所有后端應用幾乎都會記錄日志,日志系統可以統一抽象出來提供服務,
最近被Log4j2的安全漏洞刷屏了,作為開發人員的我只能咩哈哈幾次表示日志處理太難了,只有折騰過的人才知道這里面的艱辛啊,
在實作PowerDotNet日志系統之前,參考調研了Flume、ELK、Scribe和kafka的日志解決方案,對比后最終選擇Facebook的日志系統Scribe作為目標,實作了基于thrift協議(當然也支持http協議)無鎖且異步的更高性能簡潔而穩定的可擴展日志系統Power.XLogger,
本文講講PowerDotNet內置的日志平臺系統,
環境準備
1、(必須).Net Framework4.5+
2、(必須)MySQL或SqlServer或PostgreSQL或MariaDB或MongoDB或ElasticSearch
3、(必須)PowerDotNet資料庫管理平臺,主要使用DBKey功能
4、(必須)PowerDotNet配置中心Power.ConfigCenter
5、(必須)PowerDotNet注冊中心Power.RegistryCenter
6、(必須)PowerDotNet基礎資料平臺Power.BaseData
7、(必須)PowerDotNet快取平臺Power.Cache
8、(必須)PowerDotNet訊息平臺Power.Message
9、(必須)PowerDotNet人員管理平臺Power.HCRM,后續文章詳細介紹
一、Scribe簡介
Scribe是Facebook開源的日志收集系統,它能夠從各種日志源上收集日志,存盤到一個中央存盤系統(可以是NFS,分布式檔案系統等)上,以便于進行集中統計分析處理,
Scribe為日志的“分布式收集,統一處理”提供了一個可擴展的高容錯的方案,
