1 引言
網上很多文章會把集群和主從復制混為一談,其實這兩者是存在本質差異的,各自解決的問題不同,Redis在單機/單節點/單實體存在的風險:單點故障、容量有限、并發壓力問題,Redis主從復制配合Sentinel故障監控和轉移主要解決的是單點故障和并發壓力,并沒有解決服務器記憶體有限問題,
注意:記憶體不是單純的砸錢的問題,當服務器記憶體過大后對持久化和主從切換都是比較費時間的,所以,通常Redis服務器記憶體不會設定的太大,通過Redis集群擴容收容來解決記憶體有限問題,
本文主要針對Redis服務器容量有限問題進行集群模型推導,并通過主流代理和官方Redis Cluster實作Redis集群,
2 集群模型推導
2.1 AKF服務拆分
X抽拆分
當我們業務的訪問上升后,單臺Redis承載不了訪問壓力時,通常會進行橫向擴容即如下圖所示,通過橫向的全量、鏡像部署多個副本節點分擔讀請求,實作讀寫分離/主備,從而提高Redis的訪問性能,
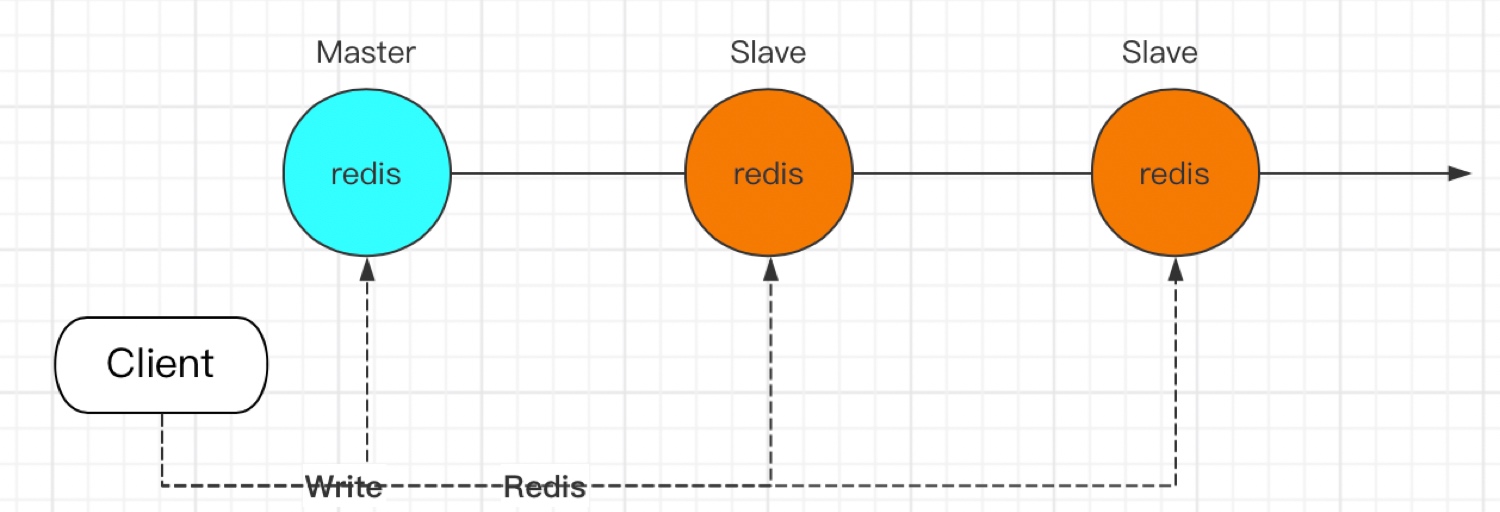
Y軸拆分
通過X軸橫向拆分解決了并發讀的問題,如果某些功能被頻繁訪問,涉及到的資料頻繁讀寫,這是可以將這部分獨立出來,按不同的業務將資料拆分,如下圖
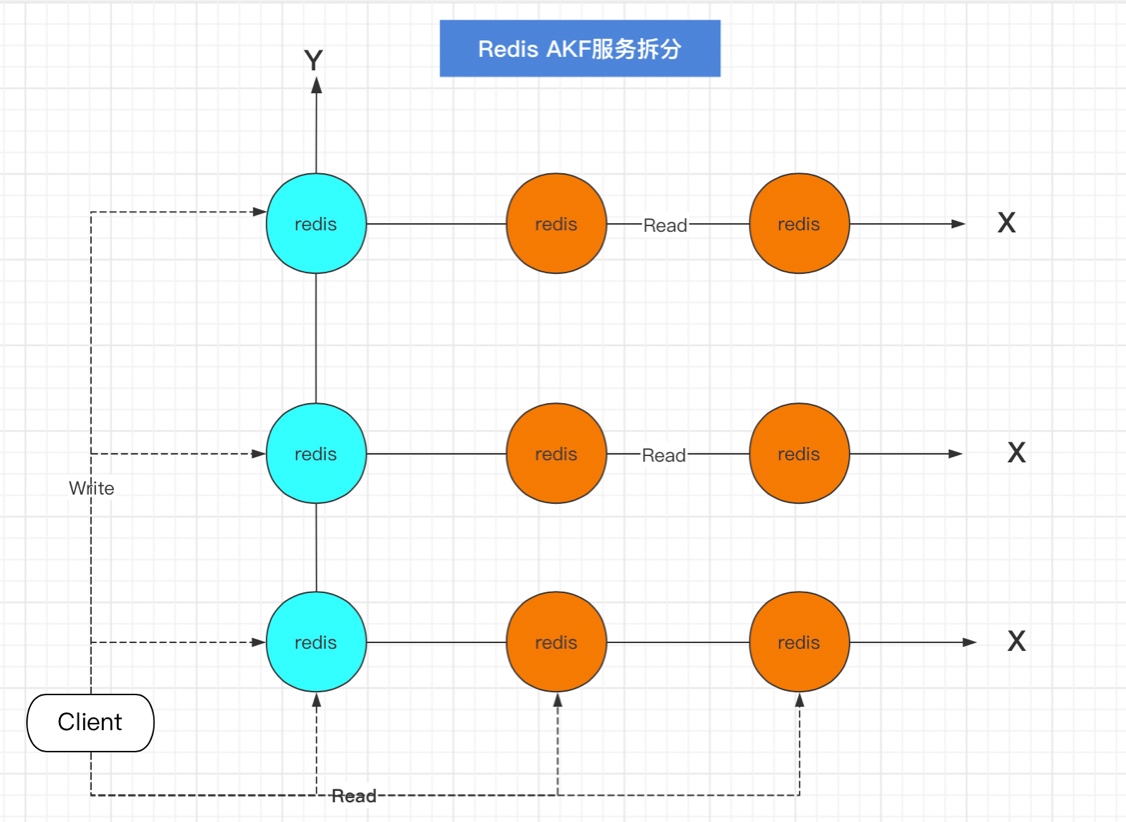
Z軸拆分
在上面的AFK原則X-Y拆分之后,對服務器做了主從主備復制,然后做了業務拆分,不同的Redis負責不同的業務請求,這時候隨著業務的發展,可能會存在某些業務訪問量要明顯高于其他業務,例如對于Y軸上一個Redis,它負責某一樣業務,但是這個業務的資料訪問巨大,那就只好對資料請求進行AFK的Z軸拆分,先分析下資料請求的情況,然后根據訪問來源,分為北京的、上海的這樣不同的Redis雖然是負責不同的資料,但是負責的業務是一樣的,AFK拆分圖示:
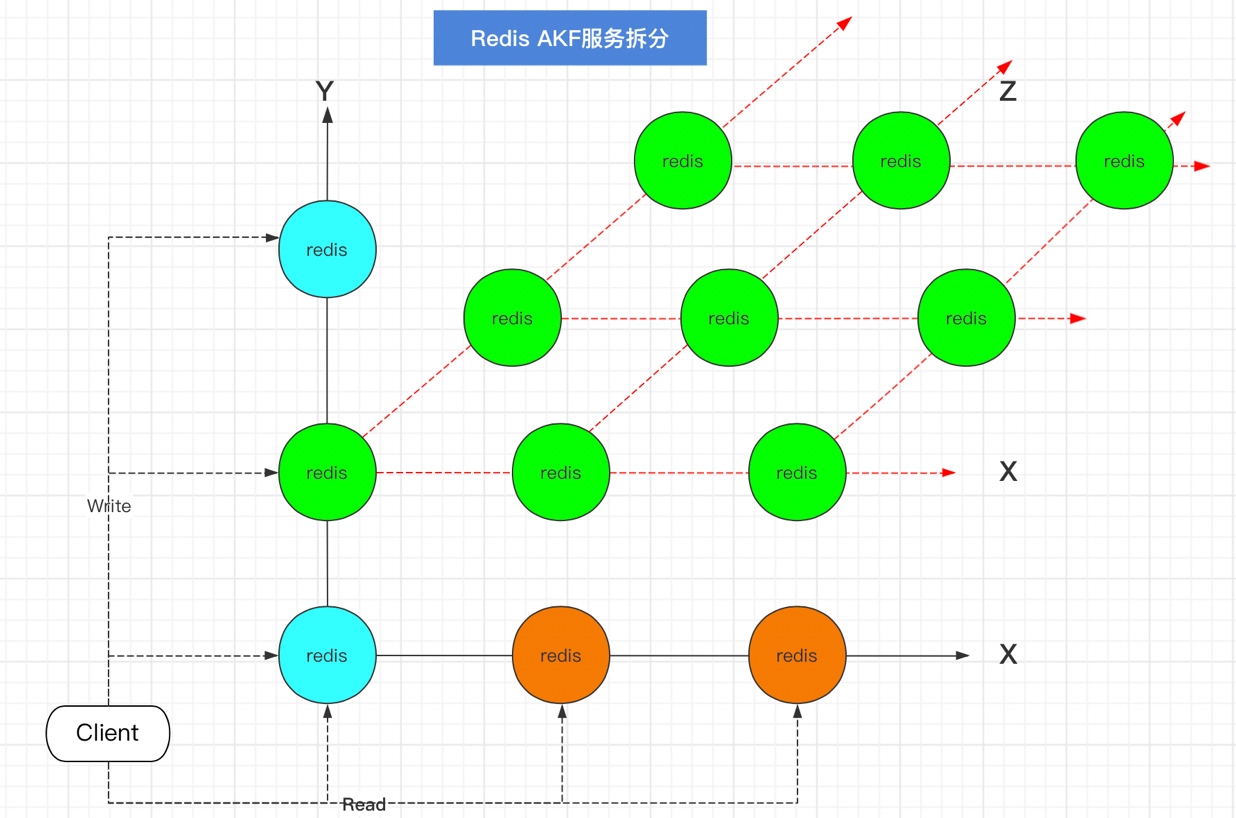
AFK總結
X軸拆分:水平復制,就是單體系統多運行幾個實體,做集群加負載均衡的模式,主主、主備、主從,
Y軸拆分:基于不同的業務拆分,
Z軸拆分:基于資料拆分,
沒有最好的架構,只有更適合的架構,不要為了技術而技術!
2.2 集群資料存取
2.2.1 資料分類存取
資料分類存盤即將資料按邏輯業務拆分存盤到不同的Redis服務器中,適用于業務之間資料交集不多,具體圖示如下:
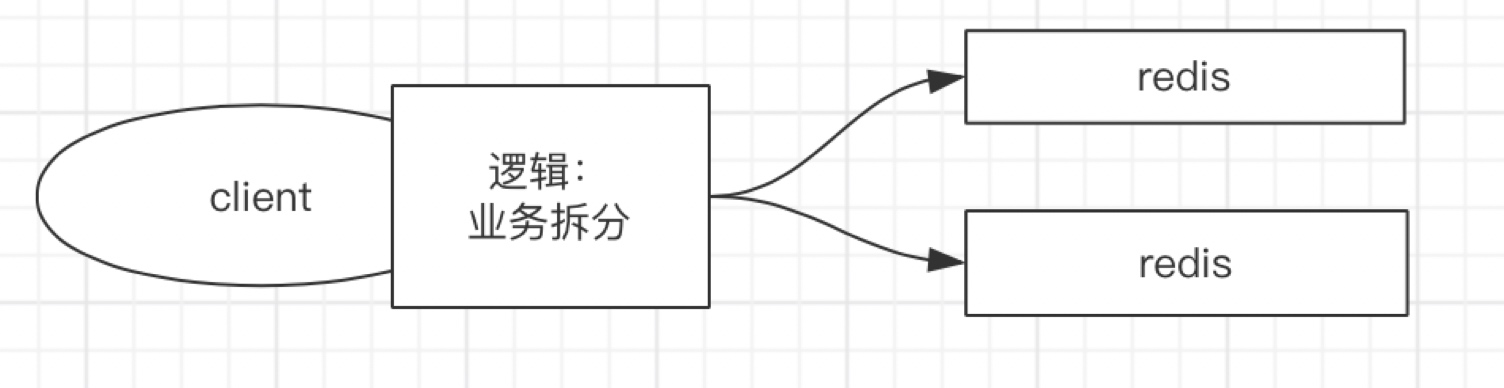
分類儲存前提是資料可以進行拆分,如果資料不能拆分這種模式就不適用了,
2.2.2 Sharding分片存取
當資料不能按業務拆分,可以使用分片存盤,如果將某條資料存盤到Redis后,查詢的時候希望可以直接去這臺資料庫查詢,通常可以把資料的固定值通過一定的演算法進行計算后再存盤,當取的時候同樣通過該值計算后再去查指定的Redis,常用的方式如下:
- Modula(Hash+取模)
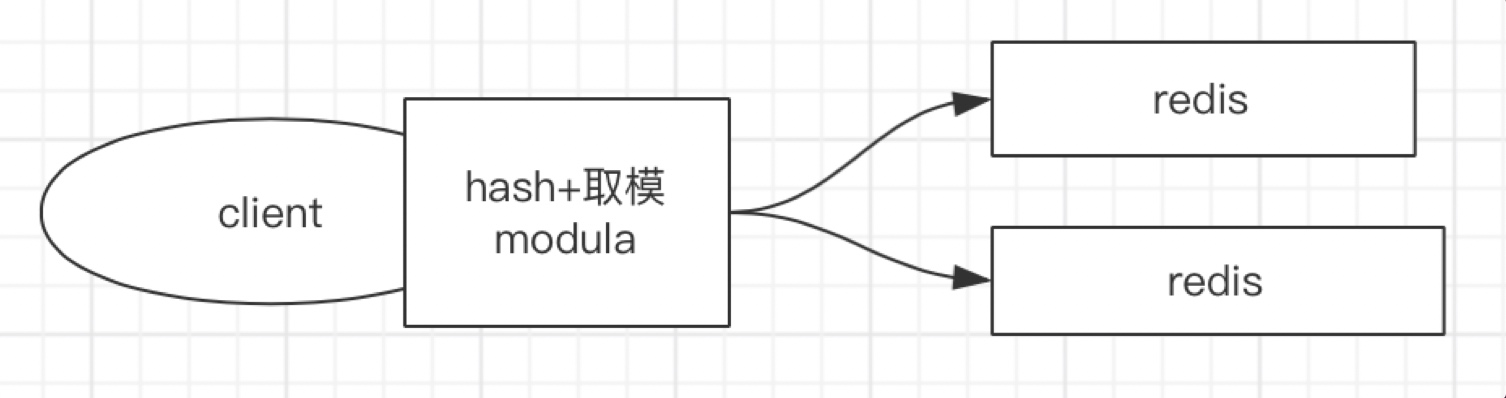
缺點:取模的數須固定,即服務器臺數需固定,否則會存在資料查不到的情況,比如,原有2臺服務器,用戶A的id通過Hash計算后與2取模,結算結果存在node1中,當服務器擴展到3臺后,用戶A的id通過Hash計算后需要與3取模,計算結果可能就不在node1上了,所以,這種模式會影響分布式下的擴展性,
2. Random(隨機存盤)
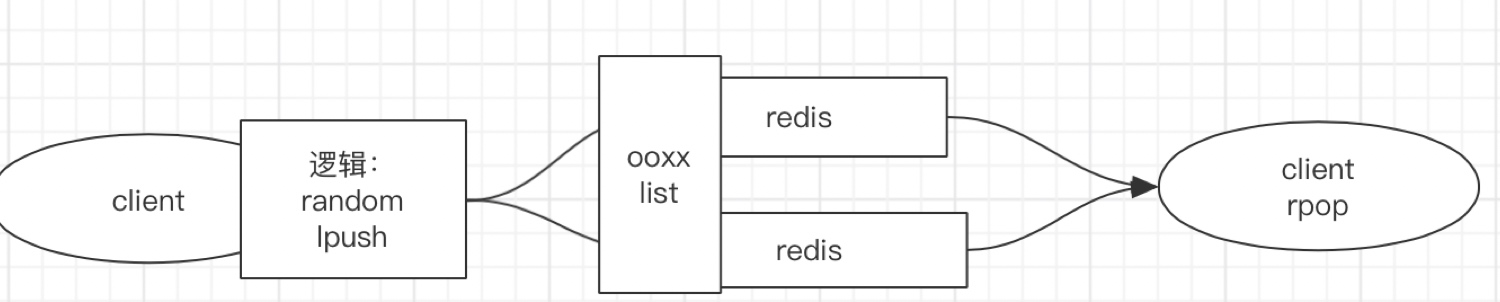
即隨機將資料存盤到某臺Redis中,但是缺點也很明顯,資料隨機存盤后,取資料就不方便了,但是,這種模式有一些特定的場景是可以使用的,比如訊息佇列,
3. Kemata(一致性哈希)
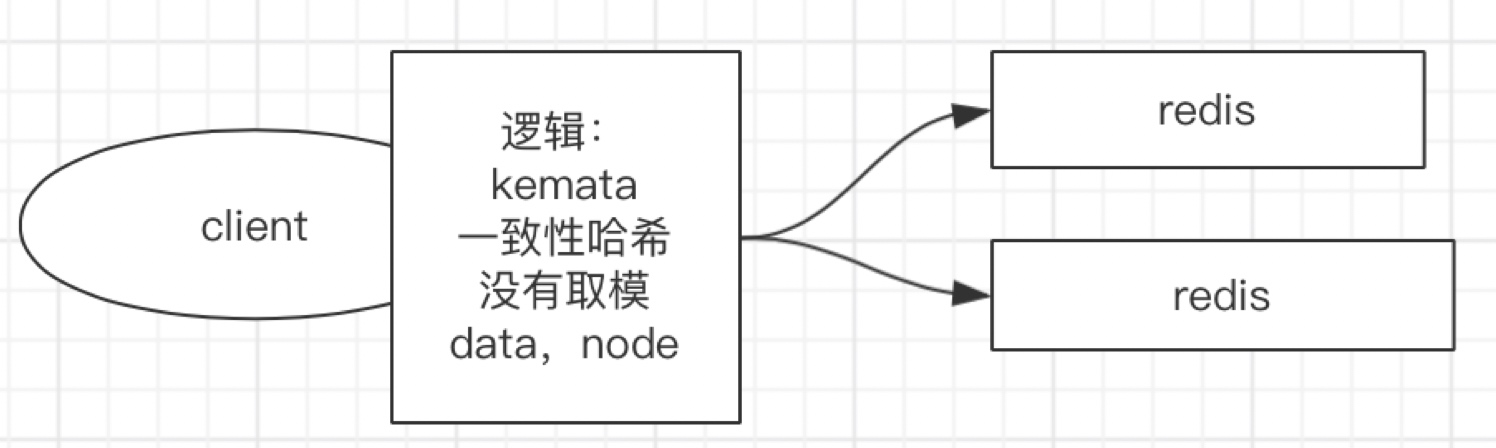
一致性Hash演算法也是使用取模的方法,只是,剛才描述的取模法是對服務器的數量進行取模,而一致性Hash演算法是對2^ 32-1取模,
第一步:將服務器的固定值(IP或主機名,建議主機名)Hash計算后對2^ 32-1取模,得到0到2^ 32的值,對應到Hash環上,如下圖:
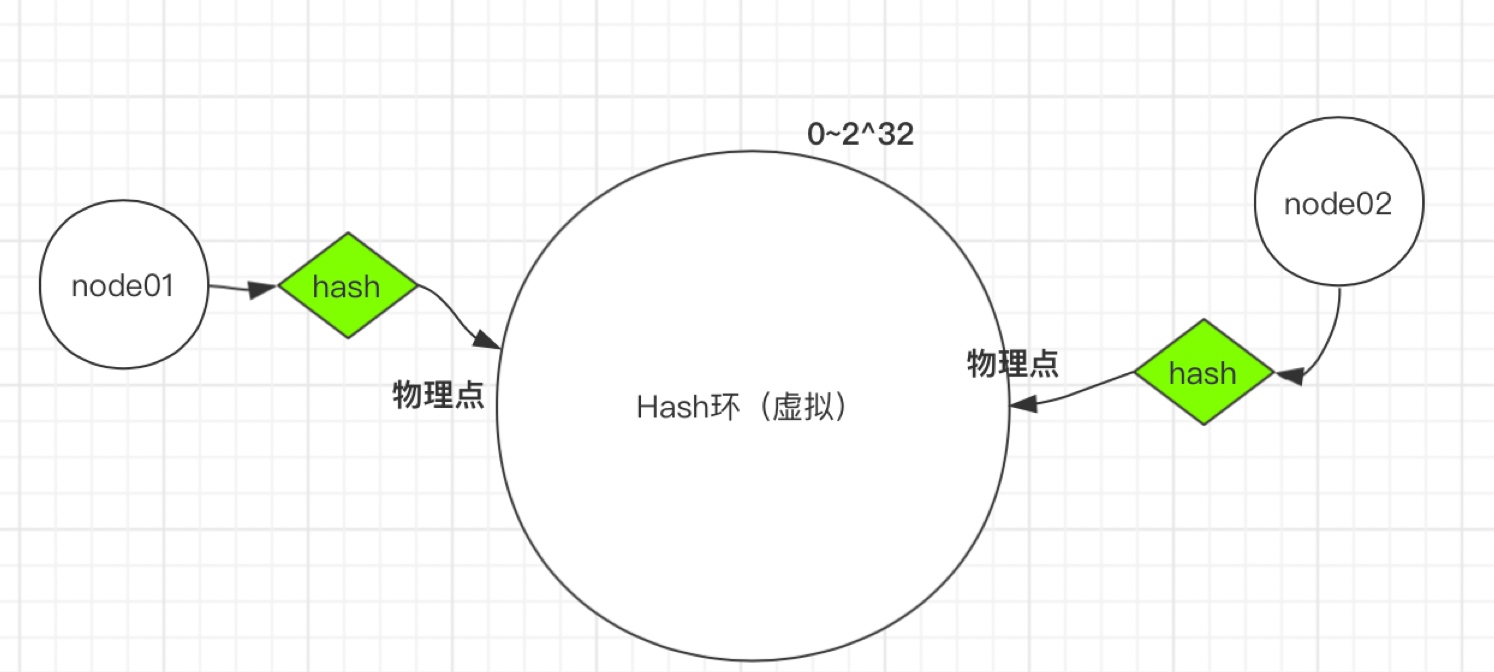
第二步:將需要存盤的資料,按第一步相同的Hash計算,同樣對2^ 32-1取模,得到0到2^ 32的值同樣對應到虛擬Hash環上,將資料從所在位置順時針找第一臺遇到的服務器節點,這個節點就是該key存盤的服務器,
例如我們有k1、k2兩個key,經過哈希計算后,在環空間上的位置如下:k1存盤在node1,k2存盤在node2,
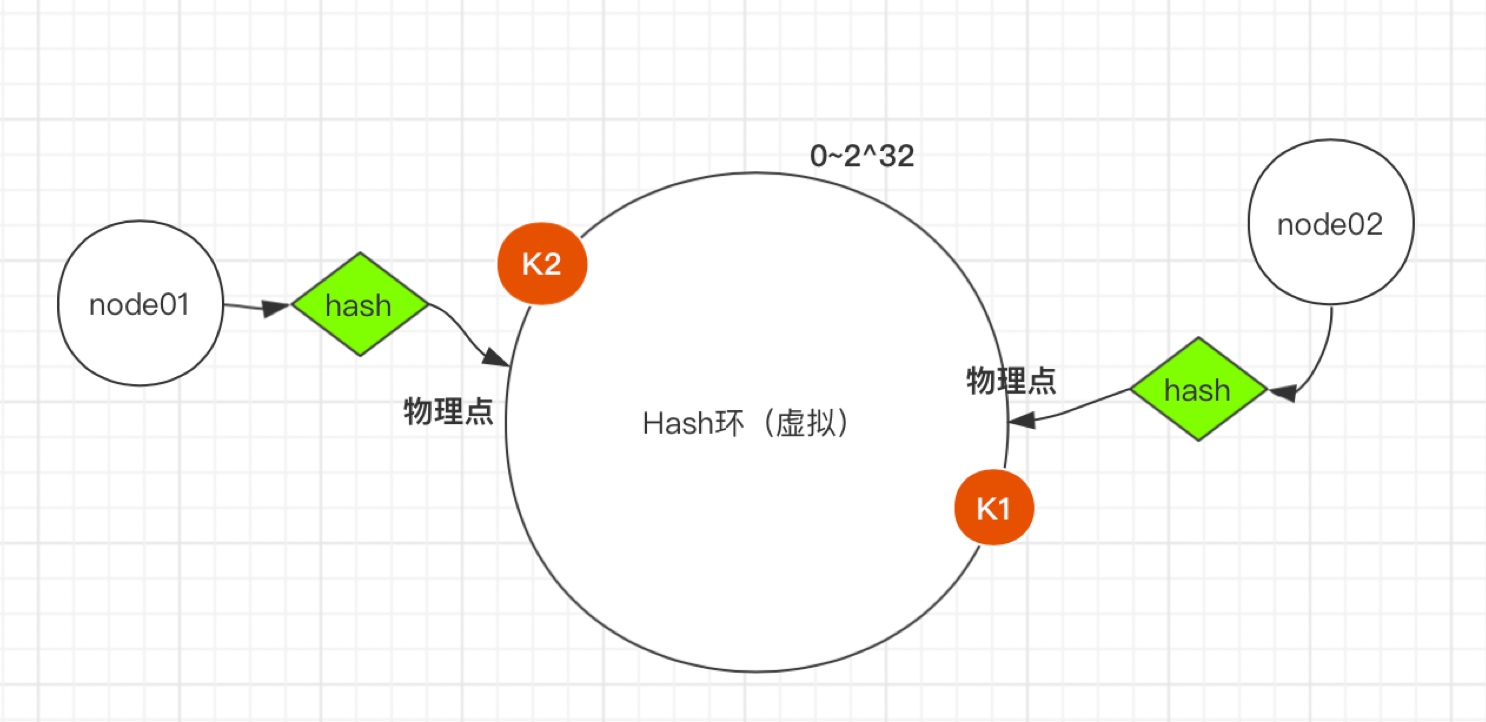
一致性hash演算法主要應用于分布式存盤系統中,可以有效地解決分布式存盤結構下普通余數Hash演算法帶來的伸縮性差的問題,可以保證在動態增加和洗掉節點的情況下盡量有多的請求命中原來的機器節點,
-
優點:對于節點的增減都只需重定位環空間中的一小部分資料,具有較好的容錯性和可擴展性,
-
缺點:一致性Hash演算法在服務節點太少時,容易因為節點分部不均勻而造成資料傾斜問題(被快取的物件大部分集中快取在某一臺服務器上),為了解決資料傾斜問題,一致性Hash演算法引入了虛擬節點機制,即對每一個服務節點計算多個哈希,每個計算結果位置都放置一個此服務節點,稱為虛擬節點,多個虛擬節點可以減少資料的傾斜,
