我有以下資料框: <class 'pandas.core.frame.DataFrame'>
RangeIndex: 1642 entries, 0 to 1641
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Date 1642 non-null datetime64[ns]
1 Volgnr 1642 non-null int64
2 account 1642 non-null object
3 Rentedatum 1642 non-null datetime64[ns]
4 Bedrag 1642 non-null float64
5 Balance 1642 non-null float64
6 tegenrekening 906 non-null object
7 Code 1642 non-null object
8 Naam tegenpartij 1642 non-null object
9 description 1642 non-null object
10 category 1642 non-null object
11 Grootboek 1578 non-null object
12 Kleinboek 1578 non-null object
dtypes: datetime64[ns](2), float64(2), int64(1), object(8)
memory usage: 166.9 KB
'account' 有 5 個不同的帳號,如下所示:NL00ABCD0123456789
我想要兩個不同的圖表,但我已經堅持第一個,即我想查看 5 個帳戶隨時間推移的余額
根據該論壇上的其他問題,我嘗試了:
pd.options.plotting.backend="plotly"
df.set_index('Date', inplace=True)
df.groupby('account')['balance'].plot(legend=True)
但出現以下錯誤:
TypeError: line() got an unexpected keyword argument 'legend'
這里出了什么問題?
稍后:如果解決了,我希望 X 軸是幾周或幾個月,而不是絕對日期,因此需要進行一些聚合
uj5u.com熱心網友回復:
簡短的回答:
您會看到此錯誤,因為運行將在定義后df.plot()觸發。并且沒有屬性。但你不需要它。所有你需要的是:px.line()pd.options.plotting.backend="plotly"px.line()legend
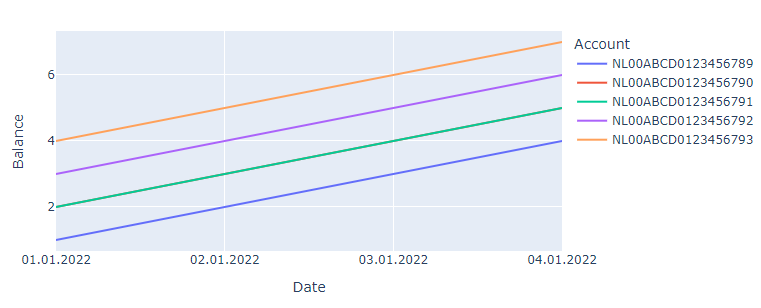
px.line(df, x = 'Date', y = 'Balance', color = 'Account')
你會得到:
細節:
pd.options.plotting.backend="plotly"您肯定知道,設定將覆寫默認的繪圖后端,pandas即matplotlib. 盡管如此,在help(df.plot())那之后運行時,彈出的幫助資訊似乎仍然是 info about matplotlib,實際上它確實有一個legend屬性。
但是實體化后px.line()會觸發什么。這就是觸發您的錯誤的原因,因為沒有屬性。Dut 不要擔心,因為事情對你來說變得非常簡單,因為會為你產生一個分組的圖例。只要您正確應用,您甚至不需要對資料進行分組。df.plot()pd.options.plotting.backend="plotly"px.linelegendpx.line()df.plot()
但在我們開始之前,我們必須看看您提供的資料集。鑒于您問題的措辭以及您提供的“資料”的外觀,我的理解是,您有幾個account與不同值相關聯的非唯一帳戶,這些帳戶balance分布在多個非唯一日期。像這樣的東西:
Date Account Balance
0 01.01.2022 NL00ABCD0123456789 1
1 01.01.2022 NL00ABCD0123456790 2
2 01.01.2022 NL00ABCD0123456791 2
3 01.01.2022 NL00ABCD0123456792 3
4 01.01.2022 NL00ABCD0123456793 4
5 02.01.2022 NL00ABCD0123456789 2
6 02.01.2022 NL00ABCD0123456790 3
7 02.01.2022 NL00ABCD0123456791 3
8 02.01.2022 NL00ABCD0123456792 4
9 02.01.2022 NL00ABCD0123456793 5
如果是這種情況,那么您需要做的就是運行:
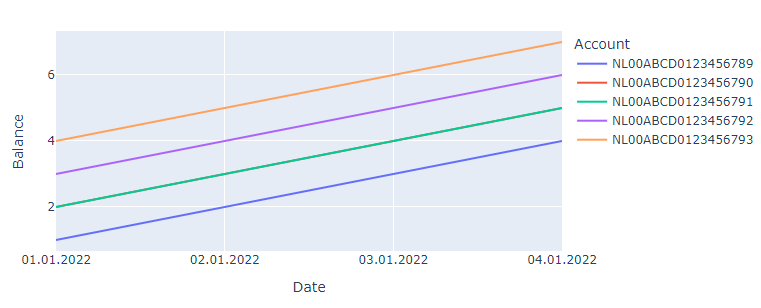
px.line(df, x = 'Date', y = 'Balance', color = 'Account')
陰謀:
完整代碼:
import pandas as pd
import plotly.express as px
pd.options.plotting.backend="plotly"
