我有兩個這樣的df:
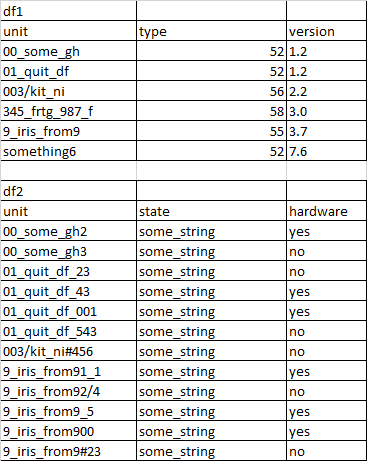
我需要這樣的最終輸出:
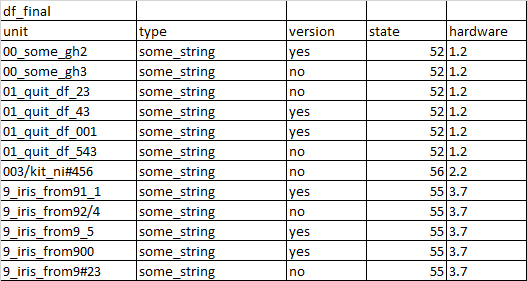
從 df1 中搜索“unit”列并獲取值(型別和版本),如果 df2 中的“unit”資料包含 df1 中的“unit”資料,則合并兩個 dfs。
我嘗試了幾個代碼,例如:
df['join'] = 1 df2['join'] = 1
dataFrameFull = df.merge(df_sql, on='join').drop('join', axis=1)
df1.drop('加入', 軸=1, 就地=真)
dataFrameFull['match'] = dataFrameFull.apply( lambda x: x.unit.find(x.unit), axis=1).ge(0)
但不起作用。
我也試過:
變數 = lambda x: process.extractOne(x, df["unit"]) 2
df2['type'] = df2.loc[df["unit"].map(best_city).values, 'type'].values
結果相同。
uj5u.com熱心網友回復:
我不太明白你的要求(我沒有足夠的聲譽來評論),但如果你想將 df1 與 df2 合并,你可以這樣做:
df_merged = df1.merge(df2, how='outer', on='unit')
“如何”是您想要加入的方式:“外部”、“內部”等。
uj5u.com熱心網友回復:
您可以像這樣在 python 中連接兩個資料幀。
concatenated = pd.concat([df1, df2])
uj5u.com熱心網友回復:
我認為這應該做你想要的。
只是為了測驗,我用你的一些資料制作了一些資料框。
df_1 = pd.DataFrame({"unit" :["00_some_gh", "01_quit_df", "003/kit_ni"], "type": [52,52,56], "version" : [1.2,1.2, 2.2]})
df_2 = pd.DataFrame({"unit" :["00_some_gh2", "00_some_gh3", "01_quit_df23", "01_quit_df43", "01_quit_df001", "003/kit_ni456"], "state": ["some_string","some_string","some_string","some_string","some_string","some_string"], "hardware" : ["yes", "no","yes", "no","yes", "no",]})
遍歷第一個 df 行并找到第二個以相同字串開頭的行。分配型別和版本值。
for index, row in df_1.iterrows():
df_2.loc[df_2['unit'].str.startswith(row['unit']), 'type'] = row['type']
df_2.loc[df_2['unit'].str.startswith(row['unit']), 'version'] = row['version']
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/420963.html
標籤: