大家好,我是 華仔, 又跟大家見面了,
上一篇作為專題系列的第二篇,從演進的角度帶你深度剖析了關于 Kafka 請求處理全流程以及超高并發的網路架構設計的實作細節,今天開啟第三篇,我們來聊聊 Kafka 生產環境大家都比較關心的問題,
那么 Kafka 到底會不會丟資料呢?如果丟資料,究竟該怎么解決呢?
只有掌握了這些, 我們才能處理好 Kafka 生產級的一些故障,從而更穩定地服務業務,
認真讀完這篇文章,我相信你會對Kafka 如何解決丟資料問題,有更加深刻的理解,
這篇文章干貨很多,希望你可以耐心讀完,
01 總體概述
越來越多的互聯網公司使用訊息佇列來支撐自己的核心業務,由于是核心業務,一般都會要求訊息傳遞程序中最大限度的做到不丟失,如果中間環節出現資料丟失,就會引來用戶的投訴,年底績效就要背鍋了,
那么使用 Kafka 到底會不會丟資料呢?如果丟資料了該怎么解決呢?為了避免類似情況發生,除了要做好補償措施,我們更應該在系統設計的時候充分考慮系統中的各種例外情況,從而設計出一個穩定可靠的訊息系統,
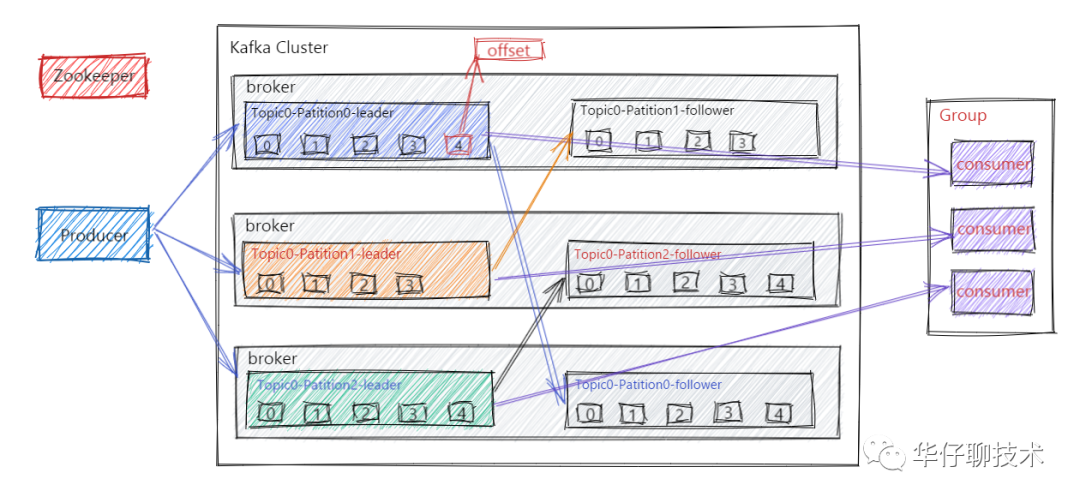
大家都知道 Kafka 的整個架構非常簡潔,是分布式的架構,主要由 Producer、Broker、Consumer 三部分組成,后面剖析丟失場景會從這三部分入手來剖析,
02 訊息傳遞語意剖析
在深度剖析訊息丟失場景之前,我們先來聊聊「訊息傳遞語意」到底是個什么玩意?
所謂的訊息傳遞語意是 Kafka 提供的 Producer 和 Consumer 之間的訊息傳遞程序中訊息傳遞的保證性,主要分為三種, 如下圖所示:
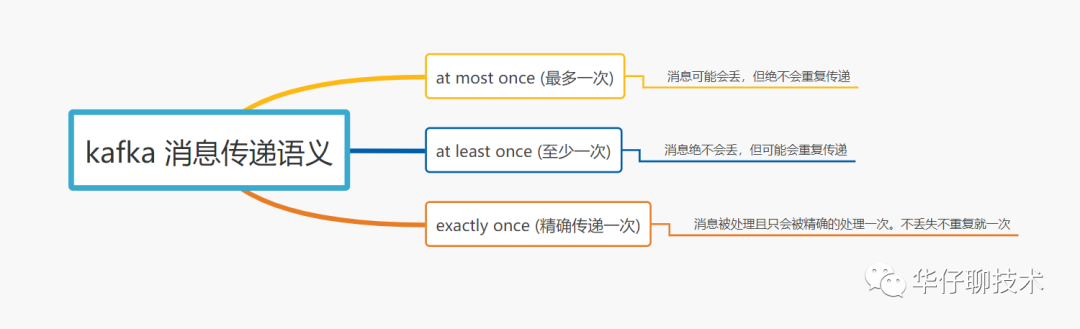
1)首先當 Producer 向 Broker 發送資料后,會進行 commit,如果 commit 成功,由于 Replica 副本機制的存在,則意味著訊息不會丟失,但是 Producer 發送資料給 Broker 后,遇到網路問題而造成通信中斷,那么 Producer 就無法準確判斷該訊息是否已經被提交(commit),這就可能造成 at least once 語意,
2)在 Kafka 0.11.0.0 之前, 如果 Producer 沒有收到訊息 commit 的回應結果,它只能重新發送訊息,確保訊息已經被正確的傳輸到 Broker,重新發送的時候會將訊息再次寫入日志中;而在 0.11.0.0 版本之后, Producer 支持冪等傳遞選項,保證重新發送不會導致訊息在日志出現重復,為了實作這個, Broker 為 Producer 分配了一個ID,并通過每條訊息的序列號進行去重,也支持了類似事務語意來保證將訊息發送到多個 Topic 磁區中,保證所有訊息要么都寫入成功,要么都失敗,這個主要用在 Topic 之間的 exactly once 語意,
其中啟用冪等傳遞的方法配置:enable.idempotence = true,
啟用事務支持的方法配置:設定屬性 transcational.id = "指定值",
3)從 Consumer 角度來剖析, 我們知道 Offset 是由 Consumer 自己來維護的, 如果 Consumer 收到訊息后更新 Offset, 這時 Consumer 例外 crash 掉, 那么新的 Consumer 接管后再次重啟消費,就會造成 at most once 語意(訊息會丟,但不重復),
4) 如果 Consumer 消費訊息完成后, 再更新 Offset, 如果這時 Consumer crash 掉,那么新的 Consumer 接管后重新用這個 Offset 拉取訊息, 這時就會造成 at least once 語意(訊息不丟,但被多次重復處理),
總結:默認 Kafka 提供 「at least once」語意的訊息傳遞,允許用戶通過在處理訊息之前保存 Offset 的方式提供 「at most once」 語意,如果我們可以自己實作消費冪等,理想情況下這個系統的訊息傳遞就是嚴格的「exactly once」, 也就是保證不丟失、且只會被精確的處理一次,但是這樣是很難做到的,
從 Kafka 整體架構圖我們可以得出有三次訊息傳遞的程序:
1)Producer 端發送訊息給 Kafka Broker 端,
2)Kafka Broker 將訊息進行同步并持久化資料,
3)Consumer 端從 Kafka Broker 將訊息拉取并進行消費,
在以上這三步中每一步都可能會出現丟失資料的情況, 那么 Kafka 到底在什么情況下才能保證訊息不丟失呢?
通過上面三步,我們可以得出:Kafka 只對 「已提交」的訊息做「最大限度的持久化保證不丟失」,
怎么理解上面這句話呢?
1)首先是 「已提交」的訊息:當 Kafka 中 N 個 Broker 成功的收到一條訊息并寫入到日志檔案后,它們會告訴 Producer 端這條訊息已成功提交了,那么這時該訊息在 Kafka 中就變成 "已提交訊息" 了,
這里的 N 個 Broker 我們怎么理解呢?這主要取決于對 "已提交" 的定義, 這里可以選擇只要一個 Broker 成功保存該訊息就算已提交,也可以是所有 Broker 都成功保存該訊息才算是已提交,
2)其次是 「最大限度的持久化保證不丟失」,也就是說 Kafka 并不能保證在任何情況下都能做到資料不丟失,即 Kafka 不丟失資料是有前提條件的,假如這時你的訊息保存在 N 個 Broker 上,那么前提條件就是這 N 個 Broker 中至少有1個是存活的,就可以保證你的訊息不丟失,
也就是說 Kafka 是能做到不丟失資料的, 只不過這些訊息必須是 「已提交」的訊息,且還要滿足一定的條件才可以,
了解了 Kafka 訊息傳遞語意以及什么情況下可以保證不丟失資料,下面我們來詳細剖析每個環節為什么會丟資料,以及如何最大限度的避免丟失資料,
03 訊息丟失場景剖析
Producer 端丟失場景剖析
在剖析 Producer 端資料丟失之前,我們先來了解下 Producer 端發送訊息的流程,對于不了解 Producer 的讀者們,可以查看 聊聊 Kafka Producer 那點事
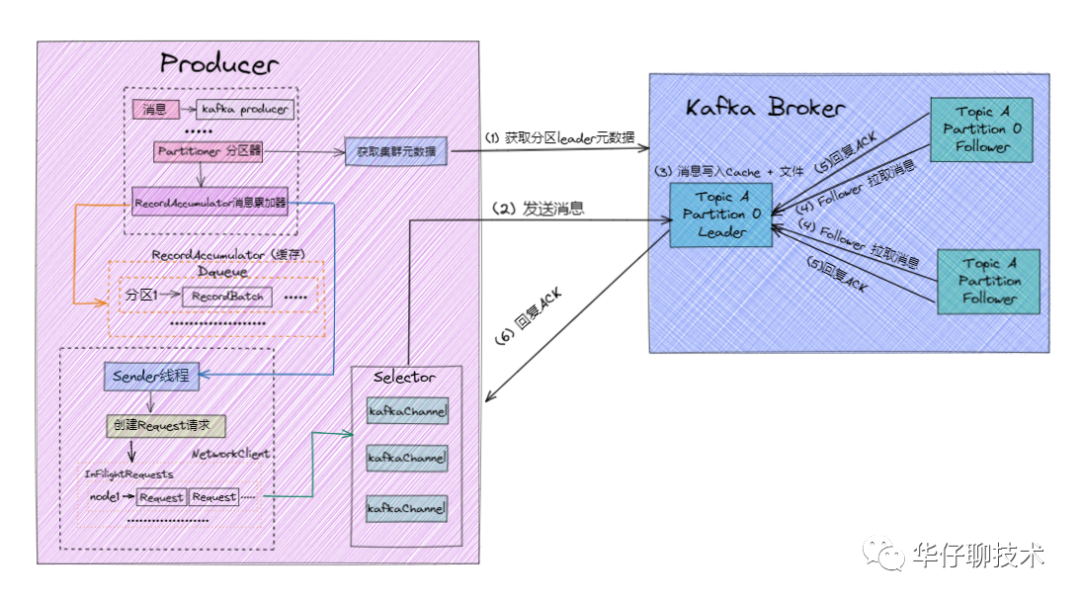
訊息發送流程如下:
1)首先我們要知道一點就是 Producer 端是直接與 Broker 中的 Leader Partition 互動的,所以在 Producer 端初始化中就需要通過 Partitioner 磁區器從 Kafka 集群中獲取到相關 Topic 對應的 Leader Partition 的元資料 ,
2)待獲取到 Leader Partition 的元資料后直接將訊息發送過去,
3)Kafka Broker 對應的 Leader Partition 收到訊息會先寫入 Page Cache,定時刷盤進行持久化(順序寫入磁盤),
4) Follower Partition 拉取 Leader Partition 的訊息并保持同 Leader Partition 資料一致,待訊息拉取完畢后需要給 Leader Partition 回復 ACK 確認訊息,
5)待 Kafka Leader 與 Follower Partition 同步完資料并收到所有 ISR 中的 Replica 副本的 ACK 后,Leader Partition 會給 Producer 回復 ACK 確認訊息,
根據上圖以及訊息發送流程可以得出:Producer 端為了提升發送效率,減少IO操作,發送資料的時候是將多個請求合并成一個個 RecordBatch,并將其封裝轉換成 Request 請求「異步」將資料發送出去(也可以按時間間隔方式,達到時間間隔自動發送),所以 Producer 端訊息丟失更多是因為訊息根本就沒有發送到 Kafka Broker 端,
導致 Producer 端訊息沒有發送成功有以下原因:
- 網路原因:由于網路抖動導致資料根本就沒發送到 Broker 端,
- 資料原因:訊息體太大超出 Broker 承受范圍而導致 Broker 拒收訊息,
另外 Kafka Producer 端也可以通過配置來確認訊息是否生產成功:
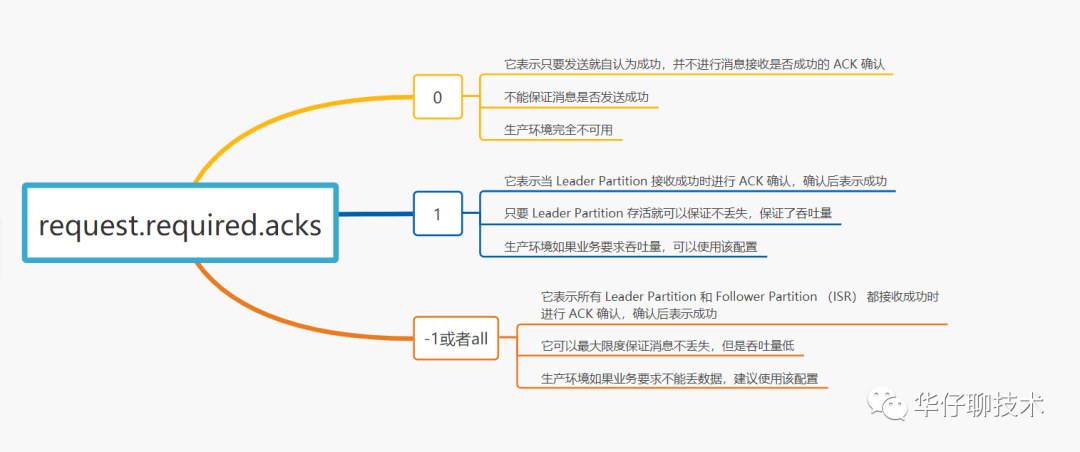
在 Kafka Producer 端的 acks 默認配置為1, 默認級別是 at least once 語意, 并不能保證 exactly once 語意,

既然 Producer 端發送資料有 ACK 機制, 那么這里就可能會丟資料的!!!
- acks = 0:由于發送后就自認為發送成功,這時如果發生網路抖動, Producer 端并不會校驗 ACK 自然也就丟了,且無法重試,
- acks = 1:訊息發送 Leader Parition 接收成功就表示發送成功,這時只要 Leader Partition 不 Crash 掉,就可以保證 Leader Partition 不丟資料,但是如果 Leader Partition 例外 Crash 掉了, Follower Partition 還未同步完資料且沒有 ACK,這時就會丟資料,
- acks = -1 或者 all: 訊息發送需要等待 ISR 中 Leader Partition 和 所有的 Follower Partition 都確認收到訊息才算發送成功, 可靠性最高, 但也不能保證不丟資料,比如當 ISR 中只剩下 Leader Partition 了, 這樣就變成 acks = 1 的情況了,
Broker 端丟失場景剖析
接下來我們來看看 Broker 端持久化存盤丟失場景, 對于不了解 Broker 的讀者們,可以先看看 聊聊 Kafka Broker 那點事,資料存盤程序如下圖所示:
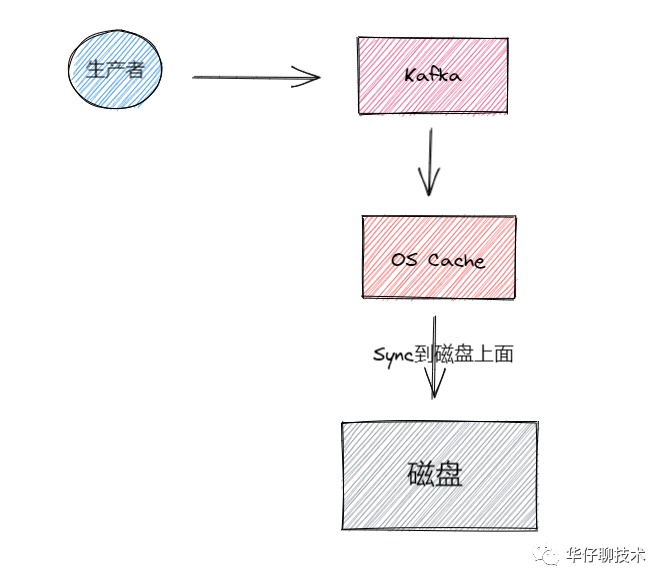
Kafka Broker 集群接收到資料后會將資料進行持久化存盤到磁盤,為了提高吞吐量和性能,采用的是「異步批量刷盤的策略」,也就是說按照一定的訊息量和間隔時間進行刷盤,首先會將資料存盤到 「PageCache」 中,至于什么時候將 Cache 中的資料刷盤是由「作業系統」根據自己的策略決定或者呼叫 fsync 命令進行強制刷盤,如果此時 Broker 宕機 Crash 掉,且選舉了一個落后 Leader Partition 很多的 Follower Partition 成為新的 Leader Partition,那么落后的訊息資料就會丟失,

既然 Broker 端訊息存盤是通過異步批量刷盤的,那么這里就可能會丟資料的!!!
