
二叉搜索樹
二叉搜索樹概念
二叉搜索樹又稱二叉排序樹,它或者是一棵空樹,或者是具有以下性質的二叉樹:
- 若它的左子樹不為空,則左子樹上所有節點的值都小于根節點的值 若它的右子樹不為空,則右子樹上所有節點的值都大于根節點的值
- 它的左右子樹也分別為二叉搜索樹
增刪查改介面
插入
//增刪查改
bool insert(const T& val)
{
Node* node = new Node(val);
if (!_root)
{
_root = node;
}
else
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
//插入的結點val值比根大
if (cur->_key < val)
{
parent = cur;
cur = cur->_right;
}
//插入的結點val值比根小
else if (cur->_key > val)
{
parent = cur;
cur = cur->_left;
}
else
{
//插入失敗
return false;
}
}
// 判斷插入的值是在根的左邊還是根的右邊
if (parent->_key > val)
parent->_left = node;
else
parent->_right = node;
}
return true;
}
遞回插入
bool InsertR(const T& val)
{
return _InsertR(_root, val);
}
bool _InsertR(Node*& root, const T& val)
{
//直到走到null位置處,也正是插入結點的適當位置
if (!root)
{
root = new Node(val);
return true;
}
//如果比根小那么就去左子樹找插入位置
if (root->_key > val)
{
return _InsertR(root->_left, val);
}
//如果比根大,那么就去右子樹找插入位置
else if (root->_key < val)
{
return _InsertR(root->_right, val);
}
else
{
//二叉搜索樹并不會存在重復的值,如果val既不大于也不小于那就是相等了
return false;
}
}
查找
//查找
Node* Find(const T& val)
{
Node* cur = _root;
while (cur)
{
//比根大
if (cur->_key < val)
{
cur = cur->_right;
}
//比根小
else if (cur->_key > val)
{
cur = cur->_left;
}
else
{
//回傳查找到的結點
return cur;
}
}
return nullptr;
}
遞回查找
Node* _FindR(Node* root, const T& val)
{
//直到走到null還沒有找到就回傳null
if (!root) return nullptr;
//比根大
if (root->_key < val)
return _FindR(root->_right, val);
//比根小
else if (root->_key > val)
return _FindR(root->_left, val);
//找到了
else
return root;
}
//遞回版本
Node* FindR(const T&val)
{
return _FindR(_root,val);
}
洗掉
搜索樹的洗掉需要考慮三種情況
洗掉一個值等于key的結點,分情況分析:
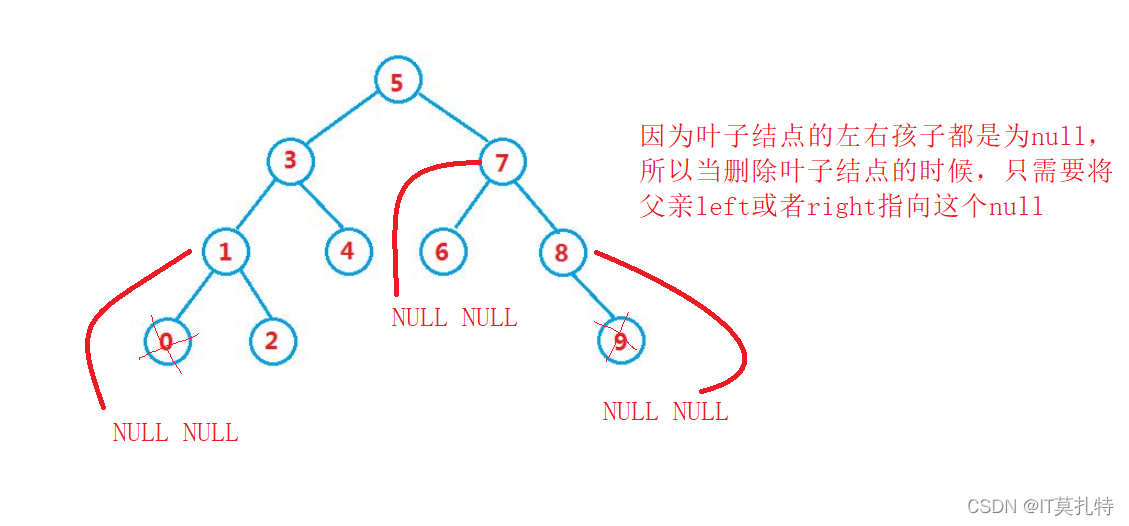
1、要洗掉的是6、9、0…,這個幾個結點的特征是屬于葉子結點,而洗掉葉子結點只需要將結點的父親指向孩子的左或者孩子的右都行,
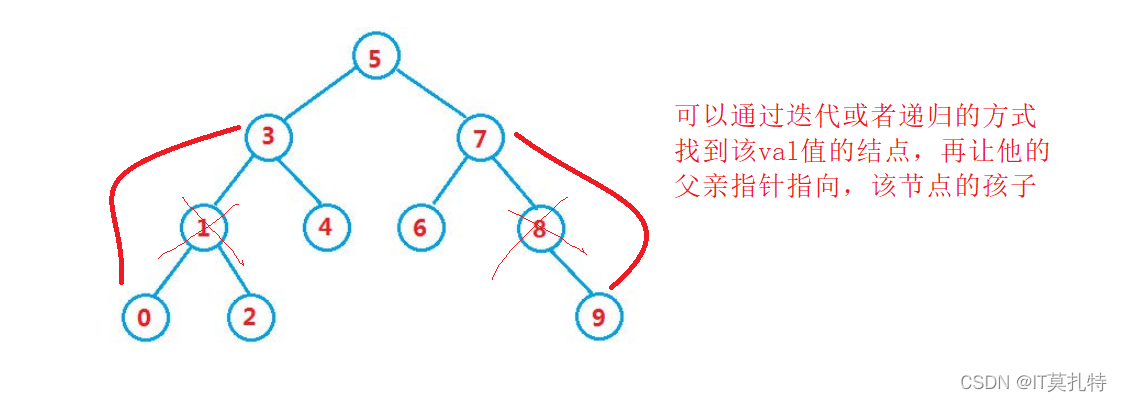
2、要洗掉的結點是8、1…,這幾個結點的特征時屬于只有一個孩子的結點,洗掉的方式是通過父親去接管孩子的孩子,再把孩子給洗掉
3、要洗掉的結點是5、7,這兩個結點的特征是擁有兩個孩子,并不好處理,也不滿足1、2的特征
如果能夠通過一個解決辦法直接將特征3的復雜度降低為特征1的復雜度就會變得很好處理,
解決辦法:替換法洗掉,去左右子樹中找一個能夠替換自己位置的結點,替換自己洗掉
這里可以通過搜索樹的性質來決定:
1、左子樹最大值得結點就是左子樹最右邊的結點:4
2、右子樹最小值的結點就是右子樹最左的結點:6
通過這兩個結點去替換要洗掉的結點
先看洗掉val值為5的結點,通過替換法,將問題復雜度直接降低為特征1
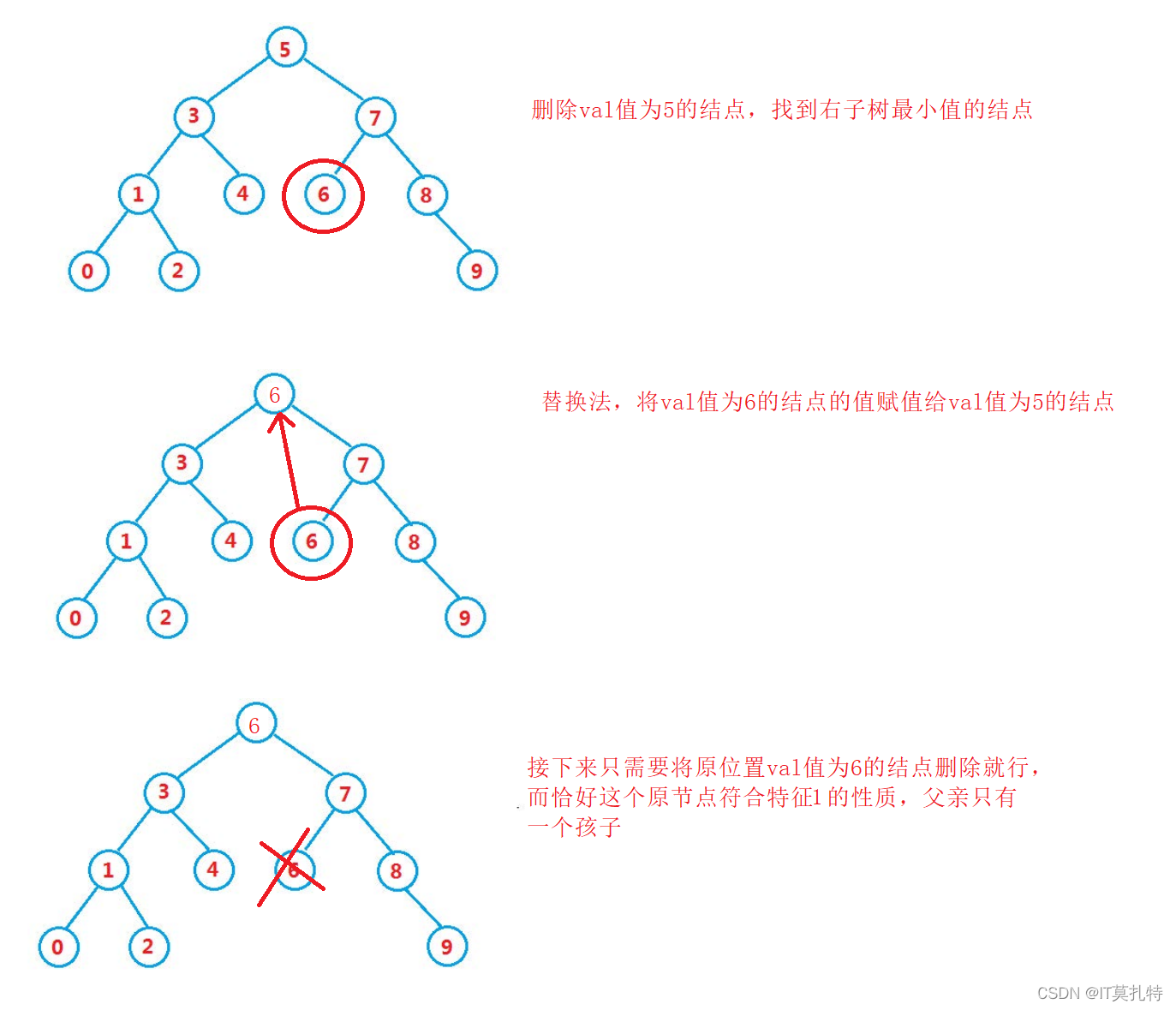
先看洗掉val值為7的結點,通過替換法,將問題復雜度直接降低為特征2
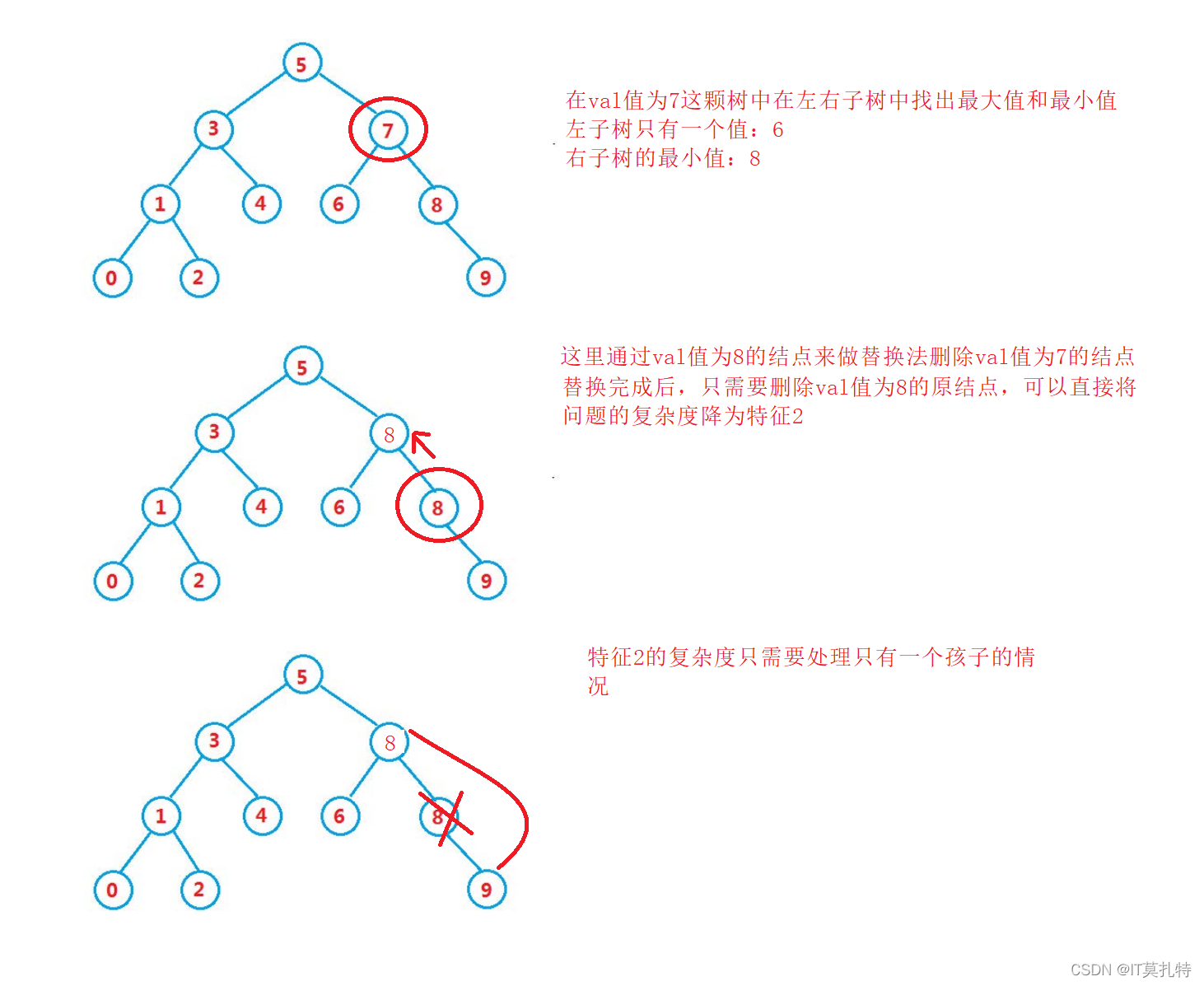
而在這里的特征2的處理方式同樣也能解決特征1的問題,所以在替換法洗掉結點的時候都采用特征2的處理方式
//洗掉
bool Erase(const T& val)
{
Node* parent = nullptr;
Node* cur = _root;
while (cur)
{
//如果val值的結點小于根結點那就去左子樹找
if (cur->_key > val)
{
parent = cur;
cur = cur->_left;
}
//如果val值的結點大于根結點那就去右子樹找
else if (cur->_key < val)
{
parent = cur;
cur = cur->_right;
}
else //找到的情況
{
//處理特征2,考慮左邊為null,洗掉只有一個孩子的結點
if (!cur->_left)
{
if(_root == cur)
{
_root = cur->_right;
}
else
{
if (parent->_left == cur)
parent->_left = cur->_right;
else
parent->_right = cur->_right;
}
delete cur;
}
//考慮右邊為null
else if (!cur->_right)
{
if(_root == cur)
{
_root = cur->_left;
}
if (parent->_left == cur)
parent->_left = cur->_left;
else
parent->_right = cur->_left;
delete cur;
}
//處理特征3
else
{
Node* minparent = cur;
Node* minRight = cur->_right;
while (minRight->_left) //找右子樹的最左結點,右子樹的最左結點適合當替代結點
{
minparent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key; //替換
if (minparent->_left == minRight) //這里需要考慮兩個最左的情況
minparent->_left = minRight->_right ; //左子樹的最左
else
minparent->_right = minRight->_right; //右子樹的最左
delete minRight;
}
return true;
}
}
return false;
}
遞回洗掉
bool EraseR(const T&val)
{
return _EraseR(_root, val);
}
bool _EraseR(Node*& root, const T& val)
//注意這里傳遞的是指標的別名
{
if (root->_key > val)
{
return _EraseR(root->_left, val);
}
else if (root->_key < val)
{
return _EraseR(root->_right, val);
}
else //找到了
{
if (!root->_left)