df = pd.DataFrame({'Date': {0: '01.01.2022',
1: '01.01.2022',
2: '01.01.2022',
3: '01.01.2022',
4: '01.01.2022',
5: '02.01.2022',
6: '02.01.2022',
7: '02.01.2022',
8: '02.01.2022',
9: '02.01.2022',
10: '03.01.2022',
11: '03.01.2022',
12: '03.01.2022',
13: '03.01.2022',
14: '03.01.2022',
15: '04.01.2022',
16: '04.01.2022',
17: '04.01.2022',
18: '04.01.2022',
19: '04.01.2022'},
'Account': {0: 'NL00ABCD0123456789',
1: 'NL00ABCD0123456790',
2: 'NL00ABCD0123456791',
3: 'NL00ABCD0123456792',
4: 'NL00ABCD0123456793',
5: 'NL00ABCD0123456789',
6: 'NL00ABCD0123456790',
7: 'NL00ABCD0123456791',
8: 'NL00ABCD0123456792',
9: 'NL00ABCD0123456793',
10: 'NL00ABCD0123456789',
11: 'NL00ABCD0123456790',
12: 'NL00ABCD0123456791',
13: 'NL00ABCD0123456792',
14: 'NL00ABCD0123456793',
15: 'NL00ABCD0123456789',
16: 'NL00ABCD0123456790',
17: 'NL00ABCD0123456791',
18: 'NL00ABCD0123456792',
19: 'NL00ABCD0123456793'},
'Balance': {0: 1,
1: 2,
2: 2,
3: 3,
4: 4,
5: 2,
6: 3,
7: 3,
8: 4,
9: 5,
10: 3,
11: 4,
12: 4,
13: 5,
14: 6,
15: 4,
16: 5,
17: 5,
18: 6,
19: 7}})
px.line(df, x = 'Date', y = 'Balance', color = 'Account')
uj5u.com熱心網友回復:
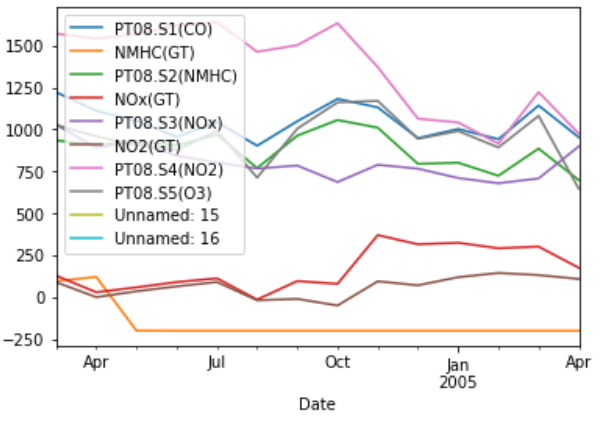
由于您沒有提供樣本資料,我有一個任意時間序列資料的解決方案。
{'Date': ['10/03/2004',
'10/03/2004',
'10/03/2004',
'10/03/2004',
'10/03/2004'],
'Time': ['18.00.00', '19.00.00', '20.00.00', '21.00.00', '22.00.00'],
'CO(GT)': ['2,6', '2', '2,2', '2,2', '1,6'],
'PT08.S1(CO)': [1360.0, 1292.0, 1402.0, 1376.0, 1272.0],
'NMHC(GT)': [150.0, 112.0, 88.0, 80.0, 51.0],
'C6H6(GT)': ['11,9', '9,4', '9,0', '9,2', '6,5'],
'PT08.S2(NMHC)': [1046.0, 955.0, 939.0, 948.0, 836.0],
'NOx(GT)': [166.0, 103.0, 131.0, 172.0, 131.0],
'PT08.S3(NOx)': [1056.0, 1174.0, 1140.0, 1092.0, 1205.0],
'NO2(GT)': [113.0, 92.0, 114.0, 122.0, 116.0],
'PT08.S4(NO2)': [1692.0, 1559.0, 1555.0, 1584.0, 1490.0],
'PT08.S5(O3)': [1268.0, 972.0, 1074.0, 1203.0, 1110.0],
'T': ['13,6', '13,3', '11,9', '11,0', '11,2'],
'RH': ['48,9', '47,7', '54,0', '60,0', '59,6'],
'AH': ['0,7578', '0,7255', '0,7502', '0,7867', '0,7888']
}
我們需要將日期轉換為datetime物件。
df['Date'] = pd.to_datetime(df['Date'] " " df['Time'], format="%d/%m/%Y %H.%M.%S")
# To plot with monthly aggregation you can use resample.
df.set_index('Date').resample('1M').mean().plot()
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/412612.html
標籤:
下一篇:熊貓在嵌套串列中爆炸