我知道網上有大量資源可用于去除例外值,但我還沒有設法獲得我真正想要的東西,所以在這里發布,我有一個4列陣列(或 DF)。現在我想根據列的例外值從 DF 中洗掉行。以下是我嘗試過的,但它們并不完美。
def outliers2(data2, m = 4.5):
c=[]
data = data2[:,1] # Choosing the column
d = np.abs(data - np.median(data)) # deviation comoutation
mdev = np.median(d) # mean deviation
for i in range(len(data)):
if (abs(data[i] - mdev) < m * np.std(data)):
c.append(data2[i])
return c
x = pd.DataFrame(outliers2(np.array(b)))
column = ['t','orig_w','filt_w','smt_w']
x.columns = column
#Plot
plt.rcParams['figure.figsize'] = [10,8]
plt.plot(b.t,b.orig_w,'o',label='Original',alpha=0.8) # Original
plt.plot(x.t,x.orig_w,'.',c='r',label='Outlier removed',alpha=0.8) # After outlier removal
plt.legend()
該圖說明了結果的外觀,藍色原始點上的例外值處理后的紅色點。我真的很想擺脫 x~0 標記周圍的那些垂直點組。該怎么辦 ?
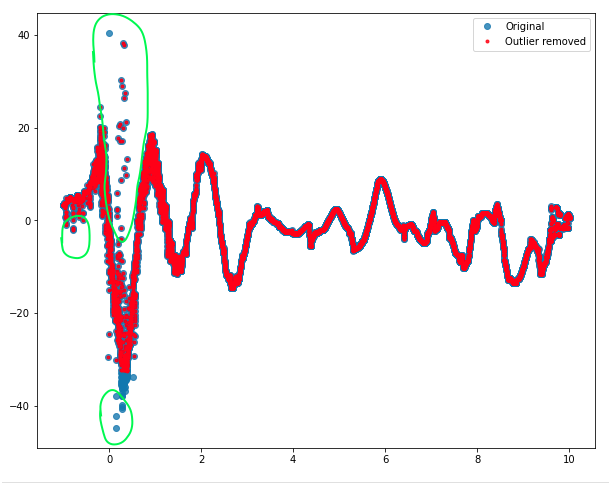
此處提供了資料檔案的鏈接: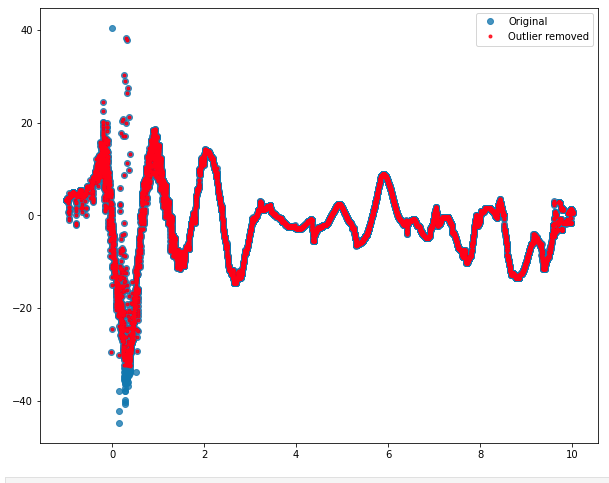 綠色圓圈通常顯示我想要擺脫的點
綠色圓圈通常顯示我想要擺脫的點
uj5u.com熱心網友回復:
您可以使用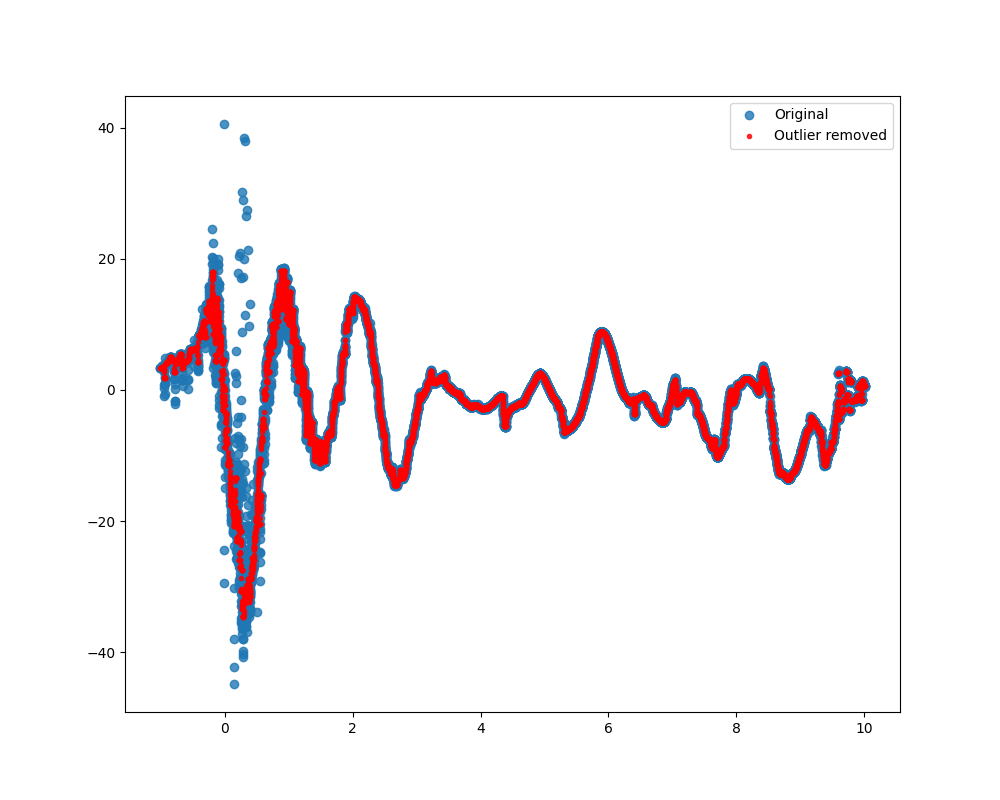
uj5u.com熱心網友回復:
由于您的資料看起來是正弦曲線,因此使用滑動視窗執行例外值洗掉技術可能很有意義。您可以計算您正在測驗的點的直接鄰域中的中位數和標準差,并通過檢查您的點是否在與您的中位數標準差的指定數量內來檢查它是否是例外值。此方法以Hampel filter(更多詳細資訊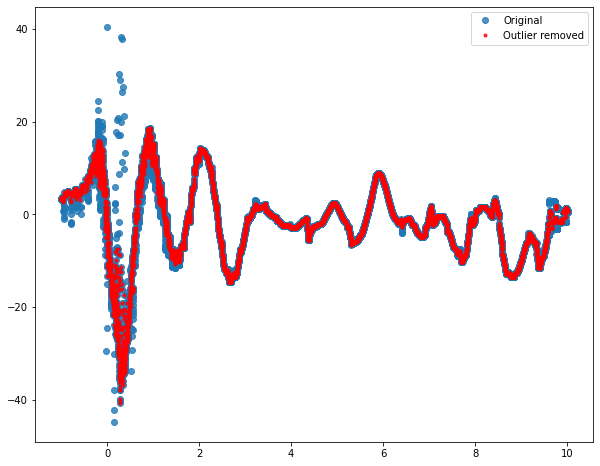
然后,您可以微調win并m獲得適合您的結果。
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/412621.html
標籤: