手把手帶你玩轉C
什么?資料在記憶體存盤原來這么好玩!(整形篇)
經過一個學期的學習,我們初步了解到資料型別有基本的char,int,short,long,long long,以及float和double,但是我們只知道怎樣去用他們去定義一個變數型別,為了讓大家能夠在敲代碼時候不單單感覺這只是一串字母,特地寫此文章來深度剖析資料在記憶體中存盤的方式,
1.資料型別的再回顧
相信各位之前都已經學習過了基本的內置型別
char //字符資料型別 1byte
short //短整型 2byte
int //整形 4byte
long //長整型 4byte
long long(c99起) //更長的整形 8byte
float //單精度浮點數 4byte
double //雙精度浮點數 8byte
其中long long 型別是在c99標準以后才有的型別,
附上圖片: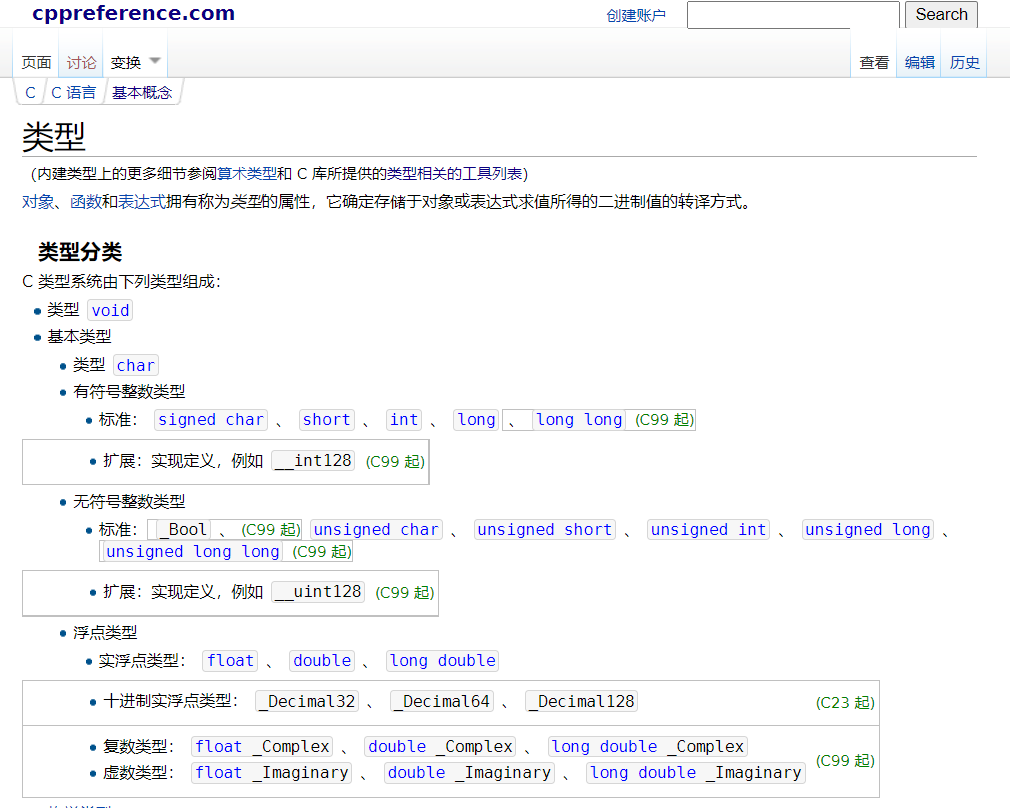
其中我們注意到C語言中有一個我們不常用的型別,但是和我們平常的判斷有關
布爾型別:_Bool -專門用于判斷真偽的變數(同樣是在C99標準開始以后才加入)
//_Bool 用于判斷真偽
#include <stdbool.h>
int main()
{
_Bool flag = false//(false代表假,true代表真)
if(flag)
{
printf("flag為真\n");
}
//if(flag)括號里的flag與0或非零的作用一樣,起判斷作用 false 等同于0 true 等同于 1
return 0;
}
使用布爾型別時,記得引頭檔案<stdbool.h>
仔細去分析_Bool型別以后,發現布爾型別它只是int 型別的重命名
型別的意義:
1.使用這個型別開辟記憶體空間的大小(大小決定了使用范圍),
2.如何看待記憶體空間的視角 ,
1.1資料型別的基本歸類
整形家族的型別:
char型別,其中細分為unsigned char以及 signed char ;及有符號的char和無符號的char,那么平常在我們使用時候很少區分,我們在敲代碼時候直接創建的char 是屬于什么型別呢?
short 細分為unsigned short 以及 signed short,其中使用short創建變數的時候,默認為signed short;
int 同樣細分為unsigned int 以及 signed int,默認int 為signed int;
long 與int以及short類似;
//當我們直接使用char創建變數時候,unsigned和signed型別取決了編譯器,并不是固定的,但是在vs中默認為signed char型別
何時使用unsigned int 型別呢?例:定義一個年齡變數時候,使用unsigned int age ;因為年齡恒為正數;
假設不小心使用了unsigned 型別時候存盤了一個負數,它仍然會將它轉化為正正數理解并非去掉負號或者符號那么簡單;
當我們列印有符號整形時應該用%d列印,用無符號整形時應該用%u
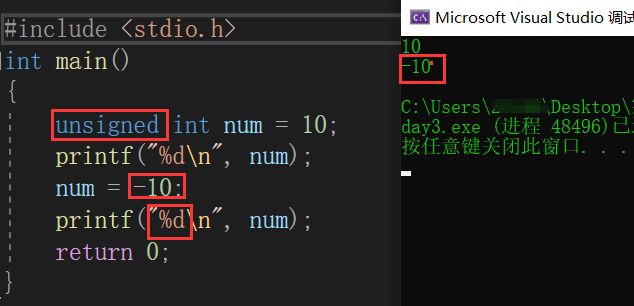
注意到,當我們使用無符號整形存盤了一個-10時候,它仍然利用%d的形式直接列印了出來,疑惑來了,那他們不是沒有什么區別嗎?難道是我前面說了一大堆廢話么,并不是,當你使用unsigned型別時候,列印時應該用的是%u,從一開始列印就錯了,那么只會一錯到底!
真正的情況是這樣滴:
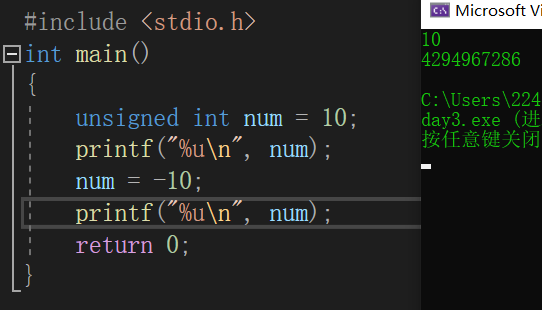
會不會頓時覺得,哇amazing!!!,竟然從-10變成這么大一個數,簡直就是翻身做地主啊,那么為什么會變化那么大呢,誒別急,后面告訴你答案,
浮點數家族:
float 單精度
double 雙精度
構造型別(自定義型別):
> 陣列型別
> 結構體型別 struct
> 列舉型別 enum
> 聯合型別 union
陣列型別:
例如int arr[10];int arr[5];就是兩種型別,我們把函式名這里是arr除去,留下的就是型別名,這里是int 【10】 和 int 【5】 ,所以是自定義型別,
指標型別:
int * pi ;
char * pc ;
float* pf ;
void* pv ;
用于對不同型別的變數地址的存盤,存盤一個變數的地址時候,它們的型別是需要一一對應的,
int main()
{
char a = 'b';
char *pc = &a;
return 0;
}
空型別:
void 表示空型別(無型別)
通常應用于函式的回傳型別、函式的引數、指標型別,
2.整形在記憶體中的存盤
一個變數的創建是要在記憶體中開辟空間的,空間的大小是根據不同的型別而決定的,
接下來我們具體談談資料是怎樣在開辟的記憶體當中存盤的,
比如
int a = 10;
int b = -10
在創建a的變數時候,系統為a分配了4個位元組的空間,那這些資料是如何存盤的呢?
2.1原碼、反碼、補碼
計算機中的整數有三種表示方法,即原碼、反碼和補碼,
三種表示方法均有符號位和數值位兩部分,符號位都是用0表示“正”,用1表示“負”
負整數的三種表示方法各不相同分別為:
原碼
直接將二進制按照正負數的形式翻譯成二進制就可以,
反碼
將原碼的符號位不變,其他位依次按位取反(1變0,0變1)就可以得到了,
補碼
反碼 +1 就得到補碼,
正數的原、反、補碼都相同,
對于整形來說:資料存放記憶體中其實存放的是補碼,
首先一步一步來決議:
1.怎樣去理解符號位和數值位呢?我用一幅圖教會

2.負數具體怎樣操作?

剛剛好像漏掉了一個問題,但是在我這篇細致到極致的文章怎么能少呢?“對于整形來說:資料存放記憶體中其實存放的是補碼,”
為什么呢?
在計算機系統中,數值一律用補碼來表示和存盤,原因在于,使用補碼,可以將符號位和數值域統一處理;
同時,加法和減法也可以統一處理(CPU只有加法器)此外,補碼與原碼相互轉換,其運算程序是相同的,不需要額外的硬體電路,
我通過一個加法減法的問題對這句話進行一個解釋,
[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-lFQZChln-1642431362803)(C:/Users/22479/AppData/Roaming/Typora/typora-user-images/image-20220117214133533.png)]


不得感嘆到當年能想到創造出補碼的人實在是太過于強大,最強大腦了屬于是,在學習程序中我們也要不斷保持敬畏之心!
此外剛剛那句話還提到了**“補碼與原碼相互轉換程序是相同的”**
我們知道,原碼到補碼的程序是原碼**—(按位取反,符號位不變)—>反碼—(反碼+1)—>**補碼
那么我們從這句話可得:補碼**—(按位取反,符號位不變)—>反碼—(反碼+1)—>**原碼
一直在提記憶體記憶體記憶體,有沒有什么方法讓我直觀的可以看到資料在記憶體理的存盤方式?
有,必須有!!!今天高低給你整明白它!,盤它!
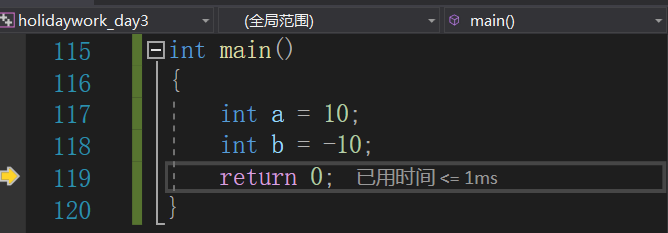
首先我們在記憶體中開辟空間分別命名為a和b;
接下來利用vs的的除錯模式觀察記憶體里面的資訊:
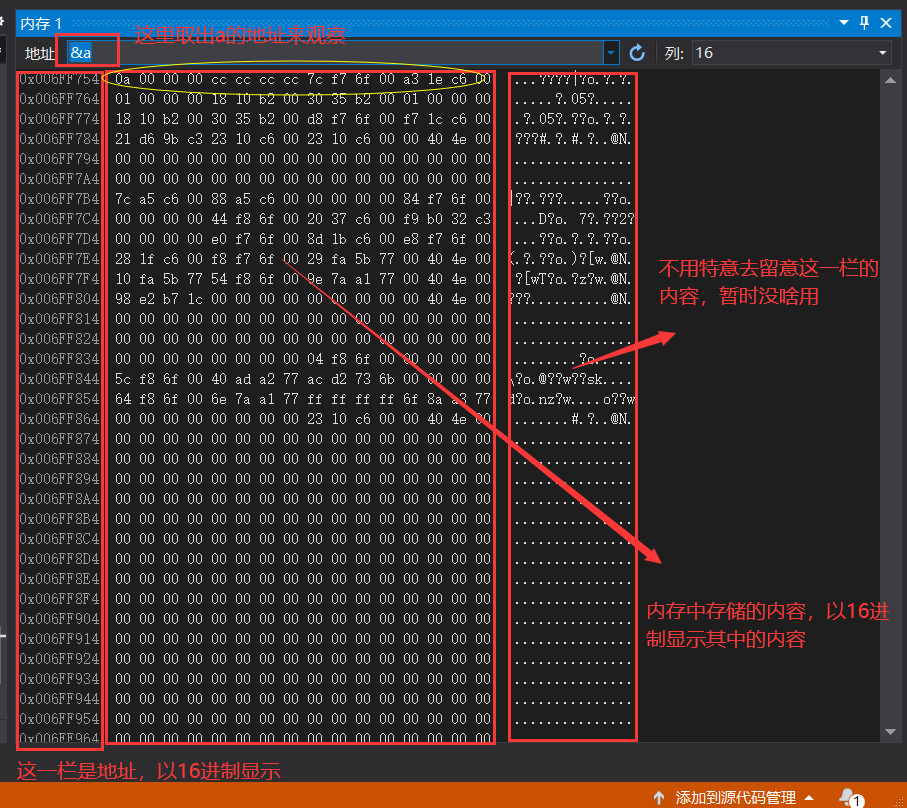
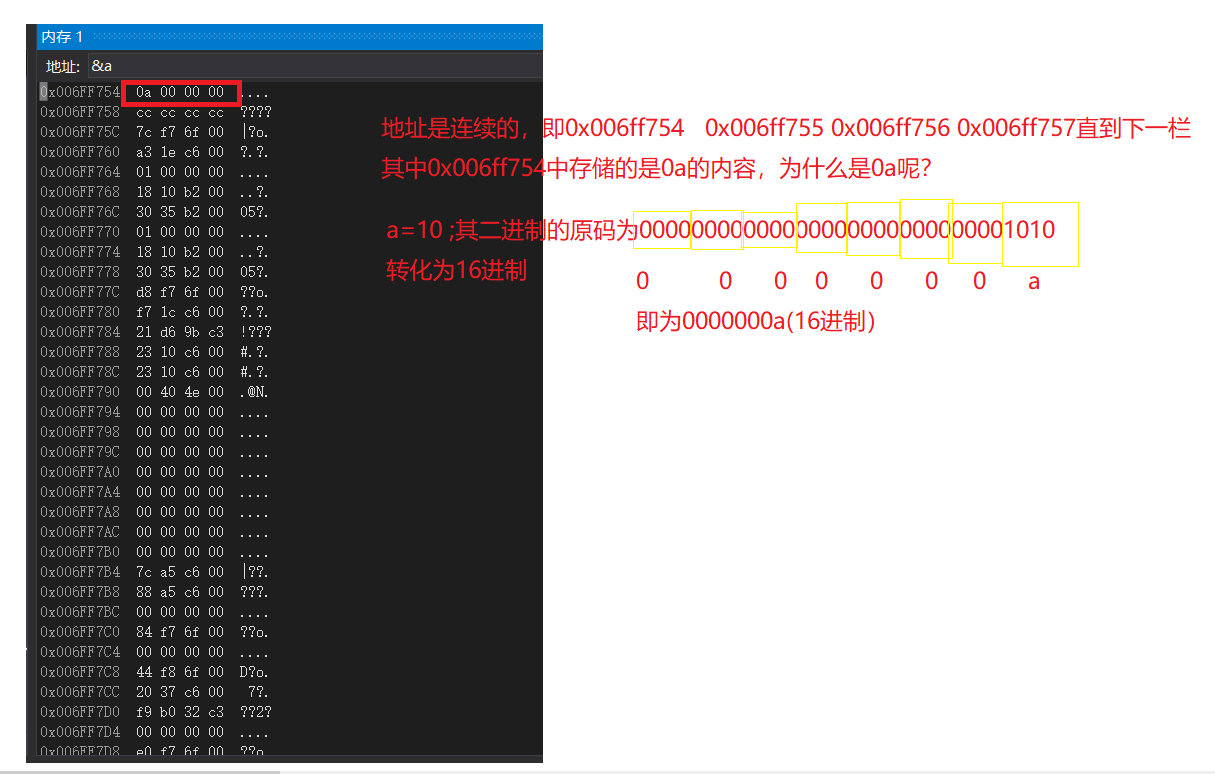
問題不對啊?紅框里面明明是0a 00 00 00,順序有點和你這也對不上啊?
2.2大小端位元組序
什么是大端小端:
大端(存盤)模式,是指資料的低位保存在記憶體的高地址中,而資料的高位,保存在記憶體的低地址 中;
小端(存盤)模式,是指資料的低位保存在記憶體的低地址中,而資料的高位 , ,保存在記憶體的高地 址中,
為什么有大端和小端:
為什么會有大小端模式之分呢?這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元 都對應著一個位元組,一個位元組為8 bit ,但是在 C 語言中除了 8 bit 的 char 之外,還有 16 bit 的 short 型, 32 bit 的 long 型(要看具體的編 譯器),另外,對于位數大于 8 位 的處理器,例如 16 位或者 32 位的處理器,由于暫存器寬度大于一個位元組,那么必然存在著一個如 何將多個位元組安排的問題,因此就 導致了大端存盤模式和小端存盤模式,
例如:一個 16bit 的 short 型 x ,在記憶體中的地址為 0x0010 , x 的值為 0x1122 ,那么 0x11 為 高位元組, 0x22 為低位元組,對于大端 模式,就將 0x11 放在低地址中,即 0x0010 中, 0x22 放在高地址中,即 0x0011 中,小端模式, 剛好相反,我們常用的 X86 結構是 小端模式,而 KEIL C51 則為大端模式,很多的 ARM , DSP 都為小端模式,有些 ARM 處理器還可以 由硬體來選擇是大端模式還是小端 模式,
什么低地址高地址,低位高位,我不懂怎么辦?上圖!
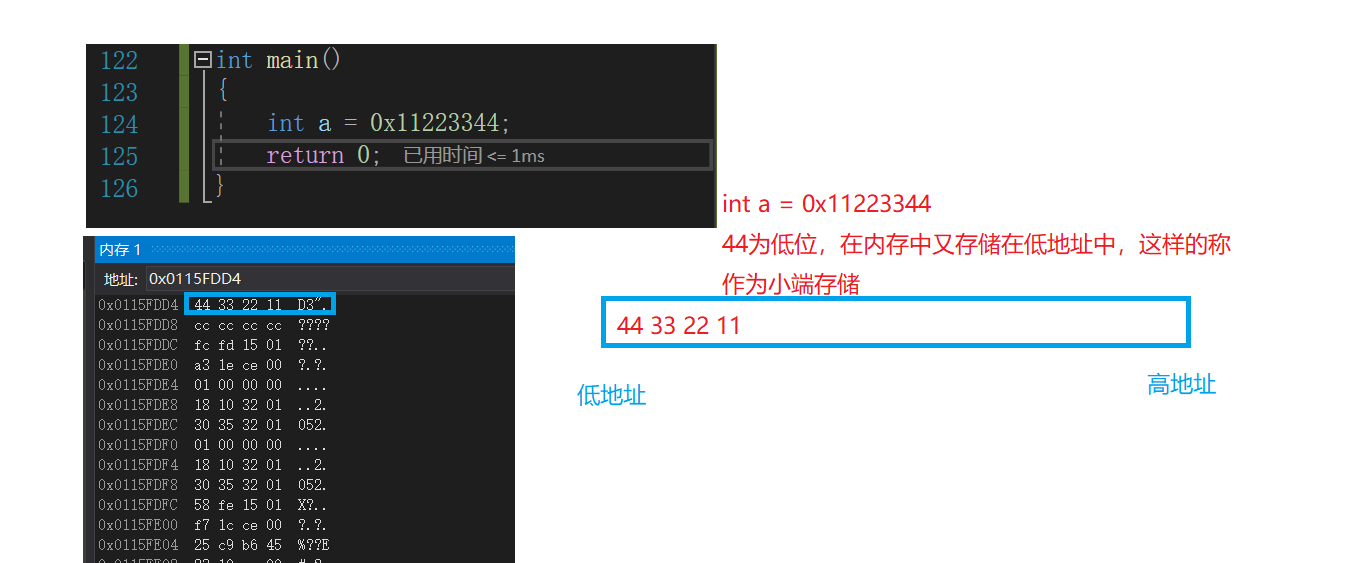

以上兩幅圖看完以后是不是簡潔明了很多了呢?
2.3練習
配套這篇文章也為了讓大家寒假過的沒那么枯燥,我準備了配套的練習題,關注我的公眾號:源晨序,回復記憶體練習即可獲取;
同時同步更新在CSDN上,

轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/413963.html
標籤:其他