我有一個熊貓資料框,它包含兩個 id 列的組合,例如:
| ID1 | ID2 |
|---|---|
| 一個 | 乙 |
| 一個 | C |
| 一個 | D |
| 一個 | 乙 |
| 乙 | C |
| 乙 | D |
| 乙 | 乙 |
| C | D |
| C | 乙 |
| D | 乙 |
| F | H |
| 一世 | ? |
| ? | ? |
| G | F |
| G | H |
| 一世 | ? |
在這里,我們為 ABCD、FGH、IJK 選擇了 2 種組合。
我只想保留特定集合中 ID1 最多的值的行。對于 ABCD,這將是 A,對于 FGH,這將是 G,對于 IJK,這將是 I。結果如下:
| ID1 | ID2 |
|---|---|
| 一個 | 乙 |
| 一個 | C |
| 一個 | D |
| 一個 | 乙 |
| 一世 | ? |
| G | F |
| G | H |
| 一世 | ? |
uj5u.com熱心網友回復:
假設您事先不知道這些組,則可以使用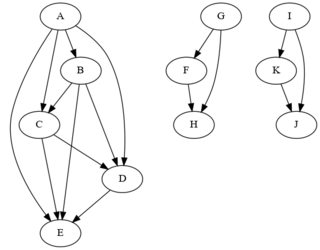
您需要的是找到每個集群的根(有關查找根的方法,請參見此處)。
import networkx as nx
G = nx.from_pandas_edgelist(df, source='ID1', target='ID2',
create_using=nx.DiGraph)
roots = [n for n,d in G.in_degree() if d==0]
df2 = df[df['ID1'].isin(roots)]
輸出:
ID1 ID2
0 A B
1 A C
2 A D
3 A E
11 I K
13 G F
14 G H
15 I J
uj5u.com熱心網友回復:
計算中的 unqiue 值的計數ID1,然后在每個集合的串列推導中計算最大值的索引,最后使用這些索引過濾資料框中的行
c = df['ID1'].value_counts()
i = [c.reindex([*s]).idxmax() for s in ['ABCB', 'FGH', 'IJK']]
df[df['ID1'].isin(i)]
ID1 ID2
0 A B
1 A C
2 A D
3 A E
11 I K
13 G F
14 G H
15 I J
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/424770.html
上一篇:比較兩個字串的相似度