Scribe從各種資料源上收集資料,放到一個共享佇列上,然后push到后端的中央存盤系統上,
當中央存盤系統出現故障時,Scribe可以暫時把日志寫到本地檔案中,待中央存盤系統恢復性能后,Scribe把本地日志續傳到中央存盤系統上,
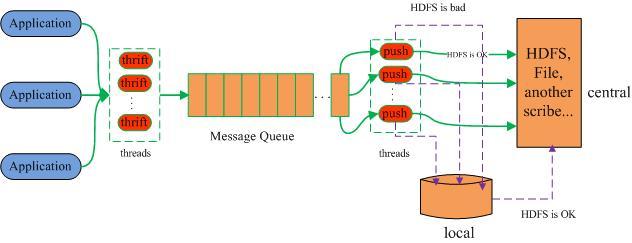
Scribe主要包括三部分,分別為Scribe Agent, Scribe和存盤系統,
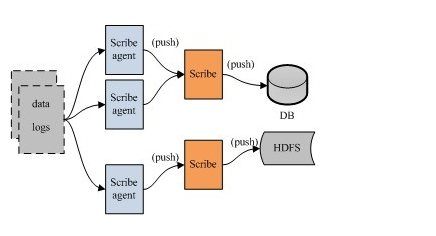
1、 Scribe Agent
Scribe Agent實際上是一個thrift client, 向Scribe發送資料的唯一方法是使用thrift client, Scribe內部定義了一個thrift介面,用戶使用該介面將資料發送給server,
2、Scribe
Scribe接收到thrift client發送過來的資料,根據組態檔,將不同topic的資料發送給不同的物件,Scribe提供了各種各樣的store,如 file, HDFS等,Scribe可將資料加載到這些store中,
3、Store
Scribe中的Store也就是我們所理解的存盤系統,當前Scribe支持非常多的Store,包括:
file(檔案)
buffer(雙層存盤,一個主儲存,一個副存盤)
network(另一個Scribe服務器)
bucket(包含多個 store,通過hash的將資料存到不同store中)
null(忽略資料)
thriftfile(寫到一個Thrift TFileTransport檔案中)
multi(把資料同時存放到不同store中)
二、日志存盤
