我有兩個資料框 df1 和 df2。
df1 有 174 列,df2 有 175 列。
我如何才能找到哪一列是額外的?
uj5u.com熱心網友回復:
只需將列串列轉換為集合,并diff在這些集合上使用操作,如下所示:
df2.columns.toSet.diff(df1.columns.toSet)
請注意,比較的順序很重要,例如,df1.columns.toSet.diff(df2.columns.toSet)不會產生所需的差異。如果你想讓 diff 獨立于位置,你可以使用這樣的東西:
df2.columns.toSet.diff(df1.columns.toSet).union(
df1.columns.toSet.diff(df2.columns.toSet))
uj5u.com熱心網友回復:
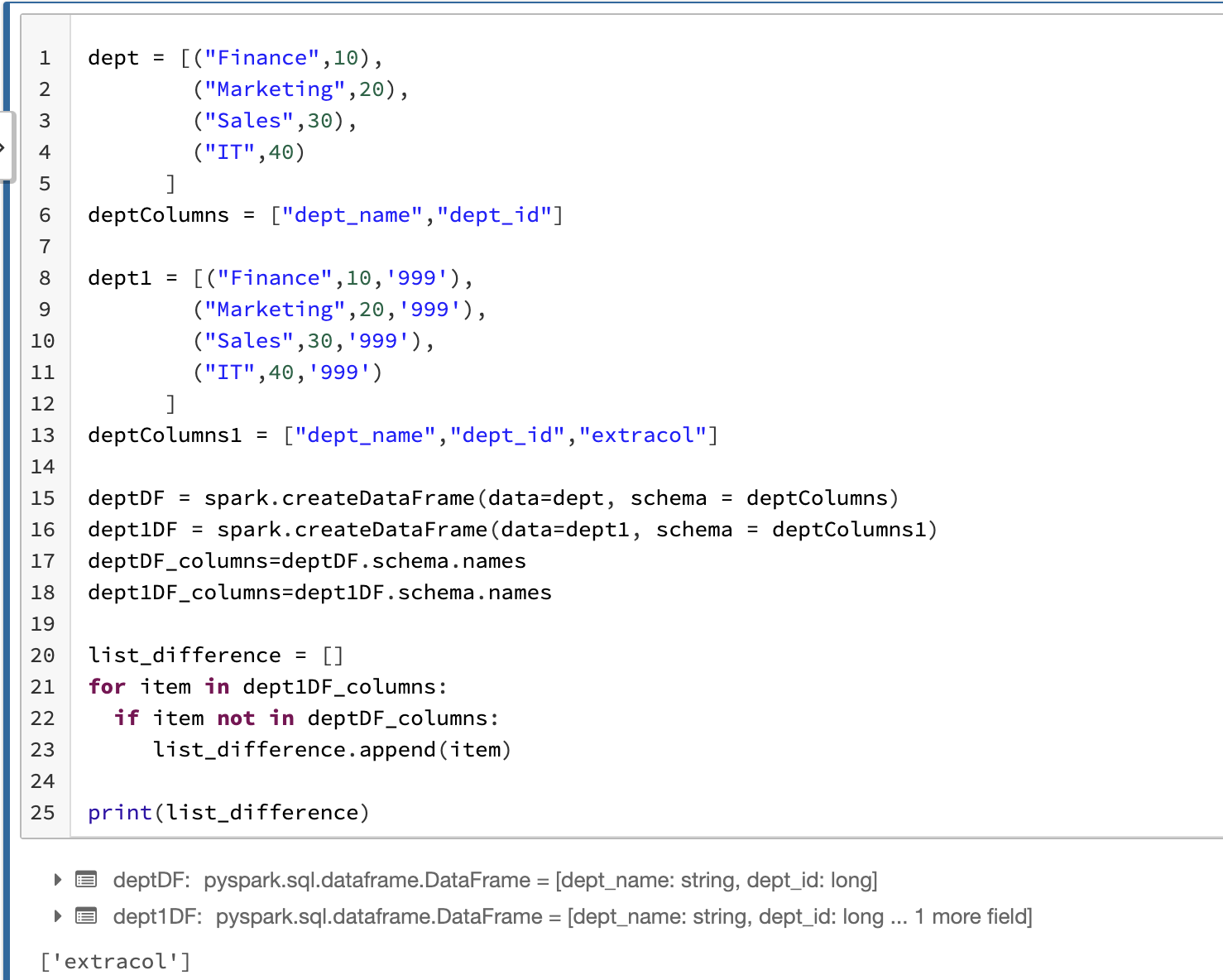
在pyspark,您可以使用以下邏輯。
dept = [("Finance",10),
("Marketing",20),
("Sales",30),
("IT",40)
]
deptColumns = ["dept_name","dept_id"]
dept1 = [("Finance",10,'999'),
("Marketing",20,'999'),
("Sales",30,'999'),
("IT",40,'999')
]
deptColumns1 = ["dept_name","dept_id","extracol"]
deptDF = spark.createDataFrame(data=dept, schema = deptColumns)
dept1DF = spark.createDataFrame(data=dept1, schema = deptColumns1)
deptDF_columns=deptDF.schema.names
dept1DF_columns=dept1DF.schema.names
list_difference = []
for item in dept1DF_columns:
if item not in deptDF_columns:
list_difference.append(item)
print(list_difference)
測驗代碼:
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/399140.html
上一篇:在Scala中使用類作為函式引數