目錄
什么是HTTP協議
URL與URI
HTTP協議的報文結構
HTTP請求方法
GET請求方法
POST請求方法
HTTP回應狀態碼
HTTP報文頭
HTTP無狀態性
什么是HTTP協議
HTTP(Hypertext Transfer Protocol):超文本傳輸協議,
那么說到超文本,我們就會想到HTML (Hyper Text Markup Lanuage)超文本標記語言,而實際上,HTTP協議早期就是專門用來傳輸HTML檔案的,而為了定位HTML檔案在網路中的位置,提出了URL(Uniform Resource Locator)統一資源定位符,即URL可以定位到一個資源檔案在網路中的位置,
而HTTP,HTML,URL 共同構造了早期的World Wide Web,即萬維網,
而隨著HTTP的發展,HTTP協議發生了許多變化:
1、HTTP協議不再單純地用來傳輸網頁內容,而是更加廣泛地應用于介面層面資料傳輸,常見的資料格式有JSON
2、HTTP請求不再只由瀏覽器發起,現在無論是瀏覽器還是服務器,或者是手機app都可以發起
3、早期地HTTP請求只能由瀏覽器重繪網頁發起,是同步的,現在有了Ajax,可以發起異步的HTTP請求
URL與URI
無論HTTP協議如何發展,它的基本核心沒有變,即HTTP協議是一種請求應答機制的協議,它需要請求一個遠程服務器上的某個資源,早期是網頁HTML,現在更多是介面JSON資料,但是無論資源如何變化,該資源都要有一個URL標識它在網路中的位置,
URL的組成

URL組成包括:協議,服務器地址,服務器埠號,資源唯一標識,請求引數,錨點,以及它們之間的分隔符
通過URL就可以確定網路中唯一的資源所在位置,
我們通常也將URL稱為網址,
那么URI又是什么呢?
URI(Uniform Resource Identifier)統一資源識別符號,它是用來定義唯一資源的,即使用一種定義方式讓資源唯一,
那么上面的網址是不是可以標識一個唯一資源呢?
答案是可以的,所以URL也是一種特殊的URI,
但是URI還有很多其他表達方式,不一定要寫出URL形式,
URI和URL的關系,就像父類和子類一樣,子類是一種特殊的父類,URL也是一種特殊的URI,
HTTP協議的報文結構
HTTP協議將報文分為了請求報文和回應報文
HTTP請求報文結構
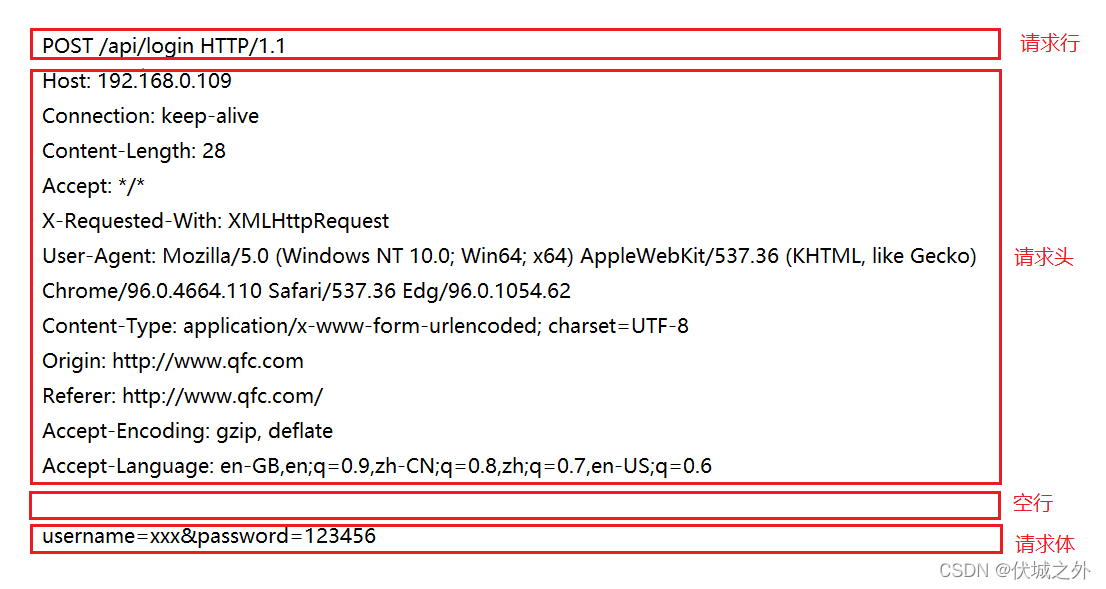
HTTP請求報文由四部分組成,從上到下依次是:請求行,請求頭,空行,請求體
請求行(必傳):組成包括請求方法(如POST),請求資源標識(如/api/login),HTTP協議版本(如HTTP/1.1)
請求頭(必傳):其中都是key:value鍵值對形式,主要是描述請求相關的資訊,如請求的服務器地址,請求體的格式,編碼方式,期望服務器回應的報文的格式和編碼方式,請求發起方所在的瀏覽器內核資訊,以及作業系統資訊,以及一些控制網路連接的設定,
空行(必傳):主要用來分隔報文首部和報文主體,請求行和請求頭可以看出報文首部,請求體可以看出報文主題,
請求體(可選):請求訊息體,即報文的主體內容,可以不傳,看業務需求
HTTP回應報文結構
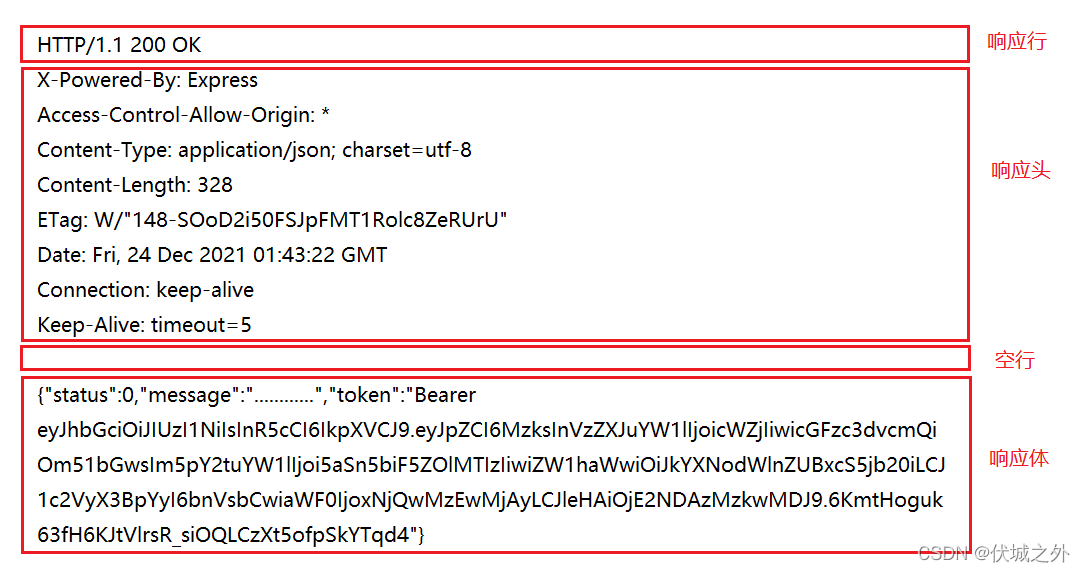
HTTP回應報文也由四部分組成,從上到下依次是:回應行,回應頭,空行,回應體
回應行(必傳):也叫狀態行,用來概括本次回應的狀態,組成包括:HTTP協議版本(如HTTP/1.1),狀態碼(如200),狀態碼描述(如OK)
回應頭(必傳):由key:value鍵值對組成,主要用來描述本次回應的一些資訊,如服務器應用程式提供者(如Tomcat,Express,Nginx),是否允許跨域(Acess-Control-Allow-Origin),以及回應體的格式和編碼方式(Content-Type),連接設定(Connection),連接失效時間(Keep-Alive)
