
老生常談的大集合過濾問題,很多大廠面試都喜歡問,其實吼,實作很簡單,難在優化
優化點:
- 如何提高效率
- 如何減少記憶體占用
既然如此,那咱先實作,后面再逐步優化
一億個物件,直接放list,然后判斷物件是否存在行不行?
行
但一億個物件裝進一個list,有億點點難啊
要不我們先試試100w個?
試試就逝世
我們先準備些工具用來生成物件
1、新建個物件,就叫person吧
public class Person {
private Long id;
private String name;//姓名
private Long phone;//電話
private BigDecimal salary;//薪水
private String company;//公司
private Integer ifSingle;//是否單身
private Integer sex;//性別
private String address;//住址
private LocalDateTime createTime;
private String createUser;
}
2、為了模擬真實資料,我們要用到一些列舉值和隨機演算法
private static Random random = new Random();
private static String[] names = {"黃某人", "負債程式猿", "譚sir", "郭德綱", "李狗蛋", "鐵蛋", "趙鐵柱", "蔡徐雞", "蔡徐母雞"};
private static String[] addrs = {"二仙橋", "成華大道", "春熙路", "錦里", "寬窄巷子", "雙子塔", "天府大道", "軟體園", "熊貓大道", "交子大道"};
private static String[] companys = {"京東", "騰訊", "百度", "小米", "米哈游", "網易", "位元組跳動", "美團", "螞蟻", "完美世界"};
private static LocalDateTime now = LocalDateTime.now();
//獲取指定數量person
private static ArrayList<Person> getPersonList(int count) {
ArrayList<Person> persons = new ArrayList<>(count);
for (int i = 0; i < count; i++) {
persons.add(getPerson());
}
return persons;
}
//隨機生成person
private static Person getPerson() {
Person person = Person.builder()
.name(names[random.nextInt(names.length)])
.phone(18800000000L + random.nextInt(88888888))
.salary(new BigDecimal(random.nextInt(99999)))
.company(companys[random.nextInt(companys.length)])
.ifSingle(random.nextInt(2))
.sex(random.nextInt(2))
.address("四川省成都市" + addrs[random.nextInt(addrs.length)])
.createTime(LocalDateTime.now())
.createUser(names[random.nextInt(names.length)]).build();
return person;
}
這個演算法生成的物件重復率很低很低(幾乎不會有重復的)
來看下效果

但全是隨機的也不行,我們需要有個確定的物件,因為我們后面要判斷某個物件是否存在,所有要有個方法用來生成確定物件
//獲得一個確定的person,需傳入一個date,什么作用這里先別管,后面一看就懂
private static Person getFixedPerson(LocalDateTime date) {
Person person = Person.builder()
.name("薇婭")
.phone(18966666666L)
.salary(new BigDecimal(99999))
.company("天貓")
.ifSingle(0)
.sex(0)
.address("上海市徐家匯某棟寫字樓")
.createTime(date)
.createUser("老馬").build();
return person;
}
開始測驗( 終于開始了,好雞凍 )

一次裝100w有點多,我們分開裝,一次裝50w
public static void main(String[] args) {
ArrayList<Person> arrayList = new ArrayList<>();
for (int i = 0; i < 2; i++) {
arrayList.addAll(getPersonList(500000));
}
//add一個確定的person
arrayList.add(getFixedPerson(now));
long start = System.currentTimeMillis();
System.out.println(arrayList.contains(getFixedPerson(now)));
System.out.println("arrayList內物件數量" + arrayList.size());
long end = System.currentTimeMillis() - start;
System.out.println("耗時(ms):" + end + ",消耗記憶體(m):" + (ObjectSizeCalculator.getObjectSize(arrayList) / (1024 * 1024)));
}
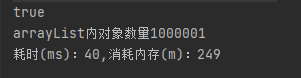
害行,100w效率害行,記憶體也還頂得住
超級加倍,試試1000w
//其它代碼跟上面一樣
for (int i = 0; i < 20; i++) {
arrayList.addAll(getPersonList(500000));
}
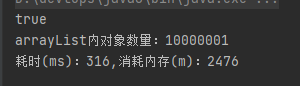
效率也害行,不過記憶體,好家伙,用了2.5G,有點拉跨,那以此類推,1個億得25G記憶體,這怕是有點頂不住啊
list一個億我就不測了 0.0
list方案以失敗告終
其實吼,非要用list也不是不行,裝不了一個億就分批次唄,醬紫解決了記憶體的問題,但是耗時解決不了,就按照上面的1000w0.3s來計算,一個億至少也得3s,還是有點拉跨
有沒有一種容器,能夠容納一億個物件,并且占用記憶體還少?
布隆過濾器:你直接念我身份證得了
是的,今天的主題是布隆過濾器(BloomFilter)
主角來了
前面都是為了引出BloomFilter,有對比你才知道這玩意兒多牛逼
下面是一個低配版BloomFilter,原理最后說
public class MyBloomFilter {
//后面hash函式會用到,用來生成不同的hash值,可以隨便給,但別給奇數
private final int[] ints = {6, 8, 16, 38, 58, 68};
//統計當前物件數量
private Integer currentBeanCount = 0;
//你的布隆過濾器容量
private int DEFAULT_SIZE = Integer.MAX_VALUE;
//bit陣列,用來存放結果
private final BitSet bitSet = new BitSet(DEFAULT_SIZE);
public MyBloomFilter() {
}
public MyBloomFilter(int size) {
if (size > Integer.MAX_VALUE) throw new RuntimeException("size is too large");
if (size <= (2 << 8)) throw new RuntimeException("size is too small");
DEFAULT_SIZE = size;
}
//獲取當前過濾器的物件數量
public Integer getCurrentBeanCount() {
return currentBeanCount;
}
//計算出key的hash值,并將對應下標置為1
public void push(Object key) {
Arrays.stream(ints).forEach(i -> bitSet.set(hash(key, i)));
currentBeanCount++;
}
//判斷key是否存在,true不一定說明key存在,但是false一定說明不存在
public boolean contain(Object key) {
boolean result = true;
for (int i : ints) {
result = result && bitSet.get(hash(key, i));
}
return result;
}
//hash演算法,借鑒了hashmap的演算法,利用i對同個key生成一組不同的hash值
private int hash(Object key, int i) {
int h;
int index = key == null ? 0 : (DEFAULT_SIZE - 1 - i) & ((h = key.hashCode()) ^ (h >>> 16));
return index > 0 ? index : -index;
}
}
先看效果
1000w
public static void main(String[] args) {
//實體化
MyBloomFilter filter = new MyBloomFilter();
for (int i = 0; i < 20; i++) {
//push到BloomFilter
getPersonList(500000).forEach(person -> filter.push(person));
}
//push一個確定的物件
filter.push(getFixedPerson(now));
//判斷這個物件是否存在
long start = System.currentTimeMillis();
System.out.println(filter.contain(getFixedPerson(now)));
long end = System.currentTimeMillis() - start;
System.out.println("bloomFilter內物件數量:" + filter.getCurrentBeanCount());
System.out.println("耗時(ms):" + end + ",消耗記憶體(m):" + (ObjectSizeCalculator.getObjectSize(filter) / (1024 * 1024)));
}
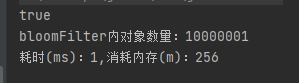
嗷嗷快是不是,而且只要是記憶體只用了256m,并且吼,這個記憶體不會隨著物件的增多而變大,不信我們來試試
一個億
//其他代碼全一樣
for (int i = 0; i < 200; i++) {
//push到BloomFilter
getPersonList(500000).forEach(person -> filter.push(person));
}
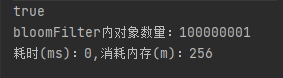
即使是一個億,性能也能嘎嘎快,而且記憶體依然是256m,得不得勁兒
當然,自古好事兩難全,BloomFilter雖然性能猛,但是也有缺點
它在用作判斷物件 是否存在 時有誤判率,誤判率隨著物件數量增加而增加
但是用作判斷物件 是否不存在 時,沒有誤判率
這個特性讓它經常用作應對快取穿透(判斷key是否合法)
看累了吧,獎勵一張嗨絲

簡單說下原理
就是通過對比hash演算法計算出來的下標,但注意,是對比一組,而不是一次,一次hash結果只對應一個下標
把同一個key進行多次hash運算,將hash出來的下標放入陣列,陣列默認全為0,放入元素后該下標就為1,后面判斷是否存在元素的時候也是進行同樣次數的hash運算,看下結果對應的所有下標是否全為1,若全為1,則代表該key可能存在,若存在不為1的,則說明該key一定不存在;
默認bit陣列:[0,0,0,0,0,0]
比方說有個key計算出的一組hash下標是0,2,5
對應位bit陣列:[1,0,1,0,0,1]
判斷某個未知key是否存在時候,假設我們計算出來的下標是0,2,4
對應位陣列:[1,0,1,0,1,0]
此時位陣列內5對應下標值為0,而已知key位陣列的5對應下標位1,說明這兩個key一定不同
相反,如果某個key計算出來的下標為[1,0,1,0,0,1],只能說這個key可能存在,因為這幾個位置可能是其它key計算出來的
ok我話說完
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/389682.html
標籤:其他