PowerDotNet的日志平臺設計借鑒了Scribe,也支持從各種資料源上收集資料,放到一個共享佇列上,然后push或pull到后端的中央存盤系統上,
不過考慮到不同的應用場景,這個共享佇列被設計成動態可配置的日志容器,容器可以是主流的幾種訊息佇列(RabbitMQ、MSMQ、RocketMQ、Kafka等),redis,本地快取等,
當存盤系統出現故障時,PowerDotNet也會把日志“訊息”暫時(序列化)寫到本地檔案中,待存盤系統恢復性能后,再把本地日志(反序列化)續傳到中央存盤系統上,這種日志記錄容錯思想其實比較簡單直白,非常容易理解,
PowerDotNet內置的日志存盤媒介(也就是中央存盤系統)包括MongoDB、MySQL、MariaDB、PostgreSQL、SQLServer和ElasticSearch,也給Exceptionless和ELK預留了介面,后續開發考慮把Hive也加進去,畢竟對于日志系統而言,大資料量處理和較為完善的分析工具鏈是極其重要的參考指標,
在創建后端應用的時候,配置中心會自動分配一個記錄日志的DBKey,默認為PostgreSQL,但是個人在公司里碰到的更多的是使用MongoDB或者ElasticSearch或者ELK,
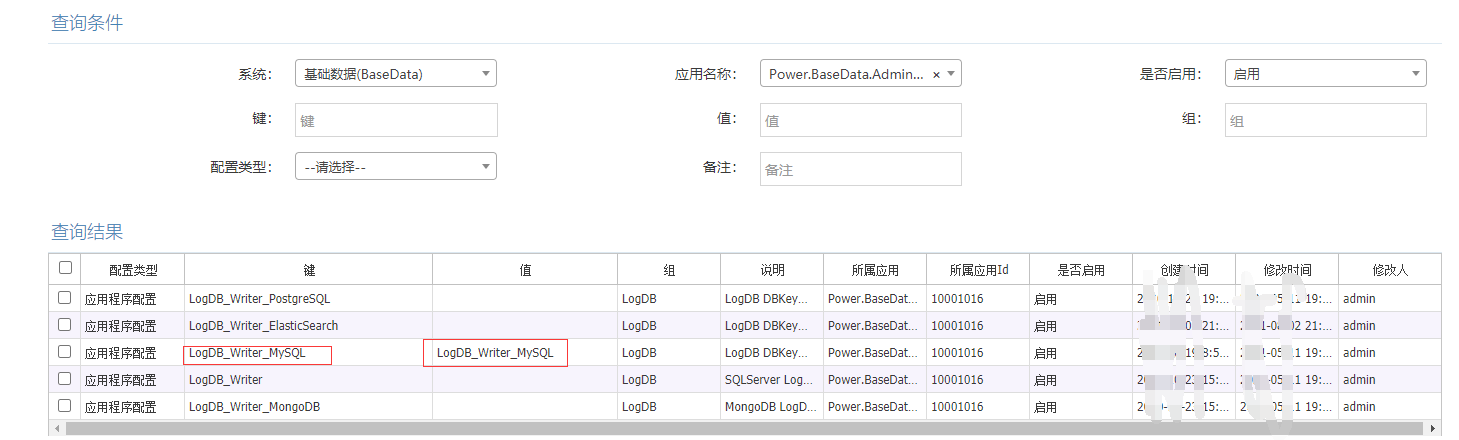
配置好DBKey,日志系統自動生效,寫代碼的時候呼叫現有的PowerDotNet記錄日志方法即可,
PowerDotNet記錄日志方法默認是全異步收集,不會影響業務主流程,
PowerDotNet日志組件支持敏感資訊脫敏,這也是非常常見的業務需求功能,
對比Scribe的存盤系統,PowerDotNet.XLogger做了大量裁剪,
三、日志管理
1、獲取DBKey
