目前正在嘗試使用 jupyter notebook 上的一些測驗資料點運行非常基本的線性回歸。下面是我的代碼,正如你所看到的,如果你運行它,預測線肯定會朝著它應該去的地方移動,但是由于某種原因它停止了,我不確定為什么。誰能幫我?
起始重量
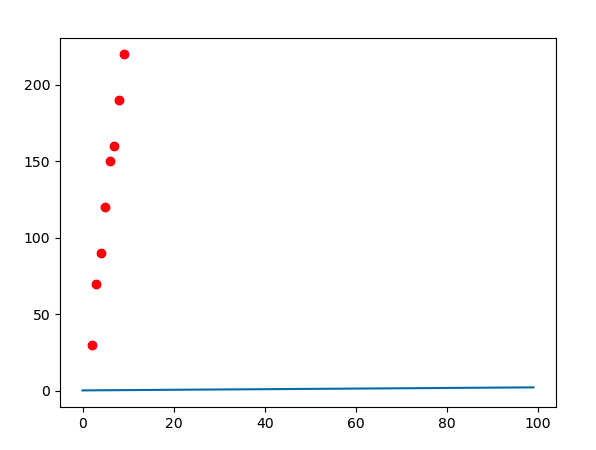
結束權重
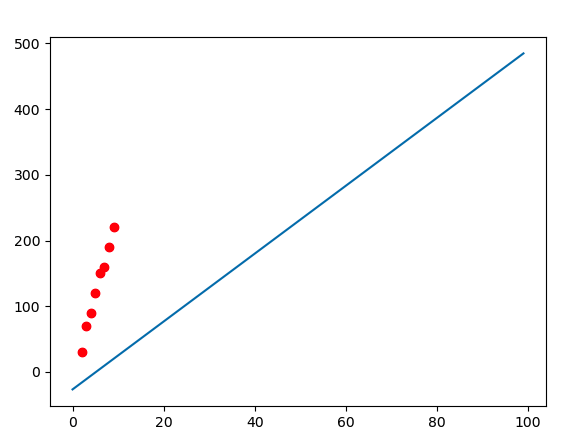
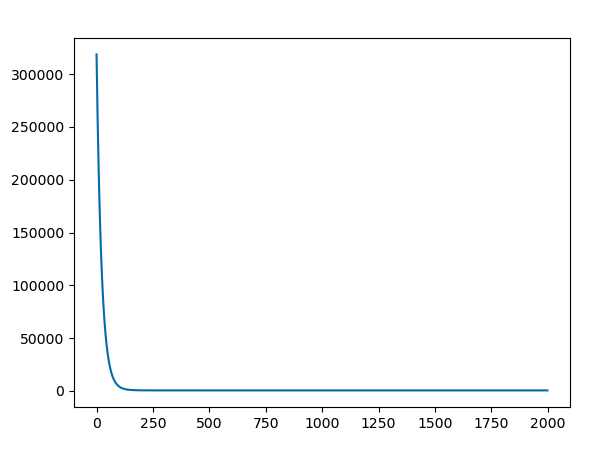
損失
import matplotlib.pyplot as plt
import numpy as np
%matplotlib notebook
plt.style = "ggplot"
y = np.array([30,70,90,120,150,160,190,220])
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(y_hat)
x_ticks = np.array([[1,x*0.1] for x in range(100)])
y_hat = []
for j in range(len(x_ticks)):
y_hat.append(np.dot(weights, x_ticks[j]))
def plot_model(x, y, weights, loss):
x_ticks = np.array([[1,x*0.1] for x in range(100)])
y_hat = []
for j in range(len(x_ticks)):
y_hat.append(np.dot(weights, x_ticks[j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(y_hat)
plt.figure()
plt.plot(loss)
def calculate_grad(weights, N, x_proc, y, loss):
residuals = np.sum(y.reshape(N,1) - weights*x_proc, 1)
loss.append(sum(residuals**2)/2)
#print(residuals, x_proc)
return -np.dot(residuals, x_proc)
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
learning_rate = 0.006
epochs = 2000
loss = []
x_processed = np.array([[1,i] for i in x])
for j in range(epochs):
grad = calculate_grad(weights, N, x_processed, y, loss)
weights = adjust_weights(weights, grad, learning_rate)
if j % 200 == 0:
print(weights, grad)
plot_model(x, y, weights, loss)
uj5u.com熱心網友回復:
有幾個問題。
首先讓我們談談您嘗試查找引數的方式。您在進行矩陣和向量乘法時遇到了一些問題。我喜歡將權重和 y 可視化為列向量。
然后,您就會知道我們需要對您處理后的 x 矩陣和權重列向量進行點積。這是第 1 步。
現在,記住你的鏈式法則!您的梯度走在了正確的軌道上,但您需要記住乘以x_proc * residuals(-2/n),其中 n 是您擁有的觀察次數!
這是代碼:
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
def calculate_grad(weights, N, x_proc, y, loss):
y_hat = np.dot(x_proc, weights.reshape(2,1))
residuals = y - y_hat
gradient = (-2/float(len(x_proc)))*sum(x_proc * residuals)
return gradient
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
現在是繪圖問題。
不需要在 x 上增加 0.1。您應該像查找權重時那樣簡單地使用 x_proc。像這樣:
def plot_model(x, y, weights, loss):
y_hat = []
for j in x:
y_hat.append(np.dot(weights, [1, j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(x, y_hat)
plt.show()
和 tada,通過 2000 次迭代,你得到了權重:[-12.80036278 25.75042317]這與實際解決方案非常接近:[-13.33333 25.833333].
這是作業代碼:
import numpy as np
import matplotlib.pyplot as plt
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
N = len(y)
weights = np.array([0.2,0.2])
def plot_model(x, y, weights, loss):
y_hat = []
for j in x:
y_hat.append(np.dot(weights, [1, j]))
plt.figure()
plt.scatter(x, y, color="red")
plt.plot(x, y_hat)
plt.show()
def calculate_grad(weights, N, x_proc, y, loss):
y_hat = np.dot(x_proc, weights.reshape(2,1))
residuals = y - y_hat
gradient = (-2/float(len(x_proc)))*sum(x_proc * residuals)
return gradient
def adjust_weights(weights, grad, learning_rate):
weights -= learning_rate*grad
return weights
learning_rate = 0.006
epochs = 2000
loss = []
x_processed = np.array([[1,i] for i in x])
for j in range(epochs):
grad = calculate_grad(weights, N, x_processed, y, loss)
weights = adjust_weights(weights, grad, learning_rate)
plot_model(x, y, weights, loss)
我認為向您解釋我是如何解決這個問題的。
我開始用筆和紙。找到數值并不那么重要,但您必須了解運算的順序(例如,將矩陣 x 乘以權重的列向量,反之亦然)。您的代碼使我感到困惑,因為我不確定您為操作順序構建的心理地圖。
然后從那里開始,撰寫代碼很容易。
如果您想檢查您的解決方案是否正確,您可以使用封閉形式的解決方案(如果有一個;))來解決最小二乘問題:inverse(XT X) (XT*y)。在你的情況下:
y = np.array([[30,70,90,120,150,160,190,220]]).T
x = np.arange(2,len(y) 2)
x = np.matrix([[1, x] for x in x])
beta_pt1 = np.linalg.inv(x.T*x)
beta_pt2 = x.T*y
beta = beta_pt1*beta_pt2
print(beta_pt1*beta_pt2)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/411795.html
標籤: