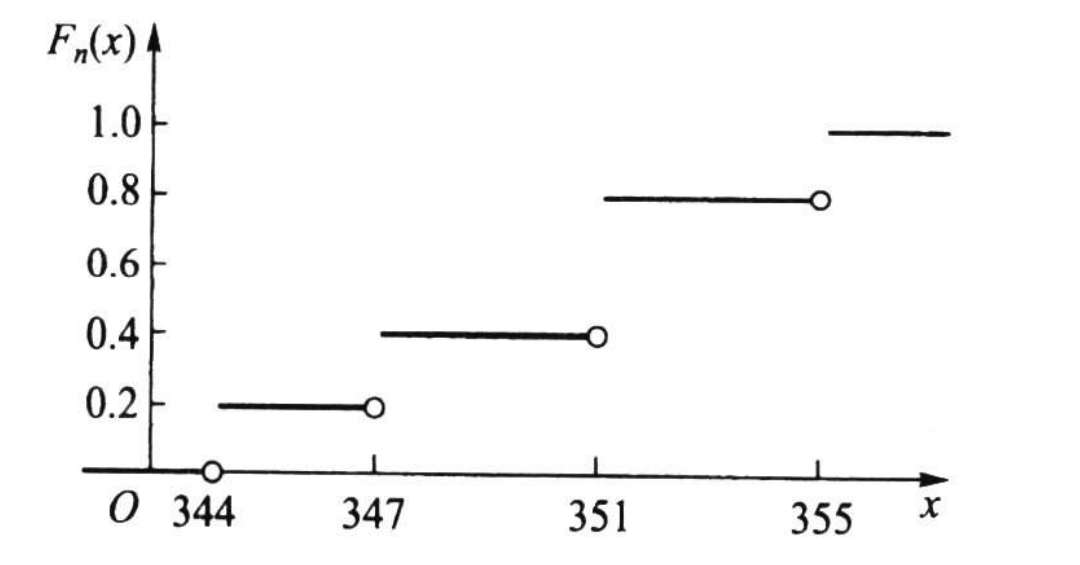
這是資料 x1:344,347,351,351,355 我需要根據上面的資料繪制經驗累積分布函式,這是我的解決方案
point<-na.omit(data$x1)
point<-point[!duplicated(point)]
point<-point[order(point)]
prob<-ecdf(data$x1)
prob<-prob(data$x1)
prob<-prob[order(prob)]
prob<-na.omit(prob)
x1<-data$x1[order(data$x1)]
x1<-c(340,344,347,351,355)
x2<-c(344,347,351,355,360)
prob2<-prob[!duplicated(prob)]
data1<-cbind(x1,x2,prob,point,prob2)
data1<-as.data.frame(data1)
ggplot(data=data1)
geom_segment(mapping = aes(x = x1,xend = x2,y = prob,yend = prob))
scale_x_continuous(limits = c(340,360))
scale_y_continuous(limits = c(0,1))
geom_point(mapping = aes(x = point ,y = prob2))
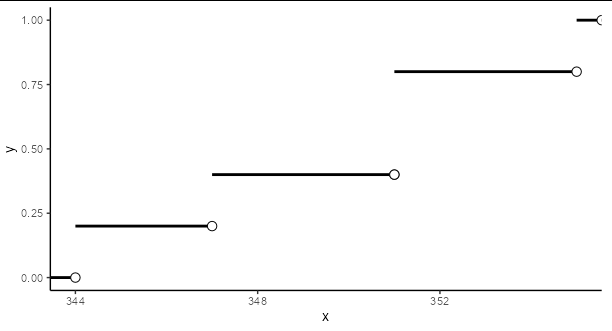
我認為這太復雜了,它不像影像上的情節,但我真的不知道如何在不使用基本情節()(或 stepfun(),因為它看起來不太好)的情況下簡化它。我已經考慮了幾個小時,非常感謝您的幫助!
uj5u.com熱心網友回復:
您可以通過創建要繪制的值的小資料框來手動完成。
library(ggplot2)
data <- c(344, 347, 351, 351, 355)
df <- data.frame(x = c(-Inf, data),
xend = c(data, Inf),
y = c(0, 0.2, 0.4, 0.4, 0.8, 1))
ggplot(df, aes(x, y))
geom_segment(aes(xend = xend, yend = y), size = 1)
geom_point(aes(x = xend), shape = 21, fill = "white", size = 3)
theme_classic()
轉載請註明出處,本文鏈接:https://www.uj5u.com/ruanti/437577.html
下一篇:指向ggplot2中的標志