- 由于 Kafka 中并沒有提供「同步刷盤」的方式,所以說從單個 Broker 來看還是很有可能丟失資料的,
- kafka 通過「多 Partition (磁區)多 Replica(副本)機制」已經可以最大限度的保證資料不丟失,如果資料已經寫入 PageCache 中但是還沒來得及刷寫到磁盤,此時如果所在 Broker 突然宕機掛掉或者停電,極端情況還是會造成資料丟失,
Consumer 端丟失場景剖析
接下來我們來看看 Consumer 端消費資料丟失場景,對于不了解 Consumer 的讀者們,可以先看看 聊聊 Kafka Consumer 那點事, 我們先來看看消費流程:
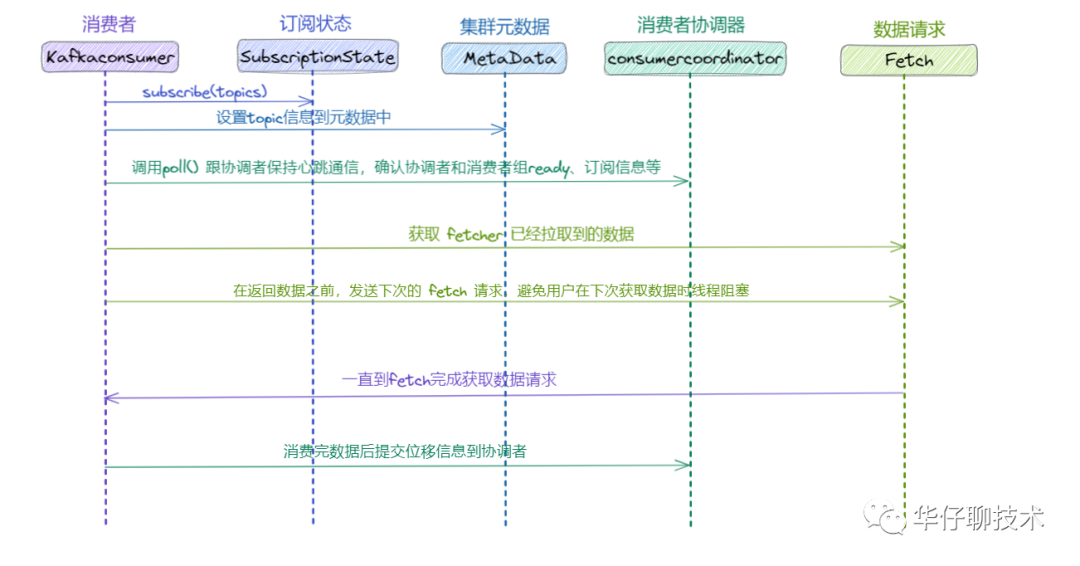
1)Consumer 拉取資料之前跟 Producer 發送資料一樣, 需要通過訂閱關系獲取到集群元資料, 找到相關 Topic 對應的 Leader Partition 的元資料,
2)然后 Consumer 通過 Pull 模式主動的去 Kafka 集群中拉取訊息,
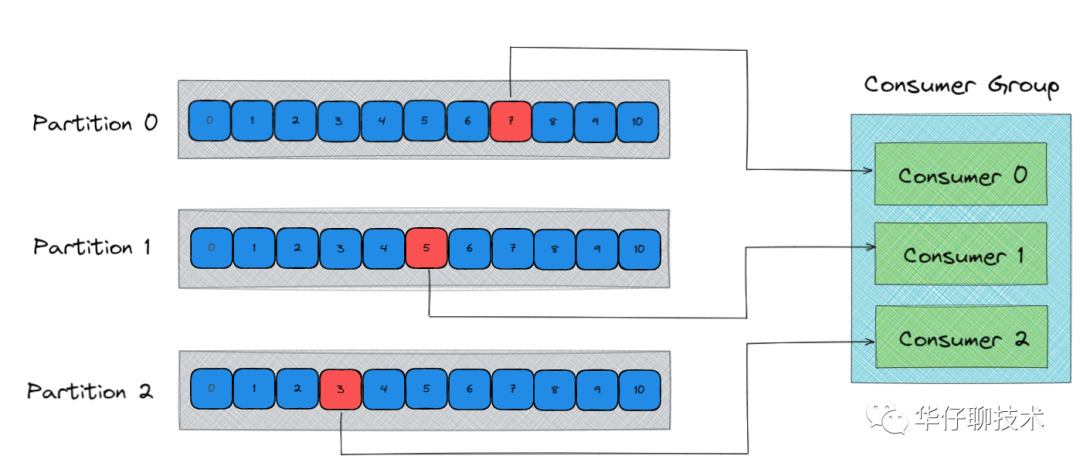
3)在這個程序中,有個消費者組的概念(不了解的可以看上面鏈接文章),多個 Consumer 可以組成一個消費者組即 Consumer Group,每個消費者組都有一個Group-Id,同一個 Consumer Group 中的 Consumer 可以消費同一個 Topic 下不同磁區的資料,但是不會出現多個 Consumer 去消費同一個磁區的資料,
4)拉取到訊息后進行業務邏輯處理,待處理完成后,會進行 ACK 確認,即提交 Offset 消費位移進度記錄,
5)最后 Offset 會被保存到 Kafka Broker 集群中的 __consumer_offsets 這個 Topic 中,且每個 Consumer 保存自己的 Offset 進度,
根據上圖以及訊息消費流程可以得出消費主要分為兩個階段:
- 獲取元資料并從 Kafka Broker 集群拉取資料,
- 處理消息,并標記訊息已經被消費,提交 Offset 記錄,

既然 Consumer 拉取后訊息最終是要提交 Offset, 那么這里就可能會丟資料的!!!
- 可能使用的「自動提交 Offset 方式」
- 拉取訊息后「先提交 Offset,后處理訊息」,如果此時處理訊息的時候例外宕機,由于 Offset 已經提交了, 待 Consumer 重啟后,會從之前已提交的 Offset 下一個位置重新開始消費, 之前未處理完成的訊息不會被再次處理,對于該 Consumer 來說訊息就丟失了,
- 拉取訊息后「先處理訊息,在進行提交 Offset」, 如果此時在提交之前發生例外宕機,由于沒有提交成功 Offset, 待下次 Consumer 重啟后還會從上次的 Offset 重新拉取訊息,不會出現訊息丟失的情況, 但是會出現重復消費的情況,這里只能業務自己保證冪等性,
04 訊息丟失解決方案
上面帶你從 Producer、Broker、Consumer 三端剖析了可能丟失資料的場景,下面我們就來看看如何解決才能最大限度的保證訊息不丟失,
Producer 端解決方案
在剖析 Producer 端丟失場景的時候, 我們得出其是通過「異步」方式進行發送的,所以如果此時是使用「發后即焚」的方式發送,即呼叫 Producer.send(msg) 會立即回傳,由于沒有回呼,可能因網路原因導致 Broker 并沒有收到訊息,此時就丟失了,
因此我們可以從以下幾方面進行解決 Producer 端訊息丟失問題:
4.1.1 更換呼叫方式:
棄用呼叫發后即焚的方式,使用帶回呼通知函式的方法進行發送訊息,即 Producer.send(msg, callback), 這樣一旦發現發送失敗, 就可以做針對性處理,
Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback);
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
// intercept the record, which can be potentially modified; this method does not throw exceptions
ProducerRecord<K, V> interceptedRecord = this.interceptors == null ? record : this.interceptors.onSend(record);
return doSend(interceptedRecord, callback);
}
(1)網路抖動導致訊息丟失,Producer 端可以進行重試,
(2)訊息大小不合格,可以進行適當調整,符合 Broker 承受范圍再發送,
通過以上方式可以保證最大限度訊息可以發送成功,
4.1.2 ACK 確認機制:
該引數代表了對"已提交"訊息的定義,
需要將 request.required.acks 設定為 -1/ all,-1/all 表示有多少個副本 Broker 全部收到訊息,才認為是訊息提交成功的標識,
