我一直在研究熊貓資料框,
df = pd.DataFrame({'col':[-0.217514, -0.217834, 0.844116, 0.800125, 0.824554]}, index=[49082, 49083, 49853, 49854, 49855])
我得到如下所示的資料:
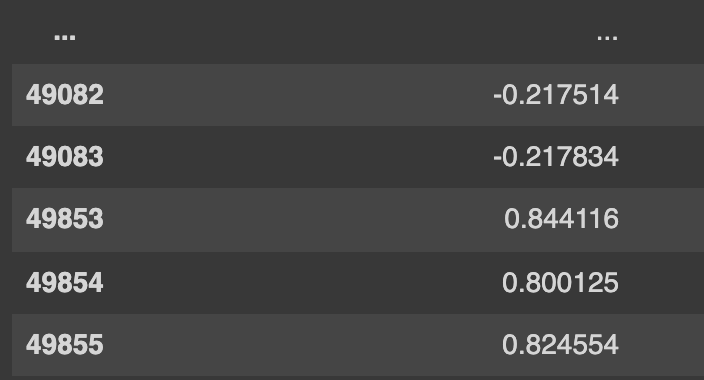
如您所見,索引突然跳躍了 770 個值(由于我之前進行的排序)。
現在我想將此 DataFrame 拆分為許多不同的 DataFrame,其中每個將由索引彼此跟隨的行組成(這里前 2 行將在同一個 DataFrame 中,而后三行將在不同的 DataFrame 中)。
有誰知道如何做到這一點?
謝謝!
uj5u.com熱心網友回復:
您可以分兩步完成:
(i) 使用np.diff和查找截止點的位置np.where。使用np.diff查找索引值之間的差異(附加np.nan以便我們不會遺漏最后一個索引)并識別索引中不連續使用的位置np.where。
(ii) 使用 (i) 中找到的索引截斷對 DataFrame 進行切片
end_of_consecutive_indices = np.where(np.diff(df.index, append=np.nan) !=1)[0] 1
df_list = [df.loc[df.index[:i]] for i in end_of_consecutive_indices]
輸出:
[ col
49082 -0.217514
49083 -0.217834,
col
49082 -0.217514
49083 -0.217834
49853 0.844116
49854 0.800125
49855 0.824554]
uj5u.com熱心網友回復:
使用groupby我們從中減去增加 1 序列的索引,然后將每個組作為單獨的 df 粘貼在串列中
all_dfs = [g for _,g in df.groupby(df.index - np.arange(len(df.index)))]
all_dfs
輸出:
[ col
49082 -0.217514
49083 -0.217834,
col
49853 0.844116
49854 0.800125
49855 0.824554]
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/409868.html
標籤:
上一篇:熊貓,調整列標題的高度?