K8S架構與核心技術介紹
參考文獻:
https://jimmysong.io/kubernetes-handbook/concepts/concepts.html
https://www.infoq.cn/article/kubernetes-and-cloud-native-applications-part01/
文章目錄
- K8S架構與核心技術介紹
- 1. 架構圖
- 1.1 整體結構圖
- 1.2 組件間的協議
- 1.3 master與node架構圖
- 1.4 分層架構圖
- 2. K8s核心技術概念
- 2.1 API物件
- 2.2 Pod
- 2.3 RC:副本控制器 Replication Controller
- 2.4 RS:副本集 Replica Set
- 2.5 部署:Deployment
- 2.6 服務:service
- 2.7 任務:Job
- 2.8 后臺支撐服務集:DaemonSet
- 2.9 有狀態服務集:StatefulSet
- 2.10 Volume:存盤卷
- 2.11 Node:節點
- 2.12 Secret:密鑰物件
- 2.13 namespace:命名空間
- 2.14 開放介面
- CRI
- CNI
- CSI
- 2.15 資源物件
- 3. 集群資源管理
- 3.1 Node
- 3.2 Namespace
- 3.3 Label
- 3.4 污點和容忍
- 3.5 垃圾回收
- 總結
- 功能
1. 架構圖
1.1 整體結構圖
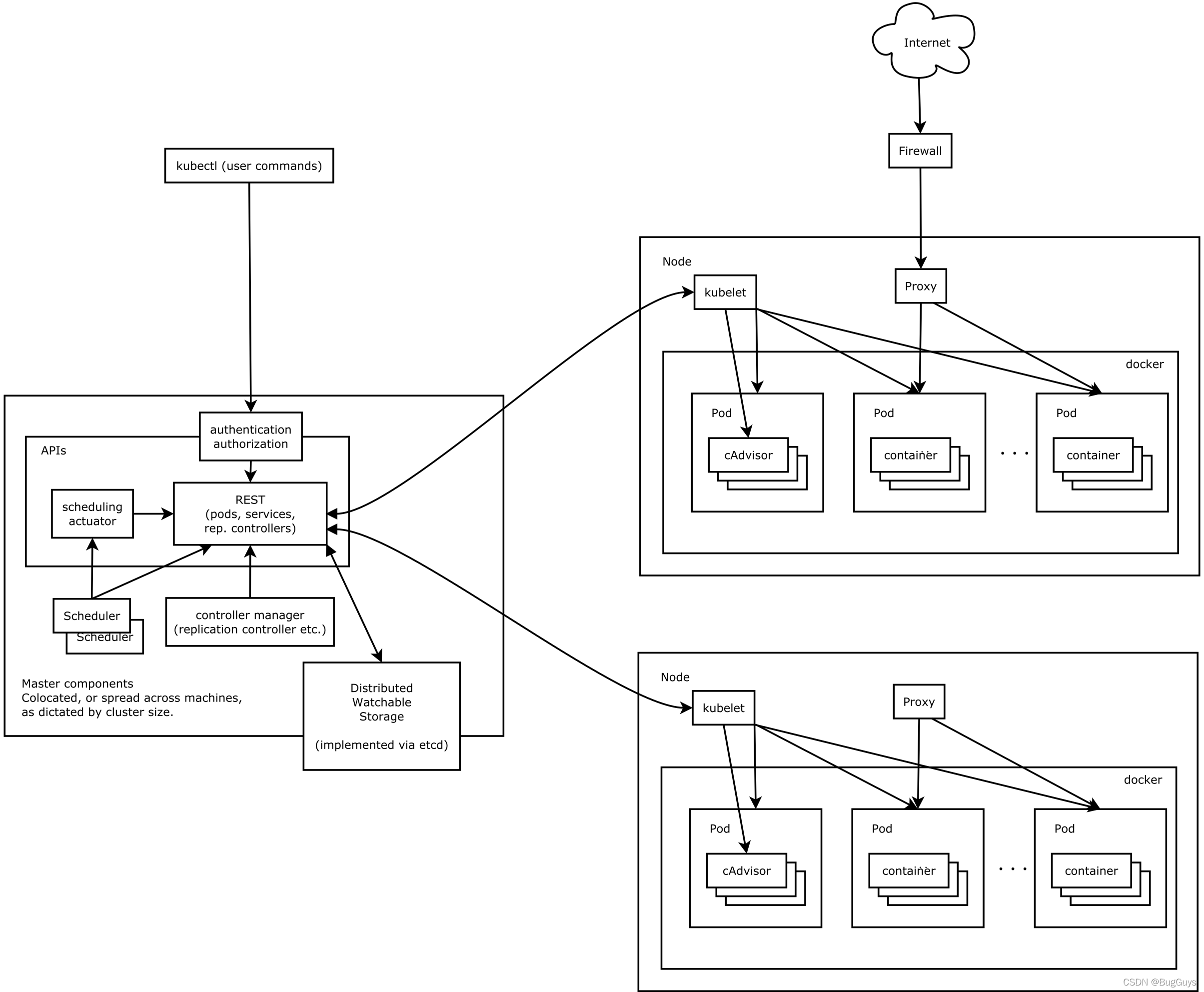
1.2 組件間的協議
-
CNI: CNI是Container Network Interface的是一個標準的,通用的介面 ;用于連接容器管理系統和網路插件,提供一個容器所在的network namespace,將network interface插入該network namespace中(比如veth的一端),并且在宿主機做一些必要的配置(例如將veth的另一端加入bridge中),最后對namespace中的interface進行IP和路由的配置,現有解決方案:flannel,calico,weave,
參考鏈接:https://blog.csdn.net/zhonglinzhang/article/details/82697524 -
CRI: 容器運行時介面(Container Runtime Interface);CRI包含了一組protocol buffers,gRPC API,相關的庫; 提供可插拔的容器運行時 ;k8s節點的底層由一個叫做“容器運行時”的軟體進行支撐,它負責比如啟停容器這樣的事情;Docker是K8s中最常用的容器運行時;
參考鏈接:https://www.kubernetes.org.cn/1079.html
-
OCI: 圍繞容器的格式和運行時制定一個開放的工業化標準,并推動這個標準,保持容器的靈活性和開放性,容器能運行在任何的硬體和系統上,容器不應該系結到特定的客戶機或編排堆疊,不應該與任何特定的供應商緊密關聯,并且可以跨多種作業系統;
參考鏈接:https://www.jianshu.com/p/c7748893ab00
官網:https://opencontainers.org/
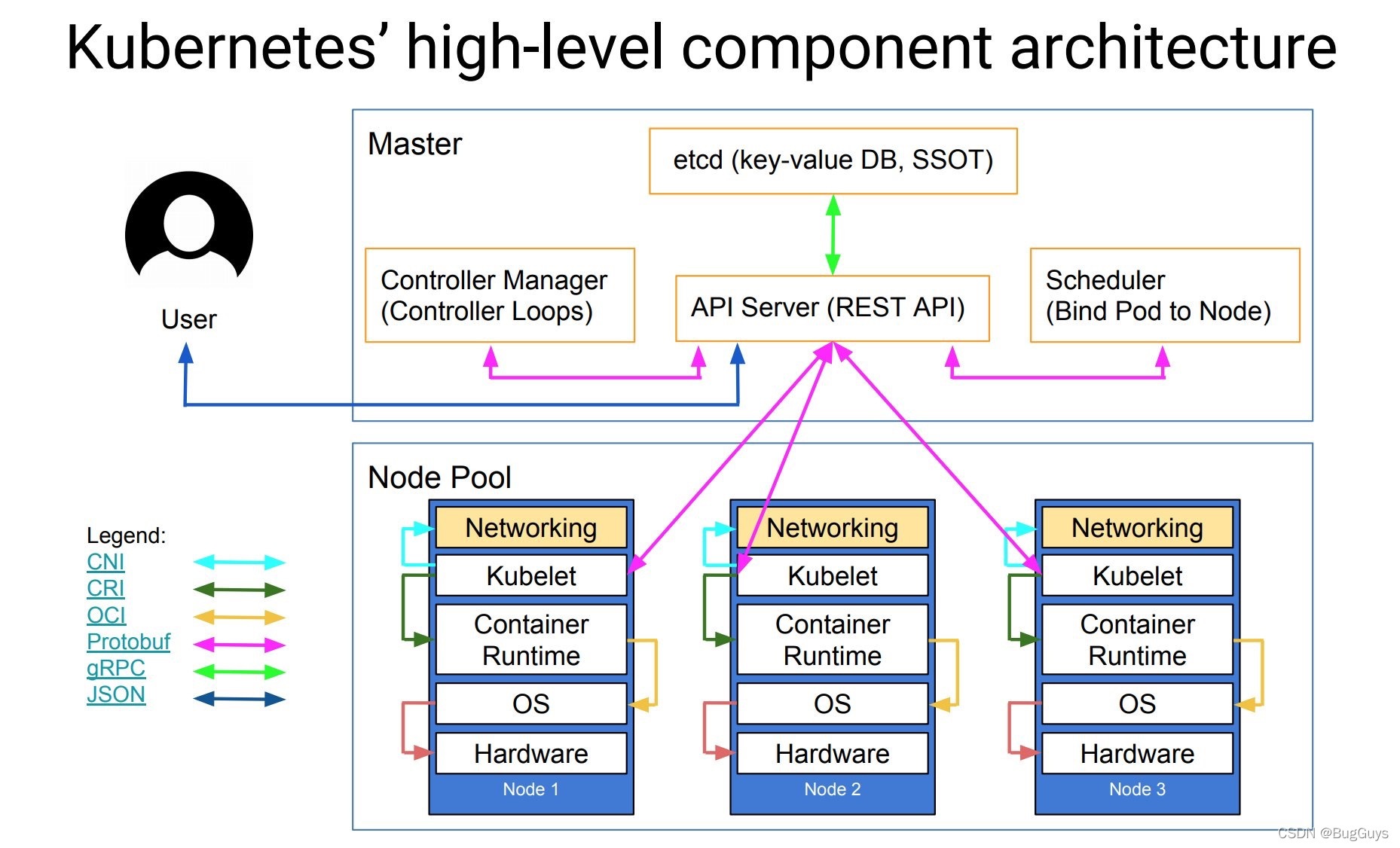
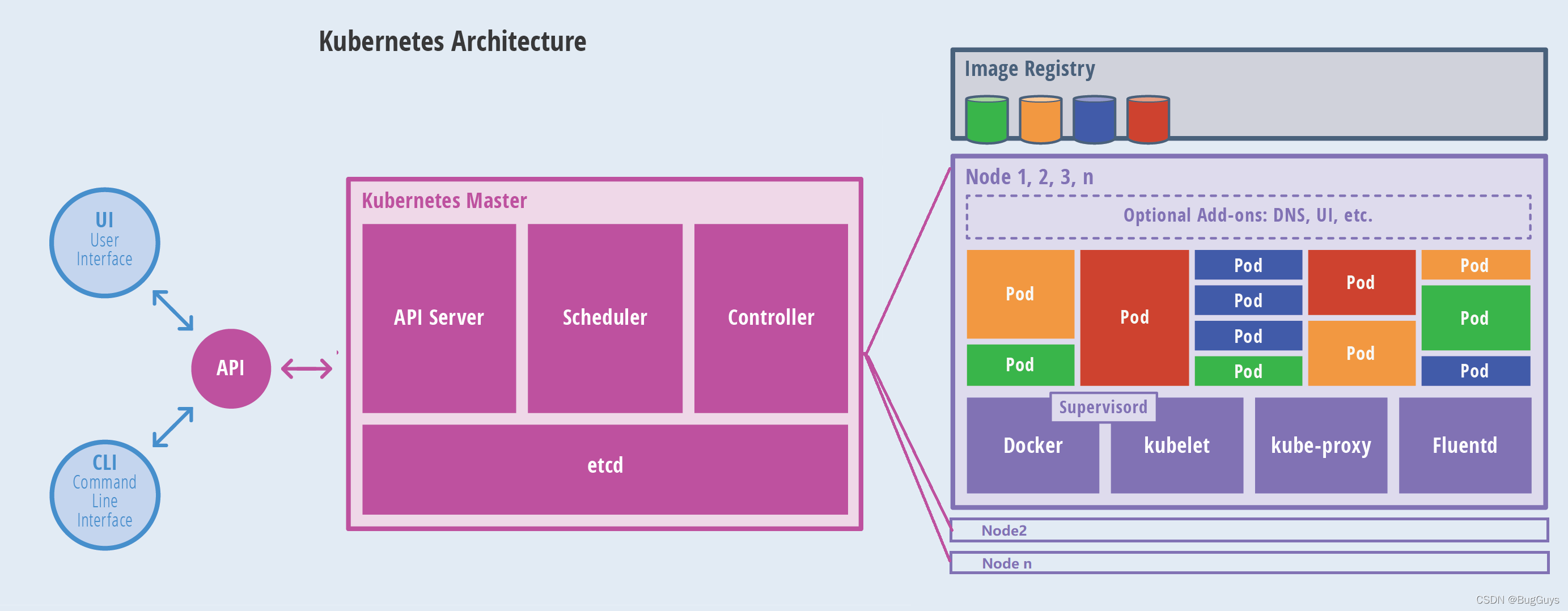
1.3 master與node架構圖
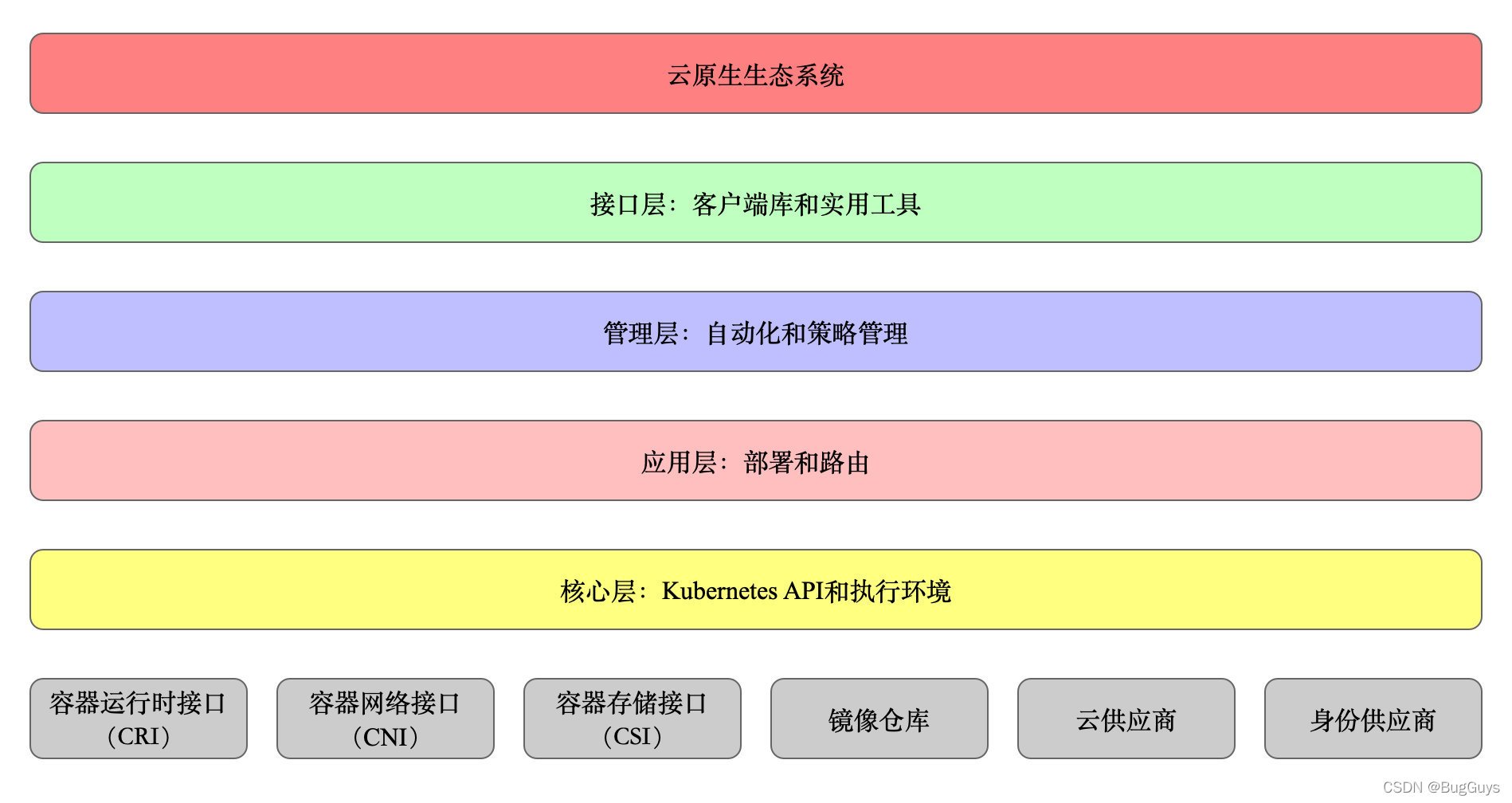
1.4 分層架構圖
核心組件:
-
etcd 保存了整個集群的狀態;
etcd是構建一個高可用的分布式鍵值(key-value)資料庫,etcd內部采用
raft協議作為一致性演算法,etcd基于Go語言實作 ;主要用于共享配置和服務發現 ;原理影片演示:http://thesecretlivesofdata.com/raft/
-
apiserver 提供了資源操作的唯一入口,并提供認證、授權、訪問控制、API 注冊和發現等機制;
-
controller manager 負責維護集群的狀態,比如故障檢測、自動擴展、滾動更新等;
-
scheduler 負責資源的調度,按照預定的調度策略將 Pod 調度到相應的機器上;
-
kubelet 負責維護容器的生命周期,同時也負責 Volume(CSI)和網路(CNI)的管理;
-
Container runtime 負責鏡像管理以及 Pod 和容器的真正運行(CRI);
-
kube-proxy 負責為 Service 提供 cluster 內部的服務發現和負載均衡;
分層介紹:
- 核心層:Kubernetes 最核心的功能,對外提供 API 構建高層的應用,對內提供插件式應用執行環境;
- 應用層:部署(無狀態應用、有狀態應用、批處理任務、集群應用等)和路由(服務發現、DNS 決議等)、Service Mesh(部分位于應用層);
- 管理層:系統度量(如基礎設施、容器和網路的度量),自動化(如自動擴展、動態 Provision 等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy 等)、Service Mesh(部分位于管理層);
- 介面層:kubectl 命令列工具、客戶端 SDK 以及集群聯邦;
- 生態系統:在介面層之上的龐大容器集群管理調度的生態系統,可以劃分為兩個范疇;
- Kubernetes 外部:日志、監控、配置管理、CI/CD、Workflow、FaaS、OTS 應用、ChatOps、GitOps、SecOps 等
- Kubernetes 內部:CRI、CNI、CSI、鏡像倉庫、Cloud Provider、集群自身的配置和管理等
2. K8s核心技術概念
2.1 API物件
API物件是K8S的集群中管理操作單元;每個API物件都有3大類屬性:元資料metadata,規范spec和狀態status;元資料:標識API物件;
API物件至少含有3個元資料:namespace,name,uid;
API物件通過spec去設定配置; 用戶通過配置系統的理想狀態來改變系統 , 所有的操作都是宣告(Declarative)的而不是命令式(Imperative)的 ; 宣告式操作在分布式系統中的好處是穩定,不怕丟操作或運行多次 ;
2.2 Pod
Pod 的設計理念是支持多個容器在一個 Pod 中共享網路地址和檔案系統,可以通過行程間通信和檔案共享這種簡單高效的方式組合完成服務,Pod 對多容器的支持是 K8 最基礎的設計理念 ;
Pod 是 Kubernetes 集群中所有業務型別的基礎,可以看作運行在 Kubernetes 集群中的小機器人,不同型別的業務就需要不同型別的小機器人去執行,
目前 Kubernetes 中的業務主要可以分為
| 業務 | API物件 |
|---|---|
| 長期伺服型(long-running) | Deployment |
| 批處理型(batch) | Job |
| 節點后臺支撐型(node-daemon) | DaemonSet |
| 有狀態應用型(stateful application) | StatefulSet |
2.3 RC:副本控制器 Replication Controller
保證 Pod 高可用的 API 物件; 通過監控運行中的 Pod 來保證集群中運行指定數目的 Pod 副本,指定的數目可以是多個也可以是 1 個;少于指定數目,RC 就會啟動運行新的 Pod 副本;多于指定數目,RC 就會殺死多余的 Pod 副本,即使在指定數目為 1 的情況下,通過 RC 運行 Pod 也比直接運行 Pod 更明智,因為 RC 也可以發揮它高可用的能力,保證永遠有 1 個 Pod 在運行,RC 是 Kubernetes 較早期的技術概念,只適用于長期伺服型的業務型別,比如控制小機器人提供高可用的 Web 服務,
2.4 RS:副本集 Replica Set
RS 是新一代 RC,提供同樣的高可用能力,區別主要在于 RS 后來居上,能支持更多種類的匹配模式,副本集物件一般不單獨使用,而是作為 Deployment 的理想狀態引數使用,
RC 和 RS 主要是控制提供無狀態服務的,其所控制的 Pod 的名字是隨機設定的,一個 Pod 出故障了就被丟棄掉,在另一個地方重啟一個新的 Pod,名字變了,名字和啟動在哪兒都不重要,重要的只是 Pod 總數;
對于 RC 和 RS 中的 Pod,一般不掛載存盤或者掛載共享存盤,保存的是所有 Pod 共享的狀態
2.5 部署:Deployment
部署表示用戶對 Kubernetes 集群的一次更新操作,部署是一個比 RS 應用模式更廣的 API 物件,可以是創建一個新的服務,更新一個新的服務,也可以是滾動升級一個服務,滾動升級一個服務,實際是創建一個新的 RS,然后逐漸將新 RS 中副本數增加到理想狀態,將舊 RS 中的副本數減小到 0 的復合操作;這樣一個復合操作用一個 RS 是不太好描述的,所以用一個更通用的 Deployment 來描述,以 Kubernetes 的發展方向,未來對所有長期伺服型的的業務的管理,都會通過 Deployment 來管理,
2.6 服務:service
RC、RS 和 Deployment 只是保證了支撐服務的微服務 Pod 的數量,但是沒有解決如何訪問這些服務的問題,一個 Pod 只是一個運行服務的實體,隨時可能在一個節點上停止,在另一個節點以一個新的 IP 啟動一個新的 Pod,因此不能以確定的 IP 和埠號提供服務,要穩定地提供服務需要服務發現和負載均衡能力,服務發現完成的作業,是針對客戶端訪問的服務,找到對應的的后端服務實體,在 K8 集群中,客戶端需要訪問的服務就是 Service 物件,每個 Service 會對應一個集群內部有效的虛擬 IP,集群內部通過虛擬 IP 訪問一個服務,在 K8s 集群中微服務的負載均衡是由 Kube-proxy 實作的,Kube-proxy 是 K8s 集群內部的負載均衡器,它是一個分布式代理服務器,在 K8s 的每個節點上都有一個;這一設計體現了它的伸縮性優勢,需要訪問服務的節點越多,提供負載均衡能力的 Kube-proxy 就越多,高可用節點也隨之增多,與之相比,我們平時在服務器端做個反向代理做負載均衡,還要進一步解決反向代理的負載均衡和高可用問題,
2.7 任務:Job
Job 是 Kubernetes 用來控制批處理型任務的 API 物件,批處理業務與長期伺服業務的主要區別是批處理業務的運行有頭有尾,而長期伺服業務在用戶不停止的情況下永遠運行,Job 管理的 Pod 根據用戶的設定把任務成功完成就自動退出了,成功完成的標志根據不同的 spec.completions 策略而不同:單 Pod 型任務有一個 Pod 成功就標志完成;定數成功型任務保證有 N 個任務全部成功;作業佇列型任務根據應用確認的全域成功而標志成功,
2.8 后臺支撐服務集:DaemonSet
長期伺服型和批處理型服務的核心在業務應用,可能有些節點運行多個同類業務的 Pod,有些節點上又沒有這類 Pod 運行;而后臺支撐型服務的核心關注點在 Kubernetes 集群中的節點(物理機或虛擬機),要保證每個節點上都有一個此類 Pod 運行,節點可能是所有集群節點也可能是通過 nodeSelector 選定的一些特定節點,典型的后臺支撐型服務包括,存盤,日志和監控等在每個節點上支持 Kubernetes 集群運行的服務,
2.9 有狀態服務集:StatefulSet
是用來控制有狀態服務,StatefulSet 中的每個 Pod 的名字都是事先確定的,不能更改, StatefulSet 中的 Pod,每個 Pod 掛載自己獨立的存盤,如果一個 Pod 出現故障,從其他節點啟動一個同樣名字的 Pod,要掛載上原來 Pod 的存盤繼續以它的狀態提供服務,
適合于 StatefulSet 的業務包括資料庫服務 MySQL 和 PostgreSQL,集群化管理服務 ZooKeeper、etcd 等有狀態服務,StatefulSet 的另一種典型應用場景是作為一種比普通容器更穩定可靠的模擬虛擬機的機制;
使用 StatefulSet,Pod 仍然可以通過漂移到不同節點提供高可用,而存盤也可以通過外掛的存盤來提供高可靠性,StatefulSet 做的只是將確定的 Pod 與確定的存盤關聯起來保證狀態的連續性,
2.10 Volume:存盤卷
Kubernetes 的存盤卷的生命周期和作用范圍是一個 Pod,每個 Pod 中宣告的存盤卷由 Pod 中的所有容器共享;
2.11 Node:節點
Kubernetes 集群中的計算能力由 Node 提供,最初 Node 稱為服務節點 Minion,后來改名為 Node,Kubernetes 集群中的 Node 也就等同于 Mesos 集群中的 Slave 節點,是所有 Pod 運行所在的作業主機,可以是物理機也可以是虛擬機,不論是物理機還是虛擬機,作業主機的統一特征是上面要運行 kubelet 管理節點上運行的容器,
2.12 Secret:密鑰物件
Secret 是用來保存和傳遞密碼、密鑰、認證憑證這些敏感資訊的物件,使用 Secret 的好處是可以避免把敏感資訊明文寫在組態檔里,在 Kubernetes 集群中配置和使用服務不可避免的要用到各種敏感資訊實作登錄、認證等功能,例如訪問 AWS 存盤的用戶名密碼,為了避免將類似的敏感資訊明文寫在所有需要使用的組態檔中,可以將這些資訊存入一個 Secret 物件,而在組態檔中通過 Secret 物件參考這些敏感資訊,這種方式的好處包括:意圖明確,避免重復,減少暴漏機會,
2.13 namespace:命名空間
命名空間為 Kubernetes 集群提供虛擬的隔離作用,Kubernetes 集群初始有兩個命名空間,分別是默認命名空間 default 和系統命名空間 kube-system,除此以外,管理員可以可以創建新的命名空間滿足需要,
2.14 開放介面
CRI
容器運行時介面(Container Runtime Interface); CRI中定義了容器和鏡像的服務的介面,因為容器運行時與鏡像的生命周期是彼此隔離的,因此需要定義兩個服務,該介面使用Protocol Buffer,基于gRPC ;
Container Runtime實作了CRI gRPC Server,包括RuntimeService和ImageService,該gRPC Server需要監聽本地的Unix socket,而kubelet則作為gRPC Client運行,
- RuntimeService:容器和Sandbox運行時管理,
- ImageService:提供了從鏡像倉庫拉取、查看、和移除鏡像的RPC,
CNI
Container Network Interface的是一個標準的通用的介面 ; 由一組用于配置 Linux 容器的網路介面的規范和庫組成,同時還包含了一些插件,CNI 僅關心容器創建時的網路分配,和當容器被洗掉時釋放網路資源,
CSI
Container Storage Interface代表容器存盤介面; 借助 CSI 容器編排系統(CO)可以將任意存盤系統暴露給自己的容器作業負載 ; 部署 CSI 兼容卷驅動后,用戶可以使用 csi 作為卷型別來掛載驅動提供的存盤,
2.15 資源物件
| 類別 | 名稱 |
|---|---|
| 資源物件 | Pod、ReplicaSet、ReplicationController、Deployment、StatefulSet、DaemonSet、Job、CronJob、HorizontalPodAutoscaling、Node、Namespace、Service、Ingress、Label、CustomResourceDefinition |
| 存盤物件 | Volume、PersistentVolume、Secret、ConfigMap |
| 策略物件 | SecurityContext、ResourceQuota、LimitRange |
| 身份物件 | ServiceAccount、Role、ClusterRole |
3. 集群資源管理
3.1 Node
描述:
是K8S的集群作業節點,可以是物理機也可以是虛擬機;
Node狀態:
- Address
- HostName:可以被 kubelet 中的
--hostname-override引數替代, - ExternalIP:可以被集群外部路由到的 IP 地址,
- InternalIP:集群內部使用的 IP,集群外部無法訪問,
- HostName:可以被 kubelet 中的
- Condition
- OutOfDisk:磁盤空間不足時為
True - Ready:Node controller 40 秒內沒有收到 node 的狀態報告為
Unknown,健康為True,否則為False, - MemoryPressure:當 node 有記憶體壓力時為
True,否則為False, - DiskPressure:當 node 有磁盤壓力時為
