我有一個適用于一個檔案的腳本。它從一個json檔案中獲取資訊,提取一個串列及其子串列(A),然后是另一個串列 B,其中包含串列 A 的第三個元素。它使用串列 B 創建一個資料框,并將其與主檔案進行比較。最后,它提供了兩個數字:串列 B 中的元素數和與主檔案比較時該串列的匹配元素數。
但是,我json在一個檔案夾中有 180 個不同的檔案,我需要為所有這些檔案運行腳本,并為每個檔案構建一個包含結果的資料框。所以最終的結果應該是這樣的(注意最后一行的數字是正確的,前兩個是虛構的):
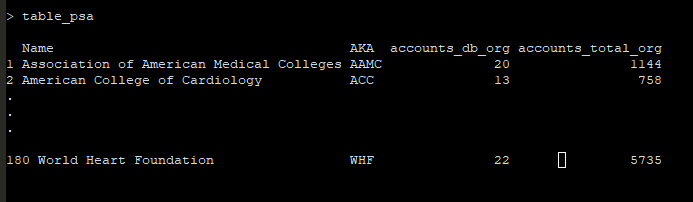
我到目前為止的代碼如下:
library(rjson)
library(dplyr)
library(tidyverse)
#load data from file
file <- "./raw_data/whf.json"
json_data <- fromJSON(file = file)
org_name <- json_data$id
# extract lists and the sublist
usernames <- json_data$twitter
following <- usernames$following
# create empty vector to populate
longitud = length(following)
names <- vector(length = longitud)
# loop to populate the empty vector with third element of the sub-list
for(i in 1:longitud){
names[i] <- following[[i]][3]
}
# create a data frame and change column name
names_list <- data.frame(sapply(names, c))
colnames(names_list) <- "usernames"
# create a data frame with the correct formatting ready to comparison
org_handles <- data.frame(paste("@", names_list$usernames, sep=""))
colnames(org_handles) <- "Twitter"
# load master file and select the needed columns
psa_handles <- read_csv(file = "./raw_data/psa_handles.csv") %>%
select(Name, AKA, Twitter)
# merge data frames and present the results
org_list <- inner_join(psa_handles, org_handles)
length(org_list$Twitter)
length(usernames$following)
我的第一次嘗試是在開頭包含此代碼:
files <- list.files()
for(f in files){
json_data <- fromJSON(file = f)
# the rest of the script for one file here
}
但我不知道如何為資料框撰寫代碼,甚至不知道如何整合這兩個想法——作業腳本和檔案名的回圈。我從這里得到了這個想法。
Alvaro Morales 回答后的新代碼如下
library(rjson)
library(dplyr)
library(tidyverse)
archivos <- list.files("./raw_data/")
calculate_accounts <- function(archivos){
#load data from file
path <- paste("./raw_data/", archivos, sep = "")
json_data <- fromJSON(file = path)
org_name <- json_data$id
# extract lists and the sublist
usernames <- json_data$twitter
following <- usernames$following
# create empty vector to populate
longitud = length(following)
names <- vector(length = longitud)
# loop to populate the empty vector with third element of the sub-list
for(i in 1:longitud){
names[i] <- following[[i]][3]
}
# create a data frame and change column name
names_list <- data.frame(sapply(names, c))
colnames(names_list) <- "usernames"
# create a data frame with the correct formatting ready to comparison
org_handles <- data.frame(paste("@", names_list$usernames, sep=""))
colnames(org_handles) <- "Twitter"
# load master file and select the needed columns
psa_handles <- read_csv(file = "./psa_handles.csv") %>%
select(Name, AKA, Twitter)
# merge data frames and present the results
org_list <- inner_join(psa_handles, org_handles)
accounts_db_org <- length(org_list$Twitter)
accounts_total_org <- length(usernames$following)
}
table_psa <- map_dfr(archivos, calculate_accounts)
但是,現在當 時出現錯誤Joining, by = "Twitter",它說subindex out of limits。
3 個測驗檔案的鏈接放在raw_data檔案夾中:
https://drive.google.com/file/d/1ilUHwLjgtZCzh0LneIJEhTryrGumDF1V/view?usp=sharing
https://drive.google.com/file/d/1KM3hRZ8DzgPMEsMFmwBdmMNHrPCttuaB/view?usp=sharing
https://drive.google.com/file/d/17cWXJ9ltGXZ6izkgJv0uyNwStrE95_OA/view?usp=sharing
鏈接到主檔案進行比較:
https://drive.google.com/file/d/11fOpYFFfHijhZl_CuWHKvkrI7edkpUNQ/view?usp=sharing
<<<<< 更新>>>>>>
我正在嘗試找到解決方案,我完成了代碼作業并提供了一個驗證輸出(一個 180x3 資料框),但是應該用物件的值填充的列accounts_db_org正在accounts_total_org顯示NA。檢查存盤在這些物件中的值時,這些值是正確的(對于最后一次迭代)。所以現在的輸出是正確的格式,但NA不是數字。
我真的很接近,但我無法讓代碼顯示正確的數字。我的最后一次嘗試是:
library(rjson)
library(dplyr)
library(tidyverse)
archivos <- list.files("./raw_data", pattern = "json", full.names = TRUE)
psa_handles <- read_csv(file = "./raw_data/psa_handles.csv", show_col_types = FALSE) %>%
select(Name, AKA, Twitter)
nr_archivos <- length(archivos)
psa_result <- matrix(nrow = nr_archivos, ncol = 3)
# loop for working with all files, one by one
for(f in 1:nr_archivos){
# load file
json_data <- fromJSON(file = archivos[f])
org_name <- json_data$id
# extract lists and the sublist
usernames <- json_data$twitter
following <- usernames$following
# empty vector
longitud = length(following)
names <- vector(length = longitud)
# loop to populate with the third element of each i item of the sublist
for(i in 1:longitud){
names[i] <- following[[i]][3]
}
# convert the list into a data frame
names_list <- data.frame(sapply(names, c))
colnames(names_list) <- "usernames"
# applying some format prior to comparison
org_handles <- data.frame(paste("@", names_list$usernames, sep=""))
colnames(org_handles) <- "Twitter"
# merge tables and calculate the results for each iteration
org_list <- inner_join(psa_handles, org_handles)
accounts_db_org <- length(org_list$Twitter)
accounts_total_org <- length(usernames$following)
# populate the matrix row by row
psa_result[f] <- c(org_name, accounts_db_org, accounts_total_org)
}
# create a data frame from the matrix and save the result
psa_result <- data.frame(psa_result)
write_csv(psa_result, file = "./outputs/cuentas_seguidas_en_psa.csv")
該subscript out of bounds錯誤是由json包含 0 條記錄的檔案引起的。這是修復洗掉檔案。
uj5u.com熱心網友回復:
你可以用purrr::mapor來做purrr::map_dfr。
這是你要找的嗎?
archivos <- list.files("./raw_data", pattern = "json", full.names = TRUE)
# load master file and select the needed columns. This needs to be out of "calculate_accounts" because you only read it once.
psa_handles <- read_csv(file = "./raw_data/psa_handles.csv") %>%
select(Name, AKA, Twitter)
# calculate accounts
calculate_accounts <- function(archivo){
json_data <- rjson::fromJSON(file = archivo)
org_handles <- json_data %>%
pluck("twitter", "following") %>%
map_chr("username") %>%
as_tibble() %>%
rename(usernames = value) %>%
mutate(Twitter = str_c("@", usernames)) %>%
select(Twitter)
org_list <- inner_join(psa_handles, org_handles)
org_list %>%
mutate(accounts_db_org = length(Twitter),
accounts_total_org = nrow(org_handles)) %>%
select(-Twitter)
}
table_psa <- map_dfr(archivos, calculate_accounts)
#output:
# A tibble: 53 x 4
Name AKA accounts_db_org accounts_total_org
<chr> <chr> <int> <int>
1 Association of American Medical Colleges AAMC 20 2924
2 American College of Cardiology ACC 20 2924
3 American Heart Association AHA 20 2924
4 British Association of Dermatologists BAD 20 2924
5 Canadian Psoriasis Network CPN 20 2924
6 Canadian Skin Patient Alliance CSPA 20 2924
7 European Academy of Dermatology and Venereology EADV 20 2924
8 European Society for Dermatological Research ESDR 20 2924
9 US Department of Health and Human Service HHS 20 2924
10 International Alliance of Dermatology Patients Organisations (Global Skin) IADPO 20 2924
# ... with 43 more rows
uj5u.com熱心網友回復:
不幸的是,álvaro 提供的答案沒有按預期作業,因為輸出重復相同的數字但組織名稱不同,因此很難閱讀。實際上,數字 20 重復了 20 次,數字 11、11 次等等。資訊在那里,但如果沒有進一步的資料處理,就無法訪??問。
與此同時,我正在做自己的研究,我得到了以下代碼。最后我讓它作業了,但是資料格式"matrix" "array"真的很混亂。幸運的是,我寫了最后幾行來轉置資料,取消列出陣列并轉換為矩陣,可以在資料框中轉換并像往常一樣進行操作。
也許我的解釋不是很有用,而且由于我是新手,我確信代碼遠非優雅和優化。無論如何,請查看以下代碼:
library(purrr)
library(rjson)
library(dplyr)
library(tidyverse)
setwd("~/documentos/varios/proyectos/programacion/R/psa_twitter")
# Load data from files.
archivos <- list.files("./raw_data/json_files",
pattern = ".json",
full.names = TRUE)
psa_handles <- read_csv(file = "./raw_data/psa_handles.csv") %>%
select(Name, AKA, Twitter)
nr_archivos <- length(archivos)
calcula_cuentas <- function(a){
# Extract lists
json_data <- fromJSON(file = a)
org_aka <- json_data$id
org_meta <- json_data$metadata
org_name <- org_meta$company
twitter <- json_data$twitter
following <- twitter$following
# create an empty vector to populate
longitud = length(following)
names <- vector(length = longitud)
# loop to populate the empty vector with third element of the sub-list
for(i in 1:longitud){
names[i] <- following[[i]][3]
}
# create a data frame and change column name
names_list <- data.frame(sapply(names, c))
colnames(names_list) <- "usernames"
# Create a data frame with the correct formatting ready to comparison
org_handles <- data.frame(paste("@",
names_list$usernames,
sep="")
)
colnames(org_handles) <- "Twitter"
# merge tables
org_list <- inner_join(psa_handles, org_handles)
cuentas_db_org <- length(org_list$Twitter)
cuentas_total_org <- length(twitter$following)
results <- data.frame(Name = org_name,
AKA = org_aka,
Cuentas_db = cuentas_db_org,
Total = cuentas_total_org)
results
}
# apply function to list of files and unlist the result
psa <- sapply(archivos, calcula_cuentas)
psa1 <- t(as.data.frame(psa))
psa2 <- matrix(unlist(psa1), ncol = 4) %>%
as.data.frame()
colnames(psa2) <- c("Name", "AKA", "tw_int_outbound", "tw_ext_outbound")
# Save the results.
saveRDS(psa2, file = "rda/psa.RDS")
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/420725.html
標籤: