分布式體系架構相關問題
分布式體系結構集中式架構中,Master 如何判斷 Slave 是否存活呢?
Slave 故障的兩類情況:
- Slave 行程退出;
- Slave 所在服務器宕機或重啟了,
如下圖所示,假設 Master 節點與 3 個 Slave 節點相連,Master 與 Slave 之間畫了兩條線,實線旁寫的是 TCP 長連接,虛線旁寫的是心跳,因為 Master 與 Slave 之間的監控關系是固定的,因此用兩種機制協同來判斷 Slave 是否存活,
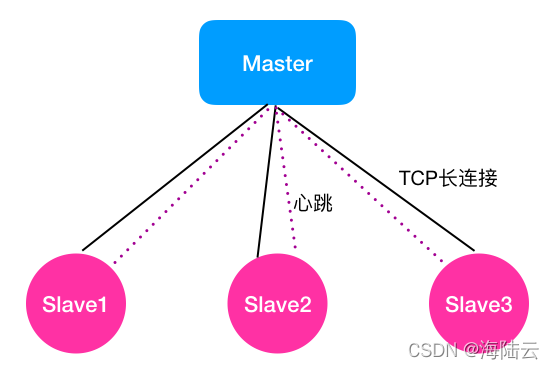
Slave 行程的退出:TCP 長連接就是針對 Slave 行程退出,但是 Slave 所在服務器未故障的情況,這種方式是借助 TCP 長連接的作業原理進行判斷的,TCP 長連接中,TCP 會對對端的 Socket 進行檢測,當發現對端 Socket 不可用時,比如不能發出探測包或探測包未收到回應,會回傳 -1 的狀態,表示連接斷開,
Slave 所在服務器宕機或重啟:由于服務器宕機或重啟,那么系統環境等均不作業 了,這種情況 TCP 長連接也無法進行探測了,TCP 長連接方法在這種場景下無法判斷節點是否故障,
對于這種場景,現有的軟體架構中,基本都采用了心跳方式,其核心策略是,Master 按照周期性(比如每隔 1s)的方式給 Slave 發送心跳包,正常情況下 Slave 收到 Master 發送的心跳包后,會立即回復一個心跳包,告知 Master 自己還活著,當某個 Slave(比如 Slave1)所在服務器故障后,由于 Slave 無法接收到 Master 的心跳包,也就無法回復了,因此,Master 也無法接收到這個 Slave(比如 Slave1)的回復資訊,
系統會設定一個閾值(一般設定為與心跳周期一致),若超過這個閾值還未收到 Slave 節點的回復,Master 就會標記自己與該 Slave 心跳超時, 設定閾值的目的是,解決 Slave 故障情況下,Master 一直收不到心跳資訊而阻塞在那里等待心跳回復的問題,一般連續 k 次 Master 與 Slave 的心跳超時,Master 就會判斷該 Slave 故障了,設定連續 k 次的目的是,降低因為系統做垃圾回識訓網路延遲導致誤判的概率, 這里的 k,主要是根據業務場景進行設定的,如果 k 設定得太小,容易導致故障誤判率過高,因為系統在做垃圾回識訓系統行程正在占用資源時,會阻塞心跳,導致心跳包無法及時回復而超時,從而被誤判,如果 k 設定得太大,會導致故障發現的時間過長,因為故障發現時間 =k* 心跳發送周期,
追問 1:非集中式架構中,如何判斷節點是否存活?
集中式架構中,采用了 TCP 連接和心跳協同判斷節點是否存活,在非集中式架構與集中式架構中,判斷節點是否存活的原理有所不同,因為非集中式架構中節點之間是對等的,沒有 Master 與 Slave 之分,如果每個節點間都建立 TCP 長 連接,假設集群中有 n 個節點,那么每個節點均需要與其他 n-1 個節點建長連接,這將導致每個節點的資源占用都會非常多,因此非集中式架構是采用心跳的方式進行判斷的,
如果像集中式架構那樣,每個節點與其他 n-1 個節點都發送心跳的話, 整個集群中同一時間心跳訊息為 n*(n-1),訊息量也特別大,甚至會導致網路風暴,其實非集中式架構與集中式架構中的心跳包不同,非集中式架構中采用的心跳方式的核心思想是,每個節點被 b(1≤b<n)個節點監控,以減少心跳資訊量,
以 Akka 的原理為例,看看 b 的取值原則:
- 不設定 b 的值,b 默認取值的原則是:若集群中節點總數 n 小于 6, b=n-1;若 n 大于等于 6,b=5,
- 設定 b 的值,則 b 以用戶設定的值為準,
Akka 集群中通過心跳方式判斷節點是否存活:
- Akka 中集群組建完成后,每個節點擁有整個集群中的節點串列,
- 每個節點根據集群節點串列,計算哈希值(比如根據節點 ID 計算一個哈希值),然后基于哈希值,將所有節點組成一個哈希環(比如,從小到大的順序),如下圖所示,由于每個節點上的計算方法一致,因此雖然每個節點獨立計算,但每個節點上維護的哈希環是一致的,
- 根據哈希環,針對每個節點逆時針或順時針方向選擇 b(圖中設定 b=2)個臨近節點作為監控節點,比如圖中 Node 2 和 Node3 監控 Node1,Node 3 和 Node4 監控 Node2,以此類推,由于每個節點被 b 個節點監控,反過來也可以說,在這個環上每個節點監控 b 個節點,因此具體的實作方式是每個節點按照逆時針或順時針方向選擇 b 個 節點進行監控,
- 當某個節點發現自己監控的節點心跳超時時(比如 Node 2 發現 Node1 心跳超時), 則標記該節點不可達(Node2 標記 Node1 不可達),并將該資訊通過 Gossip 協議傳播給集群中的其他節點,
- 如果某個節點被標記為不可達之后(比如 Node1 不可達),若不將該節點踢出集群, 那么 Node2 和 Node3 仍然會給 Node1 發送心跳,若后面 Node2 又發現 Node1 心跳可達時,則重新將 Node1 更新為可達狀態,然后同步給集群中其他節點,
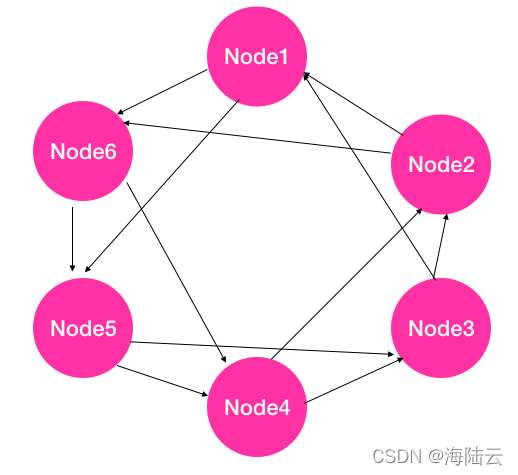
這里的判斷心跳超時機制,可采用集中式方法中的連續 k 次心跳超時的方法進行判斷,也可以通過歷史心跳資訊進行預測,
追加 2: 一個集群為什么會存在雙主的場景呢?
判斷節點存活的方法主要是通過心跳的方式,如果是因為網路連接斷開,那么節點之間就會被誤判為對方故障了,在主備場景下,通常會出現雙主的情況,
在主備場景下,正常情況下,主節點提供服務,備節點是對主節點的資料、狀態進行備份,以確保主故障后備升主后業務可以正常運行,主備節點之間通常會通過心跳的方式進行檢測,目的是監控主節點是否故障,若故障則備升主,保證業務運行,
如果主備節點之間的網路連接斷開了,那么主節點與備節點之間心跳均不可達, 因此主節點會認為備節點故障,此時主節點會繼續提供服務,而備節點會認為主節點故障, 備升主,集群中就出現了雙主的場景,
分布計算技術相關問題
在分布式計算技術中,離線計算、批量計算、實時計算、流式計算這四個概念常常會弄混,離線計算和批量計算,實時計算和流式計算到底是什么呢?離線計算和批量計算、實時計算和流式計算分別是等價的嗎?
離線計算:主要的應用場景是對時延要求不敏感、計算量大、需要計算很長時間(比如需要數天、數周甚至數月)的場景,比如大資料分析、復雜的 AI 模型訓練(比如神經網路)等,這種場景如果采用在線計算或實時計算的話,通常會存在資料量不夠或大量計算影響正在運 行的業務等問題,因此往往會采用離線計算的方式,
離線計算方式的核心思想是,先采集資料,并將這些資料存盤起來,待資料達到一定量或規模時再進行計算,然后將計算結果(比如離線訓練的模型)應用到實際業務場景中,
批量計算:批量計算通常是指,將原始資料集劃分為多個資料子集,然后每個任務負責處理一個資料子集,多個任務并發執行,以加快整個資料的處理,比如,分布式計算模式 MR 計算模式,MapReduce 中的 Map 其實就屬于批量計算,Map 計算的結果會通過 Reduce 進行匯總,
實時計算:實時計算其實是和離線計算相對應的,離線計算對時延要求不敏感,相反,實時計算對時延的要求比較敏感,這種模式需要短時間執行完成并輸出結果,比如秒級、分鐘級,強調時效,通常用于秒殺、搶購等場景,實時計算由于時延要求低,因此計算量通常不大、資料量也不會太多,所計算的資料往往是 K、M 級別的,
流式計算:分布式計算模式 Stream 流計算強調的是實時性,資料一旦產生就會被立即處理,當一條資料被處理完成后,會立刻通過網路傳輸到下一個節點,由下一個節點繼續處理,這種模式通常用于商業場景中每天的報表統計、持續多天的促銷活動效果分析等,
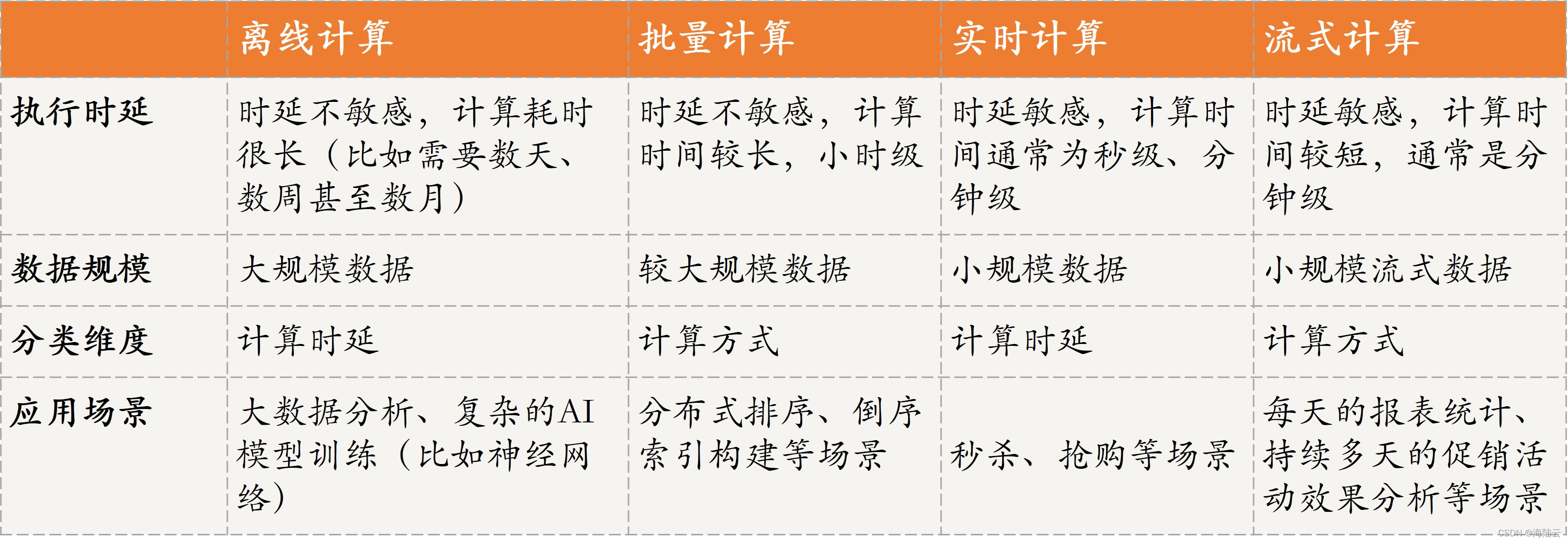
- 離線計算和批量計算對任務執行的時延不敏感;
- 實時計算和流式計算對任務執行的時延敏感;
- 離線計算和實時計算是從計算時延的維度進行分類的;
- 批量計算和流式計算是從計算方式的維度進行分類的;
因此不能將離線計算和批量計算直接等同,也不能將實時計算和流式計算直接等同,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/394205.html
標籤:其他
上一篇:資料結構期末復習