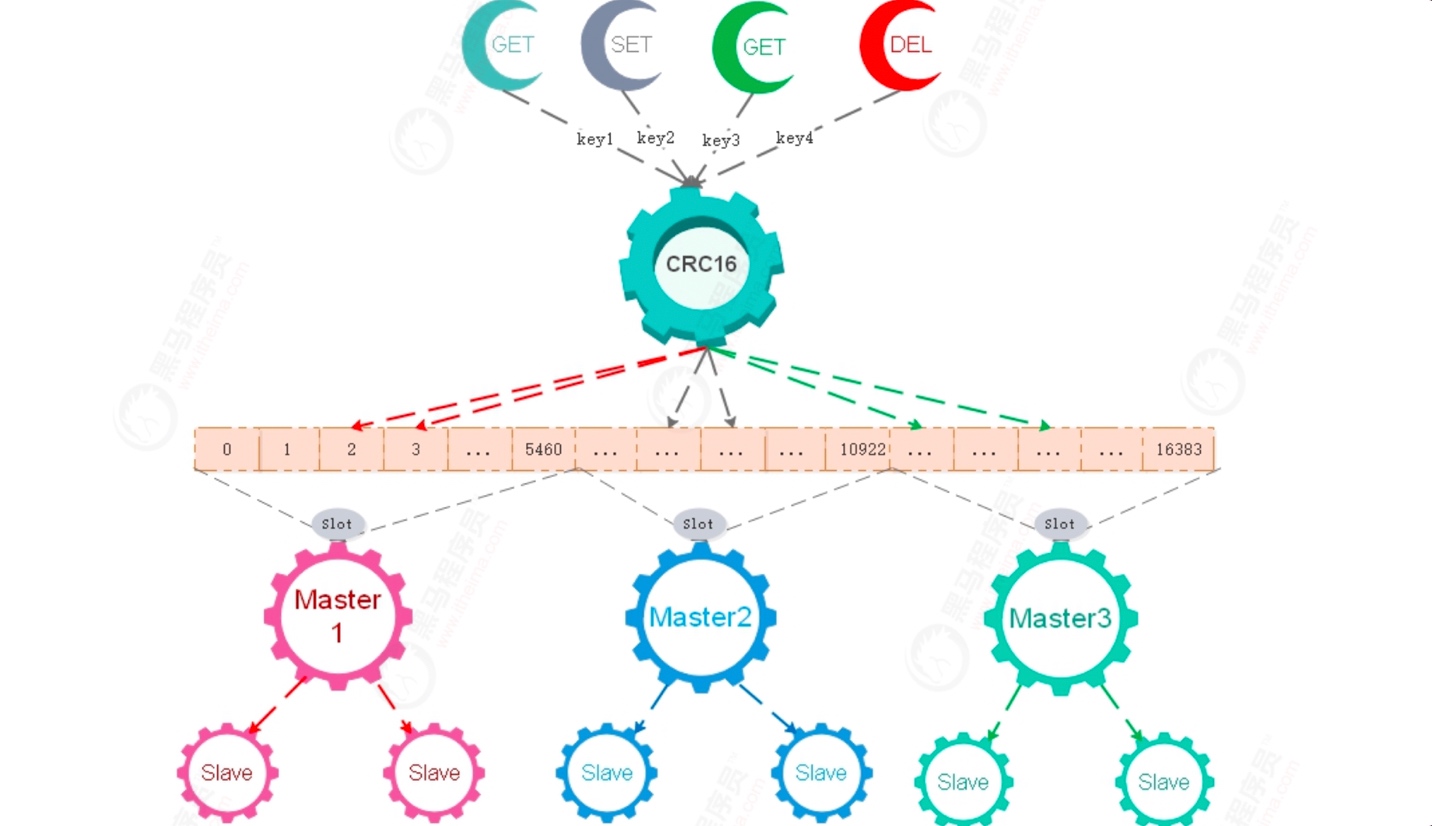
Redis 集群沒有使用一致性hash, 而是在第一種Hash+取模的基礎上引入了哈希槽slots的概念,接下來我們分析下Redis的實作,
- Redis集群的分片存取
- Redis Cluster 特性之一是引入了槽的概念,一個redis集群包含 16384 個哈希槽,
- 集群時,會將16384個哈希槽分別分配給每個Master節點,每個Master節點占16384個哈希槽中的一部分,
- 執行GET/SET/DEL時,都會根據key進行操作,Redis通過CRC16演算法對key進行計算得到該key所屬Redis節點,
- 根據key去指定Redis節點操作資料,
2.3 集群訪問
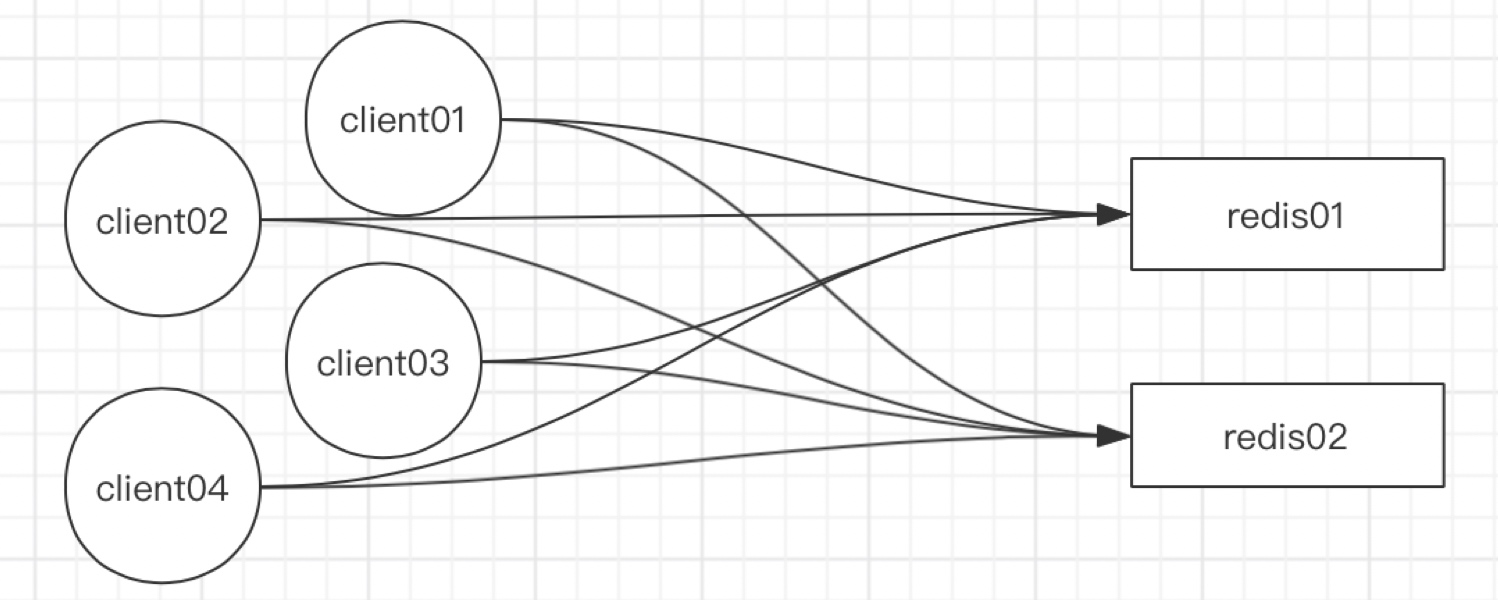
當客戶端連接Redis集群時,如果直接連server端造成的壓力很大,如下圖,4個人客戶端連接2臺Redis,每臺Redis都需要和所有客戶端連接,
因此,我們首先考慮的是同代理減少服務端連接,如下圖
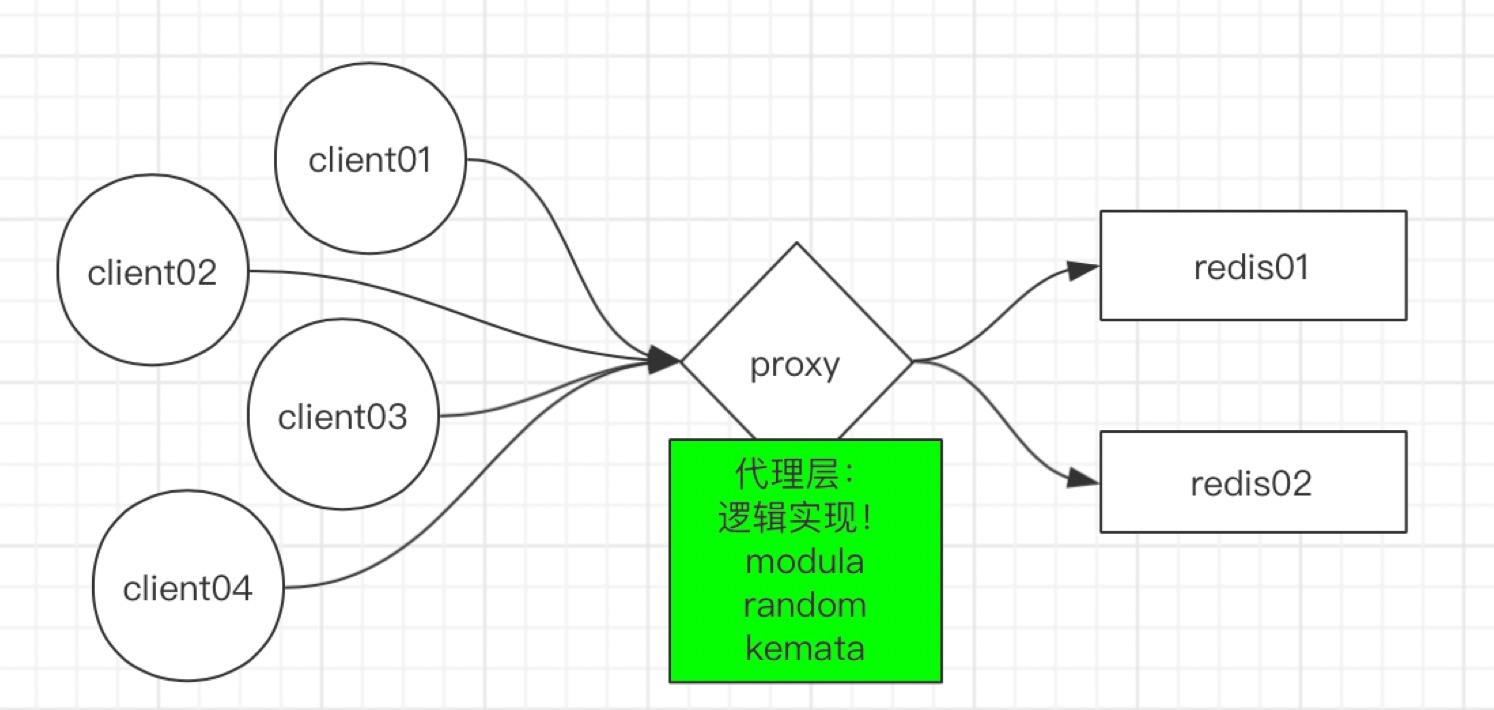
通過代理確實可以解決服務端連接問題,但是proxy服務的單點問題就暴露了,為了解決單點問題,我們把架構調整如下:
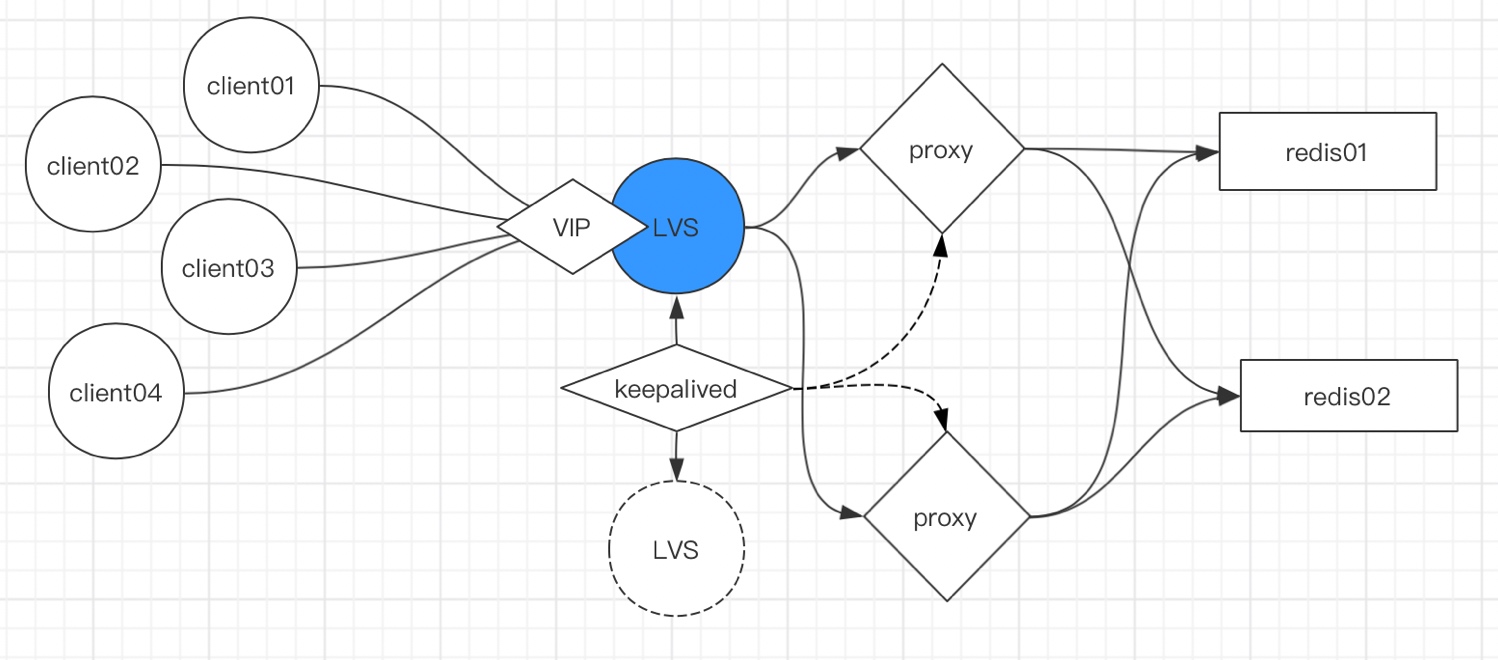
如上圖,通過LVS+KeepAlived實作proxy的高用,從而解決了這一系列問題(具體架構詳解可以參考另一篇文章《LVS+KeepAlived高可用部署架構》),接下來我們講解下Redis集群的具體搭建,proxy和Redis Cluster,
3 Redis集群搭建
無論是為了解決redis的高可用問題、還是為了可擴展性、或者是為了維護方便,用一款redis代理都是上佳的選擇,在github上有眾多開源的redis代理,本章中主要針對Twemproxy、Predixyr進行搭建Redis集群,
3.1 Twemproxy
Twemproxy是Twitter維護的(快取)代理系統,代理Memcached的ASCII協議和Redis協議,它是單執行緒程式,使用c語言撰寫,運行起來非常快,它是采用Apache2.0 license的開源軟體, Twemproxy支持自動磁區,如果其代理的其中一個Redis節點不可用時,會自動將該節點排除(這將改變原來的keys-instances的映射關系,所以你應該僅在把Redis當快取時使用Twemproxy),
Twemproxy本身不存在單點問題,因為你可以啟動多個Twemproxy實體,然后讓你的客戶端去連接任意一個Twemproxy實體,
Twemproxy是Redis客戶端和服務器端的一個中間層,由它來處理磁區功能應該不算復雜,并且應該算比較可靠的,
3.1.1 Twemproxy安裝
官網地址:GItHub
# 下載安裝包
wget https://github.com/twitter/twemproxy/releases/download/0.5.0/twemproxy-0.5.0.tar.gz
tar xf twemproxy-0.5.0.tar.gz
# twemproxy運行需要automake和 libtool
yum install automake libtool -y
cd twemproxy
autoreconf -fvi
./configure
make
# 復制組態檔及加入系統命令
cp scripts/nutcracker.init /etc/init.d/twemproxy
chmod +x /etc/init.d/twemproxy
mkdir /etc/nutcracker
cp conf/* /etc/nutcracker/
cp src/nutcracker /usr/bin/
cd /etc/nutcracker/
# 修改組態檔
cp nutcracker.yml nutcracker.yml.bak
修改后配置,按需修改,這里使用的是本機2臺Redis測驗
alpha:
listen: 127.0.0.1:22121
hash: fnv1a_64
distribution: ketama
auto_eject_hosts: true
redis: true
server_retry_timeout: 2000
server_failure_limit: 1
servers:
- 127.0.0.1:6379:1
- 127.0.0.1:6380:1
3.1.2 手動啟動2個Redis實體
創建2個Redis目錄 6379 6380 分別進入2個目錄執行啟動命令

啟動Redis
# 進入6379檔案夾
redis-server --port 6379
# 進入6380檔案夾
redis-server --port 6380
查看

啟動twemproxy
server twemproxy start
3.1.3 驗證
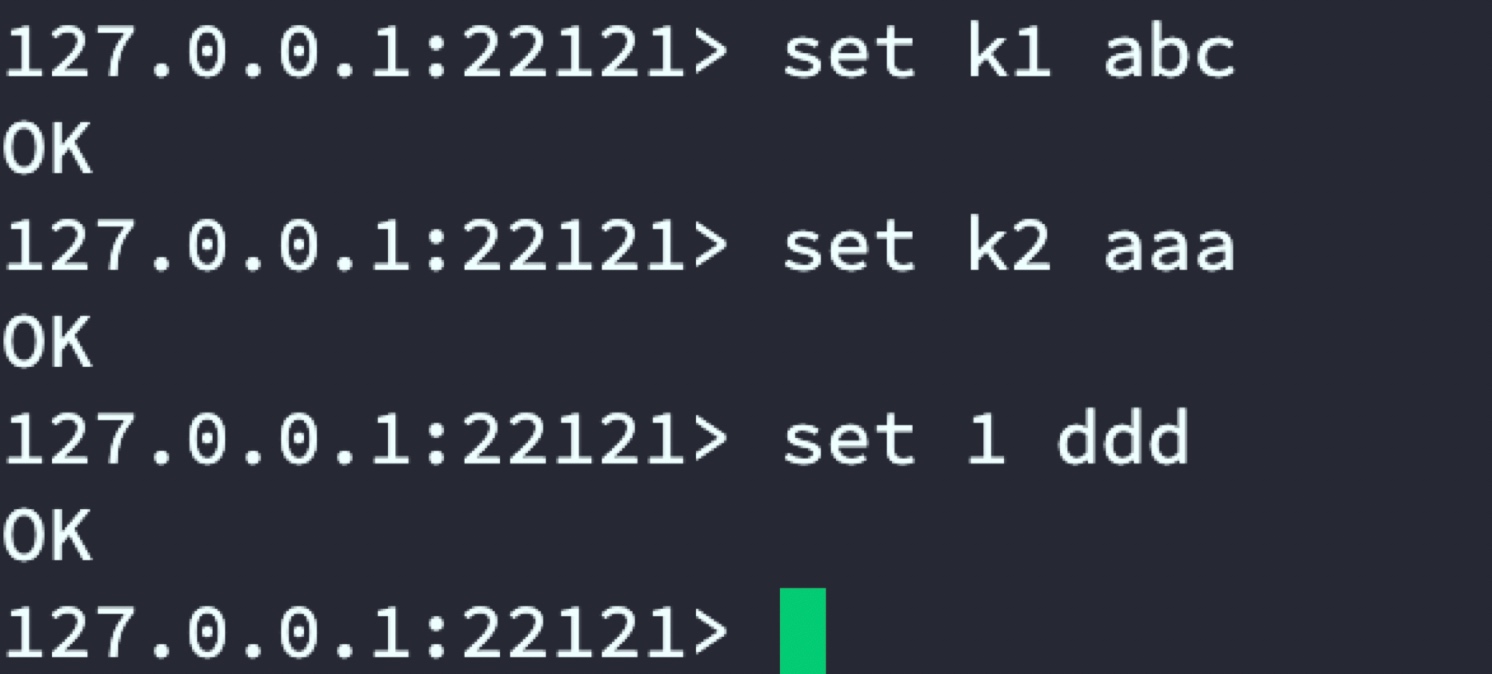
連接twemproxy代理的Redis,注意此處埠使用twemproxy埠號
redis-cli -p 22121

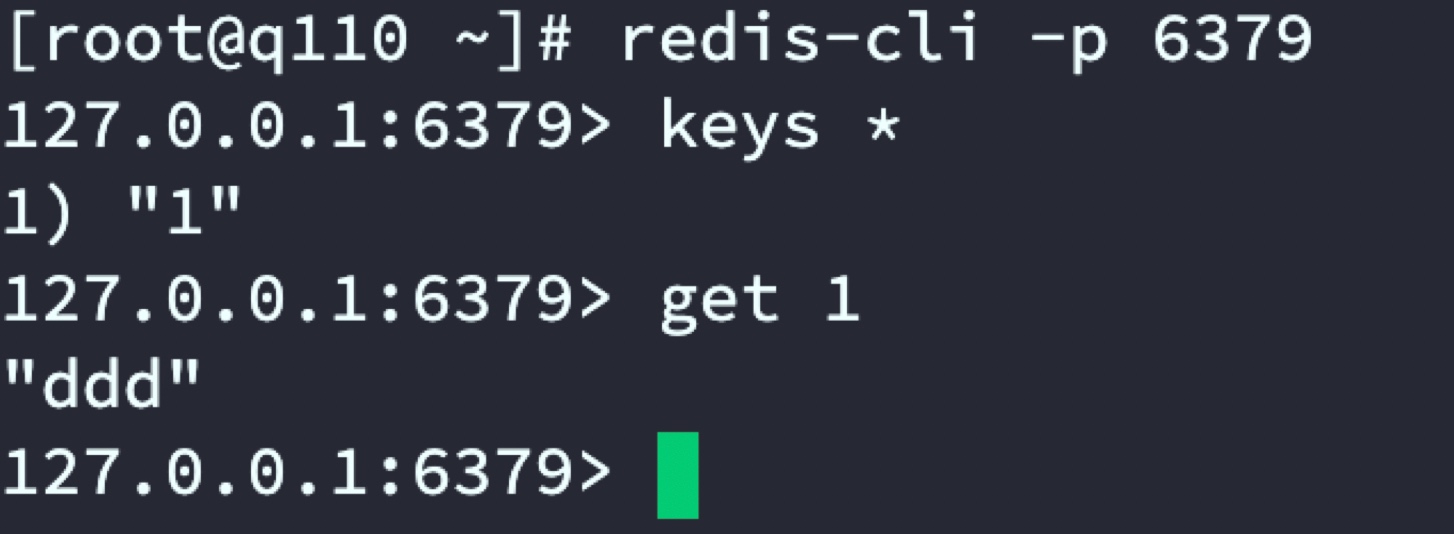
通過在22121埠中set資料,最侄訓按設定的規則分布在6379和63802臺Redis服務器,
22121代理:
6379
6380
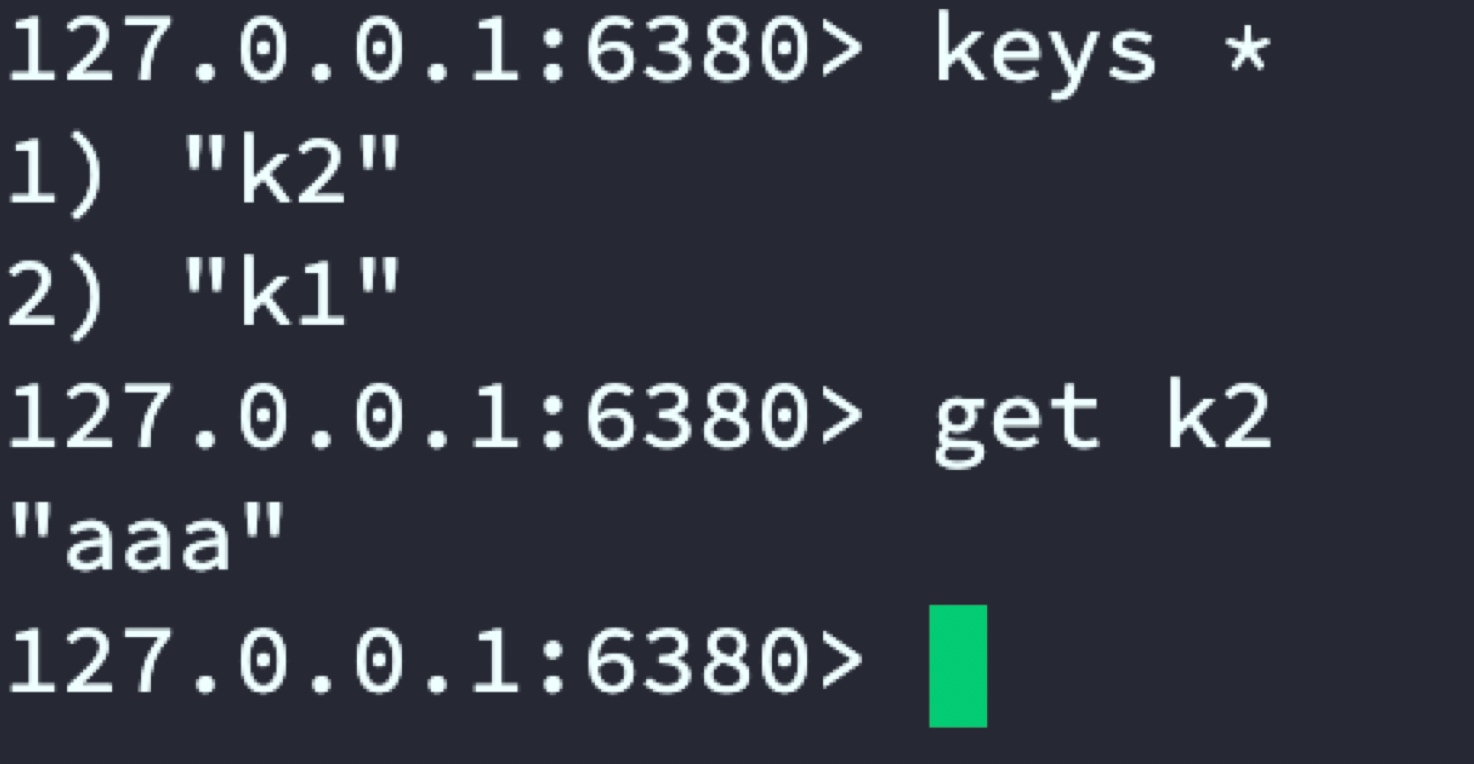
到此已實作通過twemproxy代理2臺Redis服務器進行資料分布儲存,后續用戶存取只用連接代理服務器即可,從而解決單臺Redis記憶體有限問題,
使用twemproxy代理Redis進行資料分治后會存在的問題:代理層不支持查詢全部資料,不支持事務,
3.2 Predixy
Predixy是一款redis代理的開源程式,支持一套master-slave事務,支持redis單機,多機,集群的代理,對于客戶端是感應不到的, 要求是c++11編譯,
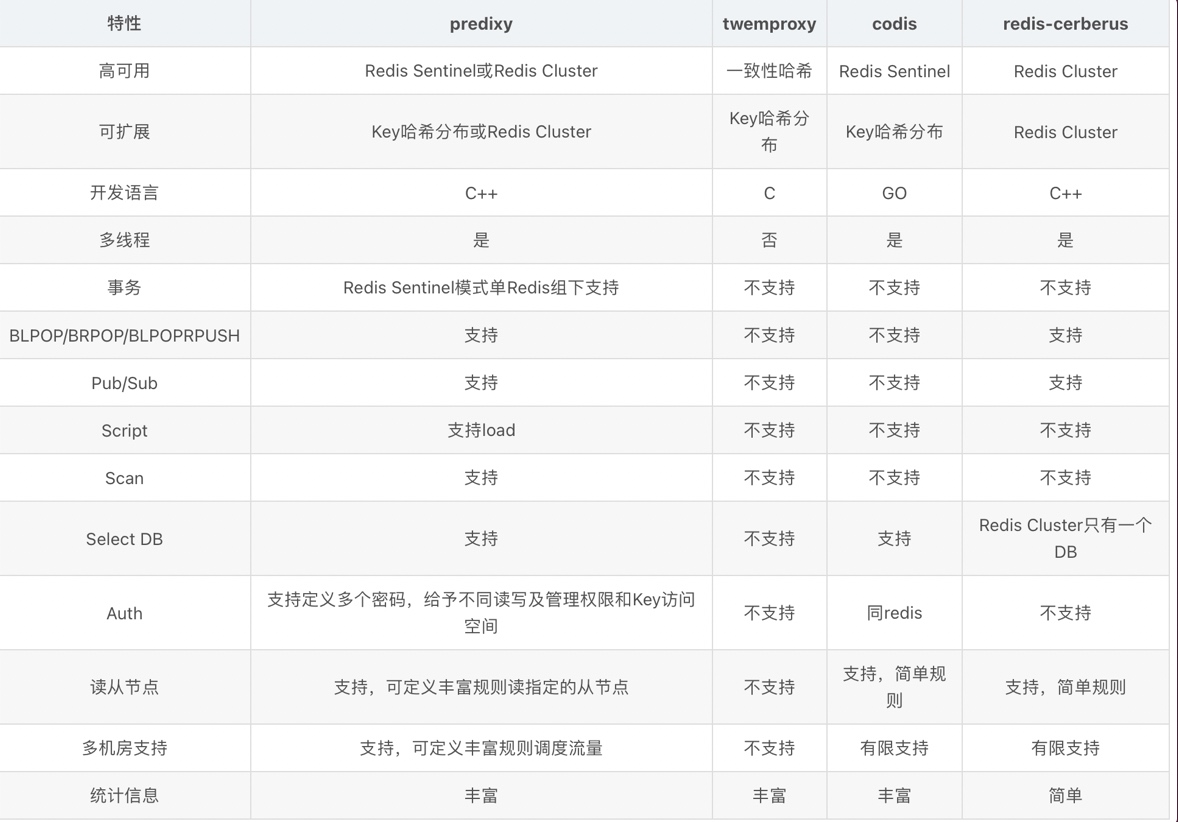
常用Redis代理對比
接下來演示Predixy代理搭建,
3.2.1 安裝
官方下載地址:GItHub
wget https://github.com/joyieldInc/predixy/releases/download/1.0.5/predixy-1.0.5-bin-amd64-linux.tar.gz
tar xf predixy-1.0.5-bin-amd64-linux.tar.gz
3.2.2 配置
修改predixy.conf
vi predixy-1.0.5/conf/predixy.conf
打開系結埠

打開sentinel配置

修改sentinel配置
vi predixy-1.0.5/conf/sentinel.conf
內容如下
SentinelServerPool {
Databases 16
Hash crc16
HashTag "{}"
Distribution modula
MasterReadPriority 60
StaticSlaveReadPriority 50
DynamicSlaveReadPriority 50
RefreshInterval 1
ServerTimeout 1
ServerFailureLimit 10
ServerRetryTimeout 1
KeepAlive 120
# 哨兵IP就埠
Sentinels {
+ 127.0.0.1:8001
+ 127.0.0.1:8002
+ 127.0.0.1:8003
}
# 分組
Group beijin {
}
Group shanghai {
}
}
3.2.3 啟動sentinel集群
集群拓撲圖
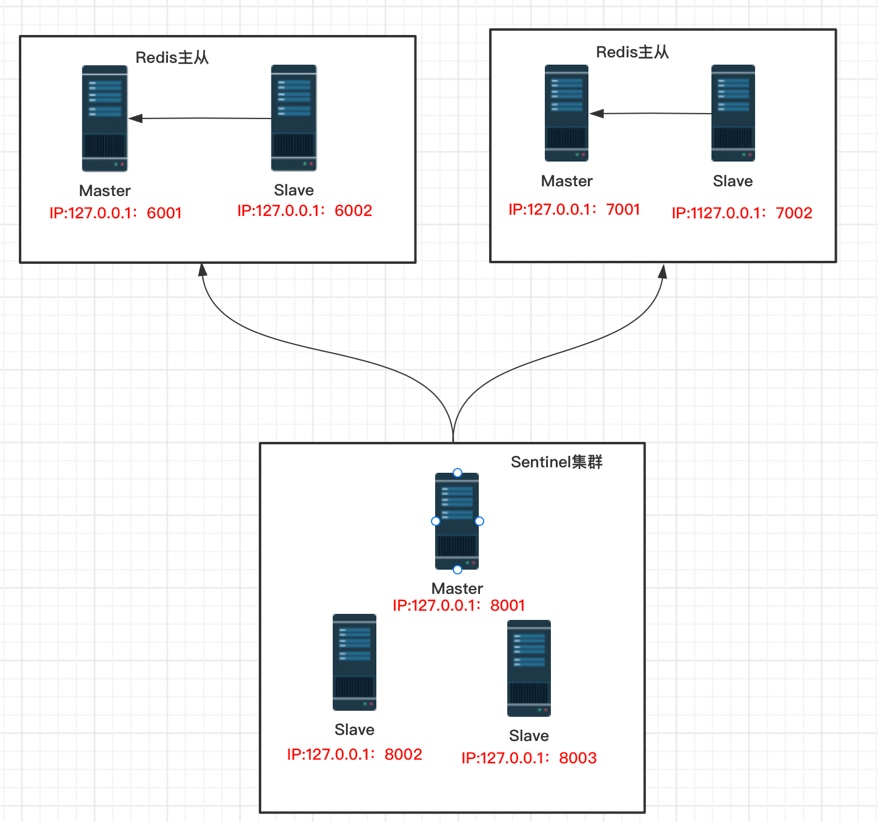
說明:通過sentinel集群埠為:8001、8002、8003 監控2套Redis主從beijin和shanghai,
Redis主從一:beijin Master埠為6001,Slave 6002;
Redis主從一: shanghai Master埠為7001,Slave埠7002;
sentinel配置
beijin和shanghai為Redis主從分組,對應predixy.conf中的Grpoup
8001:
port 8001
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
8002:
port 8002
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
8003:
port 8003
sentinel monitor beijin 127.0.0.1 6001 2
sentinel monitor shanghai 127.0.0.1 7001 2
組態檔串列

啟動3臺sentinel