因為每個應用默認都配置了一個DBKey,所以查詢應用的日志時,需要通過DBKey間接找到存盤,最后再將查詢資料顯示出來,
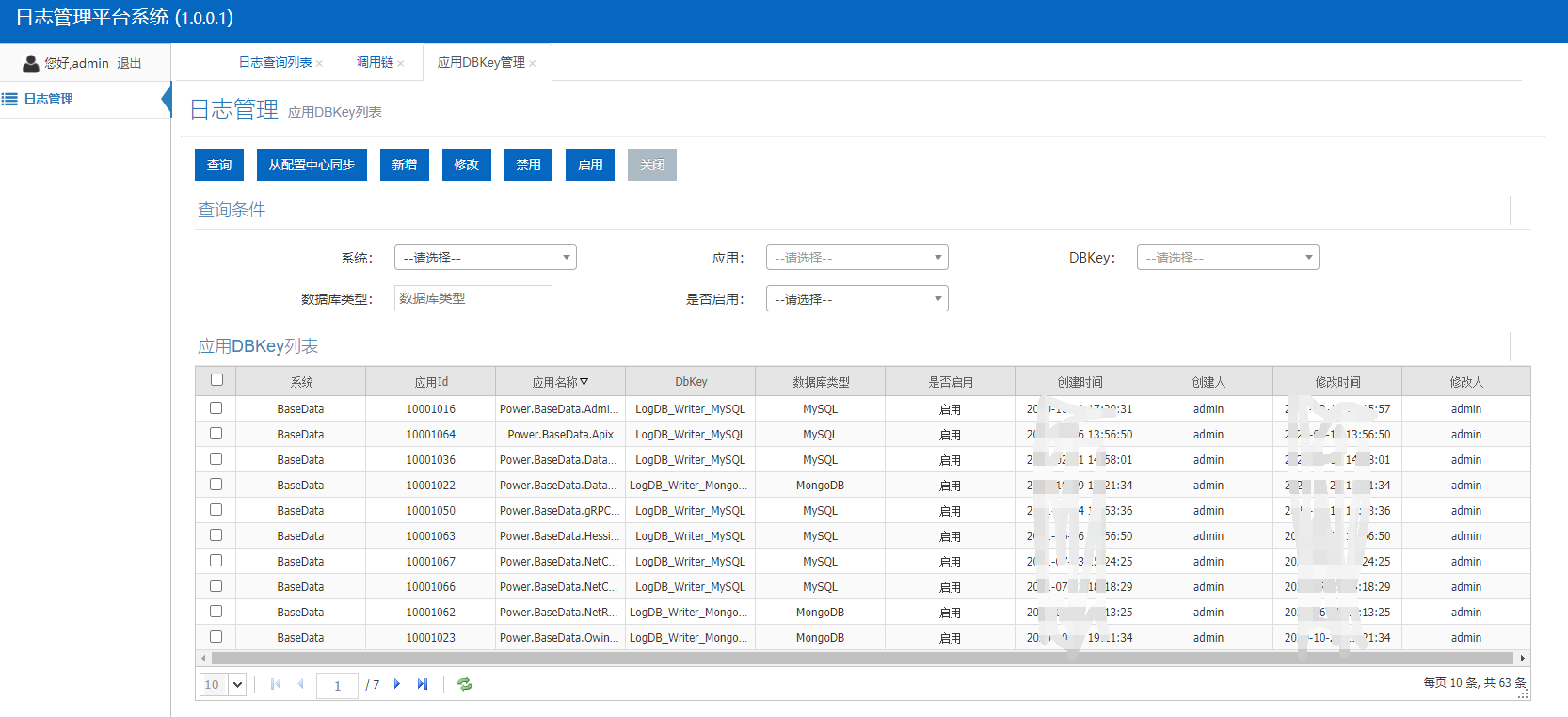
考慮到由于日志量通常都非常龐大,所以我們設計日志系統的時候都需要考慮分片處理,
DBKey配置日志這種方式天然就適合日志分片存盤,在日志發展到一定資料量級以后,不需要運維和DBA介入,直接換個DBKey或者通過DataX資料同步平臺修改DBKey連接串就可以切換新的日志存盤介質,歷史日志如果需要,通過其他工具直接訪問,簡直不要太容易,
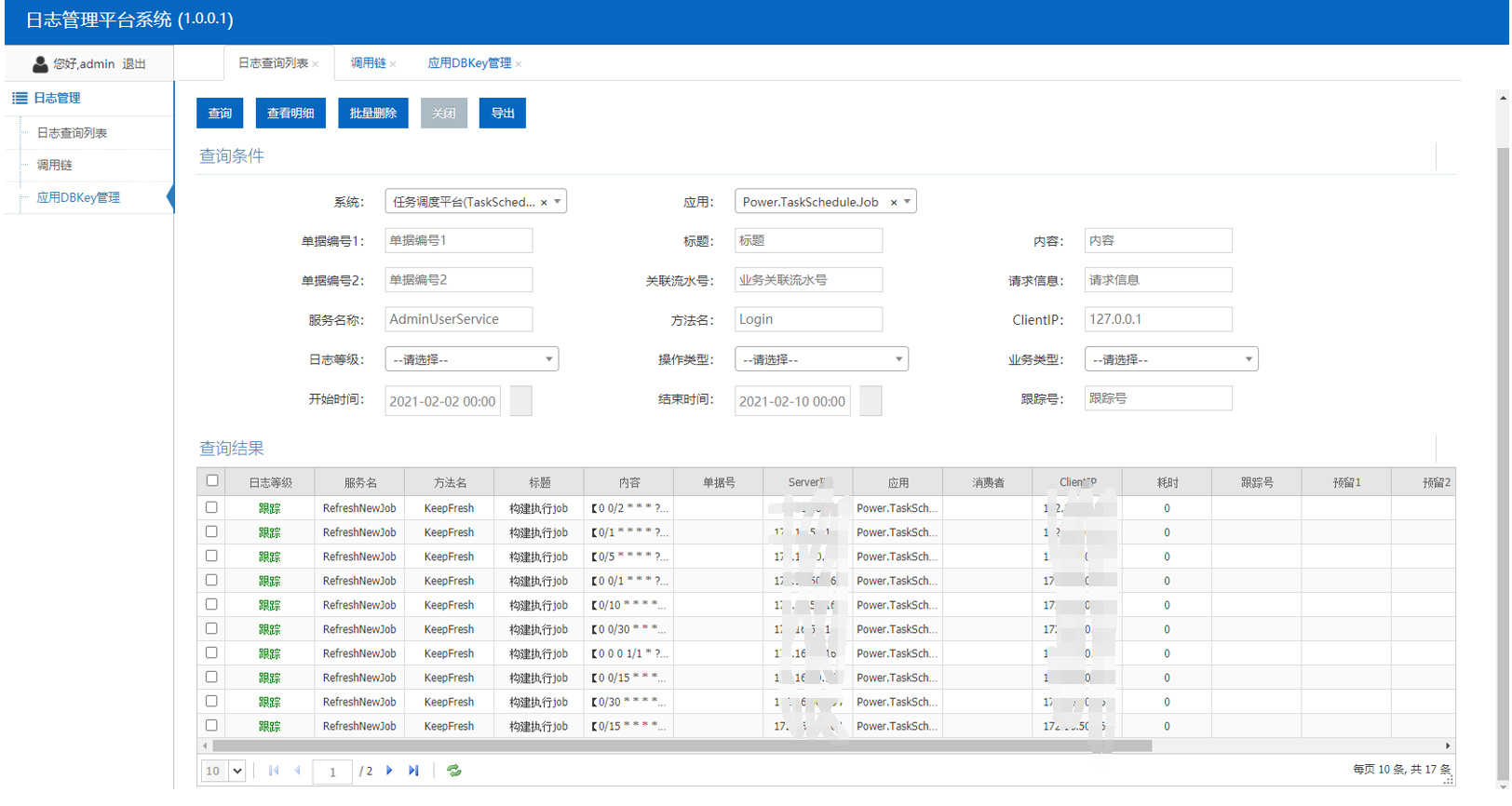
2、日志查詢
日志查詢界面自動根據應用適配DBKey找到自己的日志記錄,
3、呼叫鏈查詢
對于呼叫鏈路復雜冗長的介面,呼叫鏈查詢支持非常重要,根據個人開發運維經驗,在排查線上問題的時候,呼叫鏈查詢功能發揮了非常直觀高效的作用,
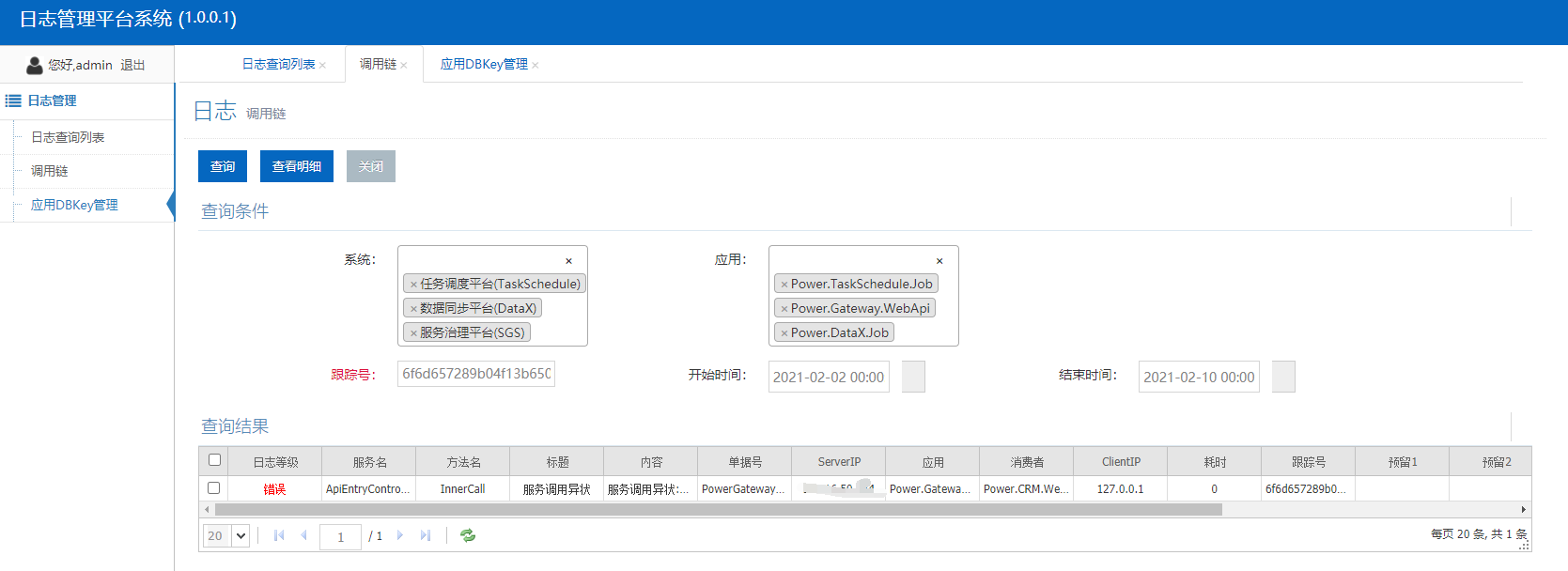
呼叫鏈支持多系統多應用的查詢,不同系統的DBKey可能不同,資料存盤在不同的資料庫中,這時候需要我們自己在記憶體中進行聚合分頁展示,
有些開源的優秀組件,如zipkin或SkyWalking+SkyApm,在你的服務中埋點相應代碼,可以實作分布式鏈路追蹤系統,
呼叫鏈查詢對于排查呼叫異狀非常有幫助,
四、其他
對于日志系統而言,我們幾乎不會強調ACID、CAP、BASE這些要求,日志系統應該盡可能做到快速高效不影響主業務流程,如果在保證日志高可用的同時,能不丟資料那是最好的結果,
Power.XLogger默認推薦各應用使用AOP方式記錄日志,統一日志記錄格式,當然為了便于排查問題,也需要在某些步驟埋點記錄特定日志,
對于某些系統,日志可能非常重要,比如支付、財務、賬戶等系統,
如果日志是業務邏輯里非常重要的一部分,尤其關鍵環節的重要日志,不但業務邏輯可能要用到,而且排查追蹤問題也很有用處,這種情況下,就不建議直接使用日志平臺了,
PowerDotNet對于這些日志敏感系統,都會在自身系統里建立日志表進行核心關鍵日志記錄,當然也支持按需在Power.XLogger記錄日志,
對于日志系統的埋點操作,建議使用Power.XLogger的異步批量處理方法,并且顯式帶上超時時間,Power.XLogger記錄日志默認2秒超時,默認批量處理200條資料,這兩個引數可通過配置中心動態調整,
日志佇列堆積到一定閾值(默認20萬條,可在配置中心動態配置)自動裁剪日志,防止系統記憶體不足或其他原因導致崩潰,
參考:
https://flume.apache.org
https://github.com/facebookarchive/scribe
https://kafka.apache.org
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
https://elasticsearch.cn
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
作者:Jeff Wong
出處:http://jeffwongishandsome.cnblogs.com/
本文著作權歸作者和博客園共有,歡迎圍觀轉載,轉載時請您務必在文章明顯位置給出原文鏈接,謝謝您的合作,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/399535.html
標籤:其他