回應體(可選):即回應訊息體,是回應報文的主體內容,其中包含請求方所需的業務資料,但是不是必傳的,可以根據業務需求決定,
HTTP請求方法
在HTTP請求報文的請求行中開頭就是請求方法,常用的有GET,POST,還有一些不常用,一共有八個
| GET | 獲取資源,通常不帶有報文體內容,它還是默認HTTP請求方法 |
| POST | 提交請求,帶有報文體的請求 |
| OPTIONS | 查詢服務器指定資源支持的請求方法 |
| HEAD | 和GET類似,但是不回傳報文體 |
| PUT | 向服務器上傳資源,存在安全問題 |
| DELETE | 洗掉服務器上的資源,存在安全問題 |
| TRACE | 讓服務器將之前的請求通信回傳給客戶端 |
| CONNECT | 用來建立傳輸通道 |
當前開發程序主要使用GET和POST,其他方式很少在開發中使用,
GET請求方法
GET請求方法的作用是 獲取 && 檢索,
“獲取”性質的GET,通常不需要攜帶請求引數,
“檢索”性質的GET,通常需要攜帶請求引數,
但是GET請求通常不會將請求引數放到請求體中,而是直接拼接在請求URL中,

URL中默認只支持部分ASCII碼表中的字符,如常見的英文字母、數字、常用的英文符號,
這是因為URL是西方人設計出來的,他們只考慮了自己的語言環境,使用ASCII碼表字符就完全夠了,所以URL中如果出現中文字符,那么URL就無法作業了,因為ASCII碼表中沒有中文字符,
而GET請求引數出現中文字符的場景是很多的,比如常見的百度搜索,我們不可能將想要搜索的中文翻譯為英文后搜索,
所以就引入了編碼技術,通過將中文字符encode為ASCII碼字符,就解決了URL無法識別中文字符的問題了,
我們知道ASCII碼表只有128個字符,但是中文字符卻有上萬個,而中文字符編碼后還需要能夠適配只識別ASCII碼的環境,比如URL,所以新的編碼技術順其自然的通過ASCII碼表字符間不同的組合,來一一對應一個中文字符,
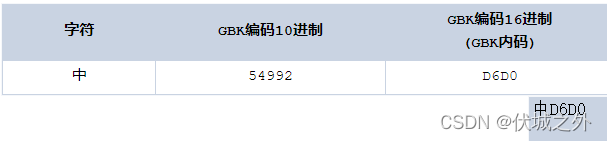
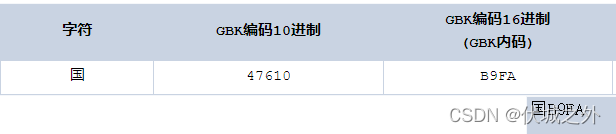
比如中文字符編碼:GBK
當然除了中文,還有日文,韓文,羅馬文,各種國家的文字,他們都需要在網路上傳輸,那么就需要一種基于ASCII碼字符組合兼容萬國文字的編碼:UTF-8
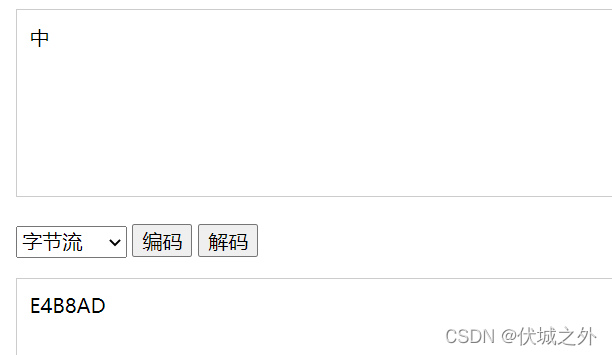
可以看出GBK表示一個中文字符只需要兩個位元組
D6D0 為啥是兩個位元組
一個位元組 = 8位 二進制數
0000 0000 ~ 1111 1111
而 4位二進制數,等價于 1位十六進制數
0000 ~ 1111 = 0 ~ F
所以 8位 二進制數,等價于 2位 16進制數
0000 0000 ~ 1111 1111 = 00 ~ FF
所以一個位元組 = 2位 十六進制數
而UTF-8表示一個中文字符需要三個位元組,
那么GET請求引數使用的是那種編碼呢?這和瀏覽器有關,常用的谷歌瀏覽器使用的是UTF-8編碼,
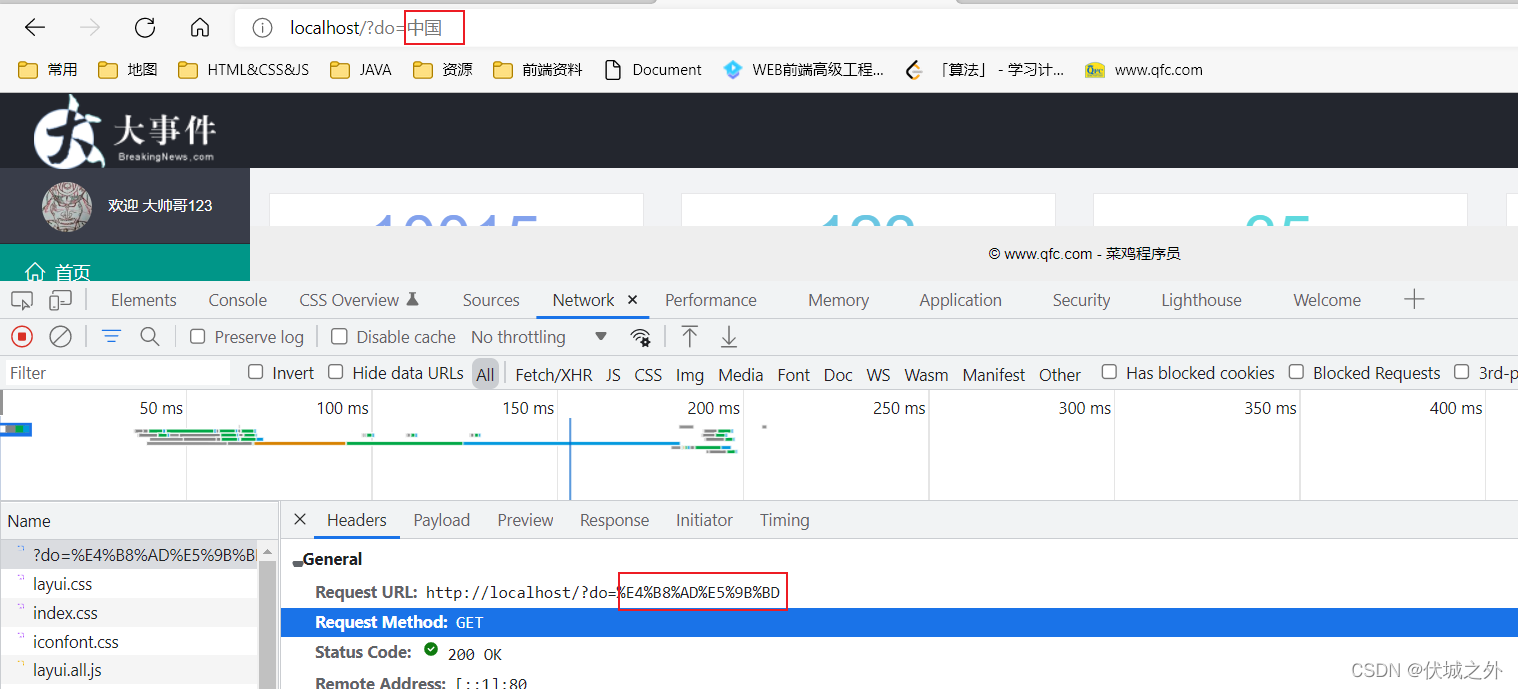
通過瀏覽器的地址欄或通過瀏覽器的XMLHttpRequest發送的GET請求引數,都會自動被瀏覽器內部進行編碼,
POST請求方法
POST請求方法的作用是 創建 | | 更新,
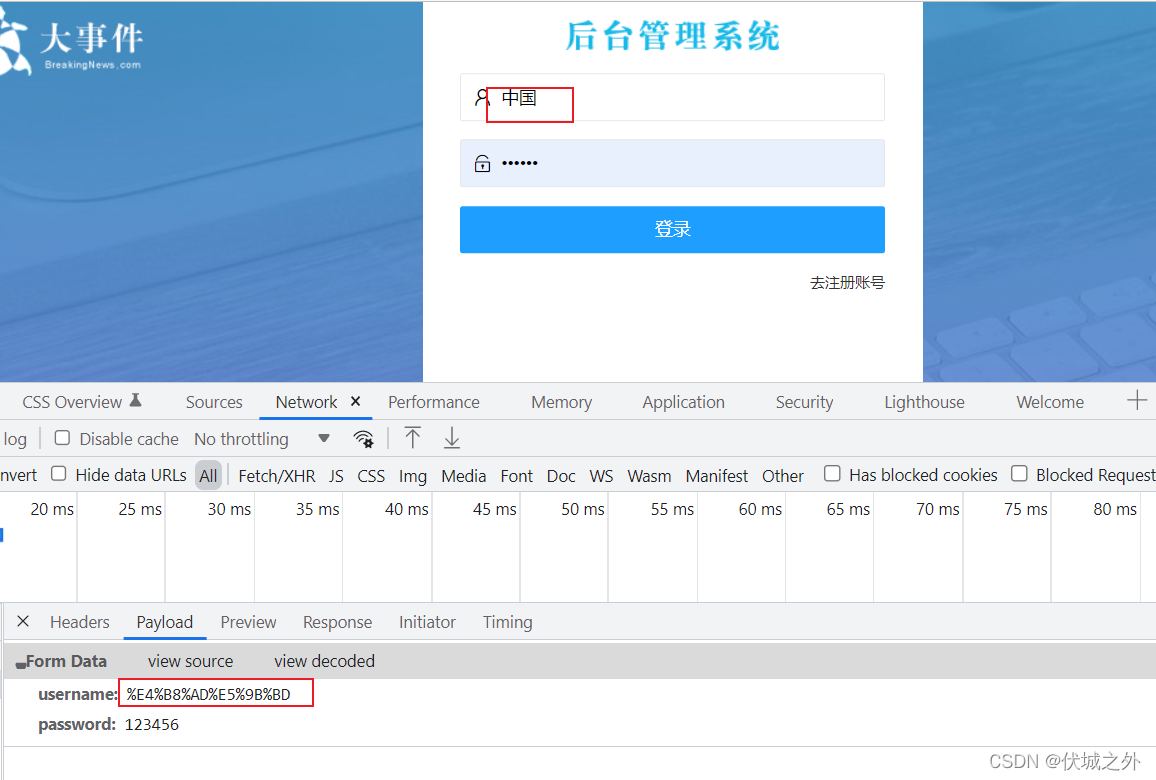
POST請求引數一般放在請求體中,而不是放在URL中,
早期POST請求方法主要用來提交網頁中表單資料,后面出現了ajax,所以可以脫離表單發送POST請求,
POST用于提交表單資料時,通常會將請求體中的資料進行url encode編碼,和上面GET類似,也是由瀏覽器自動完成的,
HTTP回應狀態碼
HTTP回應狀態碼范圍:001~999,可以自定義狀態碼
HTTP協議規定了一些標準狀態碼,主要分為以下幾類
| 狀態碼型別 | 說明 | 常見碼值 | |
| 1XX | Informational資訊性狀態碼 | 代表請求已被接受,需要繼續處理,這類回應是臨時回應,只包含狀態行和某些可選的回應頭資訊,并以空行結束 | 100 |
| 2XX | Success 成功狀態碼 | 代表請求已成功被服務器接收、理解、并接受 | 200,204,206 |
| 3XX | Redirection 重定向狀態碼 | 代表需要客戶端采取進一步的操作才能完成請求,通常,這些狀態碼用來重定向,后續的請求地址(重定向目標)在本次回應的 Location 域中指明 | 301,302,304 |
| 4XX | Client Error 客戶端錯誤 | 請求存在問題,服務器無法處理 | 400,403,404 |
| 5XX | Server Error 服務器錯誤 | 服務器處理請求程序中發送錯誤 | 500,502,503 |
HTTP報文頭
HTTP請求和回應報文都有報文頭,其中的報文頭中欄位可以分為三類:
通用報文頭欄位(請求回應都有)
專用報文頭欄位(請求或回應獨有)
自定義報文頭欄位(通常用來配合服務器的功能)
在通用報文頭欄位中還可以解耦出一個:物體報文頭欄位,即專門用于描述請求體的報文頭欄位

圖片來源:2小時玩轉HTTP協議核心知識 編程 測驗開發 網路知識 爬蟲_嗶哩嗶哩_bilibili
HTTP無狀態性
HTTP無狀態特性 是指兩臺主機之間每次發送的HTTP請求都是獨立的,沒有關聯的,
比如 沈騰 給 大爺 發了一條HTTP請求(你好,我找馬冬梅),大爺回復了一條HTTP回應(什么冬梅???)
沈騰 耐著性子 又給大爺 發了一條 HTTP請求(馬~冬梅啊),大爺回復了一條HTTP回應(馬什么梅啊???)
沈騰 抱著最后一次希望給大爺 再次發了一條HTTP請求(馬~冬~梅 啊),大爺回復一條HTTP回應(馬冬什么???)
沈騰......
沈騰像一臺客戶端,大爺就像一臺服務器,但是這臺服務器不會記錄別人發的請求資訊中的重要資料,而HTTP協議就像沈騰和大爺的交流程序,這個交流程序只負責傳遞訊息,絕也不會幫服務器去記錄請求資訊,所以在大爺看來,沈騰每次問的問題都是一個新問題,
而HTTP無狀態性有好處,也有壞處:
好處是,大爺處理問題的速度很快,他不會真的在大腦中檢索馬冬梅,而是每次都在確認找誰?
壞處是,沈騰慘了,每次問問題都要帶上引數“馬冬梅”,
在實際業務中,HTTP無狀態性主要影響了身份認證,
比如,比如某個網站需要登錄后才能訪問網頁,我們進入網站后,進行登錄操作,然后訪問了登錄后頁面A,然后我們還需訪問頁面B,但是到了B頁面,由于HTTP無狀態性,每次HTTP請求都是獨立的,導致前面的登錄結果無法保留下來,所以我們已經沒有了登錄證明,即無法訪問到B頁面,
所以導致了我們每訪問一個頁面就要重新登錄一次,以獲得登錄證明,給當前頁面,
所以HTTP無狀態給身份認證結果的延續性帶來了挑戰,
而在不改變HTTP協議特性的前提下,出現了很多解決HTTP協議下身份認證結果延續性的方案,其中最具有代表性,最常用的有三個:
Cookie,Seesion,Token
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/393081.html
標籤:其他
上一篇:node拉取微信權限,實作自定義分享微信朋友圈等操作
下一篇:簡單聊聊 OSPF