因為網上查找得到的R語言K函式分析的資料很少,Spatstat包的介紹也很少,所以拋磚引玉,本文簡單介紹了使用R語言spatstat包的Kest,Kcross(Lcross)和Kinhom方法進行了單變數和雙變數平面Ripley's K函式分析的方法及代碼,希望有所幫助,
首先需要將經緯度坐標轉換為笛卡爾坐標系下的坐標,不然Ripley's K函式計算的空間尺度半徑是不對的,
原始資料OriginalData的格式如下:
OriginalData.csv OBJECTID longitude latitude 23 30.93427 121.5829 590 30.88591 121.5676 782 30.88255 121.5452 1085 30.93471 121.5365
我們所需要的資料實際只有經緯度兩列,讀入OriginalData.csv后,可以通過SoDA包的geoXY方法進行轉換,將結果保存在point.csv中,代碼如下:
#將經緯度坐標轉換為笛卡爾坐標
library("SoDA")
pos <- read.csv("OriginalData.csv", header = T)
geoxy <- geoXY(pos$longitude, pos$latitude)
write.csv(geoxy,file = "point.csv")生成的結果檔案point.csv如下:
point.csv X Y 1 63623.28 23879.09 2 62155.98 18517.41 3 60007.67 18145 4 59173.4 23927.32
接下來先進行單變數平面Ripley's K函式分析,讀入剛剛生成的笛卡爾坐標檔案,可以看到Kest方法的關鍵是生成ppp物件,注意此處的范圍window中使用了xrange和yrange,缺點是必須知道資料的上下限,我是在Excel中通過max()和min()取到資料的極值之后才來做的,也可以直接使用range函式,具體代碼會補充在下面,
#進行單變數K函式分析:Spatstat包Kest方法
library(spatstat)
data1 <- read.csv("point.csv",header = T) #笛卡爾坐標系下的點坐標
df1 <- data1[,2:3]
sp <- ppp(df1$X, df1$Y,
window = owin(xrange=c(0,28770.79991),yrange=c(0,101406.9336)))
k <-Kest(sp)
plot(k,xlab="Scale/m",ylab="K(r)",main="單變數K函式分析")直接使用range函式,就不需要事先獲取資料的上下限,生成ppp物件的代碼如下:
#使用range確定范圍
point <- ppp(df1$X,df1$Y,
range(df1$X),range(df1$Y))最終可以得到plot繪制的K函式影像分析結果如下:
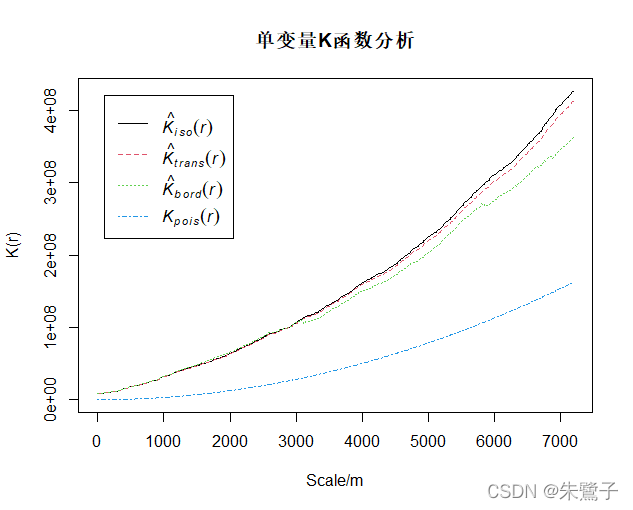
摘錄幫助檔案中對Kest方法輸出Value的描述:
r the vector of values of the argument r at which the function K has been estimated
theo the theoretical value K(r) = pi * r^2 for a stationary Poisson process
together with columns named "border", "bord.modif", "iso" and/or "trans", according to the selected edge corrections. These columns contain estimates of the function K(r) obtained by the edge corrections named.
