Acrobot機械臂🤔
- 寫在前面
- Acrobot機械臂
- show me code, no bb
- 結果展示
- 寫在最后
- 謝謝點贊交流!(?′?`?)
更多代碼: gitee主頁:https://gitee.com/GZHzzz
博客主頁: CSDN:https://blog.csdn.net/gzhzzaa
寫在前面
- 作為一個新手,寫這個強化學習-基礎知識專欄是想和大家分享一下自己強化學習的學習歷程,希望大家互相交流一起進步!😁在我的gitee收集了強化學習經典論文:強化學習經典論文,搭建了基于pytorch的典型智能體模型,大家一起多篇多交流,互相學習啊!😊
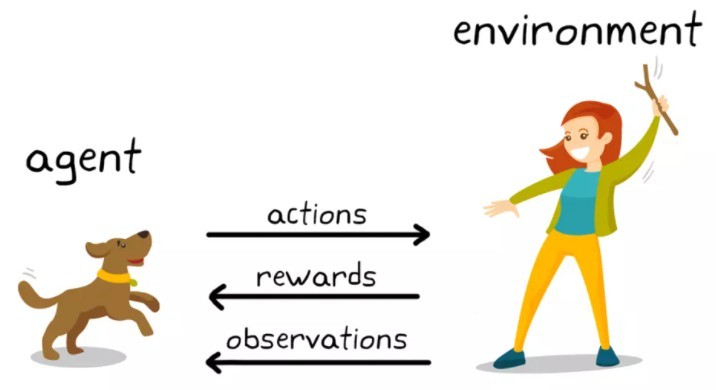
Acrobot機械臂
- Acrobot機器人系統包括兩個關節和兩個連桿,其中兩個連桿之間的關節可以被致動, 最初,連桿是向下懸掛的,目標是將下部連桿的末端擺動到給定的高度,

show me code, no bb
import sys
import logging
import itertools
import numpy as np
np.random.seed(0)
import pandas as pd
import gym
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
import torch.distributions as distributions
torch.manual_seed(0)
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s [%(levelname)s] %(message)s',
stream=sys.stdout, datefmt='%H:%M:%S')
# 加載環境
env = gym.make('Acrobot-v1')
env.seed(0)
for key in vars(env):
logging.info('%s: %s', key, vars(env)[key])
for key in vars(env.spec):
logging.info('%s: %s', key, vars(env.spec)[key])
# 加載智能體
class AdvantageActorCriticAgent:
def __init__(self, env):
self.gamma = 0.99
self.actor_net = self.build_net(
input_size=env.observation_space.shape[0],
hidden_sizes=[100,],
output_size=env.action_space.n, output_activator=nn.Softmax(1))
self.actor_optimizer = optim.Adam(self.actor_net.parameters(), 0.0001)
self.critic_net = self.build_net(
input_size=env.observation_space.shape[0],
hidden_sizes=[100,])
self.critic_optimizer = optim.Adam(self.critic_net.parameters(), 0.0002)
self.critic_loss = nn.MSELoss()
def build_net(self, input_size, hidden_sizes, output_size=1,
output_activator=None):
layers = []
for input_size, output_size in zip(
[input_size,] + hidden_sizes, hidden_sizes + [output_size,]):
layers.append(nn.Linear(input_size, output_size))
layers.append(nn.ReLU())
layers = layers[:-1]
if output_activator:
layers.append(output_activator)
net = nn.Sequential(*layers)
return net
def reset(self, mode=None):
self.mode = mode
if self.mode == 'train':
self.trajectory = []
self.discount = 1.
def step(self, observation, reward, done):
state_tensor = torch.as_tensor(observation, dtype=torch.float).reshape(1, -1)
prob_tensor = self.actor_net(state_tensor)
action_tensor = distributions.Categorical(prob_tensor).sample()
action = action_tensor.numpy()[0]
if self.mode == 'train':
self.trajectory += [observation, reward, done, action]
if len(self.trajectory) >= 8:
self.learn()
self.discount *= self.gamma
return action
def close(self):
pass
def learn(self):
state, _, _, action, next_state, reward, done, next_action \
= self.trajectory[-8:]
state_tensor = torch.as_tensor(state, dtype=torch.float).unsqueeze(0)
next_state_tensor = torch.as_tensor(next_state, dtype=torch.float).unsqueeze(0)
# calculate TD error
next_v_tensor = self.critic_net(next_state_tensor)
target_tensor = reward + (1. - done) * self.gamma * next_v_tensor
v_tensor = self.critic_net(state_tensor)
td_error_tensor = target_tensor - v_tensor
# train actor
pi_tensor = self.actor_net(state_tensor)[0, action]
logpi_tensor = torch.log(pi_tensor.clamp(1e-6, 1.))
actor_loss_tensor = -(self.discount * td_error_tensor * logpi_tensor).squeeze()
self.actor_optimizer.zero_grad()
actor_loss_tensor.backward(retain_graph=True)
self.actor_optimizer.step()
# train critic
pred_tensor = self.critic_net(state_tensor)
critic_loss_tensor = self.critic_loss(pred_tensor, target_tensor)
self.critic_optimizer.zero_grad()
critic_loss_tensor.backward()
self.critic_optimizer.step()
agent = AdvantageActorCriticAgent(env)
# 訓練與測驗
def play_episode(env, agent, max_episode_steps=None, mode=None, render=False):
observation, reward, done = env.reset(), 0., False
agent.reset(mode=mode)
episode_reward, elapsed_steps = 0., 0
while True:
action = agent.step(observation, reward, done)
if render:
env.render()
if done:
break
observation, reward, done, _ = env.step(action)
episode_reward += reward
elapsed_steps += 1
if max_episode_steps and elapsed_steps >= max_episode_steps:
break
agent.close()
return episode_reward, elapsed_steps
logging.info('==== train ====')
episode_rewards = []
for episode in itertools.count():
episode_reward, elapsed_steps = play_episode(env.unwrapped, agent,
max_episode_steps=env._max_episode_steps, mode='train',render=1)
episode_rewards.append(episode_reward)
logging.debug('train episode %d: reward = %.2f, steps = %d',
episode, episode_reward, elapsed_steps)
if np.mean(episode_rewards[-10:]) > -120:
break
plt.plot(episode_rewards)
logging.info('==== test ====')
episode_rewards = []
for episode in range(100):
episode_reward, elapsed_steps = play_episode(env, agent)
episode_rewards.append(episode_reward)
logging.debug('test episode %d: reward = %.2f, steps = %d',
episode, episode_reward, elapsed_steps)
logging.info('average episode reward = %.2f ± %.2f',
np.mean(episode_rewards), np.std(episode_rewards))
env.close()
- 代碼全部親自跑過,你懂的!😝
結果展示
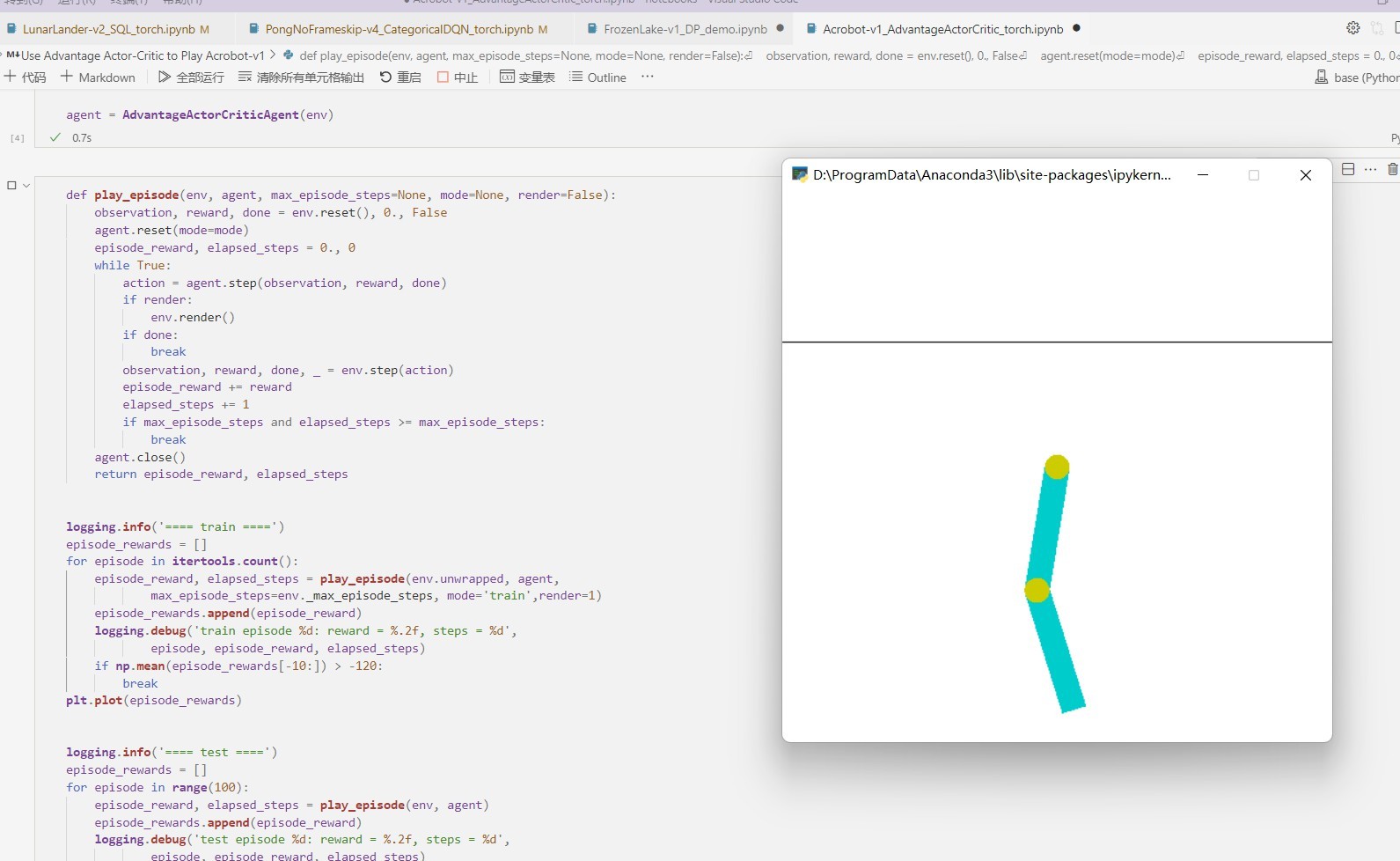
寫在最后
十年磨劍,與君共勉!
更多代碼:gitee主頁:https://gitee.com/GZHzzz
博客主頁:CSDN:https://blog.csdn.net/gzhzzaa
- Fighting!😎
基于pytorch的經典模型:基于pytorch的典型智能體模型
強化學習經典論文:強化學習經典論文

while True:
Go life

謝謝點贊交流!(?′?`?)
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/413951.html
標籤:其他