redis-server 8001.conf --sentinel
redis-server 8002.conf --sentinel
redis-server 8003.conf --sentinel
查看啟動狀態

3.2.4 啟動2套Redis主從
mkdir 6001
mkdir 6002
mkdir 7001
mkdir 7002
分別進入4個檔案夾啟動對應Redis
# 6001檔案夾
redis-server --port 6001
# 6002檔案夾
redis-server --port 6002 --replicaof 127.0.0.1 6001
# 7001檔案夾
redis-server --port 7001
# 7002檔案夾
redis-server --port 7002 --replicaof 127.0.0.1 7001
查看啟動行程

啟動predixy
cd predixy-1.0.5/bin/
./predixy ../conf/predixy.conf
啟動日志
3.2.5 驗證
- 驗證資料存取
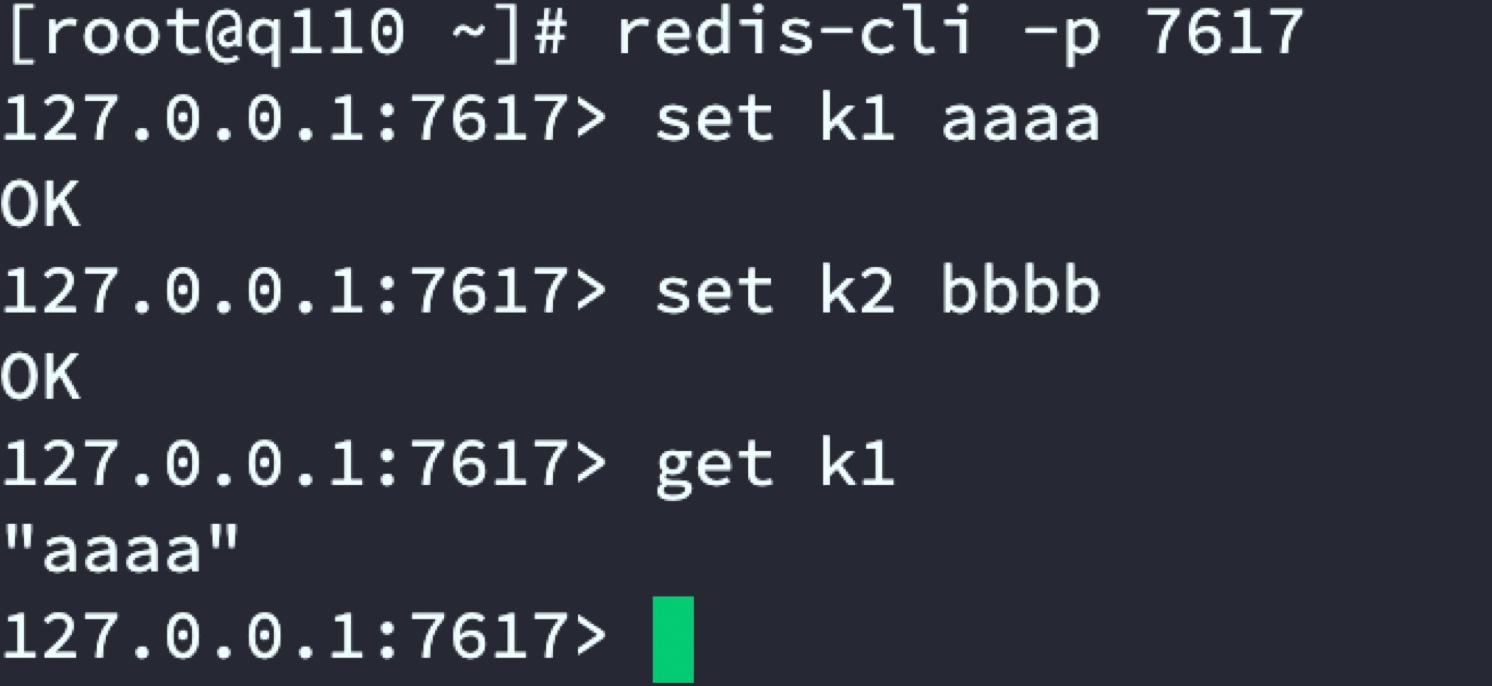
客戶端通過7617埠連接predixy代理,進而操作集群,
redis-cli -p 7617
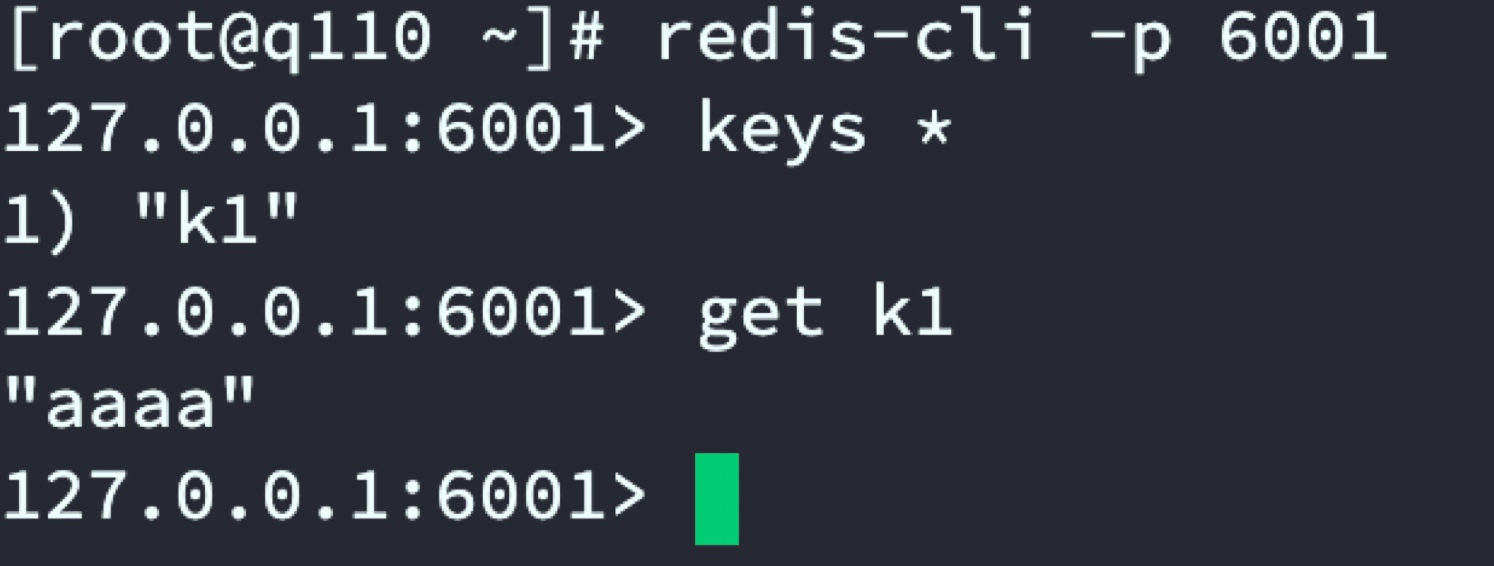
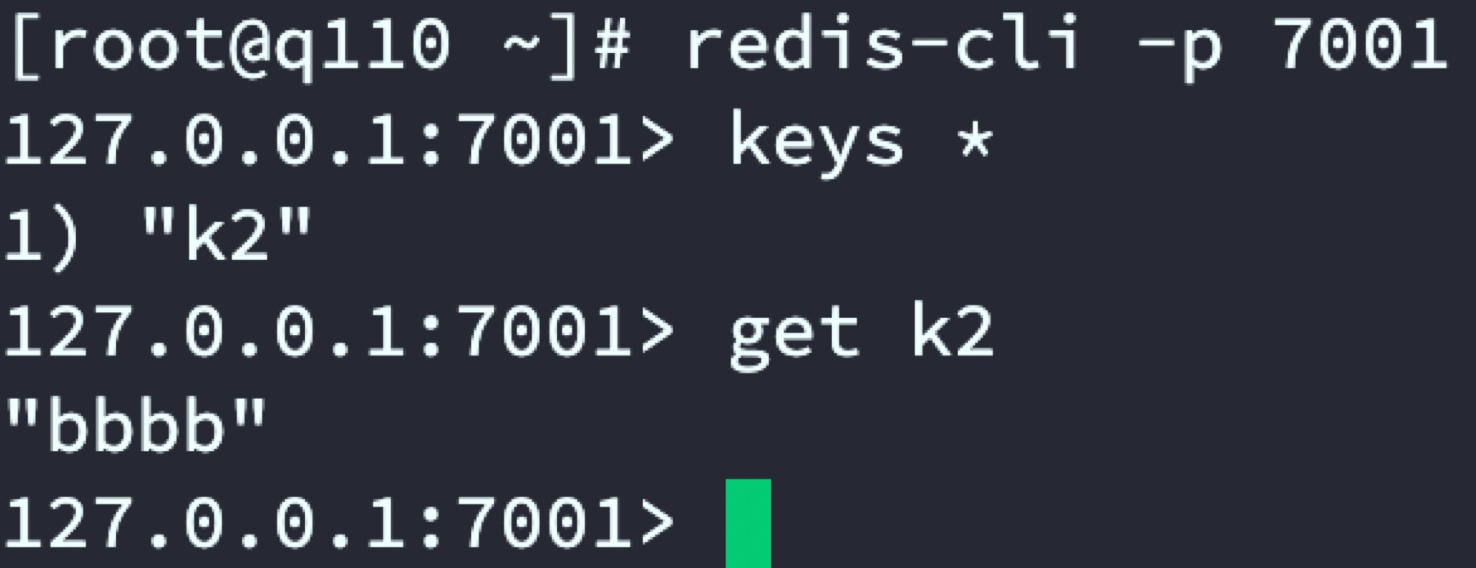
通過代理服務器set k1和k2 資料,分別在2套Redis集群中查看資料分布
代理服務器
Redis主從一:beijin
Redis主從二:shanghai
- 驗證通過代理服務器將資料存盤到指定的Redis集群
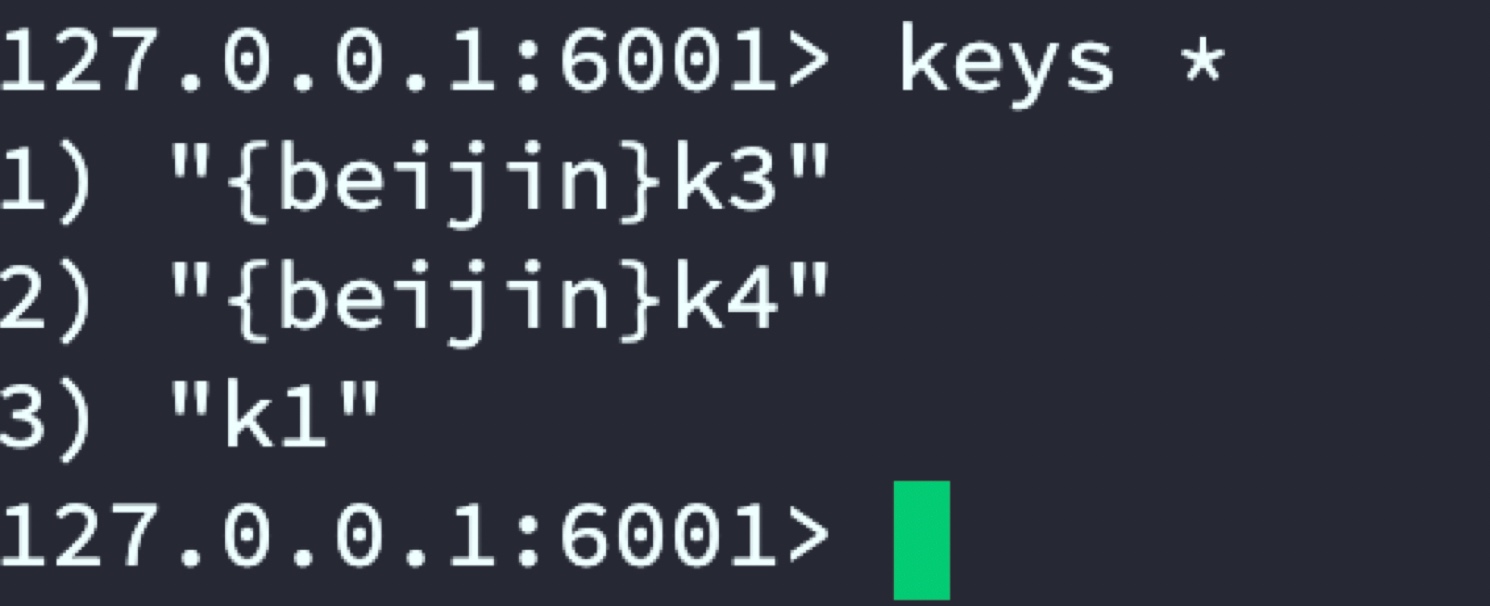
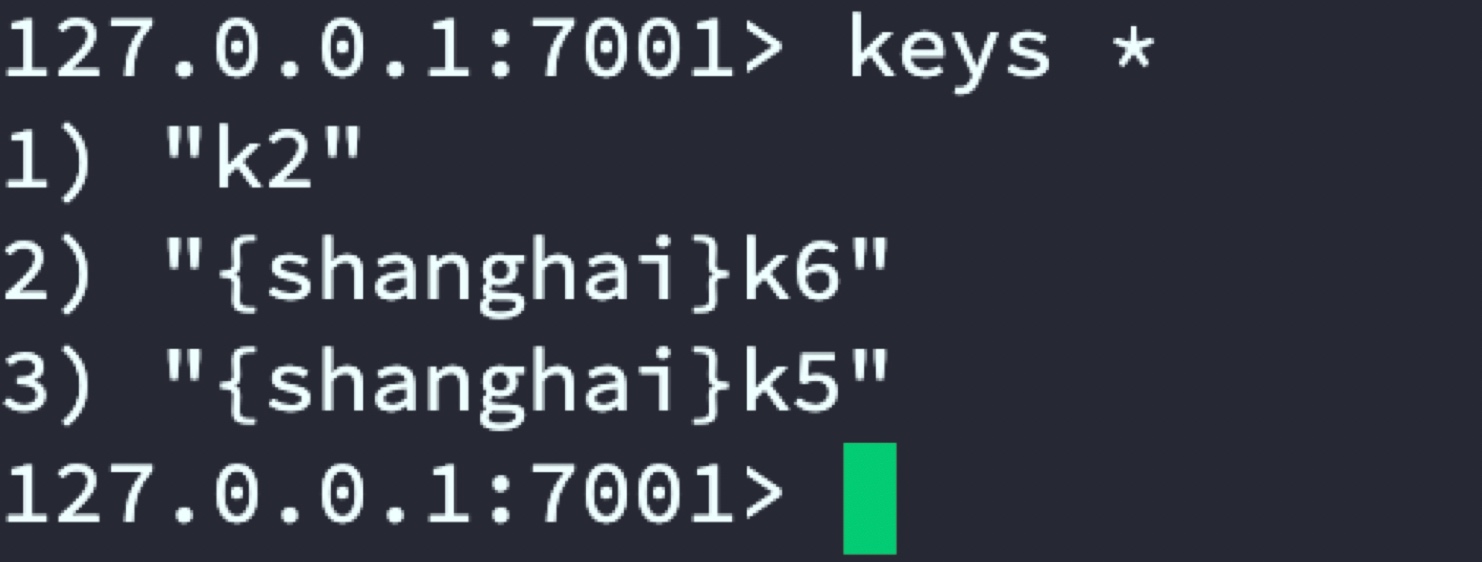
代理服務器指定將k3和k4存盤到代號beijin的Redis主從,將k5和k6存盤到代號shanghai主從中
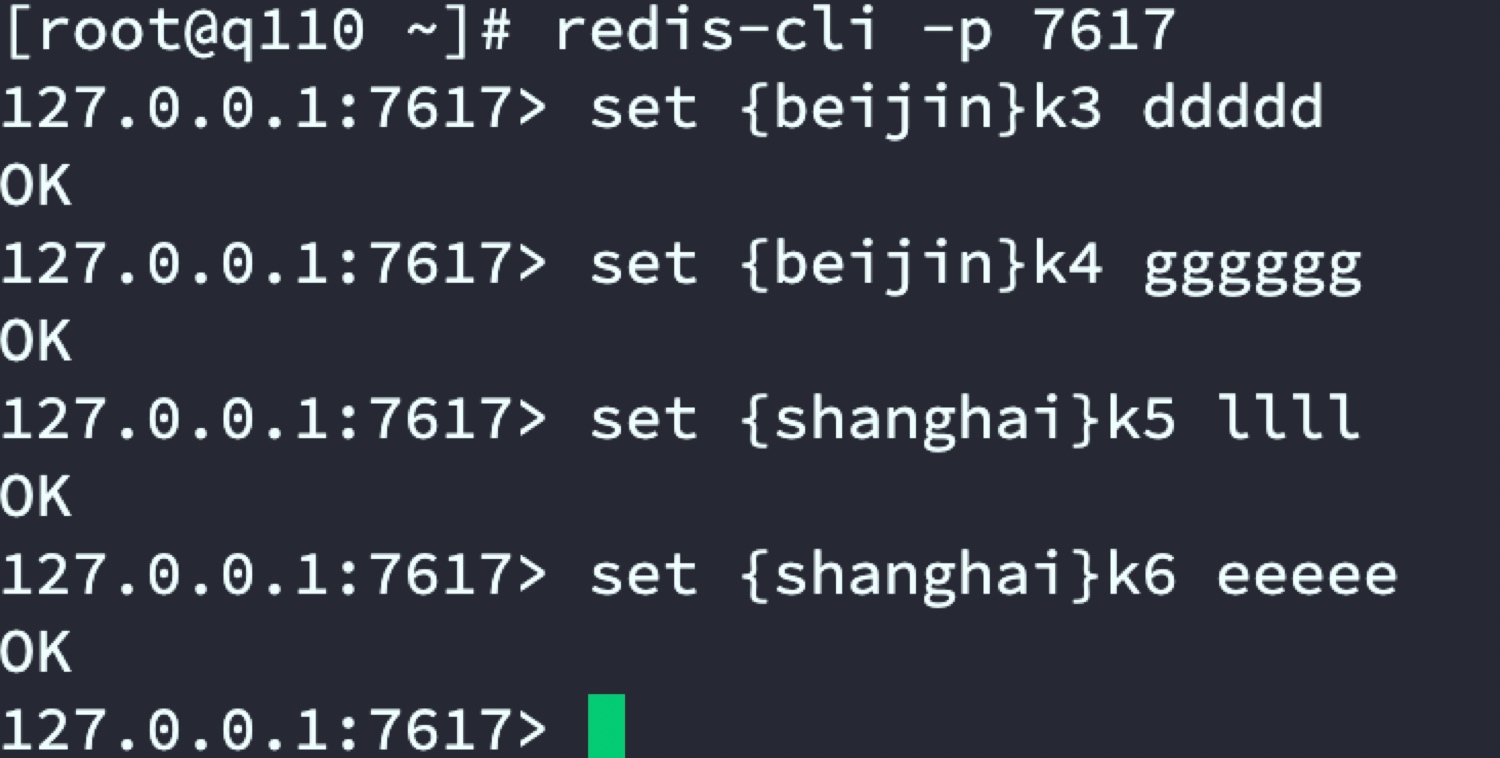
beijin主從
shanghai主從
- 驗證集群事務

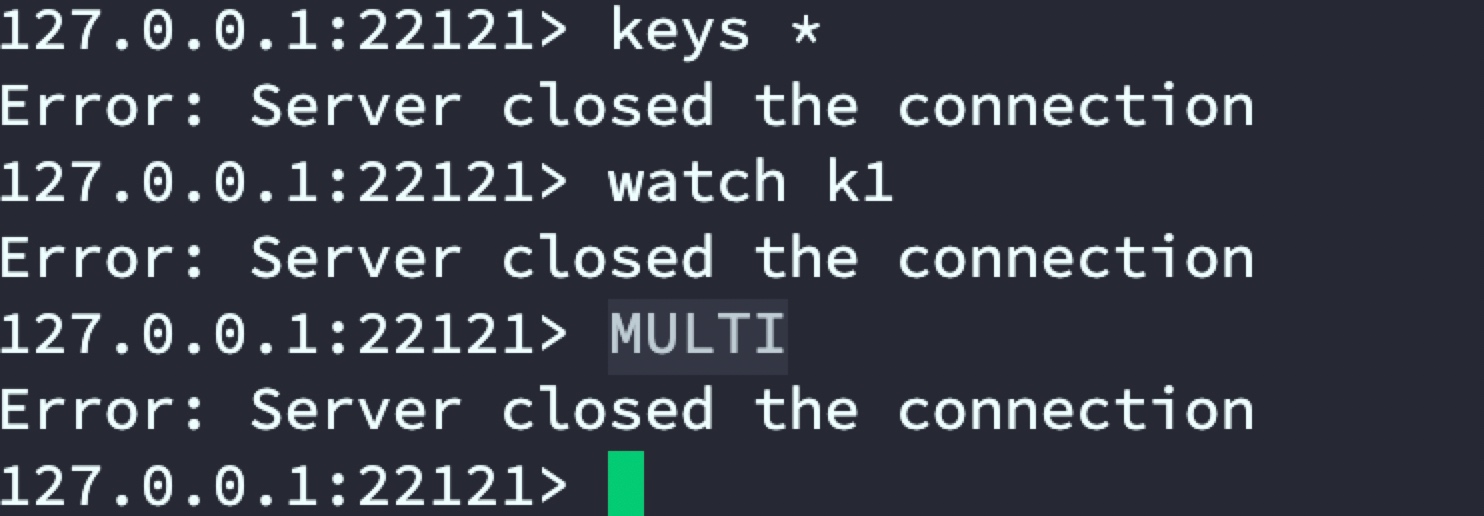
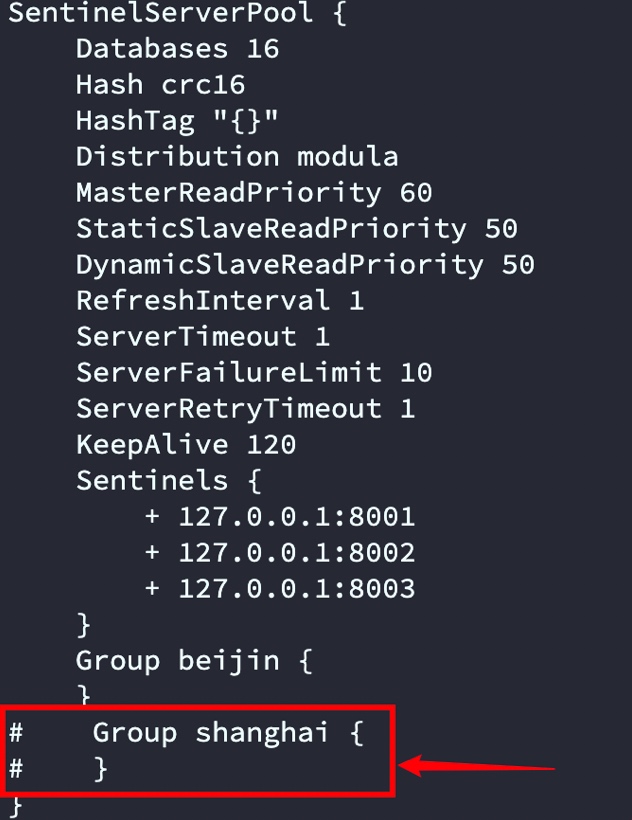
發現當存在2套Redis組集群時predixy依舊不支持事務,predixy只支持單組集群下的事務,
停止predixy修改predixy.conf
vi predixy-1.0.5/conf/sentinel.conf
修改后配置
重新啟動predixy并驗證
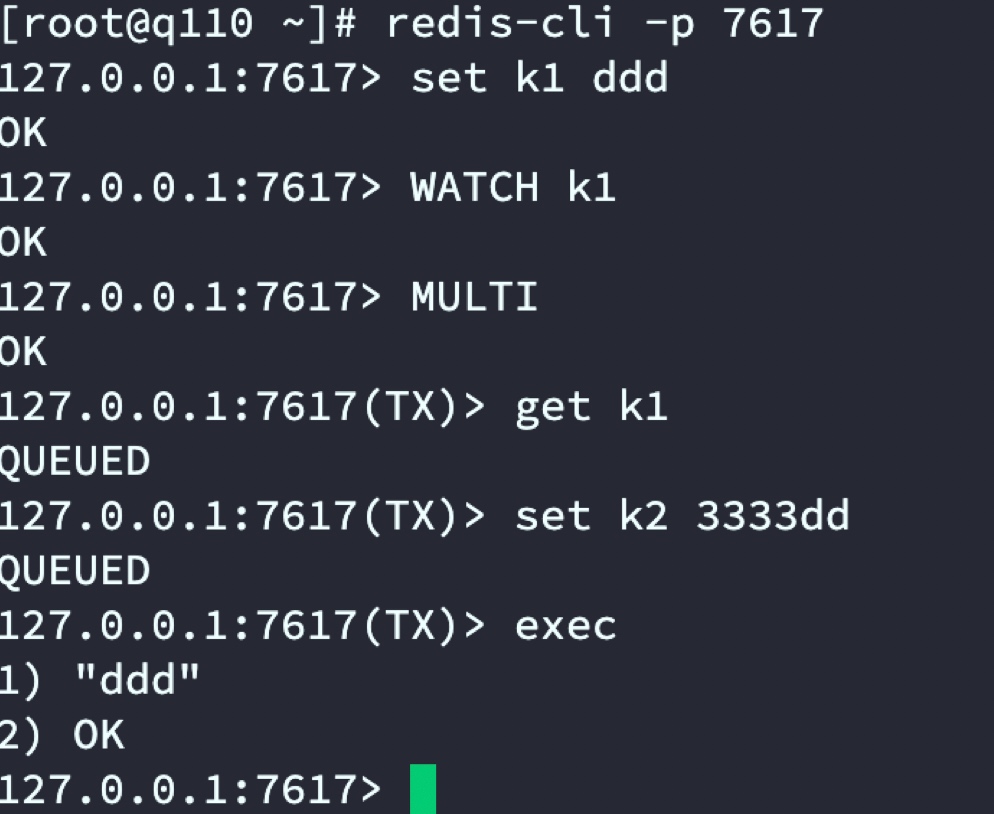
通過測驗發現單組集群predixy是可以支持事務的,接下來演示Redis Cluster集群模式
3.3 Redis Cluster集群搭建
3.3.1 使用官方提供的腳本搭建Redis Cluster集群
- 修改配置
# 進入Redis原始碼目錄
cd redis-6.2.6/utils/create-cluster
vi create-cluster
修改nodes節點數量和replicas副本數量,我這使用3組 每組1主1從測驗,修改后的結果

2. 啟動集群
# 啟動集群
./create-cluster start
# 分哈希槽
./create-cluster create
如下截圖,已經將16384個slots分給3臺master,并且反饋了每臺master對應分得的slots編號及數量
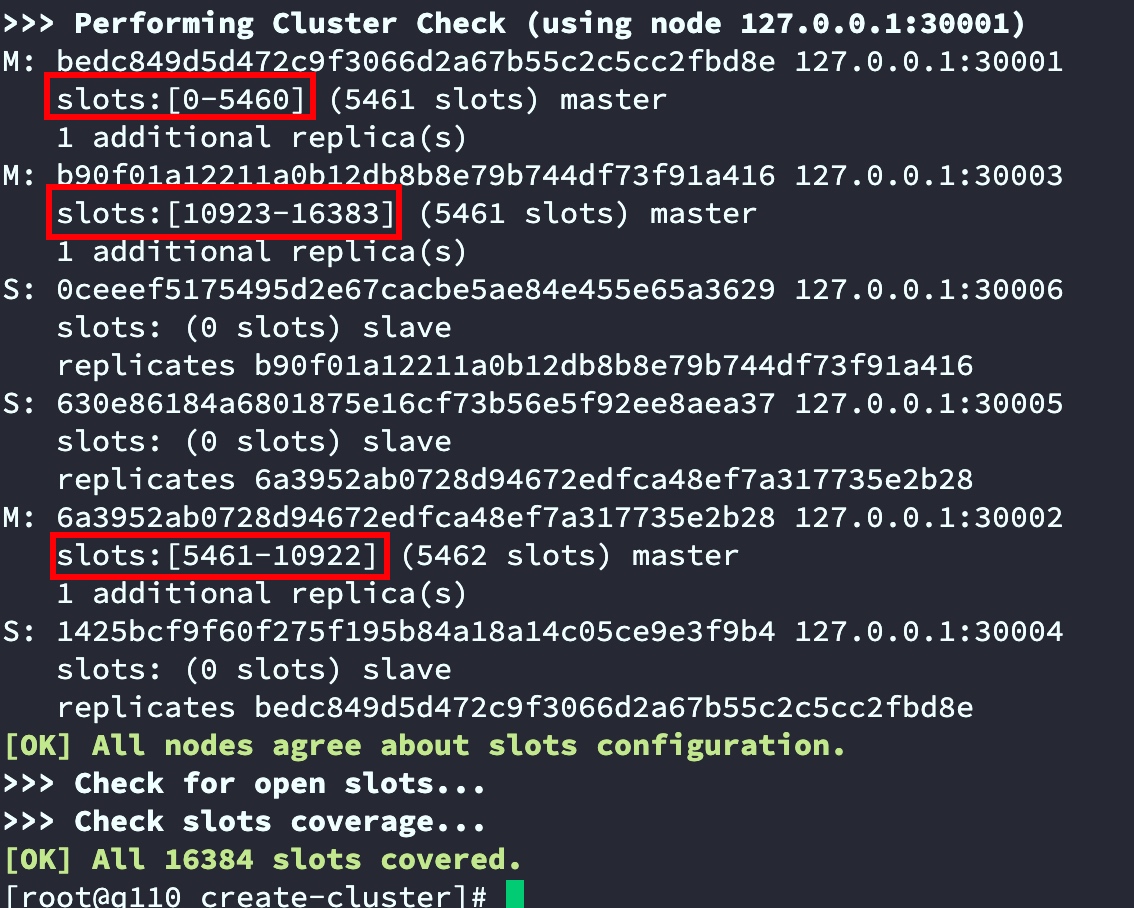
3.3.2 手動創建集群并分配哈希槽
目前是Redis cluster 自動幫我們設定的集群資訊以及分配的哈希槽,也可以手動創建和設定
手動創建集群并分配哈希槽
# 停止集群
./create-cluster stop
# 清理已分配的哈希槽資訊
./create-cluster clean
# 創建集群 --cluster-replicas 1 即 1主1從
redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1
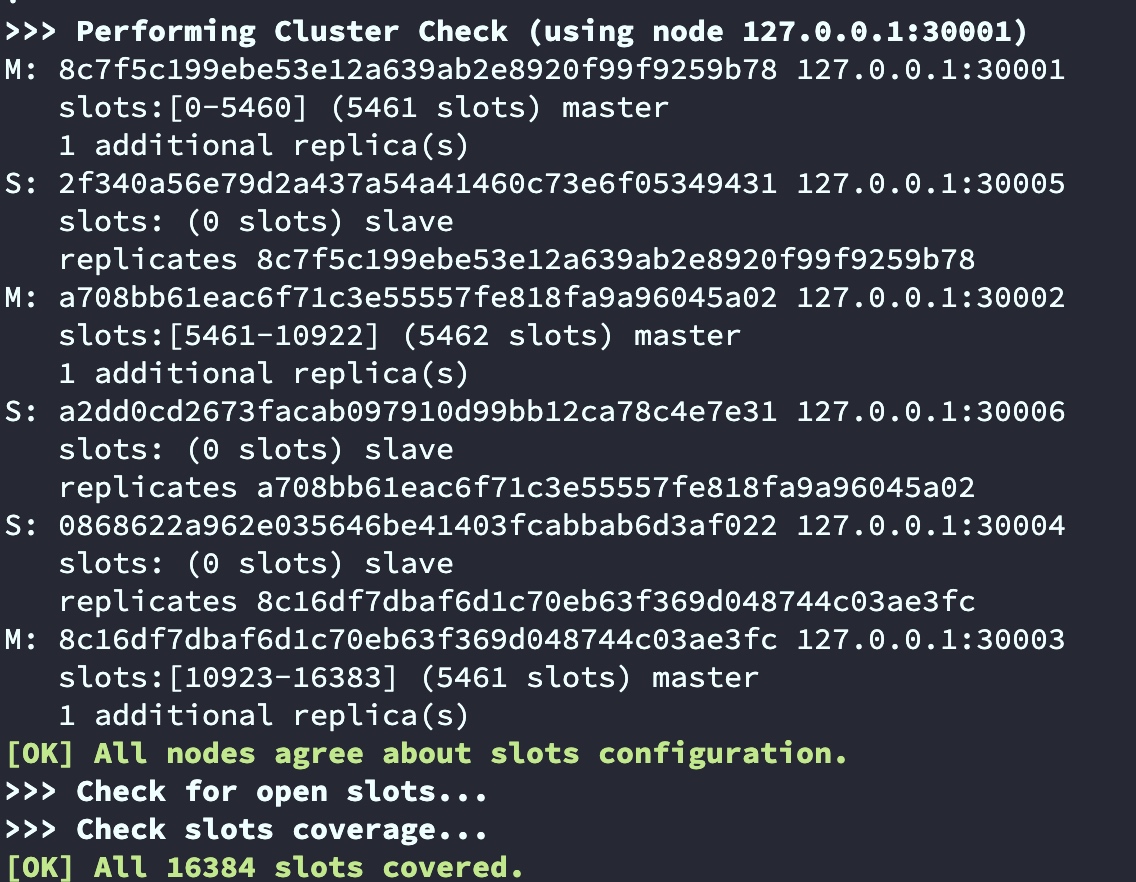
手動設定的集群哈希槽分配情況
| 節點 | 哈希槽 | 數量 |
|---|---|---|
| 30001 | 0-5460 | 5461 |
| 30002 | 5461-10922 | 5462 |
| 30003 | 10923-16383 | 5461 |
假設我們需要將30001節點的槽移動1000個到30003
# 連接Redis集群 隨便集群中的哪個節點都可以
[root@q110 create-cluster]# redis-cli --cluster reshard 127.0.0.1:30001
>>> Performing Cluster Check (using node 127.0.0.1:30001)
M: 8c7f5c199ebe53e12a639ab2e8920f99f9259b78 127.0.0.1:30001
slots:[0-5460] (5461 slots) master
1 additional replica(s)
S: 2f340a56e79d2a437a54a41460c73e6f05349431 127.0.0.1:30005
slots: (0 slots) slave
replicates 8c7f5c199ebe53e12a639ab2e8920f99f9259b78
M: a708bb61eac6f71c3e55557fe818fa9a96045a02 127.0.0.1:30002
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: a2dd0cd2673facab097910d99bb12ca78c4e7e31 127.0.0.1:30006
slots: (0 slots) slave
replicates a708bb61eac6f71c3e55557fe818fa9a96045a02
S: 0868622a962e035646be41403fcabbab6d3af022 127.0.0.1:30004
slots: (0 slots) slave
replicates 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc
M: 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc 127.0.0.1:30003
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
# 需要移動的槽數量1000
How many slots do you want to move (from 1 to 16384)? 1000
# 分配給誰節點ID?
What is the receiving node ID? 8c16df7dbaf6d1c70eb63f369d048744c03ae3fc
Please enter all the source node IDs.
Type 'all' to use all the nodes as source nodes for the hash slots.
Type 'done' once you entered all the source nodes IDs.
# 從哪個節點取出
Source node #1: 8c7f5c199ebe53e12a639ab2e8920f99f9259b78
# 結束
Source node #2: done
查看節點資訊
redis-cli --cluster info 127.0.0.1:30001
redis-cli --cluster check 127.0.0.1:30001
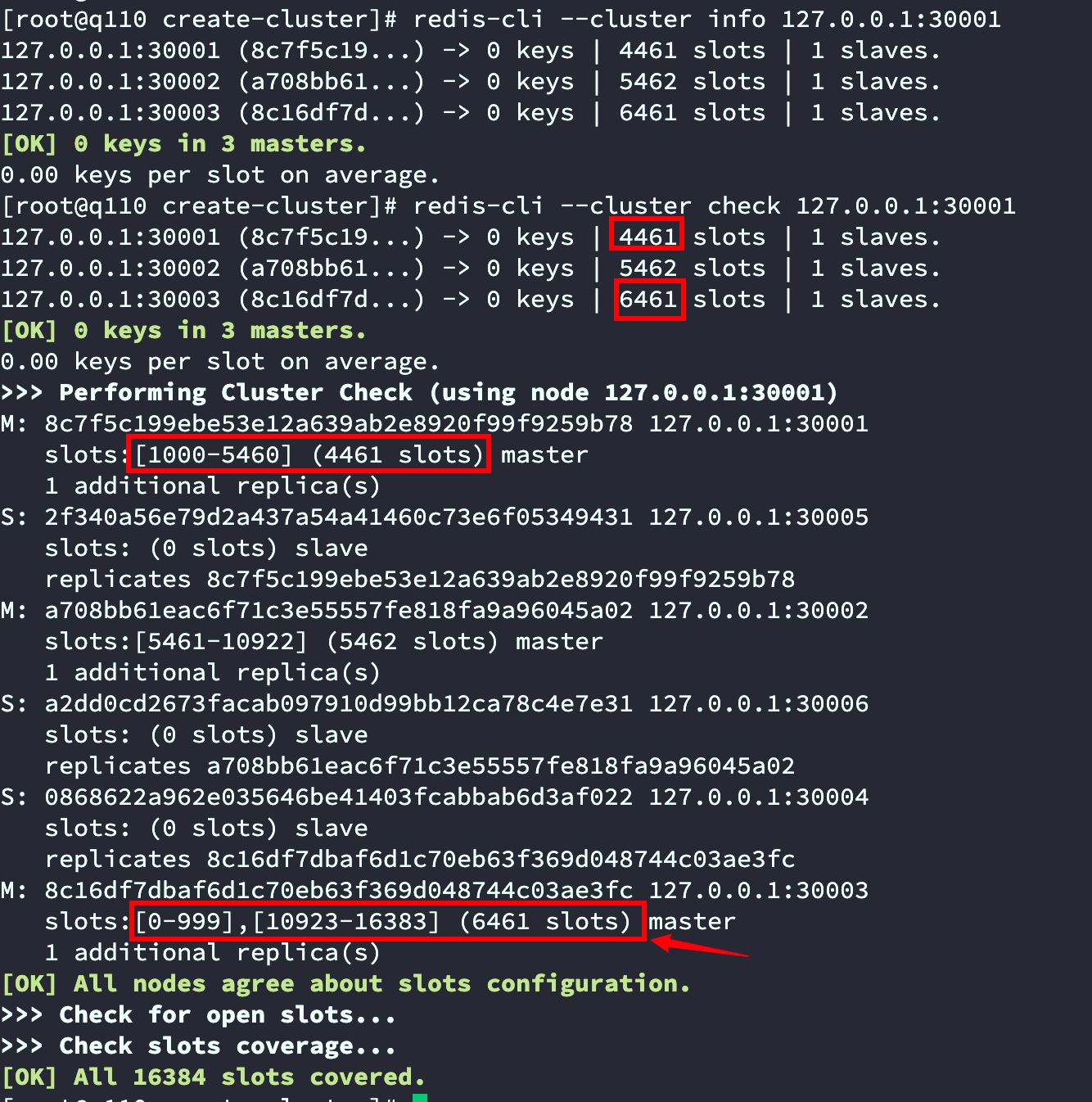
截圖中可以看出30001節點0-999共1000個槽已經移動到了30003
3.3.3 測驗集群
測驗資料存取
如下圖,我們使用Redis-cli -p 30001連接后set k1 xxx會報錯,提示set k1 需要到30003節點操作,通過redis-cli -c -p 30001連接Redis Cluster集群后 set k1 xxx會自動跳轉到30003節點,
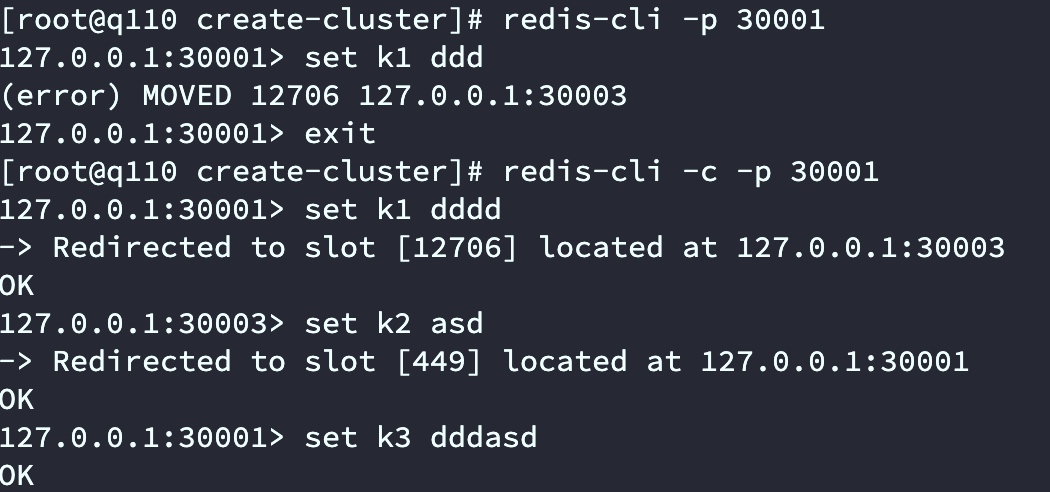
上面的截圖具體原因是Redis Cluster moved重定向問題:
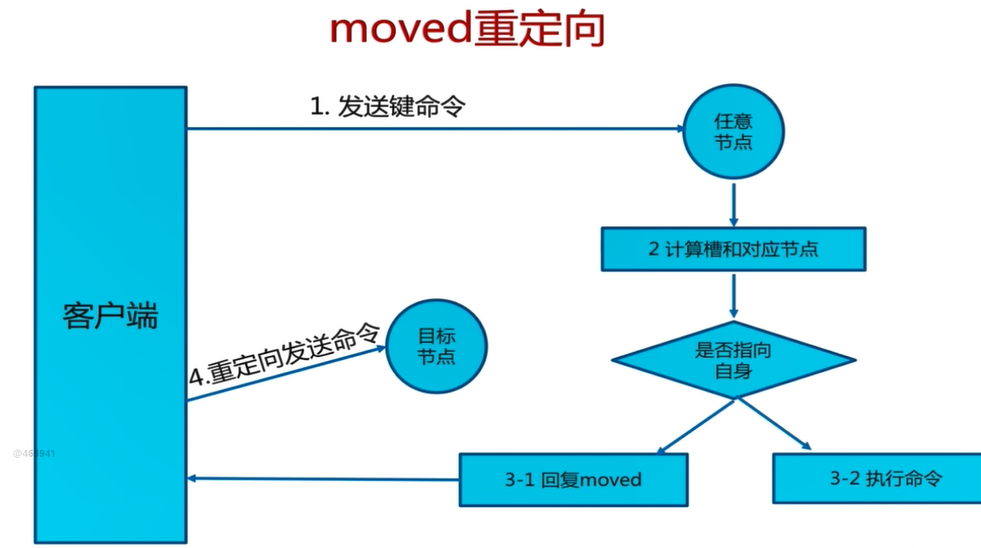
客戶端向Redis Cluster的任意節點發送命令,接收命令的節點會根據CRC16規則進行hash運算與16384取余,計算自己的槽和對應節點;如果保存資料的槽被分配給當前節點,則去槽中執行命令,并把命令執行結果回傳給客戶端;如果保存資料的槽不在當前節點的管理范圍內,則向客戶端回傳moved重定向例外;客戶端接收到節點回傳的結果,如果是moved例外,則從moved例外中獲取目標節點的資訊;客戶端向目標節點發送命令,獲取命令執行結果,
測驗事務
127.0.0.1:30003> set k2 kkd
-> Redirected to slot [449] located at 127.0.0.1:30001
OK
127.0.0.1:30001> WATCH k1
-> Redirected to slot [12706] located at 127.0.0.1:30003
OK
127.0.0.1:30003> MULTI
OK
127.0.0.1:30003(TX)> set k2 asd
-> Redirected to slot [449] located at 127.0.0.1:30001
OK
127.0.0.1:30001> exec
(error) ERR EXEC without MULTI
報錯了,原因是事務在30003節點開啟,事務中我們set k2 跳轉到了30001 然后提交事務在30001提交,這種情況Redis cluster 自身是不支持的,可以通過認為處理,類似Predixy代理的處理方式,在key前面加上固定的字符,比如下面的測驗
127.0.0.1:30002> set {beijin}k2 jjjjd
OK
127.0.0.1:30002> set {beijin}k1 jjjjd
OK
127.0.0.1:30002> MULTI
OK
127.0.0.1:30002(TX)> set {beijin}k2 lajdjddda
QUEUED
127.0.0.1:30002(TX)> exec
1) OK
127.0.0.1:30002>
至此Redis集群模式已經結束,但是實際作業中很多時候都是通過docker創建和管理集群,下一篇講解Docker搭建Redis集群及擴容收容
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/433314.html
標籤:其他
上一篇:Redis主從復制搭建及原理