針對 acks = -1/ all , 這里有兩種非常典型的情況:
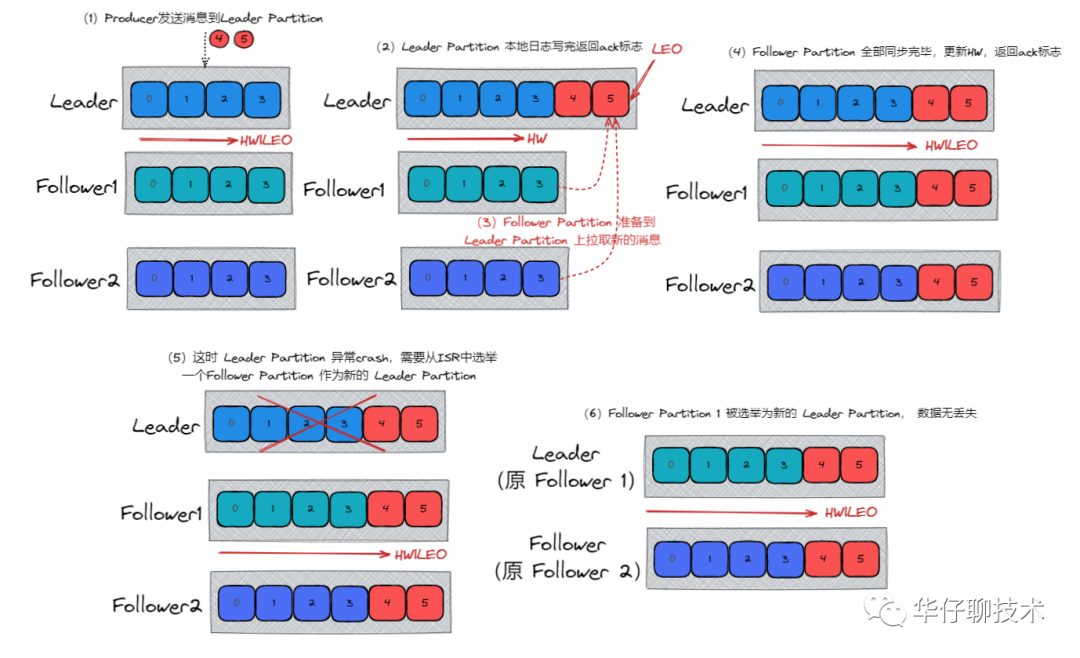
(1)資料發送到 Leader Partition, 且所有的 ISR 成員全部同步完資料, 此時,Leader Partition 例外 Crash 掉,那么會選舉新的 Leader Partition,資料不會丟失, 如下圖所示:
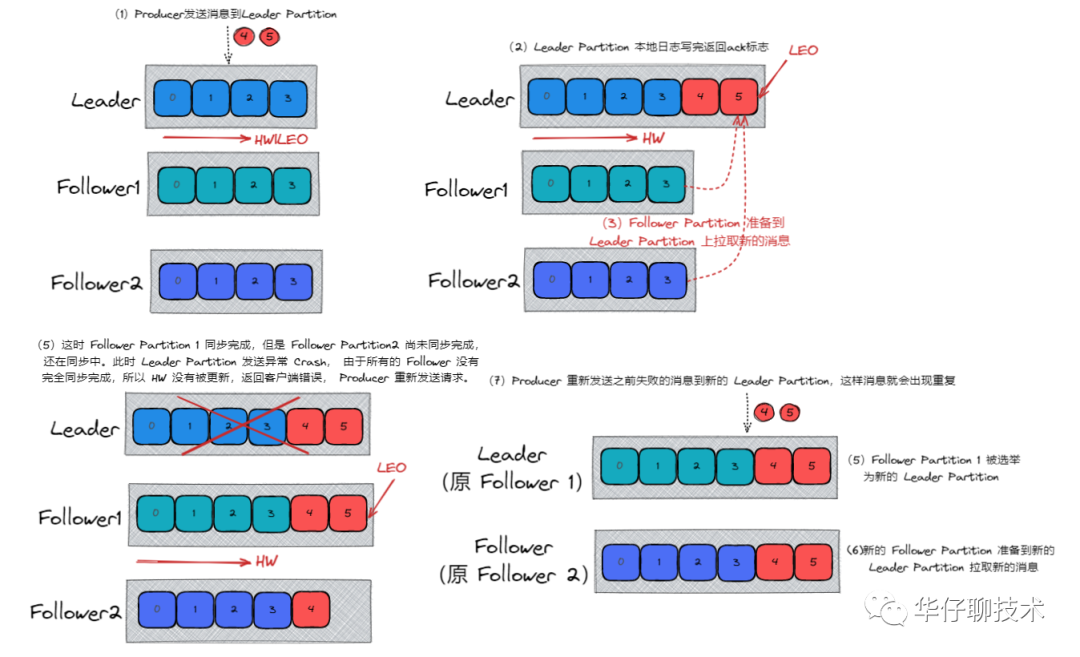
(2)資料發送到 Leader Partition,部分 ISR 成員同步完成,此時 Leader Partition 例外 Crash, 剩下的 Follower Partition 都可能被選舉成新的 Leader Partition,會給 Producer 端發送失敗標識, 后續會重新發送資料,資料可能會重復, 如下圖所示:
因此通過上面分析,我們還需要通過其他引數配置來進行保證:
replication.factor >= 2
min.insync.replicas > 1
這是 Broker 端的配置,下面會詳細介紹,
4.1.3 重試次數 retries:
該引數表示 Producer 端發送訊息的重試次數,
需要將 retries 設定為大于0的數, 在 Kafka 2.4 版本中默認設定為Integer.MAX_VALUE,另外如果需要保證發送訊息的順序性,配置如下:
retries = Integer.MAX_VALUE max.in.flight.requests.per.connection = 1
這樣 Producer 端就會一直進行重試直到 Broker 端回傳 ACK 標識,同時只有一個連接向 Broker 發送資料保證了訊息的順序性,
4.1.4 重試時間 retry.backoff.ms:
該引數表示訊息發送超時后兩次重試之間的間隔時間,避免無效的頻繁重試,默認值為100ms, 推薦設定為300ms,
Broker 端解決方案
在剖析 Broker 端丟失場景的時候, 我們得出其是通過「異步批量刷盤」的策略,先將資料存盤到 「PageCache」,再進行異步刷盤, 由于沒有提供 「同步刷盤」策略, 因此 Kafka 是通過「多磁區多副本」的方式來最大限度的保證資料不丟失,
我們可以通過以下引數配合來保證:
4.2.1 unclean.leader.election.enable:
該引數表示有哪些 Follower 可以有資格被選舉為 Leader , 如果一個 Follower 的資料落后 Leader 太多,那么一旦它被選舉為新的 Leader, 資料就會丟失,因此我們要將其設定為false,防止此類情況發生,
4.2.2 replication.factor:
該引數表示磁區副本的個數,建議設定 replication.factor >=3, 這樣如果 Leader 副本例外 Crash 掉,Follower 副本會被選舉為新的 Leader 副本繼續提供服務,
4.2.3 min.insync.replicas:
該引數表示訊息至少要被寫入成功到 ISR 多少個副本才算"已提交",建議設定min.insync.replicas > 1, 這樣才可以提升訊息持久性,保證資料不丟失,
另外我們還需要確保一下 replication.factor > min.insync.replicas, 如果相等,只要有一個副本例外 Crash 掉,整個磁區就無法正常作業了,因此推薦設定成: replication.factor = min.insync.replicas +1, 最大限度保證系統可用性,
Consumer 端解決方案
在剖析 Consumer 端丟失場景的時候,我們得出其拉取完訊息后是需要提交 Offset 位移資訊的,因此為了不丟資料,正確的做法是:拉取資料、業務邏輯處理、提交消費 Offset 位移資訊,
我們還需要設定引數 enable.auto.commit = false, 采用手動提交位移的方式,
另外對于消費訊息重復的情況,業務自己保證冪等性, 保證只成功消費一次即可,
05 總結
這里,我們一起來總結一下這篇文章的重點,
1、從 Kafka 整體架構上概述了可能發生資料丟失的環節,
2、帶你剖析了「訊息傳遞語意」的概念, 確定了 Kafka 只對「已提交」的訊息做「最大限度的持久化保證不丟失」,
3、帶你剖析了 Producer、Broker、Consumer 三端可能導致資料丟失的場景以及具體的高可靠解決方案,
如果我的文章對你有所幫助,還請幫忙點贊、在看、轉發一下,非常感謝!
最后說一句(求關注,別白嫖我)
堅持總結, 持續輸出高質量文章 關注我的微信公眾號: 【華仔聊技術】
也可以加我微信好友:meng_philip, 回復 【加群】 可以跟BAT大咖一起學習進步
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/413146.html
標籤:其他
上一篇:熱點和秒殺來臨前要做的5件事