True,否則為False,
- OutOfDisk:磁盤空間不足時為
- Capacity
- CPU
- 記憶體
- 可運行的最大 Pod 個數
- SystemInfo:節點的一些版本資訊,如 OS、kubernetes、docker 等
# 查看節點資訊
kubectl describe node NODENAME
# 禁止Pod調度到該節點上
kubectl corndon NODENAME
# 驅逐該節點上的所有 Pod
kubectl drain NODENAME
3.2 Namespace
描述:
簡寫ns,在集群中,我們可以使用namespace劃分出多個“虛擬集群”,這些ns之間可以完全隔離,也可以跨ns,讓一個ns中的service訪問到其他ns的服務; 比如 Traefik ingress 和 kube-systemnamespace 下的 service 就可以為整個集群提供服務,這些都需要通過 RBAC 定義集群級別的角色來實作;
注意:
不是所有的資源物件都對應ns,其中node和persistentVolume就不屬于任何ns;
3.3 Label
描述:
label是資源上的標識,用來對它們進行區分和選擇;
特點:
- 一個label會以kv形式附加到各種物件上;Node,Pod,Service
- 一個資源物件可以定義人一多數量的Label,同一個Label也可以被添加到任意數量的資源物件上去;
- label通常再資源物件確定時定義,也可以在資源創建后動態添加或洗掉;
可以通過label實作資源的多維度分組,以便靈活,方便的進行資源分配,調度,配置,部署等管理作業;
常用的標簽如下:
版本標簽:“version”:“release”,
環境標簽:
"environment": "dev","environment": "qa","environment": "production"架構標簽:
"tier": "frontend","tier": "backend","tier": "cache"
標簽選擇器:用于查詢和篩選擁有某些標簽的資源物件;
-
等式選擇器 equality-based
可以使用
=、==、!=運算子,可以使用逗號分隔多個運算式name=slave:選擇所有包含k=name,v=slave的物件
env!=prod:選擇所有包括k=env且v!=prod的物件
-
集合選擇器 set-based
可以使用
in、notin、!運算子,另外還可以沒有運算子,直接寫出某個label的key,表示過濾有某個key的object而不管該key的value是何值,!表示沒有該label的objectname in (master, slave):選擇所有包含k=name且v=master或者v=slave物件
name not in (frontend):選擇所有包含k=name且v不等于frontend的物件
標簽的選擇條件可以使用多個,此時將多個標簽選擇器進行組合,使用,進行分隔即可;
name=slave,env!=prod
name not in(frontend),env!=prod
Label key的組成:
- 不得超過63個字符
- 可以使用前綴,使用/分隔,前綴必須是DNS子域,不得超過253個字符,系統中的自動化組件創建的label必須指定前綴,
kubernetes.io/由kubernetes保留 - 起始必須是字母(大小寫都可以)或數字,中間可以有連字符、下劃線和點
Label value的組成:
- 不得超過63個字符
- 起始必須是字母(大小寫都可以)或數字,中間可以有連字符、下劃線和點
3.4 污點和容忍
描述:
Taint(污點)和 Toleration(容忍)可以作用于 node 和 pod 上,其目的是優化 pod 在集群間的調度,這跟節點親和性類似,只不過它們作用的方式相反,具有 taint 的 node 和 pod 是互斥關系,而具有節點親和性關系的 node 和 pod 是相吸的,另外還有可以給 node 節點設定 label,通過給 pod 設定 nodeSelector 將 pod 調度到具有匹配標簽的節點上,
Taint 和 toleration 相互配合,可以用來避免 pod 被分配到不合適的節點上,每個節點上都可以應用一個或多個 taint ,這表示對于那些不能容忍這些 taint 的 pod,是不會被該節點接受的,如果將 toleration 應用于 pod 上,則表示這些 pod 可以(但不要求)被調度到具有相應 taint 的節點上,
污點
通過node上添加污點屬性,來決定是否允許Pod調度過來;
Node被設定上污點之后,就和Pod之間存在了一種相斥的關系,進而拒絕Pod調度過來,甚至可以將已存在的Pod驅逐出去;
污點格式:key=value:effect,key和value是污點的標簽,effect描述污點的作用,支持如下三個選項:
- PreferNoSchedule: k8s盡量不把pod調度到該污點Node上,除非沒有其他節點可調度;
- NoSchedule: k8s將不會把Pod調度到該污點Node上,已存在的Pod將繼續運行;
- NoExecute:k8s將不會把Pod調度到具有該污點的Node上,同時也會將Node上已存在的Pod驅逐;
命令:
# 設定污點
kubectl taint nodes node1 key=value:effect
# 去除污點
kubectl taint nodes node1 key:effect-
# 去除所有污點
kubectl taint nodes node1 key-
# 例如:
# 為node1設定污點
kubectl taint nodes node1 tag=test:PreferNoSchedule
# 為node1取消污點
kubectl taint nodes node1 tag:PreferNoSchedule-
# 為node1洗掉去除污點
kubectl taint nodes node1 tag-
# 查看node1 污點
kubectl describe node node1
容忍
若將pod調度到一個有污點的node上去,需要用到容忍;
污點就是拒絕,容忍就是忽略,Node通過污點拒絕pod調度上去,pod通過容忍忽略拒絕;
pod的配置
spec:
containers:
- name: nginx
tolerations: # 添加容忍
- key: "tag" # 對應要容忍的污點的鍵,空著意味匹配所有的鍵
operator: "Equal" # 運算子,支持Equal和Exists(默認)
value: "tests" # 容忍的污點的值
effect: "NoExecute" # 添加容忍規則,要個污點規則一致
tolerationSeconds: # 容忍時間, 當effect為NoExecute時生效,表示pod在Node上的停留時間
3.5 垃圾回收
描述:
對于 ReplicaSet、StatefulSet、DaemonSet、Deployment、Job、 CronJob 等創建或管理的物件,會自動為其設定 ownerReferences欄位的值;K8s的垃圾回識訓制需要依賴于ownerReferences;他標記了從屬物件的所有者;
目前有兩大類GC:
-
級聯洗掉:所有者洗掉,從屬物件也被洗掉;
分為前臺級聯洗掉Foreground和后臺級聯洗掉Background模式;
- Foreground前臺級聯洗掉:所有從屬物件洗掉完畢后洗掉所有者物件;當所有者洗掉時會進入“正在洗掉”狀態,仍可以通過RestApi查詢到當前物件;
- Background后臺級聯洗掉: 立即洗掉所有者的物件,并由垃圾回收器在后臺洗掉其從屬物件 ; 用等待洗掉從屬物件的時間;
-
孤兒洗掉orphan:所有者洗掉,從屬物件變成孤兒;
直接洗掉所有者物件,并將從屬物件中的 ownerReference 元資料設定為默認值,之后垃圾回收器會確定孤兒物件并將其洗掉;
垃圾回收器的作業流程:
由Scanner、Garbage Processor 和 Propagator 組成;
-
Scanner:它會檢測 K8s 集群中支持的所有資源,并通過控制回圈周期性地檢測,它會掃描系統中的所有資源,并將每個物件添加到"臟佇列"(dirty queue)中,
-
Garbage Processor:它由在"臟佇列"上作業的 worker 組成,每個 worker 都會從"臟佇列"中取出物件,并檢查該物件里的 OwnerReference 欄位是否為空,如果為空,那就從“臟佇列”中取出下一個物件進行處理;如果不為空,它會檢測 OwnerReference 欄位內的 owner resoure object 是否存在,如果不存在,會請求 API 服務器洗掉該物件,
-
Propagator :用于優化垃圾回收器,它包含以下三個組件:
- EventQueue:負責存盤 k8s 中資源物件的事件;
- DAG(有向無環圖):負責存盤 k8s 中所有資源物件的 owner-dependent 關系;
- Worker:從 EventQueue 中取出資源物件的事件,并根據事件的型別會采取操作;
在有了 Propagator 的加入之后,我們完全可以僅在 GC 開始運行的時候,讓 Scanner 掃描系統中所有的物件,然后將這些資訊傳遞給 Propagator 和“臟佇列”,只要 DAG 一建立起來之后,那么 Scanner 其實就沒有再作業的必要了,
總結
從 Kubernetes 的系統架構、技術概念和設計理念,我們可以看到 Kubernetes 系統最核心的兩個設計理念:一個是 容錯性,一個是 易擴展性,容錯性實際是保證 Kubernetes 系統穩定性和安全性的基礎,易擴展性是保證 Kubernetes 對變更友好,可以快速迭代增加新功能的基礎,
功能
-
具備完善的集群管理能力;
-
透明的服務注冊和服務發現機制;
-
內建負載均衡,故障發現和自我修復;
-
服務滾動升級和在線擴容;
-
可擴展的自動調度機制;
-
資源配額管理;
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/395086.html
標籤:其他