /etc/passwd ./,復制過來一份,但是不要去修改源檔案,萬一,,,嗯,就哦豁!
- 正則運算式用來在檔案中匹配符合條件的字串,正則是包含匹配,grep、awk、sed 等命令可以支持正則運算式,
- 通配符用來匹配符合條件的檔案名,通配符是完全匹配,ls、find、cp 這些命令不支持正則運算式,所以只能使用 shell 自己的通配符來進行匹配了,
^匹配以什么什么字符開頭的一行:cat passwd | grep ^a
* 匹 配 以 什 么 什 么 字 符 結 尾 的 一 行 ? : ‘ c a t p a s s w d ∣ g r e p t 匹配以什么什么字符結尾的一行*:`cat passwd | grep t 匹配以什么什么字符結尾的一行?:‘catpasswd∣grept`
匹配空行就可以這么寫了: ^t$
.匹配任意一個字符:cat passwd | grep r..t注:這就是匹配r和t之間相隔兩個字符的句子,中間又幾個點就代表相隔字符,
*不單獨使用,和他左邊的第一個字符連用,表示匹配上一個字符0次或者多次:cat passwd | grep ro*t這個就會匹配到只要包含rt,或者rt之間僅有o字符的的所有單詞所在的那一行,
特殊字符[]:
-
表示匹配某個范圍內的一個字符,例如
-
[6,8]------匹配6或者8
-
[a-z]------匹配一個a-z之間的字符
-
[a-z]*-----匹配任意字母字串
-
[a-c, e-f]-匹配a-c或者e-f之間的任意字符
-
[root@pier shells]$ cat /etc/passwd | grep r[a,b,c]*t
案例
匹配所有包含n或者包含c的句子,
[root@pier shells]# cat if.sh | grep [n,c]
#!/bin/bash
then
echo "請傳參!"
then
echo "大資料,我來了!!!"
then
echo "大資料,pier又回歸!!!"
echo "都不留爺,pier要離開了!"
特殊字符:
有些特殊字符又特殊含義,所以在使用時需要加\才可以正常的使用,并使用單引號引起來,
注意:shell編程雖然不難,也許一天就吃了個七七八八,但是也得要多加練習呀,一起加油呀,學會了,就等待著和pier一起進入快樂的Hadoop吧!

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/387951.html
標籤:其他