記得當年《甄嬛傳》熱播,呼叫了我們團隊的媒體資訊介面,介面被呼叫掛了,當時雖然我不負責那一塊,只是目睹了當時大家在臨場解決問題的緊張一幕,但是這件事在我心里埋下了種子,從此追求高可用、高穩定成為職業發展的方向,
今天咱們就來聊一聊熱點和秒殺前要做的5件事,這5件事是按時間順序排列出場,
應急演練
無論對一個軟體系統運行原理掌握得多么徹底,也不能阻止人犯意外錯誤,--瑪格麗特教授
應急演練可以定期舉行,前提是對各種意外情況,提前準備好了預案,預案在演練程序中,可以發現系統問題、檢驗相關人員SOP/EOP的操作熟練情況,
舉個例子:支付系統由于下游銀行通道能力參差,需要制定關閉XX銀行通道的SOP,并進行演練,
應急演練一般要求級別較高的人員進行組織,確保其對突發情況有一定的應變權利,同時也能敏銳的發現新問題,確保效果,應急演練我個人總結要分為4個步驟,實際上也是標準的PDCA方法的步驟:
1、提前通知,確保參加人員掌握了需要的知識,同時同步到應急演練的目標、相關檔案、時間、地點、參加人員
2、演練開始時第一步是告知大家演練的目標、流程和檢查專案,比如程序中會檢查大家對SOP/EOP的操作熟練情況,如果不熟練則會進行通報,
3、按流程步驟進行演練
4、進行演練總結,制定改進計劃
在我實際進行過的演練中,上面提到的第二步做的不是很好,可能是作為一項例行事務,演練組織人員習慣于這項作業,認為沒有必要重復說明,實際上我認為這是最重要的一步,因為第一,每次演練可能會有一些新人加入,他們不了解背景,第二,大家最后可能只記得演練的一個目標,把優化流程、找問題這些事情忽視了,演練效果大打折扣,
SOP/EOP
SOP(Standard Operating Procedure三個單詞中首字母的大寫 )即標準作業程式,就是將某一事件的標準操作步驟和要求以統一的格式描述出來,用來指導和規范日常的作業,
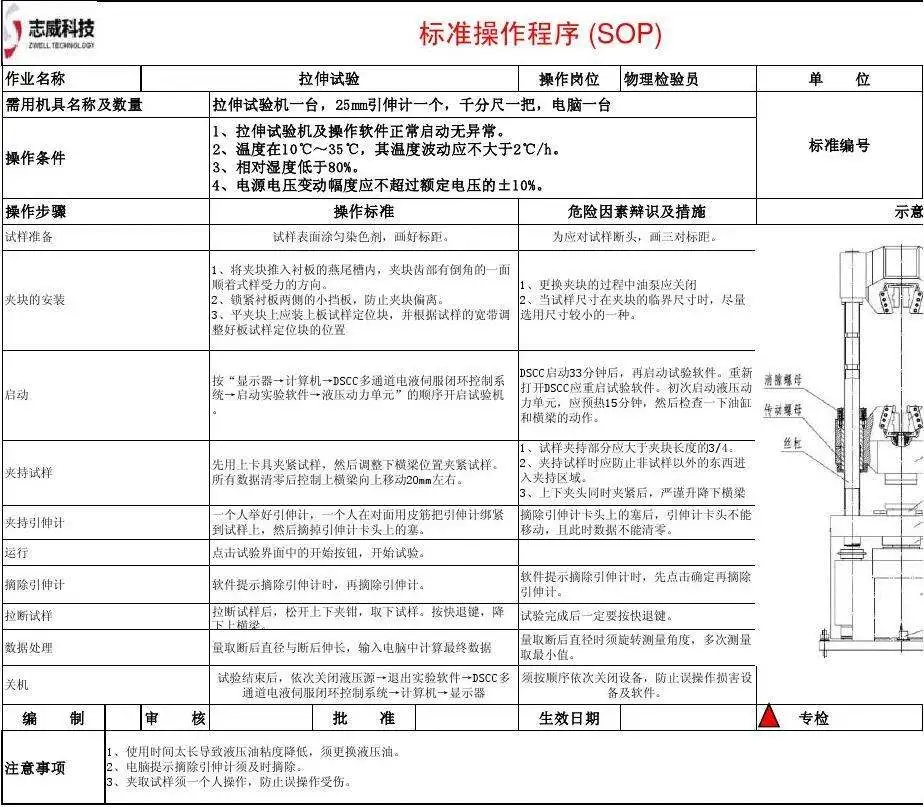
EOP(Emergency Operating Procedure三個單詞中首字母的大寫 )即應急操作流程,用于規范應急操作程序中的流程及操作步驟,確保人員可以迅速啟動,確保有序、有效的組織實施各項應對措施,
全鏈路壓測
全鏈路壓測是一個很好的資料說話的方法,下面要介紹的擴容和降級都要依賴于壓測的結果進行,同時,它也是提前發現系統問題的有效手段,
擋板壓測/聯合壓測/封版壓測
擋板壓測
擋板壓測就是鏈路上需要與外部互動的地方使用mock模擬來進行壓測,比如微信支付,要模擬使用銀行卡支付,不能每次壓測都先沖幾個億來做測驗吧,這時候可以模擬銀行側的回傳值進行模擬,這個環節主要用于發現內部問題,
聯合壓測
聯合壓測就是真的和互動的外部機構溝通好一起壓測,如果測驗微信支付,還真需要提前沖幾個億來做測驗,當然,測驗完可以退款,這個環節有個重要職責是驗證合作方能力,比如合作方有三個銀行,一個銀行并發量不夠,那大促時就少路由一些請求給它,
封版壓測
封版壓測其實和前面兩個壓測不在同一維度,封版壓測既可以是擋板壓測,也可以是聯合壓測,目的在于測驗系統穩定性,
重啟服務
Java服務如果長時間不發布,沒有任何bug的情況下也會記憶體緩慢增長,因為JVM申請了的記憶體,只要行程不死就不會釋放,雖然咱們JVM引數里指定了堆的大小和每個執行緒占用的大小,但是程式運行程序中還會不可避免的申請很多堆外記憶體,比如資料庫操作就會產生很多堆外記憶體,我負責的服務就發生過一個服務近1年沒有任何發布升級,記憶體比剛重啟后一周增長5%的情況,
除了記憶體,重啟還能避免很多慢性問題在一個關鍵點爆發,所以也熱點和秒殺保護的一個重要舉措之一,
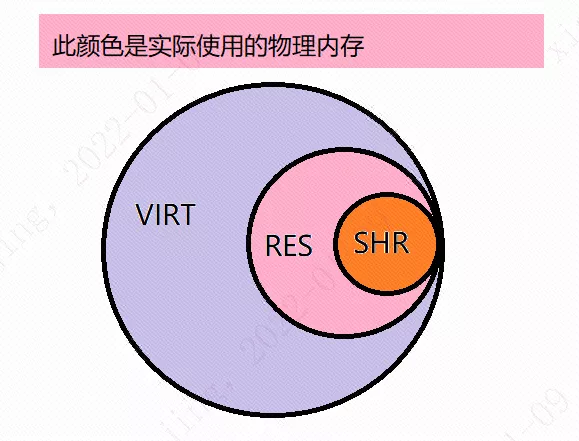
VIRT/RES/SHR
這里既然提到了JVM記憶體,那就順便說一下怎么觀察,常見的是使用top命令,

關鍵列的資料含義如下:
VIRT(虛擬記憶體)
1、行程“需要的”虛擬記憶體大小,包括行程使用的庫、代碼、資料,以及malloc、new分配的堆空間和分配的堆疊空間等;
2、假如行程新申請10MB的記憶體,但實際只使用了1MB,那么它會增長10MB,而不是實際的1MB使用量,
3、VIRT = SWAP + RES
RES(常駐記憶體)
1、行程當前使用的記憶體大小,包括使用中的malloc、new分配的堆空間和分配的堆疊空間,但不包括swap out量;
2、包含其他行程的共享;
3、如果申請10MB的記憶體,實際使用1MB,它只增長1MB,與VIRT相反;
4、關于庫占用記憶體的情況,它只統計加載的庫檔案所占記憶體大小,
5、RES = CODE + DATA
SHR(共享記憶體)
1、除了自身行程的共享記憶體,也包括其他行程的共享記憶體;
2、雖然行程只使用了幾個共享庫的函式,但它包含了整個共享庫的大小;
3、計算某個行程所占的物理記憶體大小公式:RES – SHR;
4、swap out后,它將會降下來,
它們之間的關系用一張圖來表示就是
擴容
微博歷史上曾發生過許多次服務器崩潰的情況,這種情況大多可以通過提前擴容解決的,但是一直停留在擴容狀態經費上有問題:一臺服務器每年成本按3萬來算,100臺就是300W,熱點流量帶來的收益并沒有高,
近幾年容器技術突飛猛進,對于熱點和秒殺等場景,有的公司已經做到了彈性伸縮,就是根據流量情況動態調整服務的集群機器數,公司還可以和云廠商合作,讓廠商提供動態擴容能力,
對于大公司而言,其實像阿里云、騰訊云這種云服務器的成本要比自己管理服務器成本要高,當然最貴的是亞馬遜云,這是題外話,像微博這種臨時擴容場景,服務器費用收取是按秒來計費的,
微博在【馬蓉事件】中,有次馬蓉說希望給自己來次專訪,微博提前租了阿里云機器,結果沒有提供任何實質性證據,也沒有什么流量,氣的微博團隊@馬蓉讓她結服務器的賬,
不管怎么說,很多熱點事件來臨前,提前擴容是可以解決問題的,所以,容器技術的一個重要指標就是創建容器的耗時,有的團隊已經做到30s可以創建一個容器,意思是點擊申請容器到容器上的業務鏡像啟動提供服務只需要30s!
降級
寫文章要注意邏輯倍訓,回到開頭“當年《甄嬛傳》熱播,呼叫了我們團隊的媒體資訊介面,介面被呼叫掛了”這個問題,
當時最大的問題是媒體資訊核心服務上有獲取視頻和專輯兩個主要介面,視頻咨詢內容很小,就是下圖所示內容簡介這些視頻的主要資訊,

而專輯如下圖所示的花絮呀、正片呀所有的這些主要內容簡介打包在一起,我記得當年《甄嬛傳》一個專輯包含了幾千個視頻資訊?

當時服務器就是因為呼叫專輯給調掛了,當時正確的做法應該是降級專輯,只回傳單個視頻資訊,當然了,在架構上,這個量級是要拆分服務的,這是題外話,
而在熱點秒殺來臨時,降級一些非核心服務,比如:定時服務、批量程式等,以節省帶寬、執行緒等資源給核心服務,據我了解,一般大公司秒殺之前都要走一套標準的降級流程,
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/413123.html
標籤:架構設計