{
Node* del = root;
root = root->_right; //root是指標的別名
delete del; //洗掉值為val的結點
}
else if (!root->_right)
{
Node* del = root;
root = root->_left; //root是指標的別名
delete del; //洗掉值為val的結點
}
else
{
Node* minright = root->_right;
while (minright->_left)
{
minright = minright->_left; //找到右子樹的最左值
}
T min = minright->_key;
_EraseR(root->_right ,min);//將問題規模縮小到在右子樹中洗掉替換結點,使用遞回洗掉復用前面洗掉一個結點的邏輯
root->_key = min;//使用min將原結點的值覆寫達到替換的目的
}
return true; //洗掉成功回傳true
}
return false;
}
成員函式
拷貝構造
//拷貝構造
BSTree(const BSTree<T>& root)
{
_root = copy(root._root);
}
//使用前序遍歷的思想,將每一個結點都開辟出來,回傳的程序中鏈接在一起
Node* copy(Node *root)
{
if (!root)
{
return nullptr;
}
else
{
Node* copynode = new Node(root->_key);
copynode->_left = copy(root->_left);
copynode->_right = copy(root->_right);
return copynode;
}
}
拷貝賦值
//拷貝賦值 ,現代寫法,借助形參物件來構造*this物件,交換他們的_root
BSTree<T>& operator=(BSTree<T> Tree)
{
swap(_root, Tree._root);
return *this;
}
析構
~BSTree()
{
_Destroy(_root);
_root = nullptr; //防止野指標
}
//釋放結點申請的記憶體,使用后序遍歷的思想,從最后一個結點開始倒著洗掉
void _Destroy(Node *root)
{
if (!root) return;
_Destroy(root->_left);
_Destroy(root->_right);
delete root;
}
二叉搜索樹的應用
搜索二叉樹的kv模型只要在現有的基礎上增加鍵值對就行,相關的代碼博主已經上傳在git上: link.
1、 K模型:K模型即只有key作為關鍵碼,結構中只需要存盤Key即可,關鍵碼即為需要搜索到的值,比如:給一個單詞word,判斷該單詞是否拼寫正確,具體方式如下:以單詞集合中的每個單詞作為key,構建一棵二叉搜索樹在二叉搜索樹中檢索該單詞是否存在,存在則拼寫正確,不存在則拼寫錯誤,
void func()
{
BSTree<string, string> bs;
bs.Insert("administration","管理");
bs.Insert("translate", "翻譯");
bs.Insert("modern", "現代");
bs.Insert("tape", "磁帶");
bs.Insert("hard disk", "硬碟");
bs.Insert("computer", "電腦");
string str;
while (cin >> str)
{
BSTNode<string, string>* ret = bs.FindR(str);
if (!ret)
cout << "拼寫錯誤沒有該單詞" << endl;
else
cout << ret->_key << ":" << ret->_value << endl;
}
}
2、 KV模型:每一個關鍵碼key,都有與之對應的值Value,即<Key, Value>的鍵值對,該種方式在現實生活中非常常見:比如英漢詞典就是英文與中文的對應關系,通過英文可以快速找到與其對應的中文,英文單詞與其對應的中文<word, chinese>就構成一種鍵值對;再比如統計單詞次數,統計成功后,給定單詞就可快速找到其出現的次數,單詞與其出現次數就是<word, count>就構成一種鍵值對,比如:實作一個簡單的英漢詞典dict,可以通過英文找到與其對應的中文,具體實作方式如下:<單詞,中文含義>為鍵值對構造二叉搜索樹,注意:二叉搜索樹需要比較,鍵值對比較時只比較Key查詢英文單詞時,只需給出英文單詞,就可快速找到與其對應的
BSTree<string, int> bs;
string str[] = {"電腦","cpu","電腦","硬碟","硬碟","顯卡","顯卡","顯示幕"};
for (const auto &ref : str)
{
BSTNode<string, int>* ret = bs.FindR(ref);
if (!ret) //如果詞典中沒有ref這個單詞就插入一個單詞
bs.InsertR(ref, 1);
else
ret->_value++; //對重復存在的單詞計數
}
bs.Inorder();
二叉搜索樹的性能分析
1、插入和洗掉操作都必須先查找,查找效率代表了二叉搜索樹中各個操作的性能,對有n個結點的二叉搜索樹,若每個元素查找的概率相等,則二叉搜索樹平均查找長度是結點在二叉搜索樹的深度的函式,即結點越深,則比較次數越多,
2、但對于同一個關鍵碼集合,如果各關鍵碼插入的次序不同,可能得到不同結構的二叉搜索樹:
最優情況下,二叉搜索樹為完全二叉樹,其平均比較次數為:O(log n)

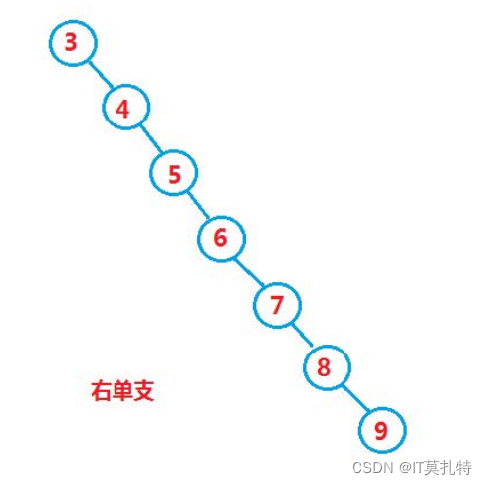
最壞情況下,二叉搜索樹為右單支,其平均比較次數為:O(n / 2)

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/387955.html
標籤:其他
上一篇:呼叫百度AI實作人像分割(下)