接下來進行雙變數的K函式計算,我手頭的資料是兩個點位資料,計算第一個點與第二個點的相關K函式,事先進行資料處理,將兩類點位放在同一個檔案position.csv中,用type進行標記,原始資料如下:
position.csv ID type X Y 1 station 11698.39 40730.17 2 station 12258.3 41581.32 … … … … 479 point 63623.28 23879.09 480 point 62155.98 18517.41
讀入position.csv,此處的關鍵依然是生成ppp影像,注意需要用marks標記不同類的點資料,使用spatstat包的Kcross方法即可簡單地完成雙變數K函式計算,結果保存在Kab,
也可以使用Lcross進行L函式計算,結果保存在Lab,
#雙變數K函式分析
data3 <- read.csv("position.csv")
df4 <- data3[,1:4]
df4$type <- as.factor(df4$type)
position <- ppp(df4$X,df4$Y,
range(df4$X),range(df4$Y),marks = df4$type)
Kab <- Kcross(position, "station", "point",correction=c("Ripley","border"))
Lab <- Lcross(position, "station", "point",correction=c("Ripley","border"))
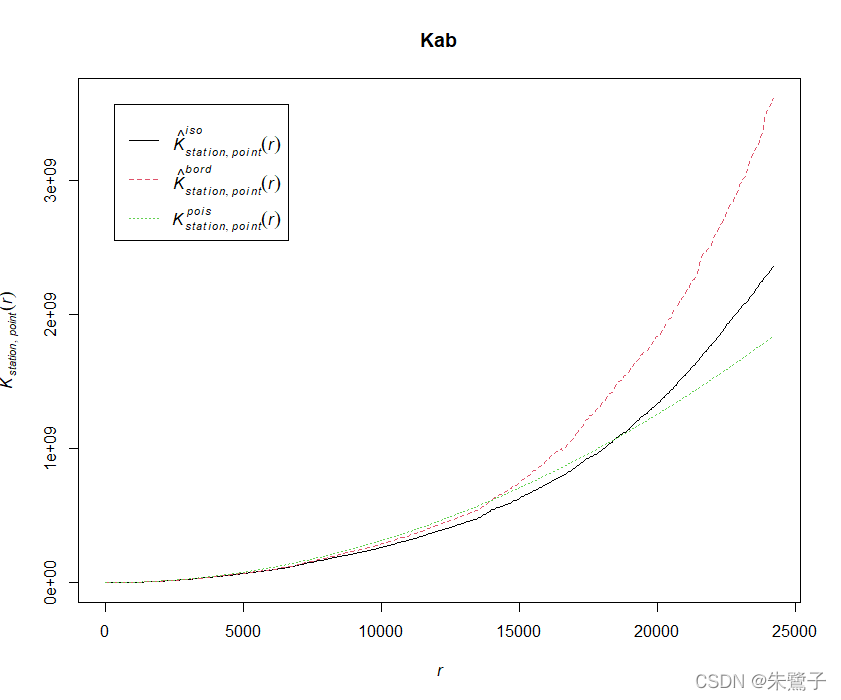
plot(Kab)具體選擇哪幾類資料可以利用dplyr包的filter函式,比如選擇type為point和station的資料時,代碼如下:
positionsab <- dplyr::filter(df, type %in% c("point", "station"))最終可以得到雙變數平面K函式的影像:
也可以利用Kinhom()進行雙變數點的平面kinhom函式計算,
#雙變數平面Kinhom函式分析
library("spatstat")
data <- read.csv("point.csv",header = T)
df <- data[,1:3]
point<-ppp(df$X,df$Y,
range(df$X),range(df3$Y),marks = df$type)
#x和y坐標進行多項式擬合空間趨勢函式
fit <- ppm(point, ~ polynom(x,y,2), Poisson())
lambda <- predict(fit, locations=point, type="trend")
Ki <- Kinhom(point, lambda)
plot(Ki,main="雙變數平面Kinhom函式分析")繪制影像結果:
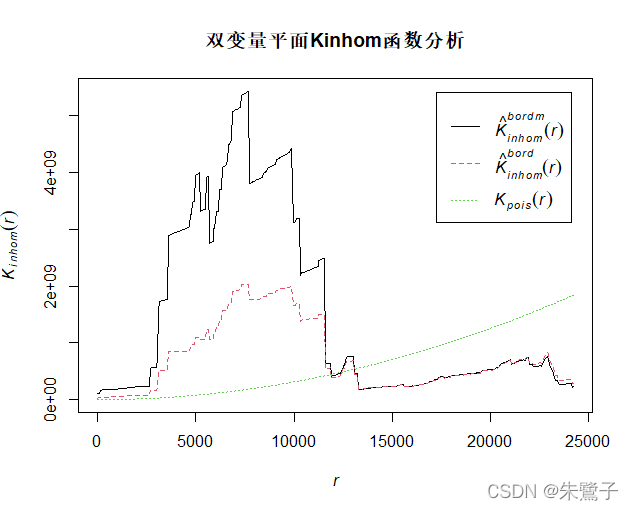
以上是計算K函式的方法,如果要進行K函式的分析,需要通過envelope計算CSR隨機分布模型,并比較空模型模擬的估計的上下限,如果在上限以上則表明是集聚分布,在下限以下則表明是均勻分布,在上下限之間則表明是隨機分布,代碼如下:
#讀入資料
library(spatstat)
data <- read.csv("position.csv",header = T) #笛卡爾坐標系下的點坐標
df <- data1[,1:3]
point <-ppp(df$X,df$Y,
range(df$X),range(df3$Y),marks = df$type)
#單變數K函式分析:Kest
pointsub <-dplyr::filter(df, type %in% c("point")) #篩選出型別為type的單變數點資料
pointsub$type <- as.factor(pointsub$type)
envelope1 <- envelope(pointsub,fun=Kest,nsim=100) #nsim表示迭代次數
plot(envelope1,xlab="Scale/m",ylab="K(r)",main="單變數點Ripley's K函式分析")
#雙變數K函式分析:Kcross
envelope2 <- envelope(point,fun=Kcross,nsim=100)
plot(envelope2,xlab="Scale/m",ylab="K(r)",main="雙變數點Ripley's K函式分析")
#雙變數Kinhom函式分析
fit <- ppm(point, ~ polynom(x,y,2), Poisson()) #x和y坐標進行多項式擬合空間趨勢函式
lambda <- predict(fit, locations=point, type="trend")
envelope3 <- envelope(fit,fun=Kinhom,nsim=100)
plot(envelope2,main="雙變數Kinhom函式分析")繪制的函式影像如下,hi和lo分別是CSR模型估計的上限和下限,
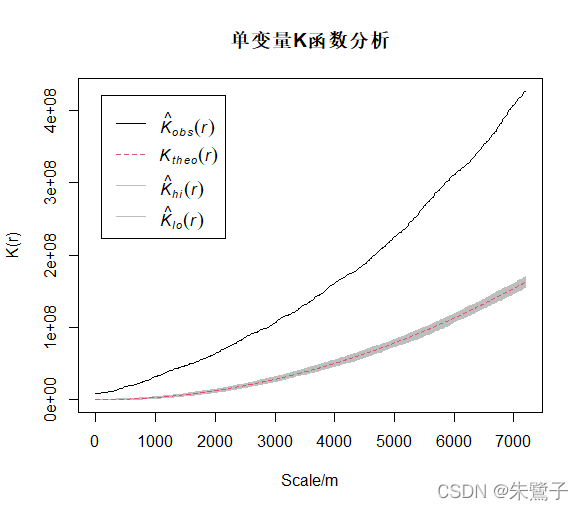
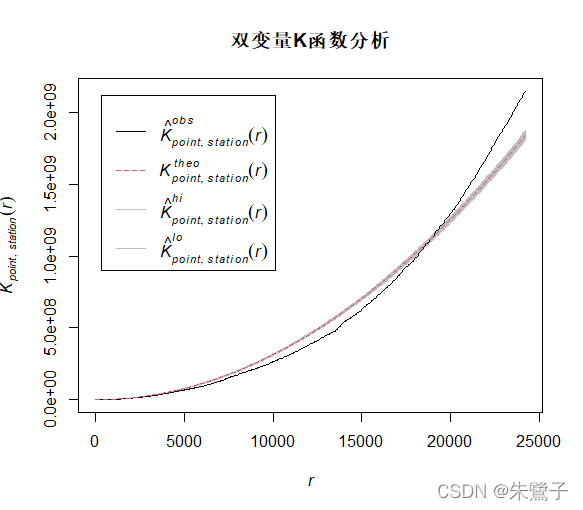
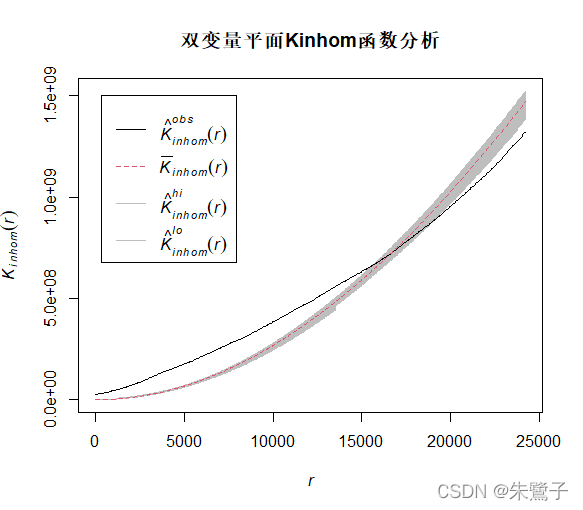
最后,感謝林元震老師分享的生態R包spatstat的部分用法一文,獲益匪淺!本文的代碼也是基于林老師的作業基礎,感謝大家閱讀!
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/402480.html
標籤:其他
上一篇:RabbitMQ發布確認高級
下一篇:模電總結(一)