我有一個看起來像這樣的 excel 檔案:
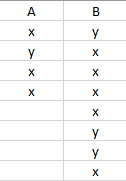
我想將其讀入熊貓資料框并避免獲取 NAN 值。我試圖避免獲得 NAN 的原因是稍后,我想創建一個類似于此的簡單列聯表
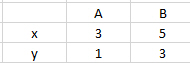
和 NAN 值在此列聯表中產生問題。是否有任何優雅的方法可以做到這一點,而無需單獨讀取列,使用 value_counts() 并連接系列,如下所示?
df_1=pd.read_excel('Book1.xlsx', usecols='A')
df_2=pd.read_excel('Book2.xlsx', usecols='B')
value_c_1 = df_1.value_counts()
value_c_2 = df_2.value_counts()
pd.concat([value_c_1, value_c_2], axis=1)
必須有一種優雅的方式來做到這一點;如果答案如此明顯,我深表歉意;我在發布這個問題之前搜索了它。
uj5u.com熱心網友回復:
如果您的 excel 類似于以下資料框:
df = pd.DataFrame({'A' : ['x','y','x','x', '','','',''],
'B' : ['y', 'x','x','x','x','y','y','x',]})
你可以試試這個:
df.apply(pd.value_counts).loc[['x','y']]
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/409858.html
標籤:
上一篇:計算給定級別的每個日期組合的差異